
Kafka+Spark Streaming+Redis實時系統實踐
我們的應用場景是分析使用者使用手機App的行為,描述如下所示:
1、手機客戶端會收集使用者的行為事件(我們以點選事件為例),將資料傳送到資料伺服器,我們假設這裡直接進入到Kafka訊息佇列
2、後端的實時服務會從
3、經過Spark Streaming實時計算程式分析,將結果寫入Redis,可以實時獲取使用者的行為資料,並可以匯出進行離線綜合統計分析
Kafka+Spark Streaming+Redis程式設計實踐
下面,我們根據上面提到的應用場景,來程式設計實現這個實時計算應用。首先,寫了一個Kafka Producer模擬程式,用來模擬向Kafka實時寫入使用者行為的事件資料,資料是JSON格式,示例如下:
檢視原始碼1 |
{ |
2 |
"uid":"068b746ed4620d25e26055a9f804385f", |
3 |
"event_time":"1430204612405", |
4 |
"os_type":"Android",
|
5 |
"click_count": 6 |
6 |
} |
一個事件包含4個欄位:
1、uid:使用者編號
2、event_time:事件發生時間戳
3、os_type:手機App
4、click_count:點選次數
下面是我們實現的程式碼,如下所示:
01 |
package
com.iteblog.spark.streaming.utils |
02 |
03 |
import
java.util.Properties |
04 |
import
scala.util.Properties |
05 |
import
org.codehaus.jettison.json.JSONObject |
06 |
import
kafka.javaapi.producer.Producer |
07 |
import
kafka.producer.KeyedMessage |
08 |
import
kafka.producer.KeyedMessage |
09 |
import
kafka.producer.ProducerConfig |
10 |
import
scala.util.Random |
11 |
12 |
object
KafkaEventProducer { |
13 |
14 |
privateval
users =Array(
|
15 |
"4A4D769EB9679C054DE81B973ED5D768","8dfeb5aaafc027d89349ac9a20b3930f", |
16 |
"011BBF43B89BFBF266C865DF0397AA71","f2a8474bf7bd94f0aabbd4cdd2c06dcf", |
17 |
"068b746ed4620d25e26055a9f804385f","97edfc08311c70143401745a03a50706", |
18 |
"d7f141563005d1b5d0d3dd30138f3f62","c8ee90aade1671a21336c721512b817a", |
19 |
"6b67c8c700427dee7552f81f3228c927","a95f22eabc4fd4b580c011a3161a9d9d") |
20 |
21 |
privateval
random =new
Random() |
22 |
23 |
privatevar
pointer =-1 |
24 |
25 |
defgetUserID()
:String
= { |
26 |
pointer=
pointer + 1 |
27 |
if(pointer >=users.length) {
|
28 |
pointer=
0 |
29 |
users(pointer) |
30 |
}
else { |
31 |
users(pointer) |
32 |
}
|
33 |
}
|
34 |
35 |
defclick()
: Double
= { |
36 |
random.nextInt(10) |
37 |
}
|
38 |
39 |
// bin/kafka-topics.sh --zookeeper zk1:2181,zk2:2181,zk3:2181/kafka --create --topic user_events --replication-factor 2 --partitions 2 |
40 |
// bin/kafka-topics.sh --zookeeper zk1:2181,zk2:2181,zk3:2181/kafka --list |
41 |
// bin/kafka-topics.sh --zookeeper zk1:2181,zk2:2181,zk3:2181/kafka --describe user_events |
42 |
// bin/kafka-console-consumer.sh --zookeeper zk1:2181,zk2:2181,zk3:22181/kafka --topic test_json_basis_event --from-beginning |
43 |
defmain(args:
Array[String]):
Unit =
{ |
44 |
valtopic
= "user_events" |
45 |
valbrokers
= "10.10.4.126:9092,10.10.4.127:9092" |
46 |
valprops
= new
Properties() |
47 |
props.put("metadata.broker.list", brokers) |
48 |
props.put("serializer.class","kafka.serializer.StringEncoder") |
49 |
50 |
valkafkaConfig
=new
ProducerConfig(props) |
51 |
valproducer
= new
Producer[String, String](kafkaConfig) |
52 |
53 |
while(true) { |
54 |
// prepare event data |
55 |
valevent
= new
JSONObject() |
56 |
event |
57 |
.put("uid", getUserID) |
58 |
.put("event_time", System.currentTimeMillis.toString) |
59 |
.put("os_type","Android")
|
60 |
.put("click_count", click) |
61 |
62 |
// produce event message |
63 |
producer.send(newKeyedMessage[String, String](topic, event.toString))
|
64 |
println("Message sent: "+ event)
|
65 |
66 |
Thread.sleep(200) |
67 |
}
|
68 |
}
|
69 |
} |
通過控制上面程式最後一行的時間間隔來控制模擬寫入速度。下面我們來討論實現實時統計每個使用者的點選次數,它是按照使用者分組進行累加次數,邏輯比較簡單,關鍵是在實現過程中要注意一些問題,如物件序列化等。先看實現程式碼,稍後我們再詳細討論,程式碼實現如下所示:
檢視原始碼 列印幫助01 |
object
UserClickCountAnalytics { |
02 |
03 |
defmain(args:
Array[String]):
Unit =
{ |
04 |
varmasterUrl
= "local[1]" |
05 |
if(args.length >
0) { |
06 |
masterUrl=
args(0) |
07 |
}
|
08 |
09 |
// Create a StreamingContext with the given master URL |
10 |
valconf
= new
SparkConf().setMaster(masterUrl).setAppName("UserClickCountStat") |
11 |
valssc
= new
StreamingContext(conf, Seconds(5)) |
12 |
13 |
// Kafka configurations |
14 |
valtopics
= Set("user_events") |
15 |
valbrokers
= "10.10.4.126:9092,10.10.4.127:9092" |
16 |
valkafkaParams
=Map[String, String](
|
17 |
"metadata.broker.list"-> brokers,
"serializer.class"->
"kafka.serializer.StringEncoder") |
18 |
19 |
valdbIndex
= 1 |
20 |
valclickHashKey
="app::users::click" |
21 |
22 |
// Create a direct stream |
23 |
valkafkaStream
=KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) |
24 |
25 |
valevents
= kafkaStream.flatMap(line
=> { |
26 |
valdata
= JSONObject.fromObject(line._2) |
27 |
Some(data) |
28 |
})
|
29 |
30 |
// Compute user click times |
31 |
valuserClicks
= events.map(x
=> (x.getString("uid"), x.getInt("click_count"))).reduceByKey(_+
_) |
32 |
userClicks.foreachRDD(rdd=> {
|
33 |
rdd.foreachPartition(partitionOfRecords=> {
|
34 |
partitionOfRecords.foreach(pair=> {
|
35 |
valuid
= pair._1 |
36 |
valclickCount
= pair._2 |
37 |
valjedis
= <SPAN
class=wp_keywordlink_affiliate><A
title=""href=target=_blank
data-original-title="View all posts in Redis"jQuery1830668587673401759="50">Redis</A></SPAN>Client.pool.getResource |
38 |
jedis.select(dbIndex) |
39 |
jedis.hincrBy(clickHashKey, uid, clickCount) |
40 |
RedisClient.pool.returnResource(jedis) |
41 |
}) |
42 |
}) |
43 |
})
|
44 |
45 |
ssc.start() |
46 |
ssc.awaitTermination() |
47 |
48 |
}
|
49 |
} |
上面程式碼使用了Jedis客戶端來操作Redis,將分組計數結果資料累加寫入Redis儲存,如果其他系統需要實時獲取該資料,直接從Redis實時讀取即可。RedisClient實現程式碼如下所示:
檢視原始碼 列印幫助01 |
object
RedisClient extends
Serializable { |
02 |
valredisHost
= "10.10.4.130" |
03 |
valredisPort
= 6379 |
04 |
valredisTimeout
=30000 |
05 |
lazyval
pool =new
JedisPool(newGenericObjectPoolConfig(), redisHost, redisPort, redisTimeout) |
06 |
07 |
lazyval
hook =new
Thread { |
08 |
overridedef
run ={
|
09 |
println("Execute hook thread: "+
this) |
10 |
pool.destroy() |
11 |
}
|
12 |
}
|
13 |
sys.addShutdownHook(hook.run) |
14 |
} |
上面程式碼我們分別在local[K]和Spark Standalone叢集模式下執行通過。
如果我們是在開發環境進行除錯的時候,也就是使用local[K]部署模式,在本地啟動K個Worker執行緒來計算,這K個Worker在同一個JVM例項裡,上面的程式碼預設情況是,如果沒有傳引數則是local[K]模式,所以如果使用這種方式在建立Redis連線池或連線的時候,可能非常容易除錯通過,但是在使用Spark Standalone、YARN Client(YARN Cluster)或Mesos叢集部署模式的時候,就會報錯,主要是由於在處理Redis連線池或連線的時候出錯了。我們可以看一下Spark架構,如圖所示(來自官網):
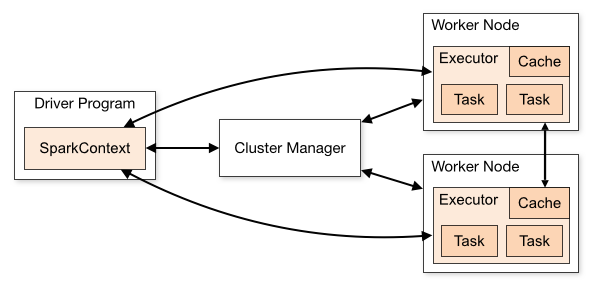
無論是在本地模式、Standalone模式,還是在Mesos或YARN模式下,整個Spark叢集的結構都可以用上圖抽象表示,只是各個元件的執行環境不同,導致元件可能是分散式的,或本地的,或單個JVM例項的。如在本地模式,則上圖表現為在同一節點上的單個程序之內的多個元件;而在YARN Client模式下,Driver程式是在YARN叢集之外的一個節點上提交Spark Application,其他的元件都執行在YARN叢集管理的節點上。
在Spark叢集環境部署Application後,在進行計算的時候會將作用於RDD資料集上的函式(Functions)傳送到叢集中Worker上的Executor上(在Spark Streaming中是作用於DStream的操作),那麼這些函式操作所作用的物件(Elements)必須是可序列化的,通過Scala也可以使用lazy引用來解決,否則這些物件(Elements)在跨節點序列化傳輸後,無法正確地執行反序列化重構成實際可用的物件。上面程式碼我們使用lazy引用(Lazy Reference)來實現的,程式碼如下所示:
檢視原始碼 列印幫助01 |
// lazy pool reference |
02 |
lazy
val pool =new
JedisPool(newGenericObjectPoolConfig(), redisHost, redisPort, redisTimeout) |
03 |
... |
04 |
partitionOfRecords.foreach(pair
=> { |
05 |
valuid
= pair._1 |
06 |
valclickCount
= pair._2 |
07 |
valjedis
= RedisClient.pool.getResource
|
08 |
jedis.select(dbIndex) |
09 |
jedis.hincrBy(clickHashKey, uid, clickCount) |
10 |
RedisClient.pool.returnResource(jedis) |
11 |
}) |
另一種方式,我們將程式碼修改為,把對Redis連線的管理放在操作DStream的Output操作範圍之內,因為我們知道它是在特定的Executor中進行初始化的,使用一個單例的物件來管理,如下所示:
檢視原始碼 列印幫助001 |
package
org.shirdrn.spark.streaming |
002 |
003 |
import
org.apache.commons.pool2.impl.GenericObjectPoolConfig |
004 |
import
org.apache.spark.SparkConf |
005 |
import
org.apache.spark.streaming.Seconds |
006 |
import
org.apache.spark.streaming.StreamingContext |
007 |
import
org.apache.spark.streaming.dstream.DStream.toPairDStreamFunctions |
008 |
import
org.apache.spark.streaming.kafka.KafkaUtils |
009 |
010 |
import
kafka.serializer.StringDecoder |
011 |
import
net.sf.json.JSONObject |
012 |
import
redis.clients.jedis.JedisPool |
013 |
014 |
object
UserClickCountAnalytics { |
015 |
016 |
defmain(args:
Array[String]):
Unit =
{ |
017 |
varmasterUrl
= "local[1]" |
018 |
if(args.length >
0) { |
019 |
masterUrl=
args(0) |
020 |
}
|
021 |
022 |
// Create a StreamingContext with the given master URL |
023 |
valconf
= new
SparkConf().setMaster(masterUrl).setAppName("UserClickCountStat") |
024 |
valssc
= new
StreamingContext(conf, Seconds(5)) |
025 |
026 |
// Kafka configurations |
027 |
valtopics
= Set("user_events") |
028 |
valbrokers
= "10.10.4.126:9092,10.10.4.127:9092" |
029 |
valkafkaParams
=Map[String, String](
|
030 |
"metadata.broker.list"-> brokers,
"serializer.class"->
"kafka.serializer.StringEncoder") |
031 |
032 |
valdbIndex
= 1 |
033 |
valclickHashKey
="app::users::click" |
034 |
035 |
// Create a direct stream |
036 |
valkafkaStream
=KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) |
037 |
038 |
valevents
= kafkaStream.flatMap(line
=> { |
039 |
valdata
= JSONObject.fromObject(line._2) |
040 |
Some(data) |
041 |
})
|
042 |
043 |
// Compute user click times |
044 |
valuserClicks
= events.map(x
=> (x.getString("uid"), x.getInt("click_count"))).reduceByKey(_+
_) |
045 |
userClicks.foreachRDD(rdd=> {
|
046 |
rdd.foreachPartition(partitionOfRecords=> {
|
047 |
partitionOfRecords.foreach(pair=> {
|
048 |
049 |
/** |
050 |
* Internal Redis client for managing Redis connection {@link Jedis} based on {@link RedisPool} |
051 |
*/ |
052 |
object
|