
大資料:Hive
ORC File檔案結構
ORC的全稱是(Optimized Row Columnar),ORC檔案格式是一種Hadoop生態圈中的列式儲存格式,它的產生早在2013年初,最初產生自Apache Hive,用於降低Hadoop資料儲存空間和加速Hive查詢速度。和Parquet類似,它並不是一個單純的列式儲存格式,仍然是首先根據行組分割整個表,在每一個行組內進行按列儲存。ORC檔案是自描述的,它的元資料使用Protocol Buffers序列化,並且檔案中的資料儘可能的壓縮以降低儲存空間的消耗,目前也被Spark SQL、Presto等查詢引擎支援,但是Impala對於ORC目前沒有支援,仍然使用Parquet作為主要的列式儲存格式。2015年ORC專案被Apache專案基金會提升為Apache頂級專案。ORC具有以下一些優勢:
- ORC是列式儲存,有多種檔案壓縮方式,並且有著很高的壓縮比。
- 檔案是可切分(Split)的。因此,在Hive中使用ORC作為表的檔案儲存格式,不僅節省HDFS儲存資源,查詢任務的輸入資料量減少,使用的MapTask也就減少了。
- 提供了多種索引,row group index、bloom filter index。
- ORC可以支援複雜的資料結構(比如Map等)
列式儲存
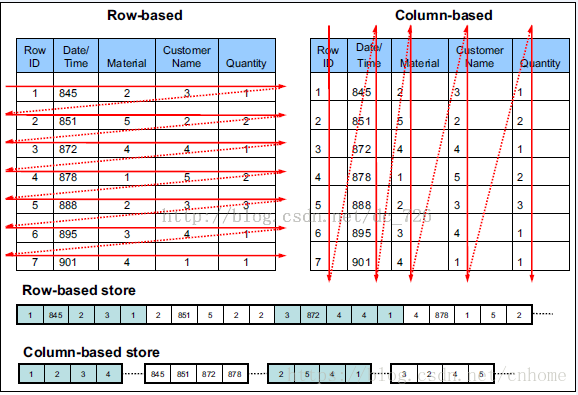
由於OLAP查詢的特點,列式儲存可以提升其查詢效能,但是它是如何做到的呢?這就要從列式儲存的原理說起,從圖1中可以看到,相對於關係資料庫中通常使用的行式儲存,在使用列式儲存時每一列的所有元素都是順序儲存的。由此特點可以給查詢帶來如下的優化:
- 查詢的時候不需要掃描全部的資料,而只需要讀取每次查詢涉及的列,這樣可以將I/O消耗降低N倍,另外可以儲存每一列的統計資訊(min、max、sum等),實現部分的謂詞下推。
- 由於每一列的成員都是同構的,可以針對不同的資料型別使用更高效的資料壓縮演算法,進一步減小I/O。
- 由於每一列的成員的同構性,可以使用更加適合CPU pipeline的編碼方式,減小CPU的快取失效。
關於Orc檔案格式的官網介紹,見
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
需要注意的是,ORC在讀寫時候需要消耗額外的CPU資源來壓縮和解壓縮,當然這部分的CPU消耗是非常少的。
資料模型
和Parquet不同,ORC原生是不支援巢狀資料格式的,而是通過對複雜資料型別特殊處理的方式實現巢狀格式的支援,例如對於如下的hive表:
CREATE TABLE `orcStructTable`(
`name` string,
`course` struct<course:string,score:int>,
`score` map<string,int>,
`work_locations` array<string>
) 在ORC的結構中包含了複雜型別列和原始型別,前者包括LIST、STRUCT、MAP和UNION型別,後者包括BOOLEAN、整數、浮點數、字串型別等,其中STRUCT的孩子節點包括它的成員變數,可能有多個孩子節點,MAP有兩個孩子節點,分別為key和value,LIST包含一個孩子節點,型別為該LIST的成員型別,UNION一般不怎麼用得到。每一個Schema樹的根節點為一個Struct型別,所有的column按照樹的中序遍歷順序編號。
ORC只需要儲存schema樹中葉子節點的值,而中間的非葉子節點只是做一層代理,它們只需要負責孩子節點值得讀取,只有真正的葉子節點才會讀取資料,然後交由父節點封裝成對應的資料結構返回。
檔案結構
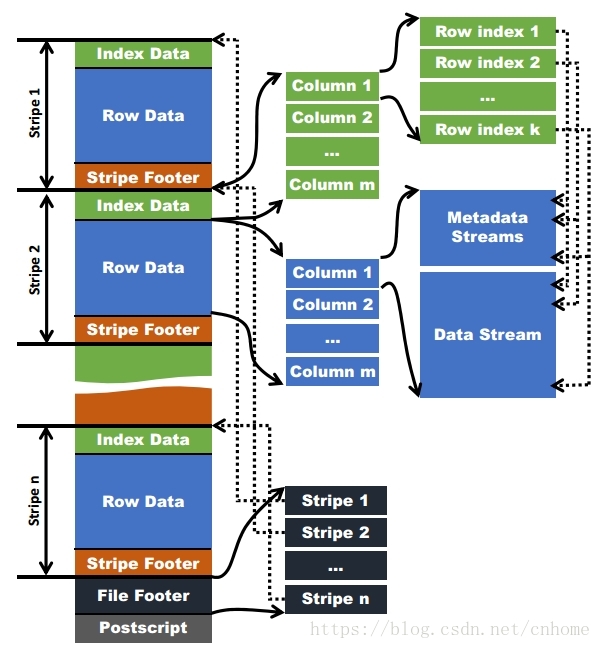
和Parquet類似,ORC檔案也是以二進位制方式儲存的,所以是不可以直接讀取,ORC檔案也是自解析的,它包含許多的元資料,這些元資料都是同構ProtoBuffer進行序列化的。ORC的檔案結構如下圖,其中涉及到如下的概念:
- ORC檔案:儲存在檔案系統上的普通二進位制檔案,一個ORC檔案中可以包含多個stripe,每一個stripe包含多條記錄,這些記錄按照列進行獨立儲存,對應到Parquet中的row
group的概念。 - 檔案級元資料:包括檔案的描述資訊PostScript、檔案meta資訊(包括整個檔案的統計資訊)、所有stripe的資訊和檔案schema資訊。
- stripe:一組行形成一個stripe,每次讀取檔案是以行組為單位的,一般為HDFS的塊大小,儲存了每一列的索引和資料。
- stripe元資料:儲存stripe的位置、每一個列的在該stripe的統計資訊以及所有的stream型別和位置。
- row group:索引的最小單位,一個stripe中包含多個row group,預設為10000個值組成。
stream:一個stream表示檔案中一段有效的資料,包括索引和資料兩類。索引stream儲存每一個row group的位置和統計資訊,資料stream包括多種型別的資料,具體需要哪幾種是由該列型別和編碼方式決定。
在ORC檔案中儲存了三個層級的統計資訊,分別為檔案級別、stripe級別和row group級別的,他們都可以用來根據Search ARGuments(謂詞下推條件)判斷是否可以跳過某些資料,在統計資訊中都包含成員數和是否有null值,並且對於不同型別的資料設定一些特定的統計資訊。file level
在ORC檔案的末尾會記錄檔案級別的統計資訊,會記錄整個檔案中columns的統計資訊。這些資訊主要用於查詢的優化,也可以為一些簡單的聚合查詢比如max, min, sum輸出結果。
stripe level
ORC檔案會儲存每個欄位stripe級別的統計資訊,ORC reader使用這些統計資訊來確定對於一個查詢語句來說,需要讀入哪些stripe中的記錄。比如說某個stripe的欄位max(a)=10,min(a)=3,那麼當where條件為a >10或者a <3時,那麼這個stripe中的所有記錄在查詢語句執行時不會被讀入。
row level
為了進一步的避免讀入不必要的資料,在邏輯上將一個column的index以一個給定的值(預設為10000,可由引數配置)分割為多個index組。以10000條記錄為一個組,對資料進行統計。Hive查詢引擎會將where條件中的約束傳遞給ORC reader,這些reader根據組級別的統計資訊,過濾掉不必要的資料。如果該值設定的太小,就會儲存更多的統計資訊,使用者需要根據自己資料的特點權衡一個合理的值
資料訪問
讀取ORC檔案是從尾部開始的,第一次讀取16KB的大小,儘可能的將Postscript和Footer資料都讀入記憶體。檔案的最後一個位元組儲存著PostScript的長度,它的長度不會超過256位元組,PostScript中儲存著整個檔案的元資料資訊,它包括檔案的壓縮格式、檔案內部每一個壓縮塊的最大長度(每次分配記憶體的大小)、Footer長度,以及一些版本資訊。在Postscript和Footer之間儲存著整個檔案的統計資訊(上圖中未畫出),這部分的統計資訊包括每一個stripe中每一列的資訊,主要統計成員數、最大值、最小值、是否有空值等。
接下來讀取檔案的Footer資訊,它包含了每一個stripe的長度和偏移量,該檔案的schema資訊(將schema樹按照schema中的編號儲存在陣列中)、整個檔案的統計資訊以及每一個row group的行數。
處理stripe時首先從Footer中獲取每一個stripe的其實位置和長度、每一個stripe的Footer資料(元資料,記錄了index和data的的長度),整個striper被分為index和data兩部分,stripe內部是按照row group進行分塊的(每一個row group中多少條記錄在檔案的Footer中儲存),row group內部按列儲存。每一個row group由多個stream儲存資料和索引資訊。每一個stream的資料會根據該列的型別使用特定的壓縮演算法儲存。在ORC中存在如下幾種stream型別:
- PRESENT:每一個成員值在這個stream中保持一位(bit)用於標示該值是否為NULL,通過它可以只記錄部位NULL的值
- DATA:該列的中屬於當前stripe的成員值。
- LENGTH:每一個成員的長度,這個是針對string型別的列才有的。
- DICTIONARY_DATA:對string型別資料編碼之後字典的內容。
- SECONDARY:儲存Decimal、timestamp型別的小數或者納秒數等。
ROW_INDEX:儲存stripe中每一個row group的統計資訊和每一個row group起始位置資訊。
在初始化階段獲取全部的元資料之後,可以通過includes陣列指定需要讀取的列編號,它是一個boolean陣列,如果不指定則讀取全部的列,還可以通過傳遞SearchArgument引數指定過濾條件,根據元資料首先讀取每一個stripe中的index資訊,然後根據index中統計資訊以及SearchArgument引數確定需要讀取的row group編號,再根據includes資料決定需要從這些row group中讀取的列,通過這兩層的過濾需要讀取的資料只是整個stripe多個小段的區間,然後ORC會盡可能合併多個離散的區間儘可能的減少I/O次數。然後再根據index中儲存的下一個row group的位置資訊調至該stripe中第一個需要讀取的row group中。
ORC檔案格式只支援讀取指定欄位,還不支援只讀取特殊欄位型別中的指定部分。
使用ORC檔案格式時,使用者可以使用HDFS的每一個block儲存ORC檔案的一個stripe。對於一個ORC檔案來說,stripe的大小一般需要設定得比HDFS的block小,如果不這樣的話,一個stripe就會分別在HDFS的多個block上,當讀取這種資料時就會發生遠端讀資料的行為。如果設定stripe的只儲存在一個block上的話,如果當前block上的剩餘空間不足以儲存下一個strpie,ORC的writer接下來會將資料打散儲存在block剩餘的空間上,直到這個block存滿為止。這樣,下一個stripe又會從下一個block開始儲存。
由於ORC中使用了更加精確的索引資訊,使得在讀取資料時可以指定從任意一行開始讀取,更細粒度的統計資訊使得讀取ORC檔案跳過整個row group,ORC預設會對任何一塊資料和索引資訊使用ZLIB壓縮,因此ORC檔案佔用的儲存空間也更小,這點在後面的測試對比中也有所印證。
檔案壓縮
ORC檔案使用兩級壓縮機制,首先將一個數據流使用流式編碼器進行編碼,然後使用一個可選的壓縮器對資料流進行進一步壓縮。
一個column可能儲存在一個或多個數據流中,可以將資料流劃分為以下四種類型:
- Byte Stream
位元組流儲存一系列的位元組資料,不對資料進行編碼。 - Run Length Byte Stream
位元組長度位元組流儲存一系列的位元組資料,對於相同的位元組,儲存這個重複值以及該值在位元組流中出現的位置。 - Integer Stream
整形資料流儲存一系列整形資料。可以對資料量進行位元組長度編碼以及delta編碼。具體使用哪種編碼方式需要根據整形流中的子序列模式來確定。 - Bit Field Stream
位元流主要用來儲存boolean值組成的序列,一個位元組代表一個boolean值,在位元流的底層是用Run Length Byte Stream來實現的。
接下來會以Integer和String型別的欄位舉例來說明。
- Integer
對於一個整形欄位,會同時使用一個位元流和整形流。位元流用於標識某個值是否為null,整形流用於儲存該整形欄位非空記錄的整數值。 - String
對於一個String型別欄位,ORC writer在開始時會檢查該欄位值中不同的內容數佔非空記錄總數的百分比不超過0.8的話,就使用字典編碼,欄位值會儲存在一個位元流,一個位元組流及兩個整形流中。位元流也是用於標識null值的,位元組流用於儲存字典值,一個整形流用於儲存字典中每個詞條的長度,另一個整形流用於記錄欄位值。
如果不能用字典編碼,ORC writer會知道這個欄位的重複值太少,用字典編碼效率不高,ORC writer會使用一個位元組流儲存String欄位的值,然後用一個整形流來儲存每個欄位的位元組長度。
在ORC檔案中,在各種資料流的底層,使用者可以自選ZLIB, Snappy和LZO壓縮方式對資料流進行壓縮。編碼器一般會將一個數據流壓縮成一個個小的壓縮單元,在目前的實現中,壓縮單元的預設大小是256KB。
引數
引數可參看
Hive+ORC建立資料倉庫
在建Hive表的時候我們就應該指定檔案的儲存格式。所以你可以在Hive QL語句裡面指定用ORCFile這種檔案格式,如下:
CREATE TABLE ... STORED AS ORC
ALTER TABLE ... [PARTITION partition_spec] SET FILEFORMAT ORC
SET hive.default.fileformat=Orc所有關於ORCFile的引數都是在Hive QL語句的TBLPROPERTIES欄位裡面出現,他們是:
| Key | Default | Notes |
|---|---|---|
| orc.compress | ZLIB | high level compression (one of NONE, ZLIB, SNAPPY) |
| orc.compress.size | 262,144 | number of bytes in each compression chunk |
| orc.stripe.size | 268435456 | number of bytes in each stripe |
| orc.row.index.stride | 10,000 | number of rows between index entries (must be >= 1000) |
| orc.create.index | true | whether to create row indexes |
Java操作ORC
到https://orc.apache.org官網下載orc原始碼包,然後編譯獲取orc-core-1.3.0.jar、orc-mapreduce-1.3.0.jar、orc-tools-1.3.0.jar,將其加入專案中
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hive.ql.exec.vector.LongColumnVector;
import org.apache.hadoop.hive.ql.exec.vector.VectorizedRowBatch;
import org.apache.orc.CompressionKind;
import org.apache.orc.OrcFile;
import org.apache.orc.TypeDescription;
import org.apache.orc.Writer;
public class TestORCWriter {
public static void main(String[] args) throws Exception {
Path testFilePath = new Path("/tmp/test.orc");
Configuration conf = new Configuration();
TypeDescription schema = TypeDescription.fromString("struct<field1:int,field2:int,field3:int>");
Writer writer = OrcFile.createWriter(testFilePath, OrcFile.writerOptions(conf).setSchema(schema).compress(CompressionKind.SNAPPY));
VectorizedRowBatch batch = schema.createRowBatch();
LongColumnVector first = (LongColumnVector) batch.cols[0];
LongColumnVector second = (LongColumnVector) batch.cols[1];
LongColumnVector third = (LongColumnVector) batch.cols[2];
final int BATCH_SIZE = batch.getMaxSize();
// add 1500 rows to file
for (int r = 0; r < 15000000; ++r) {
int row = batch.size++;
first.vector[row] = r;
second.vector[row] = r * 3;
third.vector[row] = r * 6;
if (row == BATCH_SIZE - 1) {
writer.addRowBatch(batch);
batch.reset();
}
}
if (batch.size != 0) {
writer.addRowBatch(batch);
batch.reset();
}
writer.close();
}
}大多情況下,還是建議在Hive中將文字檔案轉成ORC格式,這種用JAVA在本地生成ORC檔案,屬於特殊需求場景。
參考
相關推薦
自學大資料:Hive基於搜狗搜尋的使用者日誌行為分析
前言 ”大資料時代“,“大資料/雲端計算”,“大資料平臺”,每天聽到太多的大資料相關的詞語,好像現在說一句話不跟大資料沾邊都不好意思說自己是做IT的。可能這與整個IT圈子的炒作也有關聯,某一個方面來看其實就是一營銷術語。很多朋友就想問,我想做大資料,但是沒有這個條件,沒有這
大資料:Hive
轉自 ORC File檔案結構 ORC的全稱是(Optimized Row Columnar),ORC檔案格式是一種Hadoop生態圈中的列式儲存格式,它的產生早在2013年初,最初產生自Apache Hive,用於降低Hadoop資料儲存空間和加速Hi
大資料開發----Hive(入門篇)
前言 本篇介紹Hive的一些常用知識。要說和網上其他manual的區別,那就是這是筆者寫的一套成體系的文件,不是隨心所欲而作。 本文所用的環境為: CentOS 6.5 64位 Hive 2.1.1 Java 1.8 Hive Arc
【大資料】Hive作者肯定進修過藍翔挖掘機
正經標題應該是:解決hive初始化mysql資料庫錯誤的一種方式 Hive安裝包下載地址: https://mirrors.tuna.tsinghua.edu.cn/apache/hive/ 事情原因是這樣的,我按照書上的步驟一步一步走,到了該用hiv
大資料篇:Hive的安裝詳解
hive是什麼? 由facebook開源,用於解決海量結構化日誌的資料統計; 基於hadoop的一個數據倉庫工具,使用HDFS進行儲存並將結構化資料檔案對映成一張表,並提供類sql查詢的功能,其底層採用MR進行計算; 本質是將HQL轉化成MR程式。
影像大資料:ArcGIS Image Server
AI(人工智慧)大概是當前技術圈最火的風向,地理大資料和AI碰撞產生了一個新的概念GeoAI。GeoAI時代,ArcGIS為使用者和開發者提供了三個框架: (1)地理處理框架(GP) (2)空間大資料計算 (3)機器學習(ArcGIS Pro中自
大資料:特徵工程
1、單變數特徵篩選 計算每一個特徵與響應變數的相關性:工程上常用的手段有計算皮爾遜係數和互資訊係數,皮爾遜係數只能衡量線性相關性而互資訊係數能夠很好地度量各種相關性,但是計算相對複雜一些,好在很多toolkit裡邊都包含了這個工具(如sklearn的MINE),得到相關性之後就可以排序選
大資料 : Hadoop reduce階段
Mapreduce中由於sort的存在,MapTask和ReduceTask直接是工作流的架構。而不是資料流的架構。在MapTask尚未結束,其輸出結果尚未排序及合併前,ReduceTask是又有資料輸入的,因此即使ReduceTask已經建立也只能睡眠等待MapTask完成。從而可以從MapTask節點獲取
手機大資料:窮人愛買iPhone,華為使用者多有車有房
近日,知名調研機構MobData研究院公佈了中國2018年第三季的智慧手機市場調研報告。報告顯示,蘋果在手機市場佔有率依舊穩坐頭把交椅,高達21.6%,而華為小米OV等則緊隨其後。 有意思的是,MobData還詳盡地對各大手機品牌的使用者群體畫像進行刻畫分析。
大資料:Map終結和Spill檔案合併
當Mapper沒有資料輸入,mapper.run中的while迴圈會呼叫context.nextKeyValue就返回false,於是便返回到runNewMapper中,在這裡程式會關閉輸入通道和輸出通道,這裡關閉輸出通道並沒有關閉collector,必須要先flush一下。
大資料:Windows下配置flink的Stream
對於開發人員來說,最希望的是需要在windows中進行測試,然後把除錯好的程式放在叢集中執行。下面寫一個Socket,上面是監控本地的一個執行埠,來實時的提取資料。獲取視訊中文件資料及完整視訊的夥伴請加QQ群:947967114 下面是一段程式碼: import org.apache.flink
大資料:Mapper輸出緩衝區MapOutputBuffer
Mapper的輸出緩衝區MapOutputBuffer 現在我們知道了Map的輸入端,緊接著我們看map的輸出,這裡重點就是context.write這個語句的內涵。獲取視訊中文件資料及完整視訊的夥伴請加QQ群:947967114 搞清Mapper作為引數傳給map的context,這裡我們看Mapper
大資料平臺hive原生搭建教程
環境準備 centos 7.1系統 需要三臺雲主機: master(8) 作為 client 客戶端 slave1(9) 作為 hive server 伺服器端 slave2(10) 安裝 mysql server 安裝包使用的是官網下載的 將hive上傳到master ,mys
大資料:spark叢集搭建
建立spark使用者組,組ID1000 groupadd -g 1000 spark 在spark使用者組下建立使用者ID 2000的spark使用者 獲取視訊中文件資料及完整視訊的夥伴請加QQ群:947967114useradd -u 2000 -g spark spark 設定密碼 passwd
小米大資料:藉助Apache Kylin打造高效、易用的一站式OLAP解決方案
作者 | 小米大資料 如今的小米不僅是一家手機公司,更是一家大資料與人工智慧公司。隨著小米公司各項業務的快速發展,資料中的商業價值也愈發突顯。而與此同時,各業務團隊在資料查詢、分析等方面的壓力同樣正在劇增。因此,為幫助公司各業務線解決這些資料方面的挑戰,小米大資料團隊不斷地嘗試通過不同的技術手段打造新的解決方
學習筆記:從0開始學習大資料-10. hive安裝部署
1. 下載 wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.15.1.tar.gz 2.解壓 tar -zxvf hive-1.1.0-cdh5.15.1.tar.gz 3. hive的元資料(如表名,列
【文彬】區塊鏈 + 大資料:EOS儲存
原文連結:https://www.cnblogs.com/Evsward/p/storage.html 談到區塊鏈的儲存,我們很容易聯想到它的鏈式儲存結構,然而區塊鏈從比特幣發展到今日當紅的EOS,技術形態已經演化了10年之久。目前的EOS的儲存除了確認結構的鏈式儲存以外,在狀態
圳鵬大資料:大學生如何入行大資料行業
國內大資料行業發展的如火如荼,作為網際網路時代新型的產業,大資料行業其實是網際網路和計算機結合的產物,網際網路實現了資料的網路化,計算機實現了資料的數字化,兩者結合賦予了大資料生命力。 對於即將畢業的大學生如何入行大資料行業?成為大資料工程師需要哪些知識呢?圳鵬大資料的工程師為同學們
大資料利用hive on spark程式操作hive
hive on spark 作者:小濤 Hive是資料倉庫,他是處理有結構化的資料,當資料沒有結構化時hive就無法匯入資料,而它也是遠行在mr程式之上
大資料8-Hive簡介和叢集搭建
1.Hive特點: 1.1可擴充套件性 :Hive可以自由的擴充套件叢集的規模,一般情況下不需要重啟服務; 1.2延展性:Hive支援使用者自定義函式,使用者可以根據自己的需求來實現自己的函式; 1.3容錯:良好的容錯性,節點出現問題,SQ