
FPGA,你為什麼這麼牛?
最近幾年,FPGA這個概念越來越多地出現。
例如,比特幣挖礦,就有使用基於FPGA的礦機。還有,之前微軟表示,將在資料中心裡,使用FPGA“代替”CPU,等等。
其實,對於專業人士來說,FPGA並不陌生,它一直都被廣泛使用。但是,大部分人還不是太瞭解它,對它有很多疑問——FPGA到底是什麼?為什麼要使用它?相比 CPU、GPU、ASIC(專用晶片),FPGA有什麼特點?……
今天,帶著這一系列的問題,我們一起來——揭祕FPGA。
一、為什麼使用 FPGA?
眾所周知,通用處理器(CPU)的摩爾定律已入暮年,而機器學習和 Web 服務的規模卻在指數級增長。
人們使用定製硬體來加速常見的計算任務,然而日新月異的行業又要求這些定製的硬體可被重新程式設計來執行新型別的計算任務。
FPGA 正是一種硬體可重構的體系結構。它的英文全稱是Field Programmable Gate Array,中文名是現場可程式設計門陣列。
FPGA常年來被用作專用晶片(ASIC)的小批量替代品,然而近年來在微軟、百度等公司的資料中心大規模部署,以同時提供強大的計算能力和足夠的靈活性。
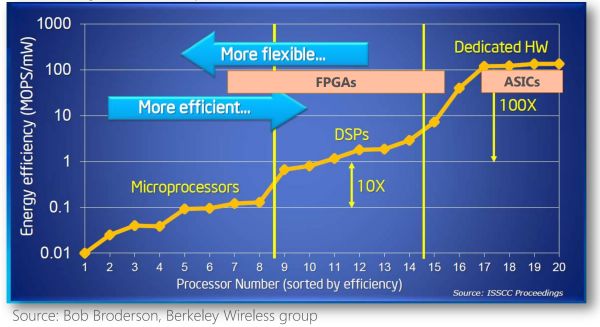
不同體系結構效能和靈活性的比較
FPGA 為什麼快?「都是同行襯托得好」。
CPU、GPU 都屬於馮·諾依曼結構,指令譯碼執行、共享記憶體。FPGA 之所以比 CPU 甚至 GPU 能效高,本質上是無指令、無需共享記憶體的體系結構帶來的福利。
馮氏結構中,由於執行單元(如 CPU 核)可能執行任意指令,就需要有指令儲存器、譯碼器、各種指令的運算器、分支跳轉處理邏輯。由於指令流的控制邏輯複雜,不可能有太多條獨立的指令流,因此 GPU 使用 SIMD(單指令流多資料流)來讓多個執行單元以同樣的步調處理不同的資料,CPU 也支援 SIMD 指令。
而 FPGA 每個邏輯單元的功能在重程式設計(燒寫)時就已經確定,不需要指令。
馮氏結構中使用記憶體有兩種作用。一是儲存狀態,二是在執行單元間通訊。
由於記憶體是共享的,就需要做訪問仲裁;為了利用訪問區域性性,每個執行單元有一個私有的快取,這就要維持執行部件間快取的一致性。
對於儲存狀態的需求,FPGA 中的暫存器和片上記憶體(BRAM)是屬於各自的控制邏輯的,無需不必要的仲裁和快取。
對於通訊的需求,FPGA 每個邏輯單元與周圍邏輯單元的連線在重程式設計(燒寫)時就已經確定,並不需要通過共享記憶體來通訊。
說了這麼多三千英尺高度的話,FPGA 實際的表現如何呢?我們分別來看計算密集型任務和通訊密集型任務。
計算密集型任務的例子包括矩陣運算、影象處理、機器學習、壓縮、非對稱加密、Bing 搜尋的排序等。這類任務一般是 CPU 把任務解除安裝(offload)給 FPGA 去執行。對這類任務,目前我們正在用的 Altera(似乎應該叫 Intel 了,我還是習慣叫 Altera……)Stratix V FPGA 的整數乘法運算效能與 20 核的 CPU 基本相當,浮點乘法運算效能與 8 核的 CPU 基本相當,而比 GPU 低一個數量級。我們即將用上的下一代 FPGA,Stratix 10,將配備更多的乘法器和硬體浮點運算部件,從而理論上可達到與現在的頂級 GPU 計算卡旗鼓相當的計算能力。

FPGA 的整數乘法運算能力(估計值,不使用 DSP,根據邏輯資源佔用量估計)
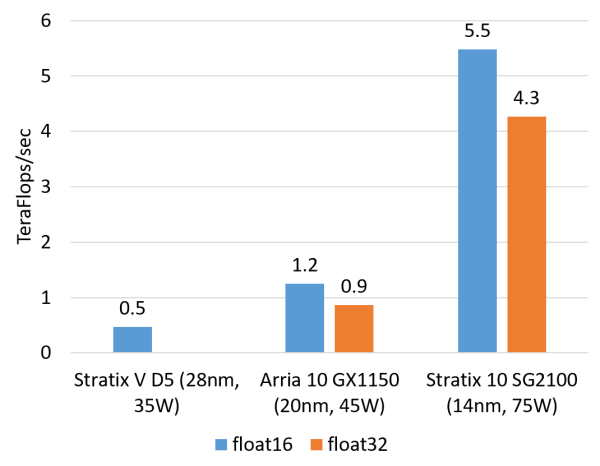
FPGA 的浮點乘法運算能力(估計值,float16 用軟核,float 32 用硬核)
在資料中心,FPGA 相比 GPU 的核心優勢在於延遲。
像 Bing 搜尋排序這樣的任務,要儘可能快地返回搜尋結果,就需要儘可能降低每一步的延遲。
如果使用 GPU 來加速,要想充分利用 GPU 的計算能力,batch size 就不能太小,延遲將高達毫秒量級。
使用 FPGA 來加速的話,只需要微秒級的 PCIe 延遲(我們現在的 FPGA 是作為一塊 PCIe 加速卡)。
未來 Intel 推出通過 QPI 連線的 Xeon + FPGA 之後,CPU 和 FPGA 之間的延遲更可以降到 100 納秒以下,跟訪問主存沒什麼區別了。
FPGA 為什麼比 GPU 的延遲低這麼多?
這本質上是體系結構的區別。
FPGA 同時擁有流水線並行和資料並行,而 GPU 幾乎只有資料並行(流水線深度受限)。
例如處理一個數據包有 10 個步驟,FPGA 可以搭建一個 10 級流水線,流水線的不同級在處理不同的資料包,每個資料包流經 10 級之後處理完成。每處理完成一個數據包,就能馬上輸出。
而 GPU 的資料並行方法是做 10 個計算單元,每個計算單元也在處理不同的資料包,然而所有的計算單元必須按照統一的步調,做相同的事情(SIMD,Single Instruction Multiple Data)。這就要求 10 個數據包必須一起輸入、一起輸出,輸入輸出的延遲增加了。
當任務是逐個而非成批到達的時候,流水線並行比資料並行可實現更低的延遲。因此對流式計算的任務,FPGA 比 GPU 天生有延遲方面的優勢。
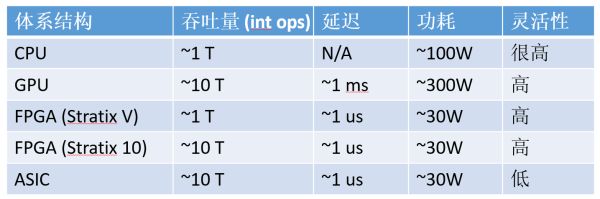
計算密集型任務,CPU、GPU、FPGA、ASIC 的數量級比較(以 16 位整數乘法為例,數字僅為數量級的估計
ASIC 專用晶片在吞吐量、延遲和功耗三方面都無可指摘,但微軟並沒有採用,出於兩個原因:
- 資料中心的計算任務是靈活多變的,而 ASIC 研發成本高、週期長。好不容易大規模部署了一批某種神經網路的加速卡,結果另一種神經網路更火了,錢就白費了。FPGA 只需要幾百毫秒就可以更新邏輯功能。FPGA 的靈活性可以保護投資,事實上,微軟現在的 FPGA 玩法與最初的設想大不相同。
- 資料中心是租給不同的租戶使用的,如果有的機器上有神經網路加速卡,有的機器上有 Bing 搜尋加速卡,有的機器上有網路虛擬化加速卡,任務的排程和伺服器的運維會很麻煩。使用 FPGA 可以保持資料中心的同構性。
接下來看通訊密集型任務。
相比計算密集型任務,通訊密集型任務對每個輸入資料的處理不甚複雜,基本上簡單算算就輸出了,這時通訊往往會成為瓶頸。對稱加密、防火牆、網路虛擬化都是通訊密集型的例子。

通訊密集型任務,CPU、GPU、FPGA、ASIC 的數量級比較(以 64 位元組網路資料包處理為例,數字僅為數量級的估計)
對通訊密集型任務,FPGA 相比 CPU、GPU 的優勢就更大了。
從吞吐量上講,FPGA 上的收發器可以直接接上 40 Gbps 甚至 100 Gbps 的網線,以線速處理任意大小的資料包;而 CPU 需要從網絡卡把資料包收上來才能處理,很多網絡卡是不能線速處理 64 位元組的小資料包的。儘管可以通過插多塊網絡卡來達到高效能,但 CPU 和主機板支援的 PCIe 插槽數量往往有限,而且網絡卡、交換機本身也價格不菲。
從延遲上講,網絡卡把資料包收到 CPU,CPU 再發給網絡卡,即使使用 DPDK 這樣高效能的資料包處理框架,延遲也有 4~5 微秒。更嚴重的問題是,通用 CPU 的延遲不夠穩定。例如當負載較高時,轉發延遲可能升到幾十微秒甚至更高(如下圖所示);現代作業系統中的時鐘中斷和任務排程也增加了延遲的不確定性。

ClickNP(FPGA)與 Dell S6000 交換機(商用交換機晶片)、Click+DPDK(CPU)和 Linux(CPU)的轉發延遲比較,error bar 表示 5% 和 95%。來源:[5]
雖然 GPU 也可以高效能處理資料包,但 GPU 是沒有網口的,意味著需要首先把資料包由網絡卡收上來,再讓 GPU 去做處理。這樣吞吐量受到 CPU 和/或網絡卡的限制。GPU 本身的延遲就更不必說了。
那麼為什麼不把這些網路功能做進網絡卡,或者使用可程式設計交換機呢?ASIC 的靈活性仍然是硬傷。
儘管目前有越來越強大的可程式設計交換機晶片,比如支援 P4 語言的 Tofino,ASIC 仍然不能做複雜的有狀態處理,比如某種自定義的加密演算法。
綜上,在資料中心裡 FPGA 的主要優勢是穩定又極低的延遲,適用於流式的計算密集型任務和通訊密集型任務。
二、微軟部署 FPGA 的實踐
2016 年 9 月,《連線》(Wired)雜誌發表了一篇《微軟把未來押注在 FPGA 上》的報道 [3],講述了 Catapult 專案的前世今生。
緊接著,Catapult 專案的老大 Doug Burger 在 Ignite 2016 大會上與微軟 CEO Satya Nadella 一起做了 FPGA 加速機器翻譯的演示。
演示的總計算能力是 103 萬 T ops,也就是 1.03 Exa-op,相當於 10 萬塊頂級 GPU 計算卡。一塊 FPGA(加上板上記憶體和網路介面等)的功耗大約是 30 W,僅增加了整個伺服器功耗的十分之一。

Ignite 2016 上的演示:每秒 1 Exa-op (10^18) 的機器翻譯運算能力
微軟部署 FPGA 並不是一帆風順的。對於把 FPGA 部署在哪裡這個問題,大致經歷了三個階段:
- 專用的 FPGA 叢集,裡面插滿了 FPGA
- 每臺機器一塊 FPGA,採用專用網路連線
- 每臺機器一塊 FPGA,放在網絡卡和交換機之間,共享伺服器網路
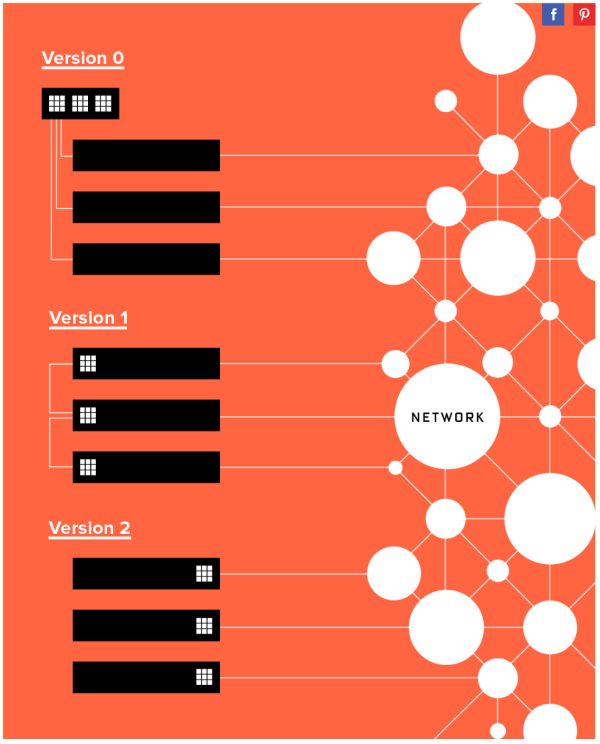
微軟 FPGA 部署方式的三個階段,來源:[3]
第一個階段是專用叢集,裡面插滿了 FPGA 加速卡,就像是一個 FPGA 組成的超級計算機。
下圖是最早的 BFB 實驗板,一塊 PCIe 卡上放了 6 塊 FPGA,每臺 1U 伺服器上又插了 4 塊 PCIe 卡。

最早的 BFB 實驗板,上面放了 6 塊 FPGA。來源:[1]
可以注意到該公司的名字。在半導體行業,只要批量足夠大,晶片的價格都將趨向於沙子的價格。據傳聞,正是由於該公司不肯給「沙子的價格」 ,才選擇了另一家公司。
當然現在資料中心領域用兩家公司 FPGA 的都有。只要規模足夠大,對 FPGA 價格過高的擔心將是不必要的。

最早的 BFB 實驗板,1U 伺服器上插了 4 塊 FPGA 卡。來源:[1]
像超級計算機一樣的部署方式,意味著有專門的一個機櫃全是上圖這種裝了 24 塊 FPGA 的伺服器(下圖左)。
這種方式有幾個問題:
- 不同機器的 FPGA 之間無法通訊,FPGA 所能處理問題的規模受限於單臺伺服器上 FPGA 的數量;
- 資料中心裡的其他機器要把任務集中發到這個機櫃,構成了 in-cast,網路延遲很難做到穩定。
- FPGA 專用機櫃構成了單點故障,只要它一壞,誰都別想加速了;
- 裝 FPGA 的伺服器是定製的,冷卻、運維都增加了麻煩。

部署 FPGA 的三種方式,從中心化到分散式。來源:[1]
一種不那麼激進的方式是,在每個機櫃一面部署一臺裝滿 FPGA 的伺服器(上圖中)。這避免了上述問題 (2)(3),但 (1)(4) 仍然沒有解決。
第二個階段,為了保證資料中心中伺服器的同構性(這也是不用 ASIC 的一個重要原因),在每臺伺服器上插一塊 FPGA(上圖右),FPGA 之間通過專用網路連線。這也是微軟在 ISCA'14 上所發表論文采用的部署方式。

Open Compute Server 在機架中。來源:[1]

Open Compute Server 內景。紅框是放 FPGA 的位置。來源:[1]

插入 FPGA 後的 Open Compute Server。來源:[1]

FPGA 與 Open Compute Server 之間的連線與固定。來源:[1]
FPGA 採用 Stratix V D5,有 172K 個 ALM,2014 個 M20K 片上記憶體,1590 個 DSP。板上有一個 8GB DDR3-1333 記憶體,一個 PCIe Gen3 x8 介面,兩個 10 Gbps 網路介面。一個機櫃之間的 FPGA 採用專用網路連線,一組 10G 網口 8 個一組連成環,另一組 10G 網口 6 個一組連成環,不使用交換機。

機櫃中 FPGA 之間的網路連線方式。來源:[1]
這樣一個 1632 臺伺服器、1632 塊 FPGA 的叢集,把 Bing 的搜尋結果排序整體效能提高到了 2 倍(換言之,節省了一半的伺服器)。
如下圖所示,每 8 塊 FPGA 穿成一條鏈,中間用前面提到的 10 Gbps 專用網線來通訊。這 8 塊 FPGA 各司其職,有的負責從文件中提取特徵(黃色),有的負責計算特徵表示式(綠色),有的負責計算文件的得分(紅色)。

FPGA 加速 Bing 的搜尋排序過程。來源:[1]

FPGA 不僅降低了 Bing 搜尋的延遲,還顯著提高了延遲的穩定性。來源:[4]
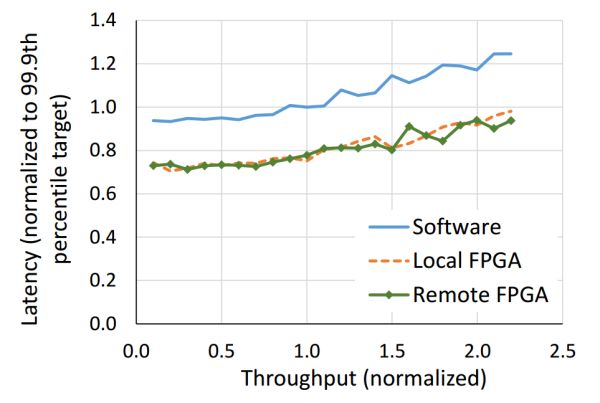
本地和遠端的 FPGA 均可以降低搜尋延遲,遠端 FPGA 的通訊延遲相比搜尋延遲可忽略。來源:[4]
FPGA 在 Bing 的部署取得了成功,Catapult 專案繼續在公司內擴張。
微軟內部擁有最多伺服器的,就是雲端計算 Azure 部門了。
Azure 部門急需解決的問題是網路和儲存虛擬化帶來的開銷。Azure 把虛擬機器賣給客戶,需要給虛擬機器的網路提供防火牆、負載均衡、隧道、NAT 等網路功能。由於雲端儲存的物理儲存跟計算節點是分離的,需要把資料從儲存節點通過網路搬運過來,還要進行壓縮和加密。
在 1 Gbps 網路和機械硬碟的時代,網路和儲存虛擬化的 CPU 開銷不值一提。隨著網路和儲存速度越來越快,網路上了 40 Gbps,一塊 SSD 的吞吐量也能到 1 GB/s,CPU 漸漸變得力不從心了。
例如 Hyper-V 虛擬交換機只能處理 25 Gbps 左右的流量,不能達到 40 Gbps 線速,當資料包較小時效能更差;AES-256 加密和 SHA-1 簽名,每個 CPU 核只能處理 100 MB/s,只是一塊 SSD 吞吐量的十分之一。
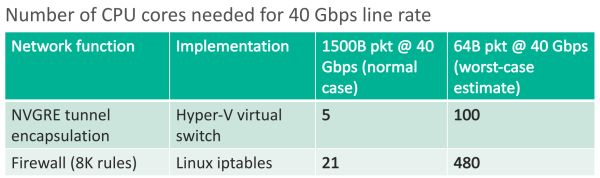
網路隧道協議、防火牆處理 40 Gbps 需要的 CPU 核數。來源:[5]
為了加速網路功能和儲存虛擬化,微軟把 FPGA 部署在網絡卡和交換機之間。
如下圖所示,每個 FPGA 有一個 4 GB DDR3-1333 DRAM,通過兩個 PCIe Gen3 x8 介面連線到一個 CPU socket(物理上是 PCIe Gen3 x16 介面,因為 FPGA 沒有 x16 的硬核,邏輯上當成兩個 x8 的用)。物理網絡卡(NIC)就是普通的 40 Gbps 網絡卡,僅用於宿主機與網路之間的通訊。
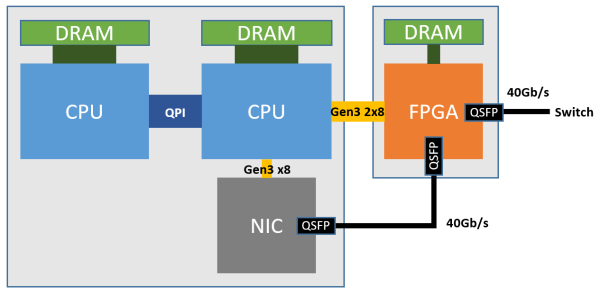
Azure 伺服器部署 FPGA 的架構。來源:[6]
FPGA(SmartNIC)對每個虛擬機器虛擬出一塊網絡卡,虛擬機器通過 SR-IOV 直接訪問這塊虛擬網絡卡。原本在虛擬交換機裡面的資料平面功能被移到了 FPGA 裡面,虛擬機器收發網路資料包均不需要 CPU 參與,也不需要經過物理網絡卡(NIC)。這樣不僅節約了可用於出售的 CPU 資源,還提高了虛擬機器的網路效能(25 Gbps),把同資料中心虛擬機器之間的網路延遲降低了 10 倍。
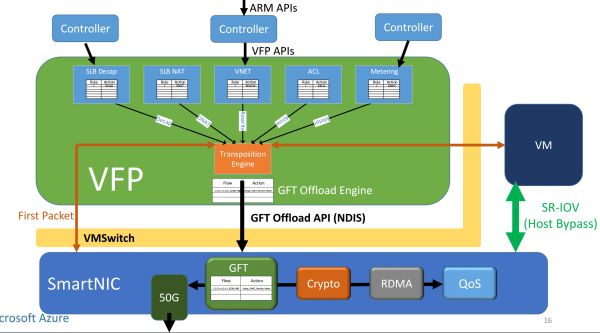
網路虛擬化的加速架構。來源:[6]
這就是微軟部署 FPGA 的第三代架構,也是目前「每臺伺服器一塊 FPGA」大規模部署所採用的架構。
FPGA 複用主機網路的初心是加速網路和儲存,更深遠的影響則是把 FPGA 之間的網路連線擴充套件到了整個資料中心的規模,做成真正 cloud-scale 的「超級計算機」。
第二代架構裡面,FPGA 之間的網路連線侷限於同一個機架以內,FPGA 之間專網互聯的方式很難擴大規模,通過 CPU 來轉發則開銷太高。
第三代架構中,FPGA 之間通過 LTL (Lightweight Transport Layer) 通訊。同一機架內延遲在 3 微秒以內;8 微秒以內可達 1000 塊 FPGA;20 微秒可達同一資料中心的所有 FPGA。第二代架構儘管 8 臺機器以內的延遲更低,但只能通過網路訪問 48 塊 FPGA。為了支援大範圍的 FPGA 間通訊,第三代架構中的 LTL 還支援 PFC 流控協議和 DCQCN 擁塞控制協議。
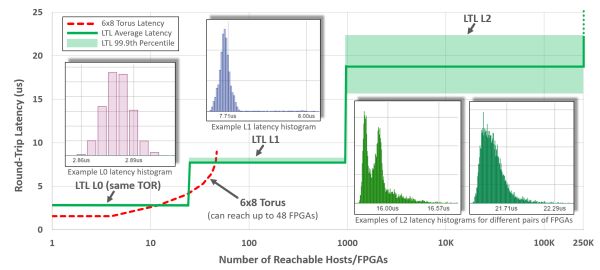
縱軸:LTL 的延遲,橫軸:可達的 FPGA 數量。來源:[4]
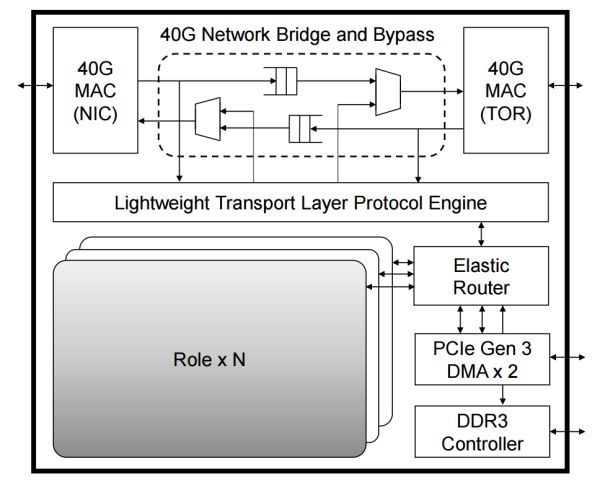
FPGA 內的邏輯模組關係,其中每個 Role 是使用者邏輯(如 DNN 加速、網路功能加速、加密),外面的部分負責各個 Role 之間的通訊及 Role 與外設之間的通訊。來源:[4]
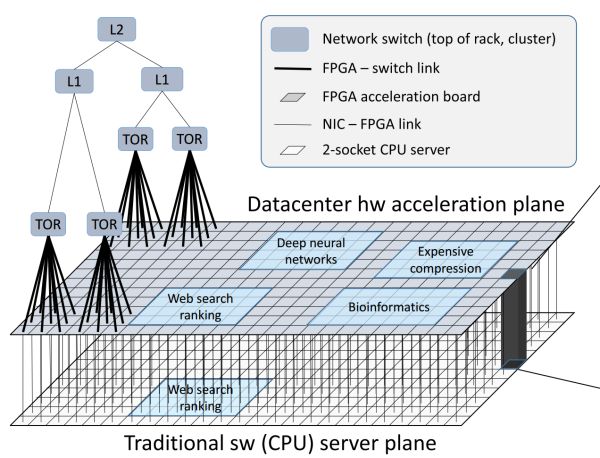
FPGA 構成的資料中心加速平面,介於網路交換層(TOR、L1、L2)和傳統伺服器軟體(CPU 上執行的軟體)之間。來源:[4]
通過高頻寬、低延遲的網路互聯的 FPGA 構成了介於網路交換層和傳統伺服器軟體之間的資料中心加速平面。
除了每臺提供雲服務的伺服器都需要的網路和儲存虛擬化加速,FPGA 上的剩餘資源還可以用來加速 Bing 搜尋、深度神經網路(DNN)等計算任務。
對很多型別的應用,隨著分散式 FPGA 加速器的規模擴大,其效能提升是超線性的。
例如 CNN inference,當只用一塊 FPGA 的時候,由於片上記憶體不足以放下整個模型,需要不斷訪問 DRAM 中的模型權重,效能瓶頸在 DRAM;如果 FPGA 的數量足夠多,每塊 FPGA 負責模型中的一層或者一層中的若干個特徵,使得模型權重完全載入片上記憶體,就消除了 DRAM 的效能瓶頸,完全發揮出 FPGA 計算單元的效能。
當然,拆得過細也會導致通訊開銷的增加。把任務拆分到分散式 FPGA 叢集的關鍵在於平衡計算和通訊。

從神經網路模型到 HaaS 上的 FPGA。利用模型內的並行性,模型的不同層、不同特徵對映到不同 FPGA。來源:[4]
在 MICRO'16 會議上,微軟提出了 Hardware as a Service (HaaS) 的概念,即把硬體作為一種可排程的雲服務,使得 FPGA 服務的集中排程、管理和大規模部署成為可能。

Hardware as a Service (HaaS)。來源:[4]
從第一代裝滿 FPGA 的專用伺服器叢集,到第二代通過專網連線的 FPGA 加速卡叢集,到目前複用資料中心網路的大規模 FPGA 雲,三個思想指導我們的路線:
- 硬體和軟體不是相互取代的關係,而是合作的關係;
- 必須具備靈活性,即用軟體定義的能力;
- 必須具備可擴放性(scalability)。
三、FPGA 在雲端計算中的角色
最後談一點我個人對 FPGA 在雲端計算中角色的思考。作為三年級博士生,我在微軟亞洲研究院的研究試圖回答兩個問題:
- FPGA 在雲規模的網路互連繫統中應當充當怎樣的角色?
- 如何高效、可擴放地對 FPGA + CPU 的異構系統進行程式設計?
我對 FPGA 業界主要的遺憾是,FPGA 在資料中心的主流用法,從除微軟外的網際網路巨頭,到兩大 FPGA 廠商,再到學術界,大多是把 FPGA 當作跟 GPU 一樣的計算密集型任務的加速卡。然而 FPGA 真的很適合做 GPU 的事情嗎?
前面講過,FPGA 和 GPU 最大的區別在於體系結構,FPGA 更適合做需要低延遲的流式處理,GPU 更適合做大批量同構資料的處理。
由於很多人打算把 FPGA 當作計算加速卡來用,兩大 FPGA 廠商推出的高層次程式設計模型也是基於 OpenCL,模仿 GPU 基於共享記憶體的批處理模式。CPU 要交給 FPGA 做一件事,需要先放進 FPGA 板上的 DRAM,然後告訴 FPGA 開始執行,FPGA 把執行結果放回 DRAM,再通知 CPU 去取回。
CPU 和 FPGA 之間本來可以通過 PCIe 高效通訊,為什麼要到板上的 DRAM 繞一圈?也許是工程實現的問題,我們發現通過 OpenCL 寫 DRAM、啟動 kernel、讀 DRAM 一個來回,需要 1.8 毫秒。而通過 PCIe DMA 來通訊,卻只要 1~2 微秒。

PCIe I/O channel 與 OpenCL 的效能比較。縱座標為對數座標。來源:[5]
OpenCL 裡面多個 kernel 之間的通訊就更誇張了,預設的方式也是通過共享記憶體。
本文開篇就講,FPGA 比 CPU 和 GPU 能效高,體系結構上的根本優勢是無指令、無需共享記憶體。使用共享記憶體在多個 kernel 之間通訊,在順序通訊(FIFO)的情況下是毫無必要的。況且 FPGA 上的 DRAM 一般比 GPU 上的 DRAM 慢很多。
因此我們提出了 ClickNP 網路程式設計框架 [5],使用管道(channel)而非共享記憶體來在執行單元(element/kernel)間、執行單元和主機軟體間進行通訊。
需要共享記憶體的應用,也可以在管道的基礎上實現,畢竟 CSP(Communicating Sequential Process)和共享記憶體理論上是等價的嘛。ClickNP 目前還是在 OpenCL 基礎上的一個框架,受到 C 語言描述硬體的侷限性(當然 HLS 比 Verilog 的開發效率確實高多了)。理想的硬體描述語言,大概不會是 C 語言吧。

ClickNP 使用 channel 在 elements 間通訊,來源:[5]
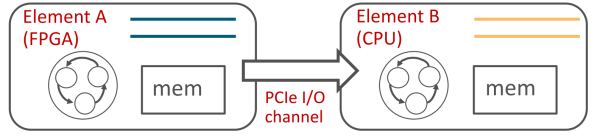
ClickNP 使用 channel 在 FPGA 和 CPU 間通訊,來源:[5]
低延遲的流式處理,需要最多的地方就是通訊。
然而 CPU 由於並行性的限制和作業系統的排程,做通訊效率不高,延遲也不穩定。
此外,通訊就必然涉及到排程和仲裁,CPU 由於單核效能的侷限和核間通訊的低效,排程、仲裁效能受限,硬體則很適合做這種重複工作。因此我的博士研究把 FPGA 定義為通訊的「大管家」,不管是伺服器跟伺服器之間的通訊,虛擬機器跟虛擬機器之間的通訊,程序跟程序之間的通訊,CPU 跟儲存裝置之間的通訊,都可以用 FPGA 來加速。
成也蕭何,敗也蕭何。缺少指令同時是 FPGA 的優勢和軟肋。
每做一點不同的事情,就要佔用一定的 FPGA 邏輯資源。如果要做的事情複雜、重複性不強,就會佔用大量的邏輯資源,其中的大部分處於閒置狀態。這時就不如用馮·諾依曼結構的處理器。
資料中心裡的很多工有很強的區域性性和重複性:一部分是虛擬化平臺需要做的網路和儲存,這些都屬於通訊;另一部分是客戶計算任務裡的,比如機器學習、加密解密。
首先把 FPGA 用於它最擅長的通訊,日後也許也會像 AWS 那樣把 FPGA 作為計算加速卡租給客戶。
不管通訊還是機器學習、加密解密,演算法都是很複雜的,如果試圖用 FPGA 完全取代 CPU,勢必會帶來 FPGA 邏輯資源極大的浪費,也會提高 FPGA 程式的開發成本。更實用的做法是FPGA 和 CPU 協同工作,區域性性和重複性強的歸 FPGA,複雜的歸 CPU。
當我們用 FPGA 加速了 Bing 搜尋、深度學習等越來越多的服務;當網路虛擬化、儲存虛擬化等基礎元件的資料平面被 FPGA 把持;當 FPGA 組成的「資料中心加速平面」成為網路和伺服器之間的天塹……似乎有種感覺,FPGA 將掌控全域性,CPU 上的計算任務反而變得碎片化,受 FPGA 的驅使。以往我們是 CPU 為主,把重複的計算任務解除安裝(offload)到 FPGA 上;以後會不會變成 FPGA 為主,把複雜的計算任務解除安裝到 CPU 上呢?隨著 Xeon + FPGA 的問世,古老的 SoC 會不會在資料中心煥發新生?
「跨越記憶體牆,走向可程式設計世界」(Across the memory wall and reach a fully programmable world.)
參考文獻:
[1] Large-Scale Reconfigurable Computing in a Microsoft Datacenter https://www.microsoft.com/en-us/research/wp-content/uploads/2014/06/HC26.12.520-Recon-Fabric-Pulnam-Microsoft-Catapult.pdf
[2] A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services, ISCA'14 https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/Catapult_ISCA_2014.pdf
[3] Microsoft Has a Whole New Kind of Computer Chip—and It’ll Change Everything
[4] A Cloud-Scale Acceleration Architecture, MICRO'16 https://www.microsoft.com/en-us/research/wp-content/uploads/2016/10/Cloud-Scale-Acceleration-Architecture.pdf
[5] ClickNP: Highly Flexible and High-performance Network Processing with Reconfigurable Hardware - Microsoft Research
[6] Daniel Firestone, SmartNIC: Accelerating Azure's Network with. FPGAs on OCS servers.
作者介紹:
李博傑,中國科技大學微軟亞洲研究院 博士在讀
相關推薦
FPGA,你為什麼這麼牛?
最近幾年,FPGA這個概念越來越多地出現。 例如,比特幣挖礦,就有使用基於FPGA的礦機。還有,之前微軟表示,將在資料中心裡,使用FPGA“代替”CPU,等等。 其實,對於專業人士來說,FPGA並不陌生,它一直都被廣泛使用。但是,大部分人還不是太瞭解它,對它有很
源碼大招:不服來戰!擼這些完整項目,你不牛逼都難!
fab 直流電機 通過 too 聚合 學習 自定義 eee 光照 經常有人問我有沒有什麽項目代碼,我回復說去 Github 找,但是還是好多人不知道如何找到那些比較好的項目。 今天花了點時間找了些安卓的項目,覺得還是不錯的,幾乎就是自己生活常用的一些 app ,如果你是
要成為一個牛逼程式猿,你要勇於嘗試這10種姿勢
很多開發者會認為要想成為一個牛逼程式設計師所需要做的事情一定都是與程式設計技能相關的,不過這種想法卻是完全錯誤的!優秀的程式碼是很好,但要想得到更好的工作,獲得更高的報酬則需要讓更多的人知道你是誰。換句話說,你需要做的還有您想不到的,成為牛逼程式設計師的10個姿勢如下: (此文來自Andrew
Ctrl+H這麼多作用,你知道幾個?
很多人都知道Ctrl+H是【查詢和替換】的快捷操作,但是你真的瞭解Ctrl+H嗎? 它的特異功能可不僅僅於此喲! 下面就和大家分享一些Ctrl+H的妙用!看看你知道幾個? 1.多個工作表替換 當我們需要同時替換掉同一個工作薄中的多個工作表的指定內容時,可以這樣做:Ctrl+H開啟任何一個工作表【查詢和
阿里P7大牛整理2的0個非常有用的Java程式片段,你知道幾個呢
1、字串有整型的相互轉換 String a = String.valueOf(2); //integer to numeric string int i = Integer.parseInt(a); //numeric string to an int 2、向檔案
學Python想要達到月薪2W的高度,你得這麼學!
“` 現在大家都在學Python。如何才能更快速的學好Python,學Python過程中有哪些坑?今天我們來看看一位自學者的經驗分享。 1、python入門基礎 這些都是基礎,基本概念必須清楚! 學習Python需要掌握如下基礎知識以及相關技能。
寫了這麼多年程式碼,你真的瞭解設計模式麼?
昨天和同事聊到最近他要做的一個培訓,大概的課程是這樣的: 第一天: 上午:面向物件原則(OO+SOLID ) 下午:設計模式(Design Pattern) 第二天: 上午:簡單設計(SimpleDesign) 下午:重構到模式(Refactor to D
程式設計師,你為什麼值這麼多錢?
聽說一段時間不加薪,人就會開始思考起和工資有關的問題。消費水平又提升了,能力也進步了,經驗也更多了,怎麼還沒漲工資呢? 近兩年,有了點餘錢就開始考慮起投資來,比如:投資股票首先需要判斷的就是關於公司價值和價格的關係。回到個人身上,似乎工資也就是個人價值在市場上的一個價格
區塊鏈數字貨幣火石AI自動炒幣機器人,這麼牛x的機器人您有了解嗎?
數字貨幣交易時代,高額的利益流動吸引了不少人來加入這場逐鹿之戰。但是面對複雜的交易規則,許多幣圈新手紛紛下馬。我們不得不想到,如果能有一個“機器人”,自動追蹤牛市、分析幣種、通過完備的計算系統幫我們盈利就好了。 真的有這樣的好事?有。這就是結合智慧交易技術而生的
IG奪冠!王思聰都這麼努力,你還不瞭解下QbaoNetwork嗎?
前幾天,小Q 的朋友圈充斥著狂歡節一般的氣氛,被IG 刷屏了。 一半的人在為IG 加油、歡呼,“IG 衝鴨”、“IG 冠軍”、“IG 牛批”…… 另一半人在問IG 是誰~ 據小Q 瞭解,IG 是由“國民老公王思聰”一手打造的電競戰隊,成立於2011年。在2018
分享大牛們的刷題經驗——比你聰明的人還在拼命努力,你有什麼資格浪費時間
這兩年目睹了師兄們找工作時的“悲壯”,壓力很大。IT公司的筆試題確實很難,一個半小時要完成3道題,實在是力不從心。師兄們面試回來,都在說被面試官吊打,真正應驗了那句話:基礎不牢,地動山搖!看著身邊的人,簽了騰訊、簽了百度、簽了小米、簽了京東,簽了美團,拿了華為的sp,心
python 實戰爬蟲專案,學會這個32個專案天下無敵 python 爬蟲------32個專案(學會了你就牛了哈哈)
python 爬蟲------32個專案(學會了你就牛了哈哈) 32個Python爬蟲專案讓你一次吃到撐 今天為大家整理了32個Python爬蟲專案。整理的原因是,爬蟲入門簡單快速,也非常適合新入門的小夥伴培養信心。所有連結指向G
寫了這麼多年程式碼,你真的瞭解Java各種“鎖”嗎?
推薦視訊連結 前言 Java提供了種類豐富的鎖,每種鎖因其特性的不同,在適當的場景下能夠展現出非常高的效率。本文旨在對鎖相關原始碼(本文中的原始碼來自JDK 8)、使用場景進行舉例,為讀者介紹主流鎖的知識點,以及不同的鎖的適用場景。 Java中往往是按照是否
技術牛人在阿里內網的公開信:“王堅,你為什麼要放棄”
王堅,你為什麼要放棄 中文不佳,全用英文寫又無法讓更多的同學瞭解我的心路旅程,所以請各位原諒我蹩腳的中文。 *一個簡單的道理:一塊2TB桌面級硬碟今天的價格約為700元,相同大小的企業級硬碟一塊今天的要價仍然超過1,500元,這兩個硬碟最大的差別 是RVI震動率的設定(因此
轉載:史上最全|阿里那些牛逼帶閃電的開源工具,你知道幾個?
開源展示了人類共同協作,成果分享的魅力,每一次技術發展都是站在巨人的肩膀上,技術諸多創新和發展往往就是基於開源發展起來的,沒有任何一家網路公司可以不使用開源技術,僅靠自身技術而發展起來。阿里巴巴各個團隊都是發自內心地將踩過的坑和總結的經驗融入到開源專案中,供業界所有人使用,希望幫助他人解決問題。 雲棲社
【chenleismr的專欄】在技術浪潮之巔,你才會有一覽眾山小的視野和深刻,人生感悟得以昇華。人生最重要的不僅是努力,還有方向。壓力不是有人比你努力,而是比你牛叉幾倍的人依然比你努力。即使看不到未來和希望,也依然相信夢想!!
在技術浪潮之巔,你才會有一覽眾山小的視野和深刻,人生感悟得以昇華。人生最重要的不僅是努力,還有方向。壓力不是有人比你努力,而是比你牛叉幾倍的人依然比你努力。即使看不到未來和希望,也依然相信夢想!!...
大牛都是這樣寫測試用例的,你get到了嘛?
1. 用於語句覆蓋的基路徑法 基路徑法保證設計出的測試用例,使程式的每一個可執行語句至少執行一次,即實現語句覆蓋。基路徑法是理論與應用脫節的典型,基本上沒有應用價值,讀者稍作了解即可,不必理解和掌握。 基路徑法步驟如下: 1)畫出程式的控制流圖 控制流圖是描述程式控制流的一種圖示方法
FPGA的製造商大佬,你知道多少?
FPGA的製造商大佬,你知道多少? FPGA(Field Programmable Gate Array)中文翻譯為現場可程式設計邏輯閘陣列,是目前全世界應用最廣泛數字系統的主流平臺之一,其市場前景誘人,但是門檻之高在晶片行業裡無出其右,生產商目前有4大巨頭,而且都是美國。下面分別介紹:
維護了這麼久的伺服器,你真的認識 Web 快取體系?
作者簡介: 趙舜東 中國SaltStack使用者組發起人 江湖人稱:趙班長,曾在武警某部負責指揮自動化的架構和運維工作,2008年退役後一直從事網際網路運維工作,歷任運維工程師、運維經理、運維架構師、運維總監。《SaltStack技術入門與實戰》作者,《運維知識體系》作者,GOPS金牌講師,Ex
做了這麼久的 DBA,你真的認識 MySQL 資料安全體系?
作者介紹: 強昌金 去哪兒網 高階DBA 2015年加入去哪兒,擔任MySQL DBA,主要負責去哪兒資料庫管理平臺的開發、MySQL和Redis的運維。在資料庫方面,具有豐富的資料庫運維、效能優化經驗。 給大家分享下有關MySQL在資料安全的話題,怎麼通過一些配置來保證資料安全以及保證資料的