
python 提取pdf檔案中的資訊
python 讀取pdf檔案有3個擴充套件包 pdfminer3k(python2中為pdfminer)、fitz和pymupdf
1.pdfminer3k
讀取並獲得pdf文件中的資訊:
from pdfminer.pdfparser import PDFParser,PDFDocument from pdfminer.pdfinterp import PDFResourceManager,PDFPageInterpreter,PDFTextExtractionNotAllowed from pdfminer.converter import PDFPageAggregator from pdfminer.layout import LTTextBoxHorizontal,LAParams,LTTextLineHorizontal,LTFigure,LTRect,LTLine,LTCurve # 檔案物件 pd_file = open("d.pdf", "rb") # pdf檔案解析物件 parser = PDFParser(pd_file) # print(parser) # pdf文件物件 document = PDFDocument() parser.set_document(document) document.set_parser(parser) # 初始化文件密碼 document.initialize() if document.is_extractable: print(True) else: raise PDFTextExtractionNotAllowed # 儲存文件資源 src = PDFResourceManager() # 裝置物件 device = PDFPageAggregator(src,laparams=LAParams()) # 直譯器物件 inter = PDFPageInterpreter(src,device) pages = document.get_pages() for page in pages: #print(page.contents) inter.process_page(page) layout = device.get_result() for x in layout: if isinstance(x, LTTextBoxHorizontal): print(str(x.get_text())) #t = dir(x) #print(t) #print(type(x))
以上程式碼屬於搬運工 (~自帶笑哭表情~~~)
上述程式碼中各個物件的作用:
檔案解析物件(PDFParser):從檔案中提取資料
文件物件(PDFDocument): 儲存提取到的資料
資源物件(PDFResourceManager):儲存共享內容
裝置物件(PDFDevice):處理資源物件為我們所需要的格式
直譯器物件(PDFPageInterpreter): 處理頁面內容

layout : 包含文件的全部內容物件主要包含:
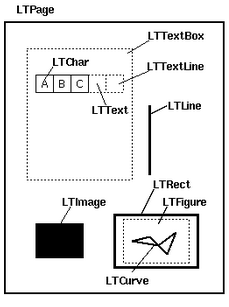
LTPage:頁面物件
LTTextBox:代表一個區域內的文字資訊,包含多個LTTextLine,get_text()方法可以獲得文字內容。
LTTextLine:代表一行文字資訊,包含多個LTChar,get_text()方法可以獲得文字內容。
LTChar:代表一個字元資訊,get_text()方法可以獲得文字內容。
LTAnno:代表文字中的字元的Unicode字串。
LTFigure:代表PDF的表單物件,可以包含圖形或圖片。
LTImage:代表一個圖片物件。
LTLine : 代表一條直線。
LTRect:代表一個矩形區域。
LTCurve:代表一條曲線。
tip:LTTextBox、LTTextLine可以分別和Horizontal、Vertical 組合表示水平方向和垂直方向
文件物件(Document)常用屬性和方法:
doc.get_outlines(): 獲取文件的目錄資料
doc.is_extractable(): 判斷文件是否支援轉文字
doc.get_pages(): 獲取所有頁面物件
doc.initialize():初始化文件密碼
doc.set_parser():繫結文件解析對像
內容物件(LTTextBox、LTTextLine、LTImage...等等)常用屬性和方法:
LTImage:
LTImage.get_rawdata(): 獲取圖片資料
2. fitz 包:
3.pymupdf包:
操作pdf檔案,可以實現建立pdf檔案、修改pdf檔案等等。。功能強大。(以後補充...)
相關推薦
python 提取pdf檔案中的資訊
python 讀取pdf檔案有3個擴充套件包 pdfminer3k(python2中為pdfminer)、fitz和pymupdf 1.pdfminer3k 讀取並獲得pdf文件中的資訊: from pdfminer.pdfparser import PDFPars
如何用Python從PDF檔案中提取文字詞彙
在日常工作中,有時可能需要解析一些 PDF 檔案,提取檔案中的關鍵詞,好讓它們能夠被我們搜尋。解決這個問題的重要部分就是找到如何從 PDF 檔案中提取文字資料的方法。從如果是幾張或者幾十張倒還好辦,那要是幾百幾千張,可能就有點麻煩了。 幸好我們可以用 Python 完成這項工作。下面就分享
提取PDF檔案中的文字資訊
我們從網上下載的PDF檔案有的是加密處理過的,無法複製其中的內容,對於這類檔案的內容提取可以通過該工具實現 PDF加密 PDF檔案經過加密處理之後是無法簡單的複製的,PDF檔案的屬性也如下圖所示: 工具的使用方法 軟體的目錄結構如
怎麼提取pdf檔案中的圖片
通常我們在網上下載的PDF檔案中,圖片和文字都是在一起的,當我們看到一些好看的圖片想儲存下來的時候,那麼,我們怎麼提取PDF檔案中的圖片呢,小編在這裡向大家簡單的介紹一下提取PDF檔案中的圖片吧。 1、PDF檔案大家都知道是無法修改的,那我們怎麼把裡面好看的圖片提取出來呢。2、首先我們要在電腦上安裝一個××
電腦中如何提取PDF檔案中的圖片
通常,我們在一些PDF檔案中看到一些好看的圖片,想將圖片儲存下來,但是PDF檔案是無法編輯的,在檔案自身當中我們無法將圖片完成的提取出來,因此大家都會想辦法在不破壞圖片完整性的情況下將圖片從PDF檔案中提取出來,下面就跟大家分享一下小編是從電腦中如何提取PDF檔案中的圖片。藉助工具:×××換器1.在PDF檔案
手把手教你如何用Python從PDF檔案中匯出資料(附連結)
有很多時候你會想用Python從PDF中提取資料,然後將其匯出成其他格式。不幸的是,並沒有多少Python包可以很好的執行這部分工作。在這篇貼子中,我們將探討多個不同的Python包,並學習如何從PDF中提取某些圖片。儘管在Python中沒有一個完整的解決方案,你還是應該能夠運用這裡的技能開始上手。
如何提取PDF檔案中的圖片
在處理一些文件資料的時候有時需要將裡面的某些型別的內容單獨提取出來,提取文件中的圖片就是很常見。可是不同型別的文件在操作上都有些不同,如果是要提取PDF中的圖片又該如何進行操作呢? 首先介紹最常見的方法——直接開啟檔案對文件中的圖片進行一一儲存,如果圖片不多可以
提取pdf檔案中文字的兩種方法
如今,在我們的工作與學習中已經不是單單使用word、Excel等格式檔案了,pdf格式的檔案已經被廣泛地運用到我們的辦公室中。大家都知道pdf檔案是不可直接編輯與修改的,使用起來有些不便。那麼
Python libtorrent提取種子檔案中的資訊
種子檔案最麻煩的就是提取種子檔案的檔案列表,有的種子檔案數上百上千的,處理起來頭疼死你。 這段指令碼只提取種子檔案中按檔案大小排序最大的5個檔案的檔名和大小,儲存為字串便於插入資料庫 如: Blood and Ties 2013 1080p BluRay x264
提取加密檔案中的pdf
買的考研資料電子版是加密的exe,只能在Windows系統檢視,很不方便,其實我們可以把其中的pdf提取出來。 這種方法適用於在有閱讀密碼的情況下,提取pdf檔案。 思路:剛開始在網上看到網友說替換pdf中的endstream之前的內容,對於普通的pdf檔案來說,會缺少前幾頁,這
python操作txt檔案中資料教程[2]-python提取txt檔案
python操作txt檔案中資料教程[2]-python提取txt檔案中的行列元素 覺得有用的話,歡迎一起討論相互學習~Follow Me 原始txt檔案 程式實現後結果-將txt中元素提取並儲存在csv中 程式實現 import csv filename = "./test/te
怎麼把PDF檔案中的圖片全部提取出來
提取PDF檔案中的圖片內容看似簡單,但是如果文件特別大,而且圖片也特別多的話,想要一次性將PDF中的圖片內容提取出來恐怕就不那麼簡單了。 通過一些pdf的網頁工具我們可以線上對PDF檔案中的圖
用Python將gml檔案中邊的資訊輸出為csv(或者txt)格式
最近在做複雜網路方面的內容,初學python。需要將gml格式的圖的資訊中邊的資訊提取出來,輸出為csv格式和txt格式。 英文描述如下: Use python to convert the edge information stored in gml file to a
Python提取PDF中的圖片
# 2018/08/16更新: 有些同學不知道fitz庫是什麼,它是pymupdf中的一個模組,操作PDF非常舒服,只需要pip安裝即可: pip install pymupdf Python提取word中的圖片(需要的自取): 最近專案需要把word、PDF中的
Python把csv檔案中的資訊寫入字典中指令碼(嘗試)
該段程式碼,只供參考,與期望不符合,後期會附上,完成的指令碼原始碼! #coding=utf8 import csv class GenExceptData(object): def __init__(self): try:
在PDF檔案中添加簽名的方法
工作中,時常會需要將紙質檔案掃描成PDF檔案。當我們忘記在紙質檔案上簽名而檔案已經掃描時,我們該如何直接在PDF檔案中添加簽名呢?今天,小編就給大家帶來在PDF檔案中添加簽名的方法。 1、首先我們需要通過PDF編輯器開啟我們需要添加簽名的PDF檔案,這裡我們使用編輯器是比較常見的,其他編
python讀取yaml檔案中的資料
注意:在python2中進行 讀取方式有兩種 程式碼中的其中一種方式以註釋的形式展現出來: yaml中檔案的內容如下: 'top寬度:': '27' # ----------- 必須 ----------------------- # 計算機使用者名稱 username: onepoi
Python從txt檔案中逐行讀取資料
Python從txt檔案中逐行讀取資料 # -*-coding:utf-8-*- import os for line in open("./samples/label_val.txt"): print('line=', line, end = '') #後面
python修改txt檔案中的某一項
在做task中,需要將TXT文字中的某一項註釋修改,但是python對txt文字只有寫入和讀取兩種操作。 我採用的方法是: 1.讀取txt檔案,將每一行資料,加入新建立的list中。 2.在list中修改資料 3.再新建一個txt檔案,按行存入資料。記得新增 ‘/n’ 分行 例項
用python從txt檔案中讀入資料
現在有如下資料集儲存在txt檔案中,利用python逐行讀取資料到list型別下。 1.658985 4.285136 -3.453687 3.424321 4.838138 -1.151539 -5.379713 -3.362104 0.972564