
Spark修煉之道(進階篇)——Spark入門到精通:第十節 Spark SQL案例實戰(一)
阿新 • • 發佈:2018-12-25
作者:周志湖
放假了,終於能抽出時間更新部落格了…….
1. 獲取資料
本文通過將github上的Spark專案git日誌作為資料,對SparkSQL的內容進行詳細介紹
資料獲取命令如下:
[[email protected] spark]# git log --pretty=format:'{"commit":"%H","author":"%an","author_email":"%ae","date":"%ad","message":"%f"}' > sparktest.json格式化日誌內容輸出如下:
[[email protected] 然後使用命令將sparktest.json檔案上傳到HDFS上
[root@master 2. 建立DataFrame
使用資料建立DataFrame
scala> val df = sqlContext.read.json("/data/sparktest.json")
16/02/05 09:59:56 INFO json.JSONRelation: Listing hdfs://ns1/data/sparktest.json on driver檢視其模式:
scala> df.printSchema()
root
|-- author: string (nullable = true 3. DataFrame方法實戰
(1)顯式前兩行資料
scala> df.show(2)
+----------------+--------------------+--------------------+--------------------+--------------------+
| author| author_email| commit| date| message|
+----------------+--------------------+--------------------+--------------------+--------------------+
| Josh Rosen|[email protected]|30b706b7b36482921...|Fri Nov 6 18:17:3...|SPARK-11389-CORE-...|
|Michael Armbrust|[email protected]|105732dcc6b651b97...|Fri Nov 6 17:22:3...|HOTFIX-Fix-python...|
+----------------+--------------------+--------------------+--------------------+--------------------+(2)計算總提交次數
scala> df.count
res4: Long = 13507
下圖給出的是我github上的commits次數,可以看到,其結束是一致的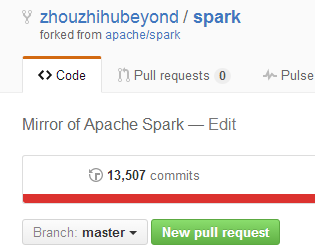
(3)按提交次數進行降序排序
scala>df.groupBy("author").count.sort($"count".desc).show
+--------------------+-----+
| author|count|
+--------------------+-----+
| Matei Zaharia| 1590|
| Reynold Xin| 1071|
| Patrick Wendell| 857|
| Tathagata Das| 416|
| Josh Rosen| 348|
| Mosharaf Chowdhury| 290|
| Andrew Or| 287|
| Xiangrui Meng| 285|
| Davies Liu| 281|
| Ankur Dave| 265|
| Cheng Lian| 251|
| Michael Armbrust| 243|
| zsxwing| 200|
| Sean Owen| 197|
| Prashant Sharma| 186|
| Joseph E. Gonzalez| 185|
| Yin Huai| 177|
|Shivaram Venkatar...| 173|
| Aaron Davidson| 164|
| Marcelo Vanzin| 142|
+--------------------+-----+
only showing top 20 rows
4. DataFrame註冊成臨時表使用實戰
使用下列語句將DataFrame註冊成表
scala> val commitLog=df.registerTempTable("commitlog")
(1)顯示前2行資料
scala> sqlContext.sql("SELECT * FROM commitlog").show(2)
+----------------+--------------------+--------------------+--------------------+--------------------+
| author| author_email| commit| date| message|
+----------------+--------------------+--------------------+--------------------+--------------------+
| Josh Rosen|[email protected]|30b706b7b36482921...|Fri Nov 6 18:17:3...|SPARK-11389-CORE-...|
|Michael Armbrust|[email protected]|105732dcc6b651b97...|Fri Nov 6 17:22:3...|HOTFIX-Fix-python...|
+----------------+--------------------+--------------------+--------------------+--------------------+
(2)計算總提交次數
scala> sqlContext.sql("SELECT count(*) as TotalCommitNumber FROM commitlog").show
+-----------------+
|TotalCommitNumber|
+-----------------+
| 13507|
+-----------------+
(3)按提交次數進行降序排序
scala> sqlContext.sql("SELECT author,count(*) as CountNumber FROM commitlog GROUP BY author ORDER BY CountNumber DESC").show
+--------------------+-----------+
| author|CountNumber|
+--------------------+-----------+
| Matei Zaharia| 1590|
| Reynold Xin| 1071|
| Patrick Wendell| 857|
| Tathagata Das| 416|
| Josh Rosen| 348|
| Mosharaf Chowdhury| 290|
| Andrew Or| 287|
| Xiangrui Meng| 285|
| Davies Liu| 281|
| Ankur Dave| 265|
| Cheng Lian| 251|
| Michael Armbrust| 243|
| zsxwing| 200|
| Sean Owen| 197|
| Prashant Sharma| 186|
| Joseph E. Gonzalez| 185|
| Yin Huai| 177|
|Shivaram Venkatar...| 173|
| Aaron Davidson| 164|
| Marcelo Vanzin| 142|
+--------------------+-----------+
更多複雜的玩法,大家可以自己去嘗試,這裡給出的只是DataFrame方法與臨時表SQL語句的用法差異,以便於有整體的認知。