
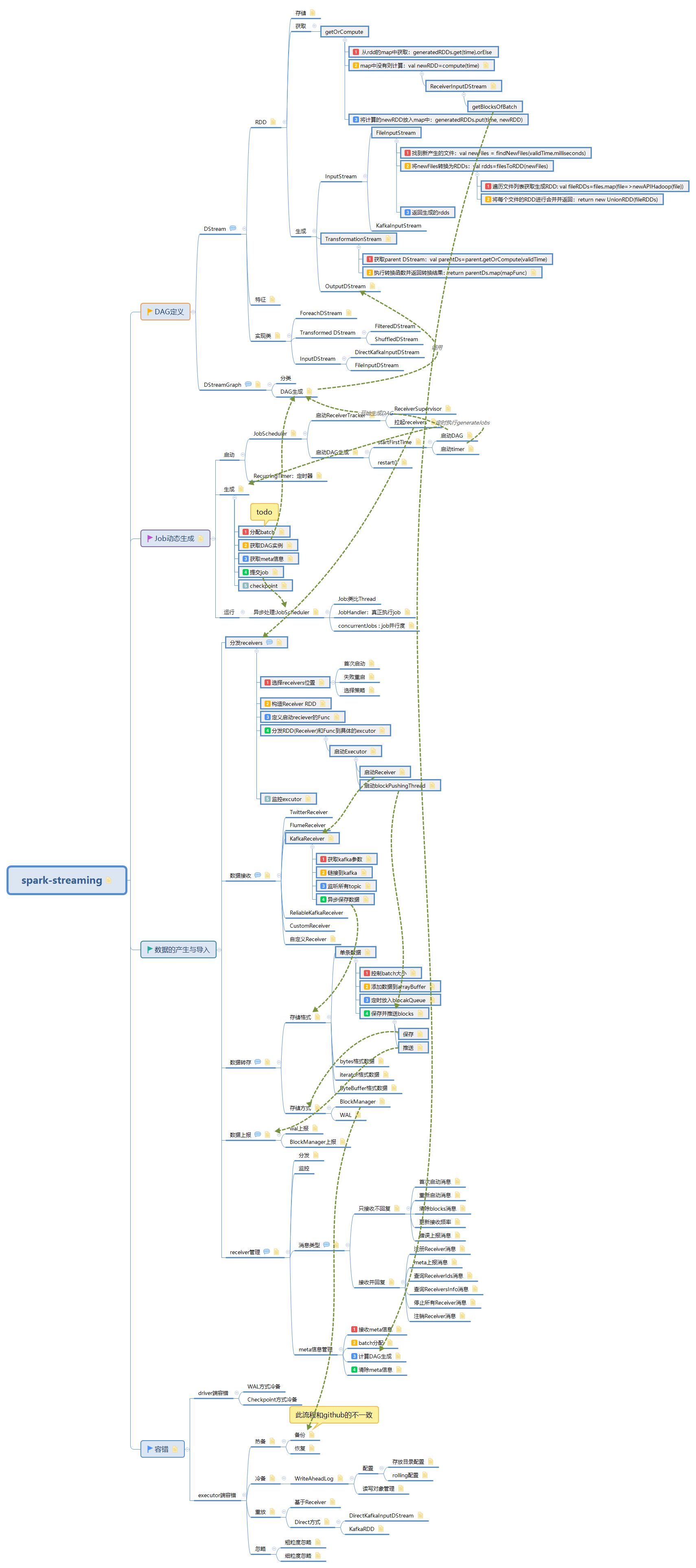
Spark——Streaming原始碼解析之資料的產生與匯入
此文是從思維導圖中匯出稍作調整後生成的,思維腦圖對程式碼瀏覽支援不是很好,為了更好閱讀體驗,文中涉及到的原始碼都是刪除掉不必要的程式碼後的虛擬碼,如需獲取更好閱讀體驗可下載腦圖配合閱讀:
此博文共分為四個部分:




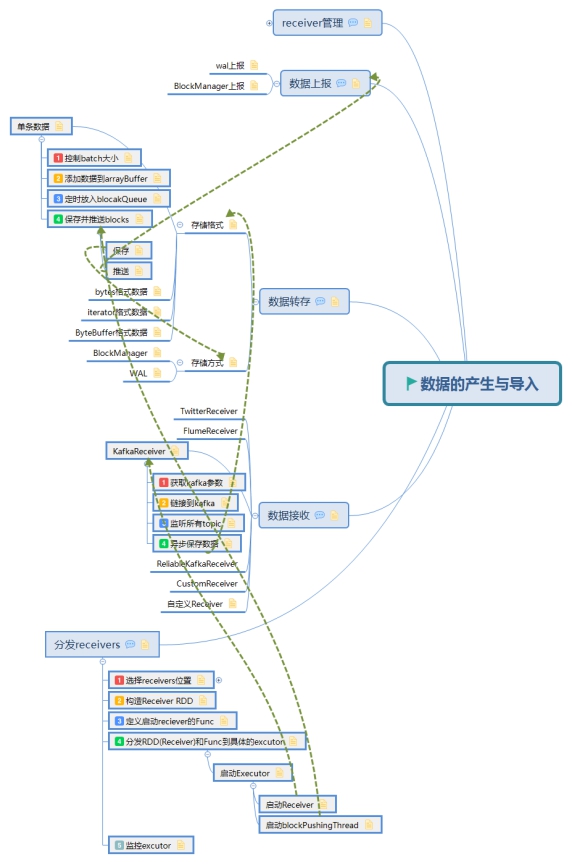
資料的產生與匯入主要分為以下五個部分
1. 分發receivers
由 Receiver 的總指揮 ReceiverTracker 分發多個 job(每個 job 有 1 個 task),到多個 executor 上分別啟動 ReceiverSupervisor 例項
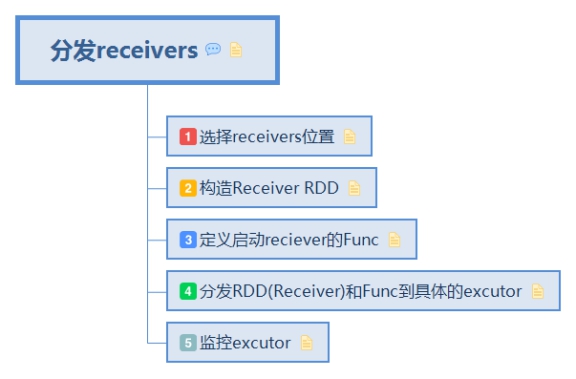
從ReceiverInputDStreams中獲取Receivers,並把他們傳送到所有的worker nodes:
class ReceiverTracker { var endpoint:RpcEndpointRef= private def **launchReceivers**(){ // DStreamGraph的屬性inputStreams val receivers=inputStreams.map{nis=> val rcvr=nis.getReceiver() // rcvr是對kafka,socket等接受資料的定義 rcvr } // 傳送到worker endpoint.send(StartAllReceivers(receivers)) } }
1.1. 選擇receivers位置

目的地選擇分兩種情況:初始化選擇和失敗重啟選擇
class ReceiverTracker {
// 分發目的地的計算
val schedulingPolicy=
new ReceiverSchedulingPolicy()
def receive{
// 首次啟動
case StartAllReceivers(receivers) =>
...
// 失敗重啟
case RestartReceiver(receiver)=>
...
}
}
1.1.1. 首次啟動
1. 選擇最優executors位置
2. 遍歷構造最終分發的excutor
class ReceiverTracker {
val schedulingPolicy=
new ReceiverSchedulingPolicy()
def receive{
// 首次啟動
case StartAllReceivers(receivers) =>
// 1. 選擇最優executors位置
val locations=
schedulingPolicy.scheduleReceivers(
receivers,getExecutors
)
// 2. 遍歷構造最終分發的excutor
for(receiver<- receivers){
val executors = scheduledLocations(
receiver.streamId)
startReceiver(receiver, executors)
}
// 失敗重啟
case RestartReceiver(receiver)=>
...
}
}
1.1.2. 失敗重啟
1.獲取之前的executors
2. 計算新的excutor位置
2.1 之前excutors可用,則使用之前的
2.2 之前的不可用則重新計算位置
3. 傳送給worker重啟receiver
class ReceiverTracker {
val schedulingPolicy=
new ReceiverSchedulingPolicy()
def receive{
// 首次啟動
case StartAllReceivers(receivers) =>
...
// 失敗重啟
case RestartReceiver(receiver)=>
// 1.獲取之前的executors
val oldScheduledExecutors =getStoredScheduledExecutors(
receiver.streamId
)
// 2. 計算新的excutor位置
val scheduledLocations = if (oldScheduledExecutors.nonEmpty) {
// 2.1 之前excutors可用,則使用之前的
oldScheduledExecutors
} else {
// 2.2 之前的不可用則重新計算位置
schedulingPolicy.rescheduleReceiver()
// 3. 傳送給worker重啟receiver
startReceiver(
receiver, scheduledLocations)
}
}
1.1.3. 選擇策略
策略選擇由ReceiverSchedulingPolicy實現,預設策略是輪訓(round-robin),在1.5版本之前是使用依賴 Spark Core 的 TaskScheduler 進行通用分發,
在1.5之前存在executor分發不均衡問題導致Job執行失敗:
如果某個 Task 失敗超過 spark.task.maxFailures(預設=4) 次的話,整個 Job 就會失敗。這個在長時執行的 Spark Streaming 程式裡,Executor 多失效幾次就有可能導致 Task 失敗達到上限次數了,如果某個 Task 失效一下,Spark Core 的 TaskScheduler 會將其重新部署到另一個 executor 上去重跑。但這裡的問題在於,負責重跑的 executor 可能是在下發重跑的那一刻是正在執行 Task 數較少的,但不一定能夠將 Receiver 分佈的最均衡的。
策略程式碼:
val scheduledLocations =ReceiverSchedulingPolicy.scheduleReceivers(receivers,xecutors)
val scheduledLocations =ReceiverSchedulingPolicy.rescheduleReceiver(receiver, ...)
1.2. 構造Receiver RDD
將receiver列表轉換為RDD
class ReceiverTracker {
def receive{
...
startReceiver(receiver, executors)
}
def startReceiver(
receiver: Receiver[_],
scheduledLocations: Seq[TaskLocation]){
}
}
class ReceiverTracker {
def startReceiver(
...
val receiverRDD: RDD[Receiver] =
if (scheduledLocations.isEmpty) {
**ssc.sc.makeRDD(Seq(receiver), 1)**
} else {
val preferredLocations = scheduledLocations.map(_.toString).distinct
ssc.sc.makeRDD(Seq(receiver -> preferredLocations))
}
receiverRDD.setName(s" $receiverId")
...
}
}
1.3. 定義啟動reciever的Func
將每個receiver,spark環境變數,hadoop配置檔案,檢查點路徑等資訊傳送給excutor的接收物件ReceiverSupervisorImpl
class ReceiverTracker {
def startReceiver(
...
val startReceiverFunc:
Iterator[Receiver[_]]=>Unit=
(iterator:Iterator)=>{
val receiver=iterator.next()
val supervisor=
new ReceiverSupervisoImpl(
receiver,
SparkEnv,
HadoopConf,
checkpointDir,
)
supervisor.start(),
supervisor.awaitTermination()
}
...
}
1.4. 分發RDD(Receiver)和Func到具體的excutor

將前兩部定義的rdd和fun從driver提交到excutor
class ReceiverTracker {
def startReceiver(
...
val future=ssc.sparkContext.submitJob(
receiverRDD,
startReceverFunc,
)
...
}
}
1.4.1. 啟動Executor
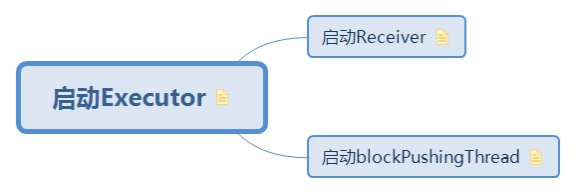
Executor的啟動在Receiver類中定義,在ReceiverSupervisor類中呼叫,在Receiver的子類中實現
excutor中共需要啟動兩個執行緒
-1. 啟動Receiver接收資料
- 2. 啟動pushingThread定時推送資料到driver
class ReceiverSupervisor(
receiver: Receiver,
conf: sparkConf
){
def start() {
onStart()
startReceiver()
}
}
1.4.1.1. 啟動Receiver
啟動Receiver,開始接收資料
class ReceiverSupervisor(
receiver: Receiver,
conf: sparkConf
){
def start() {
onStart()
startReceiver()
}
// 1. 啟動Receiver,開始接收資料
def startReceiver(){
receiverState=Started
receiver.onStart()
}
}
1.4.1.2. 啟動blockPushingThread
啟動pushTread,定時推送資訊到driver
class ReceiverSupervisor(
receiver: Receiver,
conf: sparkConf
){
def start() {
onStart()
startReceiver()
}
// 1. 啟動Receiver,開始接收資料
def startReceiver(){
receiverState=Started
receiver.onStart()
}
}
// 2. 啟動pushTread,定時推送資訊到driver
def onStart() {
registeredBlockGenerators.asScala.foreach { _.start()
}
}
}
// _.start() 的實現
class BlockGenerator{
def start(){
blockIntervalTimer.start()
blockPushingThread.start()
}
}
1.5. 監控excutor
啟動 Receiver 例項,並一直 block 住當前執行緒
在1.5版本之前,一個job包含多個task,一個task失敗次數失敗超過4次後,整個Job都會失敗,1.5版本之後一個job只包含一個task,並且添加了可重試機制,大大增加了job的活性
Spark Core 的 Task 下發時只會參考並大部分時候尊重 Spark Streaming 設定的 preferredLocation 目的地資訊,還是有一定可能該分發 Receiver 的 Job 並沒有在我們想要排程的 executor 上執行。此時,在第 1 次執行 Task 時,會首先向 ReceiverTracker 傳送 RegisterReceiver 訊息,只有得到肯定的答覆時,才真正啟動 Receiver,否則就繼續做一個空操作,導致本 Job 的狀態是成功執行已完成。當然,ReceiverTracker 也會另外調起一個 Job,來繼續嘗試 Receiver 分發……如此直到成功為止。
一個 Receiver 的分發 Job 是有可能沒有完成分發 Receiver 的目的的,所以 ReceiverTracker 會繼續再起一個 Job 來嘗試 Receiver 分發。這個機制保證了,如果一次 Receiver 如果沒有抵達預先計算好的 executor,就有機會再次進行分發,從而實現在 Spark Streaming 層面對 Receiver 所在位置更好的控制。
對 Receiver 的監控重啟機制
上面分析了每個 Receiver 都有專門的 Job 來保證分發後,我們發現這樣一來,Receiver 的失效重啟就不受 spark.task.maxFailures(預設=4) 次的限制了。
因為現在的 Receiver 重試不是在 Task 級別,而是在 Job 級別;並且 Receiver 失效後並不會導致前一次 Job 失敗,而是前一次 Job 成功、並新起一個 Job 再次進行分發。這樣一來,不管 Spark Streaming 執行多長時間,Receiver 總是保持活性的,不會隨著 executor 的丟失而導致 Receiver 死去。
// todo 阻塞,知道executor返回傳送結果
class ReceiverTracker {
def startReceiver(
...
future.onComplete {
case Success(_)=>
...
case Failure())=>
onReceiverJobFinish(receiverId)
...
}}(ThreadUtils.sameThread)
...
}
2. 資料接收
每個 ReceiverSupervisor 啟動後將馬上生成一個使用者提供的 Receiver 實現的例項 —— 該 Receiver 實現可以持續產生或者持續接收系統外資料,比如 TwitterReceiver 可以實時爬取 twitter 資料 —— 並在 Receiver 例項生成後呼叫 Receiver.onStart()。
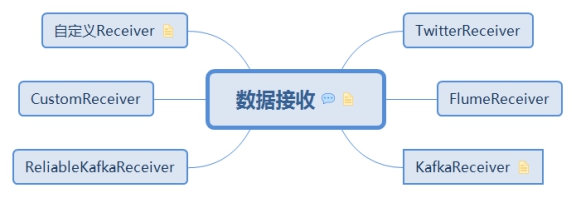
資料的接收由Executor端的Receiver實現,啟動和停止需要子類實現,儲存基類實現,供子類呼叫
abstract class Receiver[T](val storageLevel: StorageLevel) extends Serializable {
// 啟動和停止需要子類實現
def onStart()
def onStop()
// 【儲存單條小資料】
def store(dataItem: T) {...}
// 【儲存陣列形式的塊資料】
def store(dataBuffer: ArrayBuffer[T]) {...}
// 【儲存 iterator 形式的塊資料】
def store(dataIterator: Iterator[T]) {...}
// 【儲存 ByteBuffer 形式的塊資料】
def store(bytes: ByteBuffer) {...}
...
}
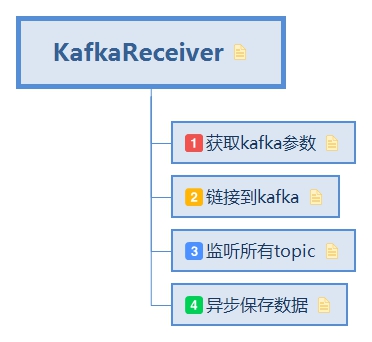
通過kafka去接收資料,
class KafkaInputDStream **extends Receiver**(
_ssc : StreamingContext,
kafkaParams : Map[String,String],
topics : Map[String,Int],
useReliableReceiver : Boolean
storageLevel : StorageLevel
){
def onStart(){
}
}
2.3.1. 獲取kafka引數
拼接kafka consumer所需引數
class KafkaInputDStream(){
def onStart(){
**// 1. 獲取kafka引數**
val props=new Properties()
kafkaParams.foreach(
p=>props.put(p._1,p._2)
)
}
}
2.3.2. 連結到kafka
class KafkaInputDStream(){
// kafka連結器
var consumerConnector:ConsumerConnector
def onStart(){
// 1. 獲取kafka引數
val props=new Properties()
kafkaParams.foreach(
p=>props.put(p._1,p._2)
)
// 2. 連結到kafka
val consumerConf=
new ConsumerConfig(props)
consumerConnector=
Consumer.create(consumerConf)
}
}
2.3.3. 監聽所有topic
class KafkaInputDStream(){
// kafka連結器
var consumerConnector:ConsumerConnector
def onStart(){
// 1. 獲取kafka引數
val props=new Properties()
kafkaParams.foreach(
p=>props.put(p._1,p._2)
)
// 2. 連結到kafka
val consumerConf=
new ConsumerConfig(props)
consumerConnector=
Consumer.create(consumerConf)
// 3. 監聽所有topic
val topicMessageStreams=
consumerConnector.createMessage()
val executorPool=ThreadUtils.
newDaemonFixedTreadPool(
topics.values.sum,
"kafkaMessageHandler"
)
topicMessageStreams.values.foreach(
streams=>streams.foreach{
stream=>
executorPool.submit(
new MessageHandler(stream)
)
}
)
}
}
2.3.4. 非同步儲存資料
class KafkaInputDStream(){
// kafka連結器
var consumerConnector:ConsumerConnector
def onStart(){
// 1. 獲取kafka引數
val props=new Properties()
kafkaParams.foreach(
p=>props.put(p._1,p._2)
)
// 2. 連結到kafka
val consumerConf=
new ConsumerConfig(props)
consumerConnector=
Consumer.create(consumerConf)
// 3. 監聽所有topic
val topicMessageStreams=
consumerConnector.createMessage()
val executorPool=ThreadUtils.
newDaemonFixedTreadPool(
topics.values.sum,
"kafkaMessageHandler"
)
topicMessageStreams.values.foreach(
streams=>streams.foreach{
stream=>
executorPool.submit(
new MessageHandler(stream)
)
}
)
}
// 4. 非同步儲存資料
class MessageHandler(
stream:KafkaStream[K,V]) extends Runable{
def run{
val streamIterator=stream.iterator()
while(streamIterator.hasNext()){
val msgAndMetadata=
streamIterator.next()
**store(**
**msgAndMetadata.key,**
**msgAndMetadata.message**
**)**
}
}
}
}
}
自定義的Receiver只需要繼承Receiver類,並實現onStart方法裡新拉起資料接收執行緒,並在接收到資料時 store() 到 Spark Streamimg 框架就可以了。
3. 資料轉存
Receiver 在 onStart() 啟動後,就將持續不斷地接收外界資料,並持續交給 ReceiverSupervisor 進行資料轉儲
3.1. 儲存格式
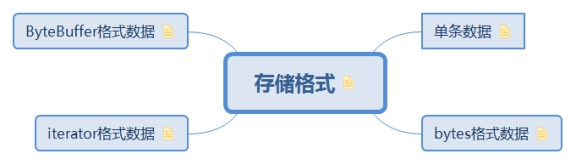
Receiver在呼叫store方法後,根據不同的入參會呼叫ReceiverSupervisor的不同方法。ReceiverSupervisor的方法由ReceiverSupervisorImpl實現
class Receiver {
var supervisor:ReceiverSupervisor;
// 1.單條資料
def strore(dataItem: T ){
supervisor.pushSigle(dataItem)
}
// 2. byte陣列
def store(bytes : ByteBuffer){
supervisor.pushBytes(bytes,None,None)
}
// 3. 迭代器格式
def store(dataIterator : Iterator[T]){
supervisor.pusthIteratro(dataIterator)
}
// 4. ByteBuffer格式
def store(dataBuffer:ArrayBuffer[T]){
supervisor.pushArrayBuffer(dataBuffer)
}
}
3.1.1. 單條資料
呼叫ReceiverSupervisorImpl的pushSigle方法儲存資料
class ReceiverSupervisorImpl {
val defaultBlockGenerator=
new BlockGenerator(
blockGeneratorListener,
streamId,
env.conf
)
def pushSinge(data:Any){
defaultBlockGenerator.addData(data)
}
}
3.1.1.1. 控制batch大小
先檢查接收資料的頻率,控制住頻率就控制了每個batch需要處理的最大資料量
就是在加入 currentBuffer 陣列時會先由 rateLimiter 檢查一下速率,是否加入的頻率已經太高。如果太高的話,就需要 block 住,等到下一秒再開始新增。這裡的最高頻率是由 spark.streaming.receiver.maxRate (default = Long.MaxValue) 控制的,是單個 Receiver 每秒鐘允許新增的條數。控制了這個速率,就控制了整個 Spark Streaming 系統每個 batch 需要處理的最大資料量。
class BlockGenerator{
def addData(data:Any)={
// 1. 檢查接收頻率
waitToPush()
}
}
class RateLimiter(conf:SparkConf){
val maxRateLimit=
conf.getLong(
"spark.streaming.receiver.maxRate",
Long.MaxValue
)
val rateLimiter=GuavaRateLimiter.create(
maxRateLimit.toDouble
)
def waitToPush(){
rateLimiter.acquire()
}
}
3.1.1.2. 新增資料到arrayBuffer
如果頻率正常,則把資料新增到陣列中,否則拋異常
class BlockGenerator{
var currentBuffer=new ArrayBuffer[Any]
def addData(data:Any)={
// 1. 檢查接收頻率
waitToPush()
// 2. 新增資料到currentBuffer
synchronized{
if(state==Active){
currentBuffer+=data
}else{
throw new SparkException{
"connot add data ..."
}
}
}
}
}
3.1.1.3. 定時放入blocakQueue
3.1 清空currentBuffer
3.2 將block塊放入blocakQueue
class BlockGenerator{
var currentBuffer=new ArrayBuffer[Any]
// 定時器:定時更新currentBuffer
val blockIntervalTimer=
new RecurringTimer(
clock,
blockIntervalMs,
updateCurrentBuffer,
"BlockGenerator"
)
// 儲存block的陣列大小,預設是10
val queueSize=conf.getInt(
"spark.streaming.blockQueueSize",10)
val blocksForPushing=
new ArrayBlockingQueue[Block](queueSize)
def addData(data:Any)={
// 1. 檢查接收頻率
waitToPush()
// 2. 新增資料到currentBuffer
synchronized{
currentBuffer+=data
}
def updateCurrentBuffer(timer:Long){
var newBlock:Block=null
synchronized{
// 3.1 清空currentBuffer
val newBlockBuffer=currentBuffer
currentBuffer=new ArrayBuffer[Any]
// 3. 2 將block塊放入blocakQueue
newBlock=
new Block(id,newBlockBuffer)
blocksForPushing.put(newBlock)
}
}
}
}
3.1.1.4. 儲存並推送blocks
在初始化BlockGenerator時,啟動一個執行緒去持續的執行pushBlocks方法。如果還沒有生成blocks,則阻塞呼叫queue.poll去獲取資料,如果已經存在blocks塊,則直接queue.take(10)
class BlockGenerator{
var currentBuffer=new ArrayBuffer[Any]
// 定時器:定時更新currentBuffer
val blockIntervalTimer=
new RecurringTimer(
clock,
blockIntervalMs,
updateCurrentBuffer,
"BlockGenerator"
)
// 儲存block的陣列大小,預設是10
val queueSize=conf.getInt(
"spark.streaming.blockQueueSize",10)
val blocksForPushing=
new ArrayBlockingQueue[Block](queueSize)
// 推送block塊
val blockPushingThread=new Thread(){
def run(){keepPushingBlocks()}
}
def addData(data:Any)={
// 1. 檢查接收頻率
waitToPush()
// 2. 新增資料到currentBuffer
synchronized{
currentBuffer+=data
}
def updateCurrentBuffer(timer:Long){
var newBlock:Block=null
synchronized{
// 3.1 清空currentBuffer
val newBlockBuffer=currentBuffer
currentBuffer=new ArrayBuffer[Any]
// 3. 2 將block塊放入blocakQueue
newBlock=
new Block(id,newBlockBuffer)
blocksForPushing.put(newBlock)
}
}
def keepPushingBlocks(){
// **4.1 當block正在產時,等待其生成**
while(areBlocksBeingGenerated){
Option(blocksForPushing.poll(
waitingTime
) match{
case Some(block)=>
pushBLock(block)
case None =>
})
}
// 4.2 block塊已經生成
while(!blocksForPushing.isEmpty){
val block=blocksForPushing.take()
pushBlock(block)
}
}
}
}
3.1.1.4.1. 儲存
class ReceiverSupervisorImpl {
def pushAndReportBlock {
val blockStoreResult =
**receivedBlockHandler.storeBlock**(
blockId,
receivedBlock
)
}
}
3.1.1.4.2. 推送
class ReceiverSupervisorImpl {
def pushAndReportBlock {
val blockStoreResult =
receivedBlockHandler.**storeBlock**(
blockId,
receivedBlock
)
val blockInfo = ReceivedBlockInfo(
streamId,
numRecords,
metadataOption,
blockStoreResult
)
trackerEndpoint.askSync[Boolean](AddBlock(blockInfo))
}
}
3.1.2. bytes格式資料
class ReceiverSupervisorImpl{
def pushBytes(
bytes: ByteBuffer,
metadataOption: Option[Any],
blockIdOption: Option[StreamBlockId]
) {
pushAndReportBlock(
ByteBufferBlock(bytes),
metadataOption,
blockIdOption
)
}
}
3.1.3. iterator格式資料
class ReceiverSupervisorImpl{
def pushIterator(
iterator: Iterator[_],
metadataOption: Option[Any],
blockIdOption: Option[StreamBlockId]
) {
pushAndReportBlock(IteratorBlock(iterator), metadataOption, blockIdOption)
}
}
3.1.4. ByteBuffer格式資料
class ReceiverSupervisorImpl{
def pushArrayBuffer(
arrayBuffer: ArrayBuffer[_],
metadataOption: Option[Any],
blockIdOption: Option[StreamBlockId]
) {
pushAndReportBlock(ArrayBufferBlock(arrayBuffer), metadataOption, blockIdOption)
}
}
3.2. 儲存方式
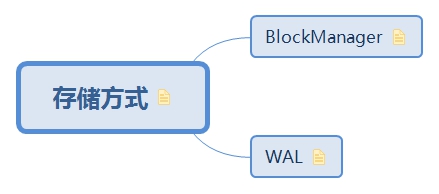
ReceivedBlockHandler 有兩個具體的儲存策略的實現:
(a) BlockManagerBasedBlockHandler,是直接存到 executor 的記憶體或硬碟
(b) WriteAheadLogBasedBlockHandler,是先寫 WAL,再儲存到 executor 的記憶體或硬碟
3.2.1. BlockManager
將資料儲存交給blockManager進行管理,呼叫blockmanager的putIterator方法,由其實現在不同excutor上的複製以及快取策略。
class BlockManagerBasedBlockHandler(
blockManager:BlockManager,
storageLevel:StorageLevel
)extends ReceivedBlockHandler{
def storeBlock(blockId,block){
var numRecords:Option[Long]=None
val putSucceeded:Boolean = block match{
case ArrayBufferBlock(arrayBuffer)=>
numRecords=Some(arrayBuffer.size)
blockManager.putIterator(
blockId,
arrayBuffer.iterator,
storageLevel,
tellMaster=true
)
case IteratorBlock(iterator)=>
val countIterator=
new CountingIterator(iterator)
val putResult=
**blockManager.putIterato**r(
blockId,
arrayBuffer.iterator,
storageLevel,
tellMaster=true
)
numRecords=countIterator.count
putResult
case ByteBufferBlock(byteBuffer)=>
blockManager.putBytes(
blockId,
new ChunkedBytedBuffer(
byteBuffer.duplicate(),
storageLevel,
tellMaster=true
)
)
// 報告給driver的資訊:id和num
BlockManagerBasedStoreResult(
blockId,
numRecords
)
}
}
}
// ChunkedBytedBuffer: 將byte陣列分片
// byteBuffer.duplicate(): 複製
3.2.2. WAL
WriteAheadLogBasedBlockHandler 的實現則是同時寫到可靠儲存的 WAL 中和 executor 的 BlockManager 中;在兩者都寫完成後,再上報塊資料的 meta 資訊。
BlockManager 中的塊資料是計算時首選使用的,只有在 executor 失效時,才去 WAL 中讀取寫入過的資料。
同其它系統的 WAL 一樣,資料是完全順序地寫入 WAL 的;在稍後上報塊資料的 meta 資訊,就額外包含了塊資料所在的 WAL 的路徑,及在 WAL 檔案內的偏移地址和長度。
class WriteAheadLogBasedBlockHandler(
blockManager: BlockManager,
serializerManager: SerializerManager,
streamId: Int,
storageLevel: StorageLevel,
conf: SparkConf,
hadoopConf: Configuration,
checkpointDir: String,
clock: Clock = new SystemClock
)extends ReceivedBlockHandler{
// 儲存超時時間
blockStoreTimeout = conf.getInt(
"spark.streaming.receiver.
blockStoreTimeout",30).seconds
// 寫log類
val writeAheadLog=WriteAheadLogUtils.
creatLogForReceiver(
conf,
checkpointDirToLogDir(
checkpointDir,
streamId,
hadoopConf
)
)
def storeBlock(){
// 1. 執行blockManager
val serializedBlock = block match {...}
// 2. 執行儲存到log
// 用future非同步執行
val storeInBlockManagerFuture=Future{
blockManger.putBytes(...serializedBlock)
}
val storeInWriteAheadLogFuture=Future{
writeAheadLog.write(...serializedBlock)
}
val combineFuture=
storeInBlockManagerFuture.zip(
storeInWriteAHeadLogFuture
).map(_._2)
val walRecordHandle=ThreadUtils.
awaitUtils.awaitResult(
combineFuture,blockStoreTimeout
)
WriteAheandLogBasedStoreResult(
blockId,
numRecords,
walRecordHandle
)
}
}
// future1.zip(future2): 合併future,返回tuple(future)
// 兩個future中有一個失敗,則失敗
4. 資料上報
每次成塊在 executor 儲存完畢後,ReceiverSupervisor 就會及時上報塊資料的 meta 資訊給 driver 端的 ReceiverTracker;這裡的 meta 資訊包括資料的標識 id,資料的位置,資料的條數,資料的大小等資訊
ReceiverSupervisor會將資料的標識ID,資料的位置,資料的條數,資料的大小等資訊上報給driver
class ReceiverSupervisorImpl {
def pushAndReportBlock {
val blockStoreResult =
receivedBlockHandler.storeBlock(
blockId,
receivedBlock
)
val blockInfo = ReceivedBlockInfo(
**streamId,**
**numRecords,**
**metadataOption,**
**blockStoreResult**
)
trackerEndpoint.askSync[Boolean](AddBlock(blockInfo))
}
}
4.1. wal上報
// 報告給driver的資訊:blockId,block數量,walRecordHandle
WriteAheandLogBasedStoreResult(
blockId,
numRecords,
**walRecordHandle**
)
4.2. BlockManager上報
// 報告給driver的資訊:id和num
BlockManagerBasedStoreResult(
blockId,
numRecords
)
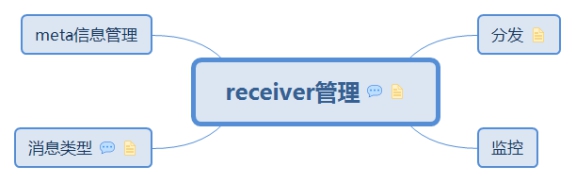
5. receiver管理
- 分發和監控receiver
- 作為RpcEndpoint和reciever通訊,接收和傳送訊息
- 管理上報的meta資訊
一方面 Receiver 將通過 AddBlock 訊息上報 meta 資訊給 ReceiverTracker,另一方面 JobGenerator 將在每個 batch 開始時要求 ReceiverTracker 將已上報的塊資訊進行 batch 劃分,ReceiverTracker 完成了塊資料的 meta 資訊管理工作。
具體的,ReceiverTracker 有一個成員 ReceivedBlockTracker,專門負責已上報的塊資料 meta 資訊管理。
5.1. 分發
在 ssc.start() 時,將隱含地呼叫 ReceiverTracker.start();而 ReceiverTracker.start() 最重要的任務就是呼叫自己的 launchReceivers() 方法將 Receiver 分發到多個 executor 上去。然後在每個 executor 上,由 ReceiverSupervisor 來分別啟動一個 Receiver 接收資料
而且在 1.5.0 版本以來引入了 ReceiverSchedulingPolicy,是在 Spark Streaming 層面新增對 Receiver 的分發目的地的計算,相對於之前版本依賴 Spark Core 的 TaskScheduler 進行通用分發,新的 ReceiverSchedulingPolicy 會對 Streaming 應用的更好的語義理解,也能計算出更好的分發策略。
並且還通過每個 Receiver 對應 1 個 Job 的方式,保證了 Receiver 的多次分發,和失效後的重啟、永活
5.2. 監控
5.3. 訊息型別
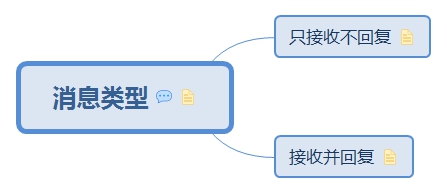
ReceiverTracker:
RpcEndPoint 可以理解為 RPC 的 server 端,底層由netty提供通訊支援,供 client 呼叫。
ReceiverTracker 作為 RpcEndPoint 的地址 —— 即 driver 的地址 —— 是公開的,可供 Receiver 連線;如果某個 Receiver 連線成功,那麼 ReceiverTracker 也就持有了這個 Receiver 的 RpcEndPoint。這樣一來,通過傳送訊息,就可以實現雙向通訊。
5.3.1. 只接收不回覆
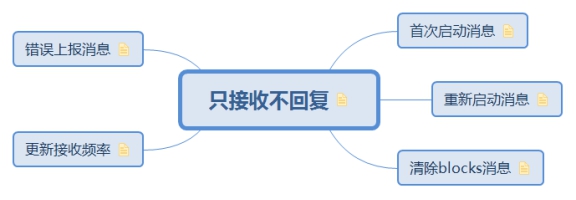
只接收訊息不回覆,除了錯誤上報訊息是excutor傳送的以外,其餘都是driver的tracker自己給自己傳送的命令,接收訊息均在ReceiverTracker.receive方法中實現
class ReceiverTracker {
def receive:PartialFunction[Any,Unit]={
case StartAllReceivers => ...
case RestartReceiver => ...
case CleanupOldBlocks => ...
case UpdateReceiverRateLimit => ...
case ReportError => ...
}
}
5.3.1.1. 首次啟動訊息
在 ReceiverTracker 剛啟動時,發給自己這個訊息,觸發具體的 schedulingPolicy 計算,和後續分發
class ReceiverTracker {
def receive:PartialFunction[Any,Unit]={
case StartAllReceivers =>
val scheduledLocations = schedulingPolicy.
scheduleReceivers(
receivers,
getExecutors
)
for (receiver <- receivers) {
val executors = scheduledLocations(
receiver.
streamId
)
updateReceiverScheduledExecutors(
receiver.
streamId,
executors
)
receiverPreferredLocations(
receiver.streamId) =
receiver.preferredLocation
startReceiver(receiver, executors)
}
case RestartReceiver => ...
case CleanupOldBlocks => ...
case UpdateReceiverRateLimit => ...
case ReportError => ...
}
}
5.3.1.2. 重新啟動訊息
當初始分發的 executor 不對,或者 Receiver 失效等情況出現,發給自己這個訊息,觸發 Receiver 重新分發
class ReceiverTracker {
def receive:PartialFunction[Any,Unit]={
case StartAllReceivers => ...
// 失敗重啟
case RestartReceiver(receiver)=>
// 1.獲取之前的executors
val oldScheduledExecutors = getStoredScheduledExecutors(
receiver.streamId
)
// 2. 計算新的excutor位置
val scheduledLocations = if (oldScheduledExecutors.nonEmpty) {
// 2.1 之前excutors可用,則使用之前的
oldScheduledExecutors
} else {
// 2.2 之前的不可用則重新計算位置
schedulingPolicy.rescheduleReceiver()
// 3. 傳送給worker重啟receiver
startReceiver(
receiver, scheduledLocations)
case CleanupOldBlocks => ...
case UpdateReceiverRateLimit => ...
case ReportError => ...
}
}
5.3.1.3. 清除blocks訊息
當塊資料已完成計算不再需要時,發給自己這個訊息,將給所有的 Receiver 轉發此 CleanupOldBlocks 訊息
class ReceiverTracker {
def receive:PartialFunction[Any,Unit]={
case StartAllReceivers => ...
case RestartReceiver => ...
case CleanupOldBlocks =>
receiverTrackingInfos.values.flatMap(
_.endpoint
).foreach(
_.send(c)
)
case UpdateReceiverRateLimit => ...
case ReportError => ...
}
}
5.3.1.4. 更新接收頻率
ReceiverTracker 動態計算出某個 Receiver 新的 rate limit,將給具體的 Receiver 傳送 UpdateRateLimit 訊息
class ReceiverTracker {
def receive:PartialFunction[Any,Unit]={
case StartAllReceivers => ...
case RestartReceiver => ...
case CleanupOldBlocks => ...
case UpdateReceiverRateLimit => ...
for (info <- receiverTrackingInfos.get(streamUID);
eP <- info.endpoint) {
eP.send(UpdateRateLimit(newRate))
}
case ReportError => ...
}
}
5.3.1.5. 錯誤上報訊息
class ReceiverTracker {
def receive:PartialFunction[Any,Unit]={
case StartAllReceivers => ...
case RestartReceiver => ...
case CleanupOldBlocks => ...
case UpdateReceiverRateLimit => ...
case ReportError =>
reportError(streamId, message, error)
}
}
5.3.2. 接收並回復
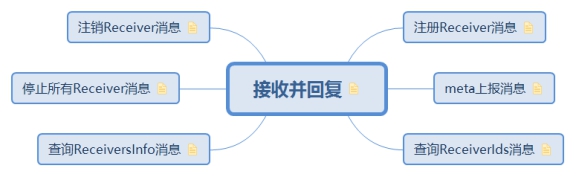
接收executor的訊息,處理完畢後並回復給executor
class ReceiverTracker {
def receiveAndReply(context:RpcCallContext){
case RegisterReceiver() => ...
case AddBlock() => ...
case DeregisterReceiver() => ...
case AllReceiverIds => ...
case StopAllReceivers => ...
}
}
5.3.2.1. 註冊Receiver訊息
由 Receiver 在試圖啟動的過程中發來,將回復允許啟動,或不允許啟動
class ReceiverTracker {
def receiveAndReply(context:RpcCallContext){
case RegisterReceiver() =>
val successful=registerReceiver(
streamId,
type,
host,
executorId,
receiverEndpoint,
context.senderAddress)
context.reply(successful)
case AddBlock() => ...
case DeregisterReceiver() => ...
case AllReceiverIds => ...
case GetAllReceiverInfo => ...
case StopAllReceivers => ...
}
}
5.3.2.2. meta上報訊息
具體的塊資料 meta 上報訊息,由 Receiver 發來,將返回成功或失敗
class ReceiverTracker {
def receiveAndReply(context:RpcCallContext){
case RegisterReceiver() => ...
case AddBlock() =>
context.reply(
addBlock(receivedBlockInfo)
)
case DeregisterReceiver() => ...
case AllReceiverIds => ...
case GetAllReceiverInfo => ...
case StopAllReceivers => ...
}
}
5.3.2.3. 查詢ReceiverIds訊息
executor傳送的本地訊息。在 ReceiverTracker stop() 的過程中,查詢是否還有活躍的 Receiver,返回所有或者的receiverId
class ReceiverTracker {
def receiveAndReply(context:RpcCallContext){
case RegisterReceiver() => ...
case AddBlock() => ...
case DeregisterReceiver() => ...
case AllReceiverIds =>
context.reply(
receiverTrackingInfos.filter(
_._2.state != ReceiverState.INACTIVE
).keys.toSeq
)
case GetAllReceiverInfo => ...
case StopAllReceivers => ...
}
}
5.3.2.4. 查詢ReceiversInfo訊息
查詢所有excutors的資訊給receiver
class ReceiverTracker {
def receiveAndReply(context:RpcCallContext){
case RegisterReceiver() => ...
case AddBlock() => ...
case DeregisterReceiver() =>
case AllReceiverIds => ...
case GetAllReceiverInfo =>
context.reply(
receiverTrackingInfos.toMap
)
case StopAllReceivers => ...
}
}
5.3.2.5. 停止所有Receiver訊息
在 ReceiverTracker stop() 的過程剛開始時,要求 stop 所有的 Receiver;將向所有的 Receiver 傳送 stop 資訊,並返回true
class ReceiverTracker {
def receiveAndReply(context:RpcCallContext){
case RegisterReceiver() => ...
case AddBlock() => ...
case DeregisterReceiver() => ...
case AllReceiverIds => ...
case GetAllReceiverInfo => ...
case StopAllReceivers =>
assert(isTrackerStopping || isTrackerStopped)
receiverTrackingInfos.values.flatMap(
_.endpoint
).foreach {
_.send(StopReceiver)
}
context.reply(true)
}
}
5.3.2.6. 登出Receiver訊息
由 Receiver 發來,停止receiver,處理後,無論如何都返回 true
class ReceiverTracker {
def receiveAndReply(context:RpcCallContext){
case RegisterReceiver() => ...
case AddBlock() => ...
case DeregisterReceiver() =>
deregisterReceiver(
streamId,
message,
error
)
context.reply(true)
case AllReceiverIds => ...
case GetAllReceiverInfo => ...
case StopAllReceivers => ...
}
}
5.4. meta資訊管理

5.4.1. 接收meta資訊
addBlock(receivedBlockInfo: ReceivedBlockInfo)方法接收到某個 Receiver 上報上來的塊資料 meta 資訊,將其加入到 streamIdToUnallocatedBlockQueues 裡
class ReceivedBlockTracker{
// 上報上來的、但尚未分配入 batch 的 Block 塊資料的 meta
val streamIdToUnallocatedBlockQueues =
new HashMap[Int, ReceivedBlockQueue]
// WAL
val writeResult=
writeToLog(
BlockAdditionEvent(
receivedBlockInfo
)
)
if(writeResult){
synchronized{
streamIdToUnallocatedBlockQueues.
getOrElseUpdate(
streamId,
new ReceivedBlockQueue()
)+=
receivedBlockInfo
}
}
}
5.4.2. batch分配
JobGenerator 在發起新 batch 的計算時,將 streamIdToUnallocatedBlockQueues 的內容,以傳入的 batchTime 引數為 key,新增到 timeToAllocatedBlocks 裡,並更新 lastAllocatedBatchTime
class ReceivedBlockTracker{
// 上報上來的、已分配入 batch 的 Block 塊資料的 meta,按照 batch 進行一級索引、再按照 receiverId 進行二級索引的 queue,所以是一個 HashMap: time → HashMap
val timeToAllocatedBlocks =
new mutable.HashMap[Time,
AllocatedBlocks:Map[
Int,
Seq[ReceivedBlockInfo]
]
]
// 記錄了最近一個分配完成的 batch 是哪個
var lastAllocatedBatchTime: Time = null
// 收集所有未分配的blocks
def allocateBlocksToBatch(batchTime: Time): Unit = synchronized {
// 判斷時間是否合法:大於最近收集的時間
if (lastAllocatedBatchTime == null || batchTime > lastAllocatedBatchTime) {
// 從未分配佇列中取出blocks
val streamIdToBlocks = streamIds.map {
streamId =>(streamId,getReceivedBlockQueue(streamId)
.dequeueAll(x => true))
}.toMap
val allocatedBlocks =AllocatedBlocks(streamIdToBlocks)
if (writeToLog(BatchAllocationEvent(batchTime, allocatedBlocks))) {
// 放入已分配佇列
timeToAllocatedBlocks.put(
batchTime, allocatedBlocks)
// 更新最近分配的時間戳
lastAllocatedBatchTime = batchTime
} else {
logInfo(s"Possibly processed batch $batchTime needs to be processed again in WAL recovery")
}
}
}
5.4.3. 計算DAG生成
JobGenerator 在發起新 batch 的計算時,由 DStreamGraph 生成 RDD DAG 例項時,呼叫getBlocksOfBatch(batchTime: Time)查 timeToAllocatedBlocks,獲得劃入本 batch 的塊資料元資訊,由此生成處理對應塊資料的 RDD
class ReceivedBlockTracker{
def getBlocksOfBatch(batchTime: Time): Map[Int, Seq[ReceivedBlockInfo]] = synchronized {
timeToAllocatedBlocks.get(batchTime).map { _.streamIdToAllocatedBlocks }.getOrElse(Map.empty)
}
}
5.4.4. 清除meta資訊
當一個 batch 已經計算完成、可以把已追蹤的塊資料的 meta 資訊清理掉時呼叫,將通過job清理 timeToAllocatedBlocks 表裡對應 cleanupThreshTime 之前的所有 batch 塊資料 meta 資訊
class ReceivedBlockTracker{
def cleanupOldBatches(cleanupThreshTime: Time, waitForCompletion: Boolean): Unit = synchronized {
val timesToCleanup = timeToAllocatedBlocks.keys.
filter { _ < cleanupThreshTime }.toSeq}
if (writeToLog(
BatchCleanupEvent(timesToCleanup))) {
// 清除已分配batch佇列
timeToAllocatedBlocks --= timesToCleanup
// 清除WAL
writeAheadLogOption.foreach(
_.clean(
cleanupThreshTime.milliseconds, waitForCompletion)
)
}
}
腦圖製作參考:https://github.com/lw-lin/CoolplaySpark
完整腦圖連結地址:https://sustblog.oss-cn-beijing.aliyuncs.com/blog/2018/spark/srccode/spark-streaming-all.png
{kind=link}