
flume+kafka+spark streaming(持續更新)
kafka
Kafka是一種高吞吐量的分散式釋出訂閱訊息系統,它可以處理消費者規模的網站中的所有動作流資料。 kafka的設計初衷是希望作為一個統一的資訊收集平臺,能夠實時的收集反饋資訊,並需要能夠支撐較大的資料量,且具備良好的容錯能力.
Apache kafka是訊息中介軟體的一種。
一 、術語介紹
Broker
Kafka叢集包含一個或多個伺服器,這種伺服器被稱為broker。
Topic
每條釋出到Kafka叢集的訊息都有一個類別,這個類別被稱為Topic。(物理上不同Topic的訊息分開儲存,邏輯上一個Topic的訊息雖然保存於一個或多個broker上但使用者只需指定訊息的Topic即可生產或消費資料而不必關心資料存於何處)。每個topic都具有這兩種模式:(佇列:消費者組(consumer group)允許同名的消費者組成員瓜分處理;釋出訂閱:允許你廣播訊息給多個消費者組(不同名))。
Partition
Partition是物理上的概念,每個Topic包含一個或多個Partition.
Producer
負責釋出訊息到Kafka broker,比如flume採集機就是Producer。
Consumer
訊息消費者,向Kafka broker讀取訊息的客戶端。比如Hadoop機器就是Consumer。
Consumer Group
每個Consumer屬於一個特定的Consumer Group(可為每個Consumer指定group name,若不指定group name則屬於預設的group)。
二、使用場景
1、Messaging
對於一些常規的訊息系統,kafka是個不錯的選擇;partitons/replication和容錯,可以使kafka具有良好的擴充套件性和效能優勢.不過到目前為止,我們應該很清楚認識到,kafka並沒有提供JMS中的”事務性”“訊息傳輸擔保(訊息確認機制)”“訊息分組”等企業級特性;kafka只能使用作為”常規”的訊息系統,在一定程度上,尚未確保訊息的傳送與接收絕對可靠(比如,訊息重發,訊息傳送丟失等)
2、Websit activity tracking
kafka可以作為”網站活性跟蹤”的最佳工具;可以將網頁/使用者操作等資訊傳送到kafka中.並實時監控,或者離線統計分析等
3、Log Aggregation
kafka的特性決定它非常適合作為”日誌收集中心”;application可以將操作日誌”批量”“非同步”的傳送到kafka叢集中,而不是儲存在本地或者DB中;kafka可以批量提交訊息/壓縮訊息等,這對producer端而言,幾乎感覺不到效能的開支.此時consumer端可以使hadoop等其他系統化的儲存和分析系統.
4、它應用於2大類應用
構建實時的流資料管道,可靠地獲取系統和應用程式之間的資料。
構建實時流的應用程式,對資料流進行轉換或反應。
三、分散式
Log的分割槽被分佈到叢集中的多個伺服器上。每個伺服器處理它分到的分割槽。 根據配置每個分割槽還可以複製到其它伺服器作為備份容錯。 每個分割槽有一個leader,零或多個follower。Leader處理此分割槽的所有的讀寫請求,而follower被動的複製資料。如果leader宕機,其它的一個follower會被推舉為新的leader。 一臺伺服器可能同時是一個分割槽的leader,另一個分割槽的follower。 這樣可以平衡負載,避免所有的請求都只讓一臺或者某幾臺伺服器處理。
四、訊息處理順序
Kafka保證訊息的順序不變。 在這一點上Kafka做的更好,儘管並沒有完全解決上述問題。 Kafka採用了一種分而治之的策略:分割槽。 因為Topic分割槽中訊息只能由消費者組中的唯一一個消費者處理,所以訊息肯定是按照先後順序進行處理的。但是它也僅僅是保證Topic的一個分割槽順序處理,不能保證跨分割槽的訊息先後處理順序。 所以,如果你想要順序的處理Topic的所有訊息,那就只提供一個分割槽。
六、Key和Value
Kafka是一個分散式訊息系統,Producer生產訊息並推送(Push)給Broker,然後Consumer再從Broker那裡取走(Pull)訊息。Producer生產的訊息就是由Message來表示的,對使用者來講,它就是鍵-值對。
Message => Crc MagicByte Attributes Key Valuekafka會根據傳進來的key計算其分割槽,但key可以不傳,可以為null,空的話,producer會把這條訊息隨機的傳送給一個partition。

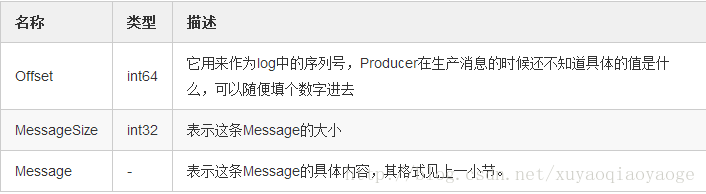
MessageSet用來組合多條Message,它在每條Message的基礎上加上了Offset和MessageSize,其結構是:
MessageSet => [Offset MessageSize Message]它的含義是MessageSet是個陣列,陣列的每個元素由三部分組成,分別是Offset,MessageSize和Message,它們的含義分別是:
七、小例子
1.啟動ZooKeeper
進入kafka目錄,加上daemon表示在後臺啟動,不佔用當前的命令列視窗。
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
如果要關閉,下面這個
bin/zookeeper-server-stop.sh
ZooKeeper 的埠號是2181,輸入jps檢視程序號是QuorumPeerMain
2.啟動kafka
在server.properties中加入,第一個是保證你刪topic可以刪掉,第二個不然的話就報topic找不到的錯誤:
delete.topic.enable=true
listeners=PLAINTEXT://localhost:9092
然後:
bin/kafka-server-start.sh -daemon config/server.properties
如果要關閉,下面這個
bin/kafka-server-stop.sh
Kafka的埠號是9092,輸入jps檢視程序號是Kafka
3.建立一個主題(topic)
建立一個名為“test”的Topic,只有一個分割槽和一個備份:
bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic test
建立好之後,可以通過執行以下命令,檢視已建立了哪些topic:
bin/kafka-topics.sh –list –zookeeper localhost:2181
檢視具體topic的資訊:
bin/kafka-topics.sh –describe –zookeeper localhost:2181 –topic test
4.傳送訊息
啟動kafka生產者:
bin/kafka-console-producer.sh –broker-list localhost:9092 –topic test
5.接收訊息
新開一個命令列視窗,啟動kafka消費者:
bin/kafka-console-consumer.sh –zookeeper localhost:2181 –topic test –from-beginning
6.最後
在producer視窗中輸入訊息,可以在consumer視窗中顯示:


spark streaming
Spark Streaming是一種構建在Spark上的實時計算框架,它擴充套件了Spark處理大規模流式資料的能力。
Spark Streaming的優勢在於:
能執行在100+的結點上,並達到秒級延遲。
使用基於記憶體的Spark作為執行引擎,具有高效和容錯的特性。
能整合Spark的批處理和互動查詢。
為實現複雜的演算法提供和批處理類似的簡單介面。
首先,Spark Streaming把實時輸入資料流以時間片Δt (如1秒)為單位切分成塊。Spark Streaming會把每塊資料作為一個RDD,並使用RDD操作處理每一小塊資料。每個塊都會生成一個Spark Job處理,最終結果也返回多塊。
在Spark Streaming中,則通過操作DStream(表示資料流的RDD序列)提供的介面,這些介面和RDD提供的介面類似。
正如Spark Streaming最初的目標一樣,它通過豐富的API和基於記憶體的高速計算引擎讓使用者可以結合流式處理,批處理和互動查詢等應用。因此Spark Streaming適合一些需要歷史資料和實時資料結合分析的應用場合。當然,對於實時性要求不是特別高的應用也能完全勝任。另外通過RDD的資料重用機制可以得到更高效的容錯處理。
當一個上下文(context)定義之後,你必須按照以下幾步進行操作:
定義輸入源;
準備好流計算指令;
利用streamingContext.start()方法接收和處理資料;
處理過程將一直持續,直到streamingContext.stop()方法被呼叫。
可以利用已經存在的SparkContext物件建立StreamingContext物件:
val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1))視窗函式
對於spark streaming中的視窗函式,參見:
視窗函式解釋
對非(K,V)形式的RDD 視窗化reduce:
1.reduceByWindow(reduceFunc, windowDuration, slideDuration)
2.reduceByWindow(reduceFunc, invReduceFunc, windowDuration, slideDuration)
對(K,V)形式RDD 按Key視窗化reduce:
1.reduceByKeyAndWindow(reduceFunc, windowDuration, slideDuration)
2.reduceByKeyAndWindow(reduceFunc, invReduceFunc, windowDuration, slideDuration, numPartitions, filterFunc)
從效率來說,應選擇帶有invReduceFunc的方法。
可以通過在多個RDD或者批資料間重用連線物件做更進一步的優化。開發者可以保有一個靜態的連線物件池,重複使用池中的物件將多批次的RDD推送到外部系統,以進一步節省開支:
dstream.foreachRDD(rdd => {
rdd.foreachPartition(partitionOfRecords => {
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
})
})spark執行時間是少了,但資料庫壓力比較大,會一直佔資源。
小例子:
package SparkStreaming
import org.apache.spark._
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
object Spark_streaming_Test {
def main(args: Array[String]): Unit = {
//local[2]表示在本地建立2個working執行緒
//當執行在本地,如果你的master URL被設定成了“local”,這樣就只有一個核執行任務。這對程式來說是不足的,因為作為receiver的輸入DStream將會佔用這個核,這樣就沒有剩餘的核來處理資料了。
//所以至少得2個核,也就是local[2]
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
//時間間隔是1秒
val ssc = new StreamingContext(conf, Seconds(1))
//有滑動視窗時,必須有checkpoint
ssc.checkpoint("F:\\checkpoint")
//DStream是一個基類
//ssc.socketTextStream() 將建立一個 SocketInputDStream;這個 InputDStream 的 SocketReceiver 將監聽伺服器 9999 埠
//ssc.socketTextStream()將 new 出來一個 DStream 具體子類 SocketInputDStream 的例項。
val lines = ssc.socketTextStream("192.168.1.66", 9999, StorageLevel.MEMORY_AND_DISK_SER)
// val lines = ssc.textFileStream("F:\\scv")
val words = lines.flatMap(_.split(" ")) // DStream transformation
val pairs = words.map(word => (word, 1)) // DStream transformation
// val wordCounts = pairs.reduceByKey(_ + _) // DStream transformation
//每隔3秒鐘,計算過去5秒的詞頻,顯然一次計算的內容與上次是有重複的。如果不想重複,把2個時間設為一樣就行了。
// val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(5), Seconds(3))
val windowedWordCounts = pairs.reduceByKeyAndWindow(_ + _, _ - _, Seconds(5), Seconds(3))
windowedWordCounts.filter(x => x._2 != 0).print()
// wordCounts.print() // DStream output,列印每秒計算的詞頻
//需要注意的是,當以上這些程式碼被執行時,Spark Streaming僅僅準備好了它要執行的計算,實際上並沒有真正開始執行。在這些轉換操作準備好之後,要真正執行計算,需要呼叫如下的方法
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
//在StreamingContext上呼叫stop()方法,也會關閉SparkContext物件。如果只想僅關閉StreamingContext物件,設定stop()的可選引數為false
//一個SparkContext物件可以重複利用去建立多個StreamingContext物件,前提條件是前面的StreamingContext在後面StreamingContext建立之前關閉(不關閉SparkContext)
ssc.stop()
}
}
1.啟動
start-dfs.sh
start-yarn.sh
2.終端輸入:
nc -lk 9999
然後在IEDA中執行spark程式。由於9999埠中還沒有寫東西,所以執行是下圖:

只有時間,沒有打印出東西。然後在終端輸入下面的東西,也可以從其他地方複製進來。
hello world
hello hadoop
hadoop love
love cat
cat love rabbit
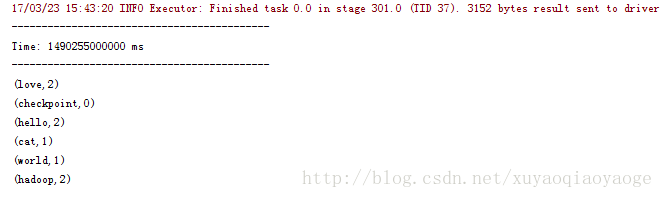
這時,IDEA的控制檯就輸出下面的東西。

3.下面執行帶時間視窗的,注意如果加了時間視窗就必須有checkpoint
輸入下面的,不要一次全輸入,一次輸個幾行。
checkpoint
hello world
hello hadoop
hadoop love
love cat
cat love rabbit
ni hao a
hello world
hello hadoop
hadoop love
love cat
cat love rabbit
hello world
hello hadoop
hadoop love
love cat
cat love rabbit
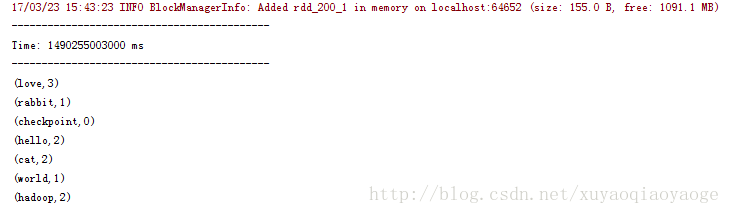
先是++–的那種:

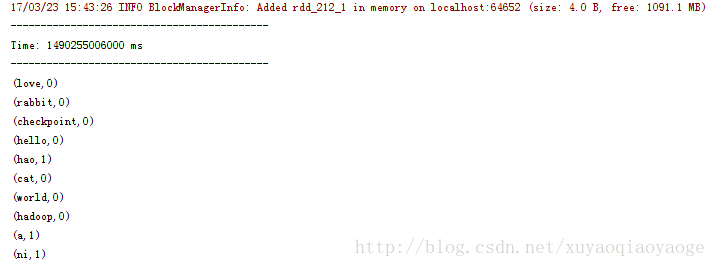
再然後是不++–的那種:
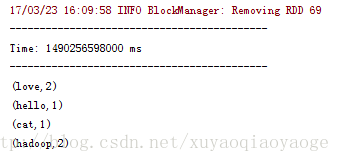

++–的那種是因為把過去的RDD也帶進來計算了,所以出現了0這個情況,為了避免這種情況只能在列印前過濾掉0的再列印。而沒有++–的那種情況是不需要這樣做的。
Checkpointing
在容錯、可靠的檔案系統(HDFS、s3等)中設定一個目錄用於儲存checkpoint資訊。就可以通過streamingContext.checkpoint(checkpointDirectory)方法來做。
預設的間隔時間是批間隔時間的倍數,最少10秒。它可以通過dstream.checkpoint來設定。需要注意的是,隨著 streaming application 的持續執行,checkpoint 資料佔用的儲存空間會不斷變大。因此,需要小心設定checkpoint 的時間間隔。設定得越小,checkpoint 次數會越多,佔用空間會越大;如果設定越大,會導致恢復時丟失的資料和進度越多。一般推薦設定為 batch duration 的5~10倍。
package streaming
import java.io.File
import java.nio.charset.Charset
import com.google.common.io.Files
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by Administrator on 2017/3/12.
*/
object RecoverableNetworkWordCount {
def createContext(ip: String, port: Int, outputPath: String, checkpointDirectory: String): StreamingContext = {
println("Creating new context") //如果沒有出現這句話,說明StreamingContext是從checkpoint裡面載入的
val outputFile = new File(outputPath) //輸出檔案的目錄
if (outputFile.exists()) outputFile.delete()
val sparkConf = new SparkConf().setAppName("RecoverableNetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1)) //時間間隔是1秒
ssc.checkpoint(checkpointDirectory) //設定一個目錄用於儲存checkpoint資訊
val lines = ssc.socketTextStream(ip, port)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
val windowedWordCounts = wordCounts.reduceByKeyAndWindow(_ + _, _ - _, Seconds(30), Seconds(10))
windowedWordCounts.checkpoint(Seconds(10))//一般推薦設定為 batch duration 的5~10倍,即StreamingContext的第二個引數的5~10倍
windowedWordCounts.print()
Files.append(windowedWordCounts + "\n", outputFile, Charset.defaultCharset())
ssc
}
def main(args: Array[String]): Unit = {
if (args.length != 4) {
System.exit(1)
}
val ip = args(0)
val port = args(1).toInt
val checkpointDirectory = args(2)
val outputPath = args(3)
val ssc = StreamingContext.getOrCreate(checkpointDirectory, () => createContext(ip, port, outputPath, checkpointDirectory))
ssc.start()
ssc.awaitTermination()
}
}
優化
1.資料接收的並行水平
建立多個輸入DStream並配置它們可以從源中接收不同分割槽的資料流,從而實現多資料流接收。因此允許資料並行接收,提高整體的吞吐量。
val numStreams = 5
val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...) }
val unifiedStream = streamingContext.union(kafkaStreams)
unifiedStream.print()多輸入流或者多receiver的可選的方法是明確地重新分配輸入資料流(利用inputStream.repartition()),在進一步操作之前,通過叢集的機器數分配接收的批資料。
2.任務序列化
執行kyro序列化任何可以減小任務的大小,從而減小任務傳送到slave的時間。
val conf = new SparkConf().setAppName("analyse_domain_day").set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
3.設定合適的批間隔時間(即批資料的容量)
批處理時間應該小於批間隔時間。如果時間間隔是1秒,但處理需要2秒,則處理趕不上接收,待處理的資料會越來越多,最後就嘣了。
找出正確的批容量的一個好的辦法是用一個保守的批間隔時間(5-10,秒)和低資料速率來測試你的應用程式。為了驗證你的系統是否能滿足資料處理速率,你可以通過檢查端到端的延遲值來判斷(可以在Spark驅動程式的log4j日誌中檢視”Total delay”或者利用StreamingListener介面)。如果延遲維持穩定,那麼系統是穩定的。如果延遲持續增長,那麼系統無法跟上資料處理速率,是不穩定的。你能夠嘗試著增加資料處理速率或者減少批容量來作進一步的測試。
DEMO
spark流操作kafka有兩種方式:
一種是利用接收器(receiver)和kafaka的高層API實現。
一種是不利用接收器,直接用kafka底層的API來實現(spark1.3以後引入)。
相比基於Receiver方式有幾個優點:
1、不需要建立多個kafka輸入流,然後Union他們,而使用DirectStream,spark Streaming將會建立和kafka分割槽一樣的RDD的分割槽數,而且會從kafka並行讀取資料,Spark的分割槽數和Kafka的分割槽數是一一對應的關係。
2、第一種實現資料的零丟失是將資料預先儲存在WAL中,會複製一遍資料,會導致資料被拷貝兩次:一次是被Kafka複製;另一次是寫入到WAL中。
Direct的方式是會直接操作kafka底層的元資料資訊,這樣如果計算失敗了,可以把資料重新讀一下,重新處理。即資料一定會被處理。拉資料,是RDD在執行的時候直接去拉資料。
3、Receiver方式讀取kafka,使用的是高層API將偏移量寫入ZK中,雖然這種方法可以通過資料儲存在WAL中保證資料的不對,但是可能會因為sparkStreaming和ZK中儲存的偏移量不一致而導致資料被消費了多次。
第二種方式不採用ZK儲存偏移量,消除了兩者的不一致,保證每個記錄只被Spark Streaming操作一次,即使是在處理失敗的情況下。如果想更新ZK中的偏移量資料,需要自己寫程式碼來實現。
由於直接操作的是kafka,kafka就相當於你底層的檔案系統。這個時候能保證嚴格的事務一致性,即一定會被處理,而且只會被處理一次。
首先去maven的官網上下載jar包
spark-streaming_2.10-1.6.2.jar
spark-streaming-kafka_2.10-1.6.2.jar
我的Scala是2.10的,spark是1.6.0的,下載的spark.streaming和kafka版本要與之對應,spark-streaming_2.10-1.6.2.jar中2.10是Scala版本號,1.6.2是spark版本號。當然下載1.6.1也行。
需要新增 kafka-clients-0.8.2.1.jar以及kafka_2.10-0.8.2.1.jar
這裡的2.10是Scala版本號,0.8.2.1是kafka的版本號。就下這個版本,別的版本不對應,會出錯。
在kafka的配置檔案裡面:
delete.topic.enable=true
host.name=192.168.1.66
zookeeper.connect=192.168.1.66:2181
我這裡寫主機名的話,各種報錯,所以乾脆就寫IP地址了。
啟動kafka以及ZK的步驟和kafka 1-2是一樣的。
進入/kafka_2.10-0.8.2.1 新建一個主題:
bin/kafka-topics.sh –create –zookeeper 192.168.1.66:2181 –replication-factor 1 –partitions 1 –topic test
啟動一個生產者:
bin/kafka-console-producer.sh –broker-list 192.168.1.66:9092 –topic test
在自己的電腦上執行spark程式後,在命令列輸入:
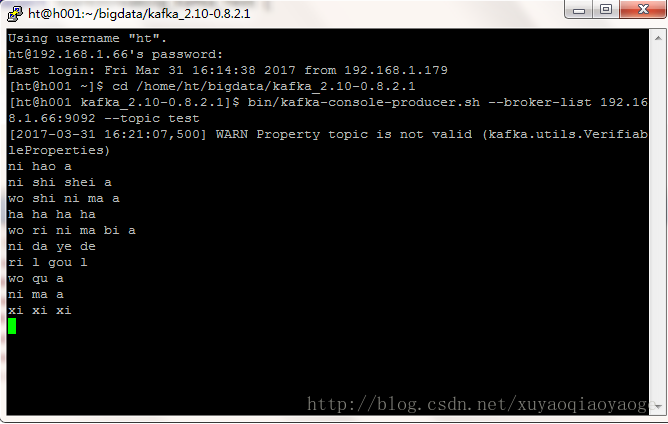
在控制檯會顯示:

package SparkStreaming
//TopicAndPartition是對 topic和partition的id的封裝的一個樣例類
import kafka.common.TopicAndPartition
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import kafka.serializer.StringDecoder
object SparkStreaming_Kafka_Test {
val kafkaParams = Map(
//kafka broker的IP加埠號,這個是必須的
"metadata.broker.list" -> "192.168.1.66:9092",
// "group.id" -> "group1",
/*此配置引數表示當此groupId下的消費者,
在ZK中沒有offset值時(比如新的groupId,或者是zk資料被清空),
consumer應該從哪個offset開始消費.largest表示接受接收最大的offset(即最新訊息),
smallest表示最小offset,即從topic的開始位置消費所有訊息.*/
"auto.offset.reset" -> "smallest"
)
val topicsSet = Set("test")
// val zkClient = new ZkClient("xxx:2181,xxx:2181,xxx:2181",Integer.MAX_VALUE,100000,ZKStringSerializer)
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("SparkStreaming_Kafka_Test")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(2))
ssc.checkpoint("F:\\checkpoint")
/*
KafkaUtils.createDirectStream[
[key的資料型別], [value的資料型別], [key解碼的類], [value解碼的類] ](
streamingContext, [Kafka配置的引數,是一個map], [topics的集合,是一個set])
*/
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)
val lines = messages.map(_._2) //取value
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
偏移量僅僅被ssc儲存在checkpoint中,消除了zk和ssc偏移量不一致的問題。所以說checkpoint就已經可以保證容錯性了。
如果需要把偏移量寫入ZK,首先在工程中新建一個包:org.apache.spark.streaming.kafka,然後建一個KafkaCluster類:
package org.apache.spark.streaming.kafka
import kafka.api.OffsetCommitRequest
import kafka.common.{ErrorMapping, OffsetAndMetadata, TopicAndPartition}
import kafka.consumer.SimpleConsumer
import org.apache.spark.SparkException
import org.apache.spark.streaming.kafka.KafkaCluster.SimpleConsumerConfig
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
import scala.util.control.NonFatal
class KafkaCluster(val kafkaParams: Map[String, String]) extends Serializable {
type Err = ArrayBuffer[Throwable]
@transient private var _config: SimpleConsumerConfig = null
def config: SimpleConsumerConfig = this.synchronized {
if (_config == null) {
_config = SimpleConsumerConfig(kafkaParams)
}
_config
}
def setConsumerOffsets(groupId: String, offsets: Map[TopicAndPartition, Long], consumerApiVersion: Short): Either[Err, Map[TopicAndPartition, Short]] = {
val meta = offsets.map {
kv => kv._1 -> OffsetAndMetadata(kv._2)
}
setConsumerOffsetMetadata(groupId, meta, consumerApiVersion)
}
def setConsumerOffsetMetadata(groupId: String, metadata: Map[TopicAndPartition, OffsetAndMetadata], consumerApiVersion: Short): Either[Err, Map[TopicAndPartition, Short]] = {
var result = Map[TopicAndPartition, Short]()
val req = OffsetCommitRequest(groupId, metadata, consumerApiVersion)
val errs = new Err
val topicAndPartitions = metadata.keySet
withBrokers(Random.shuffle(config.seedBrokers), errs) { consumer =>
val resp = consumer.commitOffsets(req)
val respMap = resp.commitStatus
val needed = topicAndPartitions.diff(result.keySet)
needed.foreach { tp: TopicAndPartition =>
respMap.get(tp).foreach { err: Short =>
if (err == ErrorMapping.NoError) {
result += tp -> err
} else {
errs.append(ErrorMapping.exceptionFor(err))
}
}
}
if (result.keys.size == topicAndPartitions.size) {
return Right(result)
}
}
val missing = topicAndPartitions.diff(result.keySet)
errs.append(new SparkException(s"Couldn't set offsets for ${missing}"))
Left(errs)
}
private def withBrokers(brokers: Iterable[(String, Int)], errs: Err)(fn: SimpleConsumer => Any): Unit = {
brokers.foreach { hp =>
var consumer: SimpleConsumer = null
try {
consumer = connect(hp._1, hp._2)
fn(consumer)
} catch {
case NonFatal(e) =>
errs.append(e)
} finally {
if (consumer != null) {
consumer.close()
}
}
}
}
def connect(host: String, port: Int): SimpleConsumer =
new SimpleConsumer(host, port, config.socketTimeoutMs,
config.socketReceiveBufferBytes, config.clientId)
}
然後在主函式中:
// 手動更新ZK偏移量,使得基於ZK偏移量的kafka監控工具可以使用
messages.foreachRDD(rdd => {
// 先處理訊息
val lines = rdd.map(_._2) //取value
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.foreach(println)
// 再更新offsets
//spark內部維護kafka偏移量資訊是儲存在HasOffsetRanges類的offsetRanges中
//OffsetRange 包含資訊有:topic名字,分割槽Id,開始偏移,結束偏移。
val offsetsList = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //得到該 rdd 對應 kafka 的訊息的 offset
val kc = new KafkaCluster(kafkaParams)
for (offsets <- offsetsList) {
val topicAndPartition = TopicAndPartition("test", offsets.partition)
val o = kc.setConsumerOffsets("group1", Map((topicAndPartition, offsets.untilOffset)),8)
if (o.isLeft) {
println(s"Error updating the offset to Kafka cluster: ${o.left.get}")
}
}
})下面是用kafka的API自己寫一個程式讀取檔案,作為kafka的生產者,需要將Scala和kafka的所有的jar包都匯入,lib資料夾下面的都匯入進去。
如果沒有2臺電腦,可以開2個開發環境,IDEA作為消費者,eclipse作為生產者。
生產者程式碼如下:
package spark_streaming_kafka_test;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class MakeRealtimeDate extends Thread {
private Producer<Integer, String> producer;
public MakeRealtimeDate() {
Properties props = new Properties();
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("zk.connect", "192.168.1.66:2181");
props.put("metadata.broker.list", "192.168.1.66:9092");
ProducerConfig pc = new ProducerConfig(props);
producer = new Producer<Integer, String>(pc);
}
public void run() {
while (true) {
File file = new File("C:\\Users\\Administrator\\Desktop\\wordcount.txt");
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file));
} catch (FileNotFoundException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
String lineTxt = null;
try {
while ((lineTxt = reader.readLine()) != null) {
System.out.println(lineTxt);
producer.send(new KeyedMessage<Integer, String>("test", lineTxt));
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new MakeRealtimeDate().start();
}
}
先啟動之前寫的sparkstreaming消費者統計單詞個數的程式,然後再啟動我們現在寫的這個生產者程式,最後就會在IDEA的控制檯中看到實時結果。
相關推薦
flume+kafka+spark streaming(持續更新)
kafka Kafka是一種高吞吐量的分散式釋出訂閱訊息系統,它可以處理消費者規模的網站中的所有動作流資料。 kafka的設計初衷是希望作為一個統一的資訊收集平臺,能夠實時的收集反饋資訊,並需要能夠支撐較大的資料量,且具備良好的容錯能力. Apache
基於Flume+Kafka+Spark Streaming打造實時流處理項目實戰課程
大數據本課程從實時數據產生和流向的各個環節出發,通過集成主流的分布式日誌收集框架Flume、分布式消息隊列Kafka、分布式列式數據庫HBase、及當前最火爆的Spark Streaming打造實時流處理項目實戰,讓你掌握實時處理的整套處理流程,達到大數據中級研發工程師的水平!下載地址:百度網盤下載
大資料求索(9): log4j + flume + kafka + spark streaming實時日誌流處理實戰
大資料求索(9): log4j + flume + kafka + spark streaming實時日誌流處理實戰 一、實時流處理 1.1 實時計算 跟實時系統類似(能在嚴格的時間限制內響應請求的系統),例如在股票交易中,市場資料瞬息萬變,決策通常需要秒級甚至毫秒級。通俗來
基於 Flume+Kafka+Spark Streaming 實現實時監控輸出日誌的報警系統
運用場景:我們機器上每天或者定期都要跑很多工,很多時候任務出現錯誤不能及時發現,導致發現的時候任務已經掛了很久了。 解決方法:基於 Flume+Kafka+Spark Streaming 的框架對這些任務的輸出日誌進行實時監控,當檢測到日誌出現Error的資訊就傳送郵件給
Flume+Kafka+Spark Streaming實現大資料實時流式資料採集
大資料實時流式資料處理是大資料應用中最為常見的場景,與我們的生活也息息相關,以手機流量實時統計來說,它總是能夠實時的統計出使用者的使用的流量,在第一時間通知使用者流量的使用情況,並且最為人性化的為使用者提供各種優惠的方案,如果採用離線處理,那麼等到使用者流量超標
flume+zookeeper+kafka+spark streaming
1.flume安裝部署 1.1、下載安裝介質,並解壓: cd /usr/local/wget http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.7.0.tar.gztar -zxvf flume-ng-1.6.0-cdh
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(三)安裝spark2.2.1
node word clas 執行 選擇 dir clust 用戶名 uil 如何配置centos虛擬機請參考《Kafka:ZK+Kafka+Spark Streaming集群環境搭建(一)VMW安裝四臺CentOS,並實現本機與它們能交互,虛擬機內部實現可以上網。》 如
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(九)安裝kafka_2.11-1.1.0
itl CA blog tor line cat pre PE atan 如何搭建配置centos虛擬機請參考《Kafka:ZK+Kafka+Spark Streaming集群環境搭建(一)VMW安裝四臺CentOS,並實現本機與它們能交互,虛擬機內部實現可以上網。》 如
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(二)VMW安裝四臺CentOS,並實現本機與它們能交互,虛擬機內部實現可以上網。
centos 失敗 sco pan html top n 而且 div href Centos7出現異常:Failed to start LSB: Bring up/down networking. 按照《Kafka:ZK+Kafka+Spark Streaming集群環
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(十三)定義一個avro schema使用comsumer發送avro字符流,producer接受avro字符流並解析
finall ges records ring ack i++ 一個 lan cde 參考《在Kafka中使用Avro編碼消息:Consumer篇》、《在Kafka中使用Avro編碼消息:Producter篇》 pom.xml <depende
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(十七)待整理
lan post -a 客戶端 客戶 struct bsp www get redis按照正則批量刪除key redis客戶端--jedis 在Spark結構化流readStream、writeStream 輸入輸出,及過程ETL Spark Structur
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(十九)待整理
set dstream 搭建 details 編程指南 .com .cn csdn read redis按照正則批量刪除key redis客戶端--jedis 在Spark結構化流readStream、writeStream 輸入輸出,及過程ETL Spark St
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(二十三)Structured Streaming遇到問題:Set(TopicName-0) are gone. Some data may have been missed
ack loss set div top 過程 pan check use 事情經過:之前該topic(M_A)已經存在,而且正常消費了一段時間,後來刪除了topic(M_A),重新創建了topic(M-B),程序使用新創建的topic(M-B)進行實時統計操作,執行過程中
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(二十五)Structured Streaming:同一個topic中包含一組數據的多個部分,按照key它們拼接為一條記錄(以及遇到的問題)。
eas array 記錄 splay span ack timestamp b- each 需求: 目前kafka的topic上有一批數據,這些數據被分配到9個不同的partition中(就是發布時key:{m1,m2,m3,m4...m9},value:{records
計算成交量例子,kafka/spark streaming/zk
package com.ws.streaming import kafka.common.TopicAndPartition import kafka.message.MessageAndMetadata import kafka.serializer.StringDecoder impor
學習筆記 --- Kafka Spark Streaming獲取Kafka資料 Receiver與Direct的區別
Receiver 使用Kafka的高層次Consumer API來實現 receiver從Kafka中獲取的資料都儲存在Spark Executor的記憶體中,然後Spark Streaming啟動的job會去處理那些資料 要啟用高可靠機制,讓資料零丟失,就必須啟用Spark
kafka+spark streaming程式碼例項(pyspark+python)
一、系統準備1.啟動zookeeper:bin/zkServer.cmd start2.啟動kafka:bin/kafka-server-start.sh -daemon config/server.properties3.啟動spark:sbin/start-all.sh資
Kafka+Spark Streaming+Redis實時系統實踐
基於Spark通用計算平臺,可以很好地擴充套件各種計算型別的應用,尤其是Spark提供了內建的計算庫支援,像Spark Streaming、Spark SQL、MLlib、GraphX,這些內建庫都提供了高階抽象,可以用非常簡潔的程式碼實現複雜的計算邏輯、這也得益於S
Flume+Kakfa+Spark Streaming整合(執行WordCount小例子)
環境版本:Scala 2.10.5; Spark 1.6.0; Kafka 0.10.0.1; Flume 1.6.0 Flume/Kafka的安裝配置請看我之前的部落格: http://blog.c
ZK+Kafka+Spark Streaming叢集環境搭建(九)安裝kafka_2.11-1.1.0
安裝kafka的伺服器:192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 slave2 192.168.0.123 slave3備註:只在slave1,slave2,slave3三個節店上安裝zookeepe