
Spark Streaming重複消費,多次輸出問題剖析與解決方案
1,Exactly once 事務
什麼事Exactly once 事務?
資料僅處理一次並且僅輸出一次,這樣才是完整的事務處理。
Spark在執行出錯時不能保證輸出也是事務級別的。在Task執行一半的時候出錯了,雖然在語義上做了事務處理,資料僅被處理一次,但是如果是輸出到資料庫中,那有空能將結果多次儲存到資料庫中。Spark在任務失敗時會進行重試,這樣會導致結果多次儲存到資料庫中。
如下圖,當執行在Executor上的Receiver接收到資料通過BlockManager寫入記憶體和磁碟,或者通過WAL機制寫記錄日誌,然後把metedata資訊彙報給Driver。在Driver端定期進行checkpoint
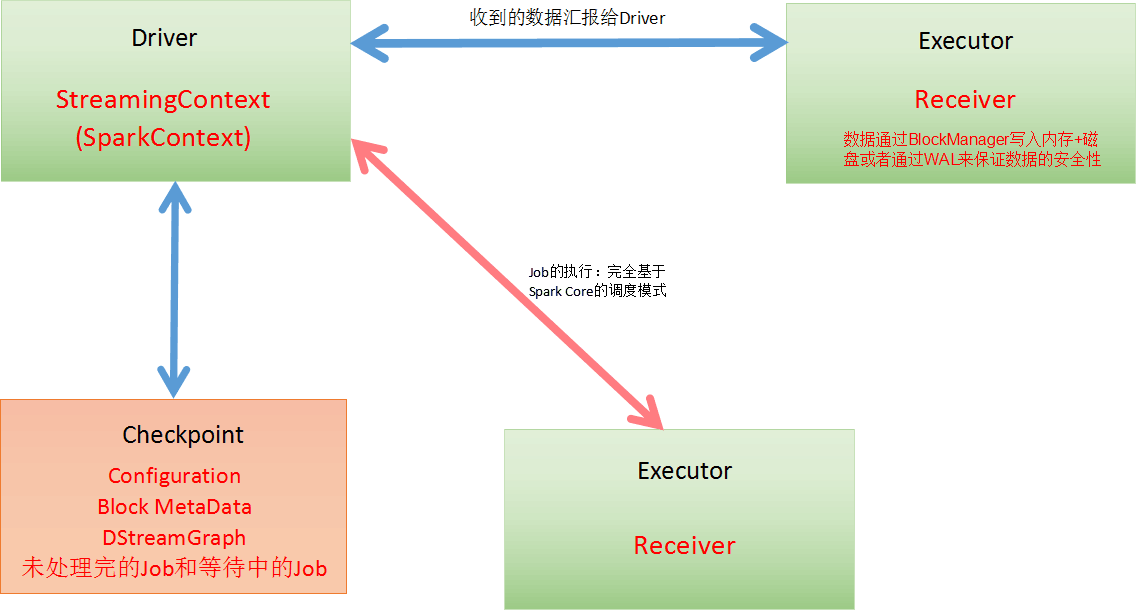
Exactly once 事務的處理:
1,資料零丟失:必須有可靠的資料來源和可靠的Receiver,且整個應用程式的metadata必須進行checkpoint,且通過WAL來保證資料安全。
我們以資料來自Kafka為例,執行在Executor上的Receiver在接收到來自Kafka的資料時會向Kafka傳送ACK確認收到資訊並讀取下一條資訊,kafka會updateOffset來記錄Receiver接收到的偏移,這種方式保證了在Executor資料零丟失。
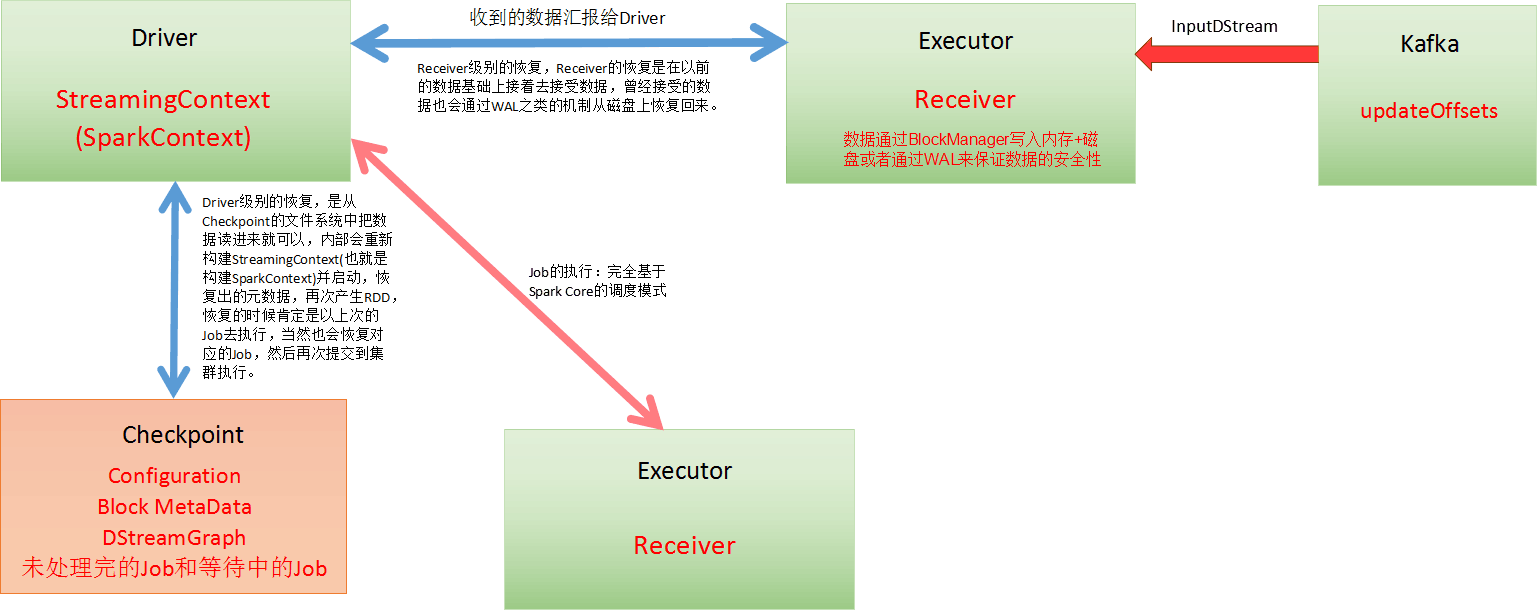
在Driver端,定期進行checkpoint操作,出錯時從Checkpoint
那麼資料可能丟失的地方有哪些呢和相應的解決方式?
在Receiver收到資料且通過Driver的排程Executor開始計算資料的時候,如果Driver突然奔潰,則此時Executor會被殺死,那麼Executor中的資料就會丟失(如果沒有進行WAL的操作)。
解決方式:此時就必須通過例如WAL的方式,讓所有的資料都通過例如HDFS的方式首先進行安全性容錯處理。此時如果Executor
這種方式的弊端是通過WAL的方式會極大額損傷SparkStreaming中Receivers接收資料的效能。
資料重複讀取的情況:
在Receiver收到資料儲存到HDFS等持久化引擎但是沒有來得及進行updateOffsets(以Kafka為例),此時Receiver崩潰後重新啟動就會通過管理Kafka的Zookeeper中元資料再次重複讀取資料,但是此時SparkStreaming認為是成功的,但是kafka認為是失敗的(因為沒有更新offset到ZooKeeper中),此時就會導致資料重新消費的情況。
解決方式:以Receiver基於ZooKeeper的方式,當讀取資料時去訪問Kafka的元資料資訊,在處理程式碼中例如foreachRDD或transform時,將資訊寫入到記憶體資料庫中(memorySet),在計算時讀取記憶體資料庫資訊,判斷是否已處理過,如果以處理過則跳過計算。這些元資料資訊可以儲存到記憶體資料結構或者memsql,sqllite中。
如果通過Kafka作為資料來源的話,Kafka中有資料,然後Receiver接收的時候又會有資料副本,這個時候其實是儲存資源的浪費。
Spark在1.3的時候為了避免WAL的效能損失和實現Exactly Once而提供了Kafka Direct API,把Kafka作為檔案儲存系統。此時兼具有流的優勢和檔案系統的優勢,至此Spark Streaming+Kafka就構建了完美的流處理世界(1,資料不需要拷貝副本;2,不需要WAL對效能的損耗;3,Kafka使用ZeroCopy比HDFS更高效)。所有的Executors通過Kafka API直接訊息資料,直接管理Offset,所以也不會重複消費資料。
2,輸出不重複
關於Spark Streaming資料輸出多次重寫及其解決方案:
1,為什麼會有這個問題,因為Spark Streaming在計算的時候基於Spark Core天生會做以下事情導致Spark Streaming的結果(部分)重複輸出。Task重試,慢任務推測,Stage重試,Job重試。
2,具體解決方案:
設定spark.task.maxFailures次數為1,這樣就不會有Task重試了。設定spark.speculation為關閉狀態,就不會有慢任務推測了,因為慢任務推測非常消耗效能,所以關閉後可以顯著提高Spark Streaming處理效能。
Spark Streaming On Kafka的話,Job失敗後可以設定Kafka的引數auto.offset.reset為largest方式。
最後再次強調可以通過transform和foreachRDD基於業務邏輯程式碼進行邏輯控制來實現資料不重複消費和輸出不重複。這兩個方法類似於Spark Streaming的後門,可以做任意想象的控制操作。
相關推薦
Spark Streaming重複消費,多次輸出問題剖析與解決方案
1,Exactly once 事務什麼事Exactly once 事務?資料僅處理一次並且僅輸出一次,這樣才是完整的事務處理。Spark在執行出錯時不能保證輸出也是事務級別的。在Task執行一半的時候出錯了,雖然在語義上做了事務處理,資料僅被處理一次,但是如果是輸出到資料庫中
react-navigation重複點選多次跳轉的解決方案
廢話 在[email protected]版本之後,官方廢棄了之前的導航Navigator,用react-navigation 替代 react-natvigation於2017年1月份開源,在3個月時間內,GitHub上star數達4000+,備
animationend和transitionend多次執行的問題解決方案
對於animationend事件來說的話,如果我們在外層新增這個事件監聽,如果監聽元素裡面還有動畫,則裡面元素動畫結束也會執行這個animationend事件。所以我們可以這樣做: $('.ele').on('animationend webkitAnimationEnd'
swiper函式同一個事件多次連續觸發失效解決方案
swiper 函式 如 mySwiper.slideTo(index, speed, runCallbacks);mySwiper.removeSlide(index); 等, 當點選按鈕觸發這些函式
Spark Streaming接收kafka資料,輸出到HBase
需求 Kafka + SparkStreaming + SparkSQL + HBase 輸出TOP5的排名結果 排名作為Rowkey,word和count作為Column 實現 建立kafka生產者模擬隨機生產資料 object produ
本地開發spark streaming無法消費雲主機kafka訊息
1、Kafka叢集在一個192.168.0.x網段的,而我們的生產者在叢集外,無法將訊息傳送過去 錯誤:11:21:13,936 ERROR KafkaProducer - Batch containing 11 record(s) expired due to timeout while re
解決spark streaming重複提交第三方jar包問題
背景: 由於spark streaming每次提交都需要上傳大量jar包到hdfs,為節約HDFS資源,現只存一份來解決這個問題 元件: CDH 5.13 spark2.2.x 針對cluster模
解決SpringBoot 定時計劃 quartz job 任務重複執行多次(10次)
上一篇:SpringBoot多工Quartz動態管理Scheduler,時間配置,頁面+源 設定了多個 任務,本應該是各司其職的,任務呼叫多執行緒處理任務,but這個定時任務竟然同時跑了10次???如下圖 讓我很苦惱 百度一波,懷疑是否是因為多次初始化bean導致的? debu
spark Streaming 直接消費Kafka資料,儲存到 HDFS 實戰程式設計實踐
最近在學習spark streaming 相關知識,現在總結一下 主要程式碼如下 def createStreamingContext():StreamingContext ={ val sparkConf = new SparkConf().setAppName("
Sping 定時任務 CronTrigger 重複執行 多次執行
我不知道有沒人遇到過這個問題,我是在百度和谷歌裡都沒找到相關的東西。 先說我的專案吧,定時任務主要是按時提醒客戶端該發資料了,但是在實際執行中,我發現定時任務指定的Job總是被多次執行,而且不是固定的次數,是逐步增加的。 鬱悶了好久啊,找不到方法,今天突然靈光乍現!因為我又
tomcat配置多域名站點啟動時專案重複載入多次
這兩天熊哥在配置tomcat多站點的時候遇到一個問題,目前有兩個java web專案,要求放在一個tomcat下並通過二級域名問。所以我就在server.xml增加了多個host的配置。但是配置成功後,啟動tomcat發現,專案居然被重複載入了3次。感覺很莫名,然後就go
C#中WebBrowser.DocumentCompleted事件多次調用問題解決方法
post lin ont display err 框架 center 一個 blank 關於DocumentCompleted事件,MSDN給出的解釋是在文檔加載完畢後執行,但是在我的程序中DocumentCompleted卻被多次調用,查了一下資料,大概出現了以下幾種情
iOS直播Liveroom組件,遊客,用戶多次切換登錄同一直播間,消息出現多次重復問題解決
with handle roo 遇到 format 重復 con 單例 serve byzqk 新版,加入連麥功能,直播的流程修改很多,每次登錄都需要登錄liveroom組件 期間遇到一個奇葩的問題,就是遊客登錄組件之後,切換為用戶登錄,出現im消息重復的問題,一開始以為是
jQuery事件多次繫結與解綁
jQuery事件繫結很常見,相信大家經常會用到click、focus、blur等事件,但是如果對控制元件的某個事件繫結多個方法會是怎樣的結果呢,覆蓋、累加、或其他效果?今天我就來驗證一下這個疑問並說說如何解綁。 一、jQuery事件多次繫結 <head> <sc
函式中為什麼不要有多次return以及其解決方法
函式中隨處return,是造成我們資源洩露和程式死鎖的主要根源。很多同志寫過類似的程式碼,函式中建立了和引用了多個資源,中間使用的過程中出錯了,程式return,經典的程式碼是這樣的: void fun() { Lock(mutex); mem
Spark——Streaming原始碼解析之資料的產生與匯入
此文是從思維導圖中匯出稍作調整後生成的,思維腦圖對程式碼瀏覽支援不是很好,為了更好閱讀體驗,文中涉及到的原始碼都是刪除掉不必要的程式碼後的虛擬碼,如需獲取更好閱讀體驗可下載腦圖配合閱讀: 此博文共分為四個部分: DAG定義 Job動態生成 資料的產生與匯入 容錯 資料的產生與匯入主要分為以下五個部分
spark 大型專案實戰(五十八):資料傾斜解決方案之sample取樣傾斜key進行兩次join
當採用隨機數和擴容表進行join解決資料傾斜的時候,就代表著,你的之前的資料傾斜的解決方案,都沒法使用。 這個方案是沒辦法徹底解決資料傾斜的,更多的,是一種對資料傾斜的緩解。 原理,其實在上一講,已經帶出來了。 步驟: 1、選擇一個RDD,要用flatM
Spark Streaming 流計算優化記錄(5)-分割槽與記憶體的優化
8. 不一定非得每秒處理一次 由於Spark Streaming的原理是micro batch, 因此當batch積累到一定數量時再發放到叢集中計算, 這樣的資料吞吐量會更大些. 這需要在StreamingContext中設定Duration引數. 我們試著把Duration調成兩秒, 這樣S
標頭檔案被多次呼叫時的解決辦法
微控制器程式設計中有時會出現標頭檔案多次呼叫,編譯時導致結構體函式被重複定義的錯誤以STM3210X為例當頭檔案stm32f10x.h被多次呼叫時,會出現函式體被多次定義的錯誤,此時在標頭檔案中新增#ifndef __STM32F10X_H#define __STM32F10
Kafka結合Spark-streaming 的兩種連線方式(AWL與直連)
kafka結合spark-streaming的用法及說明之前部落格有些,這裡就不贅述了。 這篇文章說下他們結合使用的兩種連線方式。(AWL與直連) 先看一張圖: 這是kafka與streaming結合的基本方式,如圖spark叢集中的 worker節點中 exeutor