
深度影象的獲取原理
在計算機視覺系統中,三維場景資訊為影象分割、目標檢測、物體跟蹤等各類計算機視覺應用提供了更多的可能性,而深度影象(Depth map)作為一種普遍的三維場景資訊表達方式得到了廣泛的應用。深度影象的每個畫素點的灰度值可用於表徵場景中某一點距離攝像機的遠近。
獲取深度影象的方法可以分為兩類:被動測距感測和主動深度感測。
In short:深度影象的畫素值反映場景中物體到相機的距離,獲取深度影象的方法=被動測距感測+主動深度感測。
被動測距感測
被動測距感測中最常用的方法是雙目立體視覺[1,2],該方法通過兩個相隔一定距離的攝像機同時獲取同一場景的兩幅影象,通過立體匹配演算法找到兩幅影象中對應的畫素點,隨後根據三角原理計算出時差資訊,而視差資訊通過轉換可用於表徵場景中物體的深度資訊。基於立體匹配演算法,還可通過拍攝同一場景下不同角度的一組影象來獲得該場景的深度影象。除此之外,場景深度資訊還可以通過對影象的光度特徵[3]、明暗特徵[4]等特徵進行分析間接估算得到。

上圖展示了Middlebury Stereo Dataset中Tsukuba場景的彩色影象、視差實際值與用Graph cuts演算法得到的立體匹配誤差估計結果,該視差影象可以用於表徵場景中物體的三維資訊。
可以看到,通過立體匹配演算法得到的視差圖雖然可以得到場景的大致三維資訊,但是部分畫素點的時差存在較大誤差。雙目立體視覺獲得視差影象的方法受限於基線長度以及左右影象間畫素點的匹配精確度,其所獲得的視差影象的範圍與精度存在一定的限制。
In short, 常用於深度影象增強領域的測試資料集Middlebury Stereo Dataset屬於被動測距感測;被動測距感測=兩個相隔一定距離的相機獲得兩幅影象+立體匹配+三角原理計算視差(disparity)
主動測距感測
主動測距感測相比較於被動測距感測最明顯的特徵是:裝置本身需要發射能量來完成深度資訊的採集。這也就保證了深度影象的獲取獨立於彩色影象的獲取。近年來,主動深度感測在市面上的應用愈加豐富。主動深度感測的方法主要包括了TOF(Time of Flight)、結構光、鐳射掃描等。
TOF相機
TOF相機獲取深度影象的原理是:通過對目標場景發射連續的近紅外脈衝,然後用感測器接收由物體反射回的光脈衝。通過比較發射光脈衝與經過物體反射的光脈衝的相位差,可以推算得到光脈衝之間的傳輸延遲進而得到物體相對於發射器的距離,最終得到一幅深度影象。
TOF相機所獲得的深度影象有以下的缺陷:
1. 深度影象的解析度遠不及彩色影象的解析度
2. 深度影象的深度值受到顯著的噪聲干擾
3. 深度影象在物體的邊緣處的深度值易出現誤差,而這通常是由於一個畫素點所對應的場景涵蓋了不同的物體表面所引起的。
除此之外,TOF相機的通常價格不菲。

結構光與Kinect
結構光是具有特定模式的光,其具有例如點、線、面等模式圖案。
基於結構光的深度影象獲取原理是:將結構光投射至場景,並由影象感測器捕獲相應的帶有結構光的圖案。
由於結構光的模式圖案會因為物體的形狀發生變形,因此通過模式影象在捕捉得到的影象中的位置以及形變程度利用三角原理計算即可得到場景中各點
的深度資訊。
結構光測量技術提供了高精度並且快速的三維資訊,其在汽車、遊戲、醫療等領域均已經得到了廣泛的應用。
基於結構光的思想,微軟公司推出了一款低價優質的結合彩色影象與深度影象的體感裝置Kinect,該裝置被應用於如人機互動(Xbox系列遊戲機)、三維場景重建、機器視覺等諸多領域。 
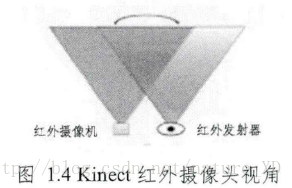
微軟公司的Kinect有三個鏡頭,除了獲取RGB彩色影象的攝像機之外,左右兩邊的鏡頭分別是紅外線發射器和紅外線CMOS攝像機,這兩個鏡頭共同構成了Kinect的深度感測裝置,其投影和接收區域相互重疊,如下圖所示。
Kinect採用了一種名為光編碼(Light Coding)的技術,不同於傳統的結構光方法投射一幅二維模式圖案的方法,Kinect的光編碼的紅外線發射機發射的是一個具有三維縱深的“立體編碼”。光編碼的光源被稱為鐳射散斑,其形成原理是鐳射照射到粗糙物體或穿透毛玻璃後得到了隨機的衍射斑點。鐳射散斑具有高度的三維空間隨機性。當完成一次光源標定後,整個空間的散斑圖案都被記錄,因此,當物體放進該空間後,只需得知物體表面的散斑圖案,就可以知道該物體所處的位置,進而獲取該場景的深度影象。紅外攝像機捕獲的紅外散斑影象如下圖所示,其中左側的圖片展現了右側圖片中框中的細節。

Kinect低廉的價格與實時高解析度的深度影象捕捉特性使得其在消費電子領域得到了迅猛發展,然而Kinect的有效測距範圍僅為800毫米到4000毫米,對處在測距範圍之外的物體,Kinect並不能保證準確深度值的獲取。Kinect捕獲的深度影象存在深度缺失的區域,其體現為深度值為零,該區域意味著Kinect無法獲得該區域的深度值。而除此之外,其深度影象還存在著深度影象邊緣與彩色影象邊緣不對應、深度噪聲等問題。Kinect所捕獲的彩色影象與深度影象如下圖所示。

Kinect所捕獲的深度影象產生深度缺失區域的原因多種多樣。除了受限於測距範圍,一個重要的原因是目標空間中的一個物體遮擋了其背後區域。這種情況導致了紅外發射器所投射的圖案無法照射到背後區域上,而背後區域卻有可能被處在另一個視角的紅外攝像機捕捉到,然而該區域並不存在散斑圖案,該區域的深度資訊也就無法被獲得。【Oops,原來遮擋是這樣導致了深度值缺失,作者果然厲害,兩句話讓人茅塞頓開!】物體表面的材質同樣會影響Kinect深度影象的獲取。當材質為光滑的平面時,紅外投射散斑光束在物體表面產生鏡面反射,紅外攝像機無法捕捉該物體反射的紅外光,因此也就無法捕獲到該表面的深度;當材質為吸光材料時,紅外投射散斑被該表面所吸收而不存在反射光,紅外攝像機同樣無法捕捉到該表面的深度資訊。【材質對深度缺失的影響,分析到位】除此之外,Kinect所捕獲的深度影象存在的與彩色影象邊緣不一致的問題主要是由彩色攝像機與紅外攝像機的光學畸變引起的。
鐳射雷達
鐳射雷達測距技術通過鐳射掃描的方式得到場景的三維資訊。其基本原理是按照一定時間間隔向空間發射鐳射,並記錄各個掃描點的訊號從鐳射雷達到被測場景中的物體,隨後又經過物體反射回到鐳射雷達的相隔時間,據此推算出物體表面與鐳射雷達之間的距離。
鐳射雷達由於其測距範圍廣、測量精度高的特性被廣泛地用於室外三維空間感知的人工智慧系統中,例如自主車的避障導航、三維場景重建等應用中。下圖展示的是鐳射雷達Velodyne HDL-64E在自主車中的應用,該鐳射雷達能夠獲取360°水平方向上的全景三維資訊,其每秒能夠輸出超過130萬個掃描點的資料。全向鐳射雷達曾在美國舉辦的DARPA挑戰賽中被許多隊伍所採用,其也成為了自主行駛車輛的標準配置。

相關推薦
由RGB影象和深度影象獲取點雲
#include <iostream> #include <fstream> #include <string> #include <pcl/io/pcd_io.h> #include <pcl/io/ply_io.h> #include
RGB和深度影象獲取最終版
此處在原部落格基礎上進行了改正,調整了深度影象的歸一化處理方法,最終顯示減少了空洞 #include <opencv2\opencv.hpp> #include<iostream> #include <Windows.h> #inclu
深度影象的獲取原理
在計算機視覺系統中,三維場景資訊為影象分割、目標檢測、物體跟蹤等各類計算機視覺應用提供了更多的可能性,而深度影象(Depth map)作為一種普遍的三維場景資訊表達方式得到了廣泛的應用。深度影象的每個畫素點的灰度值可用於表徵場景中某一點距離攝像機的遠近。 獲取深度影象的
深度圖像的獲取原理
dataset byte 描述 其他 相關 最大 term jsb 等級 RGB-D(深度圖像) 深度圖像 = 普通的RGB三通道彩色圖像 + Depth Map 在3D計算機圖形中,Depth Map(深度圖)是包
ROS使用openni獲取Kinect彩色影象和深度影象
本實驗使用Ubuntu14.04的64bit版本,ROS使用Indigo版本,影象獲取使用OpenNI1(因為OpenNI2中未找到彩色影象和深度影象對齊功能,臺灣的一代大神Heresy已經實現這一功能,但是我更喜歡OpenNI1官方對齊方法),影象處理使用OpenCV2
《深度學習:原理與應用實踐》中文版PDF
應用 href 書籍 nag tex 原理 圖片 water images 下載:https://pan.baidu.com/s/1YljEeog_D0_RUHjV6hxGQg 《深度學習:原理與應用實踐》中文版PDF,帶目錄和書簽; 經典書籍,講解詳細; 如圖: 《深度學
分享《深入淺出深度學習:原理剖析與python實踐》PDF+源代碼
img color fff png aid pdf ffffff pytho 下載 下載:https://pan.baidu.com/s/1H4N0W5sPOE7YlK0KyC7TZQ 更多資料分享:http://blog.51cto.com/3215120 《深入淺出深度
Qt影象合成原理
Qt影象合成原理 若對C++語法不熟悉,建議參閱《C++語法詳解》一書,電子工業出版社出版,該書語法示例短小精悍,對查閱C++知識點相當方便,並對語法原理進行了透徹、深入詳細的講解。 需要用到的QPainter類中的函式如下 CompositionMode compositi
DeepLearning(深度學習)原理與實現
經過三年的狂刷理論,覺得是時候停下來做些有用的東西了,因此決定開博把他們寫下來,一是為了整理學過的理論,二是監督自己並和大家分享。先從DeepLearning談起吧,因為這個有一定的實用性(大家口頭傳的“和錢靠的很近”大笑),國內各個大牛也都談了不少,我儘量從其他方面解釋一下。
深度影象理解
深度學習基礎知識 深度學習的基礎模組
iOS影象顯示原理
析構圖顯示: 影象顯示各元件分工: ~ CPU:計算檢視frame,圖片解碼,繪製紋理交給GPU。 ~ GPU:紋理混合,頂點變換,渲染到幀緩衝區。 ~ 時鐘訊號:垂直同步訊號V-Sync / 水平同步訊號H-Sync。 ~ iOS裝置雙緩衝
神經網路和深度學習基本原理
這是看到的一篇對神經網路的講解的文章,我覺得寫得很好,也仔細學習了學習,最近我可能也得用這個東西,現在確實是很火啊,也很實用。 神經網路和深度學習 神經網路:一種可以通過觀測資料使計算機學習的仿生語言範例 深度學習:一組強大的神經網路學習技術
《深入淺出深度學習:原理剖析與python實踐》pdf 下載
深入淺出深度學習:原理剖析與Python實踐》介紹了深度學習相關的原理與應用,全書共分為三大部分,第一部分主要回顧了深度學習的發展歷史,以及Theano的使用;第二部分詳細講解了與深度學習相關的基礎知識,包括線性代數、概率論、概率圖模型、機器學習和至優化演算法;在第三部分中,針對若干核心的深度
分享《深度學習:原理與應用實踐》+PDF+張重生
ofo 51cto 經典 mar src mage 詳細 深度學習 目錄 下載:https://pan.baidu.com/s/1LmlYGbleDhkDAuqoZ2XjAQ更多資料分享:http://blog.51cto.com/14087171 《深度學習:原理與應用實
影象優化原理
我們都喜歡有圖片的網頁,圖片很美好,很有趣,同時它涵蓋了豐富的資訊。所以,在載入網頁時,大部分流量被影象資源所佔據(平均60%,資料可能不準確)。 影象資源不只佔用網路資源,它也會佔用網頁中大量的視覺空間。所以影象渲染的速度會直接影響使用者體驗。影象優化其實就是最大限度地減少影象的位元組數,從而最大化地縮減
【進階3-4期】深度解析bind原理、使用場景及模擬實現
本週的主題是this全面解析,本計劃一共28期,每期重點攻克一個面試重難點,如果你還不瞭解本進階計劃,文末點選檢視全部文章。 如果覺得本系列不錯,歡迎點贊、評論、轉發,您的支援就是我堅持的最大動力。 bind() bind() 方法會建立一個新函式,當這個新函式被呼叫時,它的 this 值是傳
【進階3-5期】深度解析 new 原理及模擬實現
本週的主題是this全面解析,本計劃一共28期,每期重點攻克一個面試重難點,如果你還不瞭解本進階計劃,文末點選檢視全部文章。 如果覺得本系列不錯,歡迎點贊、評論、轉發,您的支援就是我堅持的最大動力。 介紹下定義 new 運算子建立一個使用者定義的物件型別的例項或具有建構函式的內建物件的例項。
【進階3-4期】深度解析bind原理、使用場景及模擬實現(轉)
這是我在公眾號(高階前端進階)看到的文章,現在做筆記 https://github.com/yygmind/blog/issues/23 bind() bind() 方法會建立一個新函式,當這個新函式被呼叫時,它的 this 值是傳遞給 bind(
深度-影象風格變換【二】
深度卷積神經網路影象風格變換 Taylor Guo, 2017年4月23日 星期日 - 4月27日星期四 摘要 本文介紹了深度學習方法的影象風格轉換,處理各種各樣的影象內容,保持高保真的參考風格變換。我們的方法構建於最近繪畫風格變換基礎上,用神經網路的不同網
【進階3-5期】深度解析 new 原理及模擬實現(轉)
這是我在公眾號(高階前端進階)看到的文章,現在做筆記 https://github.com/yygmind/blog/issues/24 new 運算子建立一個使用者定義的物件型別的例項或具有建構函式的內建物件的例項。 ——(來自於MDN) 舉個例子: function Car(color) {