
Python3:Python+spark程式設計實戰 總結
不宜妄自菲薄,引喻失義。
0、前提
0.1 配置
0.2 有關spark
說明:
spark 不相容 Python3.6
安裝注意版本
可下載:
anaconda4.2
一、例項分析
1.1 資料 student.txt
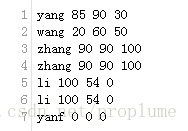
1.2 程式碼
#studentExample 例子 練習
def map_func(x):
s = x.split()
return (s[0], [int(s[1]),int(s[2]),int(s[3])]) #返回為(key,vaklue)格式,其中key:x[0],value:x[1]且為有三個元素的列表 #print(lines.collect())
print("資料集個數(行):",count)
print("單科滿分者:",whohas100)
print("單科零分者:",whois0)
print("單科最高分者:",subM)
print("單科總分:",sumSubScore)
print("合併名字相同的分數:",redByK)
print("總分/(人)",sumPerSore)
print("最高總分者:",maxScore)
print("最低總分者:",minScore)
print("每科平均成績:",avgScore)
print("總分倒序:",sortedWithRank)
print("總分前三者:",first3)
print(first3RDD)
sc.stop() 1.3 結果展示
資料集個數(行): 7
單科滿分者: [('li', [100, 54, 0]), ('li', [100, 54, 0])]
單科零分者: [('yanf', [0, 0, 0])]
單科最高分者: ('Maximum subject score', [100, 90, 100])
單科總分: ('Total subject score', [485, 438, 280])
合併名字相同的分數: [('li', [200, 108, 0]), ('zhang', [180, 180, 200]), ('yang', [85, 90, 30]), ('wang', [20, 60, 50]), ('yanf', [0, 0, 0])]
總分/(人) [('yang', 205), ('wang', 130), ('zhang', 280), ('zhang', 280), ('li', 154), ('li', 154), ('yanf', 0)]
最高總分者: ('zhang', 280)
最低總分者: ('yanf', 0)
每科平均成績: [69.28571428571429, 62.57142857142857, 40.0]
總分倒序: [(('yanf', [0, 0, 0]), 0), (('wang', [20, 60, 50]), 1), (('li', [100, 54, 0]), 2), (('li', [100, 54, 0]), 3), (('yang', [85, 90, 30]), 4), (('zhang', [90, 90, 100]), 5), (('zhang', [90, 90, 100]), 6)]
總分前三者: [('zhang', [90, 90, 100]), ('zhang', [90, 90, 100]), ('yang', [85, 90, 30])]
None二、程式碼解析
2.1函式解析
2.1.1 collect()
RDD的特性
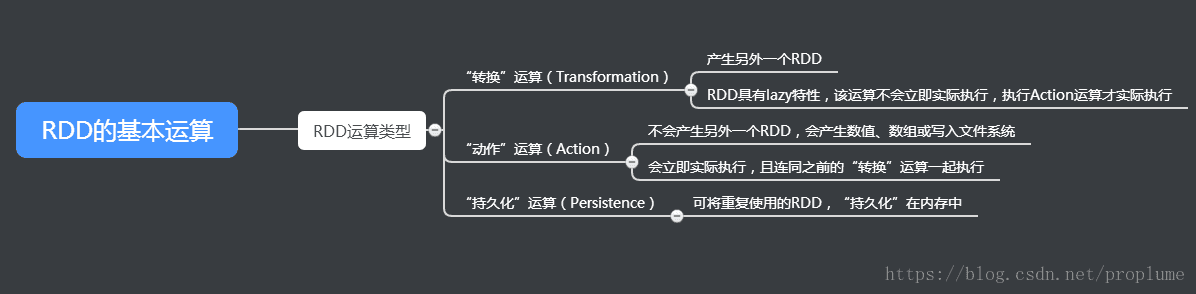
在進行基本RDD“轉換”運算時不會立即執行,結果不會顯示在顯示屏中,collect()是一個“動作”運算,會立刻執行,顯示結果。
2.1.2 reduce()
說明
reduce()函式會對引數序列中的元素進行累積。
語法
reduce(function, iterable[, initializer])
引數
- function – 函式,有兩個引數
- iterable – 可迭代物件
- initializer – 可選,初始引數
例項
說明:Python3的內建函式移除了reduce函式,reduce函式放在functools模組
In [24]:
#r = reduce(lambda x, y: x+y, [4,4,5,5]) # 使用 lambda 匿名函式
from functools import reduce
def add(x, y) : # 兩數相加
return x + y
reduce(add, [1,2,3,4,5])
Out[24]:
15
In [25]:
reduce(lambda x, y: x+y, [1,2,3,4,5]) # 使用 lambda 匿名函式
Out[25]:
152.1.3 type()
語法
class type(name, bases, dict)
引數
- name – 類的名稱。
- bases – 基類的元組。
- dict – 字典,類內定義的名稱空間變數。
返回值
一個引數返回物件型別, 三個引數,返回新的型別物件。
例項
#一個引數例項
In [1]:
type(1)
Out[1]:
int
In [2]:
type([2])
Out[2]:
list
In [3]:
type({3:'three'})
Out[3]:
dict
In [5]:
x = 5
type(x) == list #判斷x的型別是否為list
Out[5]:
False#三個引數例項
class y(object):
z = 5
x = type('y',(object,),dict(z=5))
print(x)
<class '__main__.y'> #產生一個新的型別三、問題分析
An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 2.0 failed 1 times, most recent failure: Lost task 1.0 in stage 2.0 (TID 5, localhost, executor driver): org.apache.spark.api.python.PythonException: Traceback (most recent call last):解析
1、檢查拼寫是否有誤
2、檢查縮排是否合規
3、檢查()是否一一配對
四、例項 小練
4.1 資料 user_small
1441900799.728000 1441900802.452000 8618245698655 0134730038729312 2 1 1 IPHONE_5 17999 20693 10.67.23.157 111.13.34.100 6 58986 80 GET mmsns.qpic.cn /mmsns/PdibpV1sFDHdaOTqNXb8VGSNicyYpOVa9R7icxSr4BkwbsSyzJbBTmE5Zz5aZichejbkKuia7twzraqk/150?tp=webp&length=1136&width=640 weixin.qq.com/?version=369229843&uin=2925174340&nettype=0&scene=moment WeChat/6.2.0.19 CFNetwork/711.3.18 Darwin/14.0.0 200 59 image/webp 7504 706 8212 7 1827
1441900750.023000 1441900754.063000 8613836044032 0136210021269713 2 1 1 IPHONE_5 17752 25632 10.67.21.71 117.144.242.26 6 52941 80 POST short.weixin.qq.com http://short.weixin.qq.com/cgi-bin/micromsg-bin/tenpay - MicroMessenger Client - - - - 715 0 7 1827
1441900755.480472 1441900756.762000 8618246899077 0131830068670612 2 1 1 IPHONE_4S 17875 61433 10.67.43.51 120.192.84.86 6 58684 31271 GET i.gtimg.cn http://i.gtimg.cn/qqshow/admindata/comdata/vip_emoji_aio_ios_new_config/xydata.json - QQ/5.7.0.469 CFNetwork/672.0.8 Darwin/14.0.0 304 83 x-json - 0 0 18 1041
1441900754.860000 1441900755.480472 8618246899077 0131830068670612 2 1 1 IPHONE_4S 17875 61433 10.67.43.51 120.192.84.86 6 58684 31271 GET i.gtimg.cn http://i.gtimg.cn/club/item/avatar/zip/0/i0/all.zip - QQ/5.7.0.469 CFNetwork/672.0.8 Darwin/14.0.0 404 210 text/html 85 487 411 18 1041
1441900753.786000 1441900755.726000 8618246195634 9900026543899411 2 1 1 IPHONE_4S 17783 19302 10.67.29.55 111.40.194.207 6 49412 80 GET sb.symcd.com /MFYwVKADAgEAME0wSzBJMAkGBSsOAwIaBQAEFDmvGLQcAh85EJZW%2FcbTWO90hYuZBBROQ8gddu83U3pP8lhvlPM44tW93wIQd9jUM82by0%2FVy957MNapGQ%3D%3D - securityd (unknown version) CFNetwork/672.0.2 Darwin/14.0.0 - - - - 522 0 18 1041
1441900761.308739 1441900761.408000 8615045213668 0127590050857822 2 1 1 IPHONE_4 17772 50621 10.67.63.219 183.232.95.61 6 49337 80 POST szminorshort.weixin.qq.com http://szminorshort.weixin.qq.com/cgi-bin/micromsg-bin/rtkvreport - MicroMessenger Client - - - - 500 16 7 1827
1441900696.427624 1441900761.308739 8615045213668 0127590050857822 2 1 1 IPHONE_4 17772 50621 10.67.63.219 183.232.95.61 6 49337 80 POST szminorshort.weixin.qq.com http://szminorshort.weixin.qq.com/cgi-bin/micromsg-bin/rtkvreport - MicroMessenger Client - - - - 500 16 7 1827
1441900693.219000 1441900696.427624 8615045213668 0127590050857822 2 1 1 IPHONE_4 17772 50621 10.67.63.219 183.232.95.61 6 49337 80 POST szminorshort.weixin.qq.com http://szminorshort.weixin.qq.com/cgi-bin/micromsg-bin/rtkvreport - MicroMessenger Client - - - - 502 16 7 1827
1441900750.845345 1441900753.537000 8618246195634 9900026543899411 2 1 1 IPHONE_4S 17783 19302 10.67.29.55 117.135.169.124 6 49411 80 GET b227.photo.store.qq.com /psb?/V12jlwSP30SPej/VE1V5LlXFMzHeg5gTzpyuCueaEVEGV*0X6BbSyJZRhs!/b/dCWGUIc.HQAA&ek=1&kp=1&pt=0&bo=yAD6AAAAAAABBxI!&t=5 v1_iph_sq_5.6.0_1_app_a-4-2 QQ/5.6.0.438 CFNetwork/672.0.2 Darwin/14.0.0 - - - - 792 0 18 1041
1441900748.094000 1441900750.845345 8618246195634 9900026543899411 2 1 1 IPHONE_4S 17783 19302 10.67.29.55 117.135.169.124 6 49411 80 GET b227.photo.store.qq.com /psb?/V12jlwSP30SPej/VE1V5LlXFMzHeg5gTzpyuCueaEVEGV*0X6BbSyJZRhs!/b/dCWGUIc.HQAA&ek=1&kp=1&pt=0&bo=yAD6AAAAAAABBxI!&t=5 v1_iph_sq_5.6.0_1_app_a-4-2 QQ/5.6.0.438 CFNetwork/672.0.2 Darwin/14.0.0 - - - - 792 0 18 10414.2 使用者上網記錄統計(一行為一條記錄).(使用者:第3列)
#test 1_1 使用者上網記錄統計
sc.stop()
from pyspark import SparkContext
sc = SparkContext(appName='test1')
rdd = sc.textFile('user_small')\
.map(lambda x:x.split('\t'))\
.map(lambda x:(x[3],1))\
.reduceByKey(lambda x,y:x+y)\
.map(lambda x:str(x[0])+' '+str(x[0][1])).collect()
#.saveAsTextFile('text1_1') #限定為空格鍵輸出到檔案
print(rdd)['0127590050857822 1', '9900026543899411 9', '0131830068670612 1', '0136210021269713 1', '0134730038729312 1']4.2使用者流量統計。分別統計上行流量及下行流量並將結果各列以空格鍵隔開輸出到檔案。(使用者:第3列;上行流量:第25列;下行流量:第26列)
#test 1_2 統計使用者上網 分別為上、下行流量
def map_func(x):
s = x.split('\t')
return (s[2],[int(s[24]),int(s[25])])#返回為(key,vaklue)格式,其中key:x[0],value:x[1]且為有三個元素的列表
#return (s[0],[int(s[1],s[2],s[3])]) #注意此用法不合法
try:
sc.stop() #停止之前的SparkContext,不然重新執行或者建立工作會失敗
except:
pass
from pyspark import SparkContext
sc=SparkContext(appName='test')
lines=sc.textFile("user_small").map(lambda x:map_func(x)).cache()
redByK = lines.reduceByKey(lambda x,y: (x[0]+y[0],x[1]+y[1]))
sum_flow = redByK.map(lambda x:str(x[0])+' '+str(x[1][0])+' '+str(x[1][1]))\
.saveAsTextFile('text1_2')
sc.stop()4.3 統計使用者總流量
#test 1_2 統計使用者上網 總流量
try:
sc.stop() #停止之前的SparkContext,不然重新執行或者建立工作會失敗
except:
pass
from pyspark import SparkContext
sc = SparkContext(appName='test1')
rdd = sc.textFile('user_small')\
.map(lambda x:x.split('\t'))\
.map(lambda x:(x[2],int(x[24])+int(x[25])))\
.reduceByKey(lambda x,y:x+y)\
.map(lambda x:str(x[0])+' '+str(x[1])).collect()
print(rdd)
sc.stop()['8618246899077 898', '8615045213668 1550', '8618245698655 8918', '8613836044032 715', '8618246195634 2106']4.4、微信APP流量統計。(微信APP特徵MicroMessenger,位於第20列,統計對應的下行流量值——第26列的數值。)
#test 1_3
sc.stop()
from pyspark import SparkContext
sc = SparkContext(appName='test1')
rdd = sc.textFile('user_small')\
.map(lambda x:x.split('\t'))\
.map(lambda x:(x[19],int(x[25])))\
.filter(lambda x: 'WeChat' or 'MicroMessenger' in x[1])#篩選\
.reduceByKey(lambda x,y:x+y)\
.map(lambda x:str(x[0])+' '+str(x[1])).collect()
print(rdd)['securityd (unknown version) CFNetwork/672.0.2 Darwin/14.0.0 0', 'QQ/5.6.0.438 CFNetwork/672.0.2 Darwin/14.0.0 0', 'QQ/5.7.0.469 CFNetwork/672.0.8 Darwin/14.0.0 411', 'MicroMessenger Client 48', 'WeChat/6.2.0.19 CFNetwork/711.3.18 Darwin/14.0.0 8212']相關推薦
Python3:Python+spark程式設計實戰 總結
不宜妄自菲薄,引喻失義。 0、前提 0.1 配置 0.2 有關spark 說明: spark 不相容 Python3.6 安裝注意版本 可下載: anaconda4.2 一、例項分析 1.1 資料 student.
福大軟工1816:團隊現場程式設計實戰(抽獎系統)
福大軟工1816 · 團隊現場程式設計實戰(抽獎系統) 組長部落格連結 本次作業連結 隊員職責分工 團隊成員 分工 張揚 預處理演算法、抽獎演算法、解決其他問題、本次部落格撰寫 韞月 "建立抽獎
Python GUI程式設計實戰--Tkinter元件詳解:Scale
Scale元件 “Scale”小元件提供了一個圖形滑塊物件,允許您從特定比例中選擇值。 語法 Here is the simple syntax to create this widget − w = Scale ( master, option, … ) Parameters ma
Python GUI程式設計實戰--Tkinter元件詳解:Entry
Radiobutton控制元件 Radiobutton(單選按鈕):元件用於實現多選一的問題。Radiobutton 元件可以包含文字或影象,每一個按鈕都可以與一個 Python 的函式或方法與之相關聯,當按鈕被按下時,對應的函式或方法將被自動執行。 Radiobutton 元件僅能顯示單
Python GUI程式設計實戰--Tkinter元件詳解:ListBox
Listbox控制元件 列表框控制元件;在Listbox視窗小部件是用來顯示一個字串列表給使用者 Listbox 元件通常被用於顯示一組文字選項,Listbox 元件跟 Checkbutton 和Radiobutton 元件類似,不過 Listbox 是以列表的形式來提供選項的(後兩個是通
Python GUI程式設計實戰--Tkinter元件詳解:Button
Button控制元件 Tkinter 按鈕元件用於在 Python 應用程式中新增按鈕,按鈕上可以放上文字或影象,按鈕可用於監聽使用者行為,能夠與一個 Python 函式關聯,當按鈕被按下時,自動呼叫該函式。 語法 bt = Button ( master, option=value, …
Python GUI程式設計實戰--Tkinter元件詳解:Label
Label 控制元件 在 Tkinter 中, Label 控制元件用以顯示文字和圖片. Label 通常被用來展示資訊, 而非與使用者互動. (注: Label 也可以繫結點選等事件, 只是通常不這麼用). import tkinter as tk # 建立視窗物件 root = t
Python GUI程式設計實戰--認識Tkinter元件
Tkinter 元件 Tkinter的提供各種控制元件,如按鈕,標籤和文字框,一個GUI應用程式中使用。這些控制元件通常被稱為控制元件或者部件。 目前有15種Tkinter的部件。 如下圖: 標準屬性 標準屬性也就是所有控制元件的共同屬性,如大小,字型和顏色等等。 幾何管理 Tkin
Python GUI程式設計實戰--Tkinter初識
什麼是Tkinter? Tkinter模組(“Tk 介面”)是Python的標準Tk GUI工具包的介面.Tk和Tkinter可以在大多數的Unix平臺下使用,同樣可以應用在Windows和Macintosh系統裡.Tk8.0的後續版本可以實現本地視窗風格,並良好地執行在絕大多數平臺中. T
Python高效程式設計實戰---9、淺談 Python 的 with 語句
引言 with 語句是從 Python 2.5 開始引入的一種與異常處理相關的功能(2.5 版本中要通過 from __future__ import with_statement 匯入後才可以使用),從 2.6 版本開始預設可用(參考 What’s new
Java基礎:java網路程式設計IO總結(BIO、NIO、AIO)
1.基本概念 在Java網路通訊中,最基本的概念就是Socket程式設計了。Socket又稱“套接字” 向網路發出請求或者應答網路請求。 Socket 和ServerSocket類庫位於 Java.net 包中。ServerSocket用於伺服器端,Socket是建立網路連線時使用的
Python貓薦書系列之五:Python高效能程式設計
稍微關心程式語言的使用趨勢的人都知道,最近幾年,國內最火的兩種語言非 Python 與 Go 莫屬,於是,隔三差五就會有人問:這兩種語言誰更厲害/好找工作/高工資…… 對於程式語言的爭論,就是猿界的生理週期,每個月都要鬧上一回。到了年末,各類榜單也是特別抓人眼球,鬧得更凶。 其實,它們各有
Python硬體程式設計實戰------書評
《Python硬體程式設計實戰》,李茂編著 機械工業出版社 版次2015年2月第1版第1次印刷 首先,這本書不適合入門,儘管作者的初衷是想作為入門,實際上卻是博文的集合。 個人覺得本書有兩處比較出彩: 1、關於開發工具的介紹; 2、__name__和__main__的關係
Spark Programming Guide (Python) Spark程式設計指南 (二)
對部分內容有修改,恕本人水平有限,如有錯誤,在所難免。 PySpark程式設計指南(譯): 1. 概述: a) 從高層次上來看,每一個Spark應用都包含一個驅動程式,用於執行使用者的main函式以及在叢集上執行各種並行操作。Spark提供的主要抽象是彈性分散式資
第三章:Python高階程式設計-深入類和物件
# 第三章:Python高階程式設計-深入類和物件 [Python3高階核心技術97講](https://coding.imooc.com/class/200.html) **筆記** ## 3.1 鴨子型別和多型 ```python """ 當看到一直鳥走起來像鴨子、游泳起來像鴨子、叫起來像鴨子,那
Java併發程式設計實戰總結 (一)
# 前提 首先該場景是一個酒店開房的業務。為了朋友們閱讀簡單,我把業務都簡化了。 業務:開房後會新增一條賬單,新增一條房間排期記錄,房間排期主要是為了房間使用的時間不衝突。如:賬單A,使用房間1,使用時間段為2020-06-01 12:00 - 2020-06-02 12:00 ,那麼還需要使用房間1開房的時
Scala實戰高手****第16課:Scala implicits程式設計徹底實戰及Spark原始碼鑑賞
隱式轉換:當某個類沒有具體的方法時,可以在該類的伴生物件或上下文中查詢是否存在隱式轉換,將其轉換為可以呼叫該方法的類,通過程式碼簡單的描述下 一:隱式轉換 1、定義類Man class Man(val name: String) 2、定義類SuperMan,並在類中定義一個方法 class Supe
python UI自動化實戰記錄十一: 總結
首先說說為什麼想起來用自動化指令碼來實現該專案的自動化。 工作還是以手工測試為主,業務驅動型的專案大概就是這樣,業務不停地變,不斷的迭代。 自動化測試實施的先決條件: 一 得有時間。如果有時間大部分的專案都可以實現自動化,這是毋庸置疑 的。不過公司手工測試崗位的測試任務之繁重做過的同學
第16課:Scala implicits程式設計徹底實戰及Spark原始碼鑑賞
本節課主要講的內容: 1、函式隱式轉換 2、隱式引數 3、隱式類 4、隱式物件 本節課搜狐視訊地址:http://my.tv.sohu.com/us/299637343/84785657.shtml隱式轉換:當某個類沒有具體的方法時,可以在該類的伴生物件或上下文中查詢是否存在隱式轉換,將其轉換為可以呼叫該方法
機器學習:Python實現聚類算法(三)之總結
.fig ask class ted ssi 缺點 處理 blob ron 考慮到學習知識的順序及效率問題,所以後續的幾種聚類方法不再詳細講解原理,也不再寫python實現的源代碼,只介紹下算法的基本思路,使大家對每種算法有個直觀的印象,從而可以更好的理解函數中