
資料結構之連結串列(1):單鏈表基本操作
1.前言
1.1宣告
文章中的文字可能存在語法錯誤以及標點錯誤,請諒解;
如果在文章中發現程式碼錯誤或其它問題請告知,感謝!
2.關於連結串列
2.1什麼是連結串列
連結串列可以看成一種在物理儲存單元上的非連續、非順序儲存的資料結構,該資料結構中的結點(資料元素)邏輯順序通過連結串列中指標連結次序實現。結點可以在程式執行是動態生成。每一個結點包括兩部分:一個是儲存資料元素的資料域,另一個是儲存下一個結點地址的指標域。
連結串列可以分為 單向連結串列 雙向連結串列 迴圈連結串列 等。
單鏈表指連結串列中的每個結點,有指向該連結串列中這個結點的下一個結點或者為空的指標,是一種線性連結串列。

單鏈表(不帶頭節點)

單鏈表(帶頭節點)
*關於頭節點知識可以參看下面。
雙鏈表和單鏈表的不同之處在於,每個連結串列結點中既有指向下一個結點的指標,又有指向前一個結點的指標,其中每個結點都有兩種指標,即pPrev和pNEXT。pPrev指標指向左邊結點,pNEXT指標指向右邊結點。

雙鏈表(不帶頭節點)

雙鏈表(帶頭節點)
迴圈連結串列指的是在單向連結串列和雙向連結串列的基礎上,將兩種連結串列的最後一個結點指向第一個結點從而實現迴圈。
2.2連結串列的意義
連結串列的出現是解決其他資料結構在應用中出現的侷限性,例如陣列,在陣列中所有元素的的型別必須相同,在實際程式設計應用中,我們希望可以儲存的不同型別資料;並且一般來說陣列在定義的時候需要指出其大小(除了Linux核心中可以使用變長陣列,C++中也支援變長陣列);另外陣列中某個元素的移動會造成其它元素的大面積移動,存在效率問題。
2.3連結串列的作用
解決其他資料結構在應用中出現的侷限性,實現資料元素的儲存按一定順序儲存,允許在任意位置插入和刪除結點,提高效率。
2.4連結串列的優點和缺點
連結串列的優點:
1.採用動態記憶體分配,物理儲存單元不用連續,能夠有效的分配和利用記憶體資源;
2.節點插入和刪除時不需要移動其他元素,不需要記憶體空間的重組。
連結串列的缺點:
1.不能進行索引訪問,只能從頭結點(或頭指標)開始順序查詢;
2.資料結構較為複雜,需要大量的指標操作,容易出錯。
3單鏈表的實現
3.1單鏈表的實現步驟
單鏈表從建立到使用的需要如下步驟:
1.定義節點型別;
2.定義一個頭指標;
3.建立第一個結點 ,並將頭指標指向第一個節點;
4.繼續建立節點,將前一個節點的指標指向新建立節點的地址;
5.以此類推,需要多少長度連結串列按照上面步驟進行節點增加,最終形成一個完整連結串列。
3.2構建一個簡單鏈表(從連結串列尾部插入節點)
按照3.1首先定義節點型別,要注意每個結點包括有效資料以及指標兩個部分,構建結點的方法是構建一個結構體,為了簡明起見,定義一個數據為int型,指標為struct node*型別的節點:
struct node
{
int data;
struct node *pNext;
}需要強調的是,該結構體只是給結點的定義一個型別,並不佔用記憶體,只有使用該型別建立結點的時候,創建出來的節點才會佔用一定的記憶體空間。
然後,定義一個頭指標(不是頭節點,注意頭指標和頭節點的區別),頭指標的型別就是節點型別,不過頭指標中的資料區不儲存資料,頭指標的指標部分指向第一個節點:
struct node *pHeader = NULL;接著,使用堆記憶體建立節點:
struct node * NodeCreate(int data)
{
struct node* p = (struct node*)malloc(sizeof(struct node));
if(NULL == p)
{
printf("Failed to malloc\n");
return NULL;
}
memset(p, 0,sizeof(struct node));
p->data = data;
p->pNext = NULL;
return NULL;
}使用這個函式,建立第一個節點,並將頭指標指向這個節點(簡明起見,設定每個節點資料區儲存節點在連結串列中的編號):
struct node* pHeader = NodeCreate(0);使用這個函式,繼續建立節點NodeCreate(1),這樣我們有了一個只有一個節點的連結串列以及一個新節點new,下面就要把這個新節點插入這個連結串列中,也就是將前一個節點的指標指向新建立節點的地址:pHeader->pNext = new,實現這個指向,可以分為兩步驟:
1.找到連結串列最後一個節點;
2.將新的節點和連結串列最後一個節點連線起來。
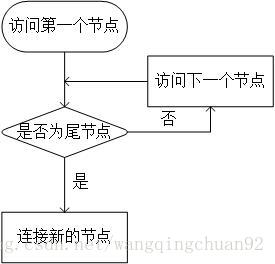
將兩個節點連線函式:
void TailInsert(struct node* pH,struct node* new)
{
struct node *p = pH;
while(NULL != p->pNext)
{
p = p->pNext;
}
p->pNext = new;
}以上,連結串列所需的函式已經完成,現在利用上述函式構建一個從尾部插入節點的三連結串列函式:
#include < stdio.h >
#include < string.h >
#include < stdio.h >
struct node
{
int data;
struct node *pNext;
}
struct node* NodeCreate(int data);
void TailInsert(struct node* pH,struct node* new);
int main(void)
{
struct node* pHeader = NodeCreate(0);
TailInsert(pHeader, NodeCreate(1);
TailInsert(pHeader, NodeCreate(2);
printf("node data1 is %d\n",pHeader->pNext);
printf("node data2 is %d\n",pHeader->pNext->data);
printf("node data3 is %d\n",pHeader->pNext->pNext->data);
return 0;
}
void TailInsert(struct node* pH,struct node* new)
{
struct node *p = pH;
while(NULL != p->pNext)
{
p = p->pNext;
}
p->pNext = new;
}
struct node * NodeCreate(int data)
{
struct node* p = (struct node*)malloc(sizeof(struct node));
if(NULL == p)
{
printf("Failed to malloc\n");
return NULL;
}
memset(p, 0,sizeof(struct node));
p->data = data;
p->pNext = NULL;
return NULL;
}有時候,根據業務要求或者方便連結串列查詢,會將頭指標指向的第一個節點作為頭節點使用。頭節點有如下特點:緊跟頭指標後面,不一定和連結串列中資料節點的型別一樣(頭節點的資料部分可以為空或者業務要求為節點總數或者其它需要儲存的資料),例如下面就是某個連結串列的頭節點和資料節點:
頭節點
typedef struct stMessageListHeadNode
{
int iListCurrentNodeNum; //當前佇列中節點的數量
int iListMax; //佇列支援的最大節點數
MESSAGE_NODE *pFirst; //指向佇列的第一個結點
MESSAGE_NODE *pLast; //指向佇列的最後一個結點
}MESSAGE_LIST_HEAD_NODE;資料節點
typedef struct stMessageNode
{
long locomotive_num;
int len;
void *pData; //節點攜帶資訊的記憶體地址
MESSAGE_NODE *pNext; //指向next節點
}MESSAGE_NODE;仍然為了簡明起見,下面使用同一型別定義頭節點和資料節點,即struct node。
除了從連結串列尾節點插入節點,也有從連結串列尾部插入節點的方法,步驟如下:
1.新節點的pNext指向原來的第一個節點首地址,即新節點和原來的第一個節點相連;
2.頭節點的pNext指向新節點的首地址,即頭節點和新節點相連。
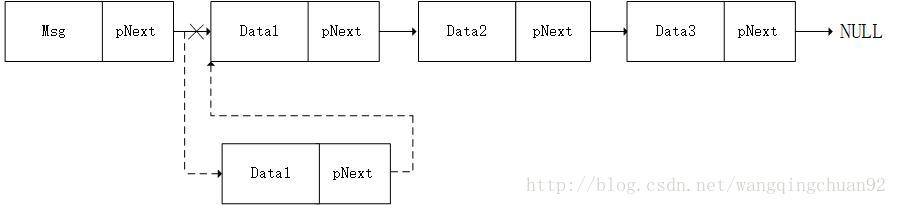
從連結串列尾部插入節點函式:
void TailInsert(struct node* pH,struct node* new)
{
new->pNext = pH->pNext;//新節點的pNext指向原來的第一個節點
pH->pNext = new;//頭節點pNext指向新節點
}3.3單鏈表遍歷
連結串列是用來儲存資料的,那麼要使用連結串列裡的資料就必須要取出來,這隻用到遍歷,即將連結串列中每一個節點中的資料取出來。
連結串列遍歷步驟:
1.指標p方位第一個有效節點並判斷是否為尾節點並取出該節點資料,若不是尾節點,將指標移至下一個節點;
2.重複步驟1,若判斷是尾節點,取出資料,停止遍歷。
單鏈錶帶頭節點時遍歷函式:
//pH為指向單鏈表的頭指標
void SearchList(struct node* pH)
{
struct node* p = pH->pNext;
while(NULL != p->pNext)
{
p->pNext;
printf("node data: %d\n",p->data);
}
}單鏈表不帶頭節點時遍歷函式:
//pH為指向單鏈表的頭指標
void SearchList(struct node* pH)
{
struct node* p = pH;
while(NULL != p->pNext)
{
printf("node data: %d\n",p->data);
p->pNext;
}
printf("node data: %d\n",p->data);
} 3.4單鏈表刪除節點
通過上述,我們知道連結串列是用來儲存資料的,既然有儲存資料,就有刪除資料,當有的時候連結串列中某個節點的資料 我們不想要了,就需要刪除該節點。
對於刪除連結串列節點,有兩種情況:刪除的節點為尾節點,刪除的節點為普通節點。
刪除普通節點
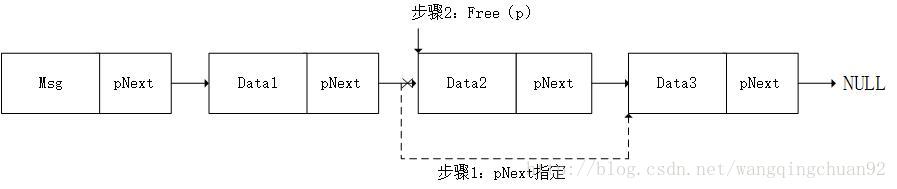
刪除尾節點

刪除節點函式
int DeleteNode(struct node* pH,int data)
{
struct node* p = pH;
struct node* pPrev = NULL;
while(NULL != p->pNext)
{
pPrev = p;
p = p->pNext;
if(p->data == data)
{
if(NULL == p->pNext);
{
pPrev->pNext = NULL;
free(p);
}
else
{
pPrev->pNext = p->pNext;
free(p);
}
return 0;
}
}
printf("No delete node!\n");
return -1;
}
以上就是連結串列的基本操縱,需要注意的是,在實際專案工程中,一般會在將頭指標和互斥鎖封裝在一個結構體中,這樣在別的執行緒在對該連結串列進行增減操作時,首先將互斥鎖上鎖,加上了一個保護,達到保證連結串列增減的正常。
以上。
相關推薦
資料結構之連結串列(1):單鏈表基本操作
1.前言 1.1宣告 文章中的文字可能存在語法錯誤以及標點錯誤,請諒解; 如果在文章中發現程式碼錯誤或其它問題請告知,感謝! 2.關於連結串列 2.1什麼是連結串列 連結串列可以看成一種在物理儲存單元上的非連續、非順序儲存的資料結構,該資
資料結構之圖篇(2):圖的基本操作 深度和廣度遍歷
程式碼實現 main.cpp(主函式) #include <iostream> #include "CMap.h" using namespace std; /** 圖的的儲存:鄰接矩陣 圖的遍歷:深度+廣度 A / \
python資料結構之連結串列(linked list)
目錄 基礎 知識 1.1 連結串列的基本結構 1.2 節點類和連結串列節點的定義 1.3 順序列印和逆序列印 連結串列的基本操作 2.1 計算連結串列長度 2.2 從前,後插入資料 2.3 查詢與刪除 參考 1.基礎 知識 1.1
c++資料結構之連結串列詳情1(順序連結串列)
長大是人必經的潰爛 ---大衛塞林格 程式碼是年輕人的新生!!!!!! 程式 = 資料結構 + 演算法 --Niklaus EmilWirth 這篇部落格在參考一些書籍和教學視訊的基礎上整理而來,中間夾雜了一些自己
資料結構——動態連結串列(C++)
定義一個節點: [cpp] view plain copy print? #include <iostream> usingnamespace std; typedefint T; struct Node{ T dat
資料結構之連結串列(LinkedList)(二)
資料結構之連結串列(LinkedList)(一) 雙鏈表 上一篇講述了單鏈表是通過next 指向下一個節點,那麼雙鏈表就是指不止可以順序指向下一個節點,還可以通過prior域逆序指向上一個節點 示意圖: 那麼怎麼來實現雙鏈表的增刪改查操作呢。 分析: 1) 遍歷 方和 單鏈表一樣,只是可以向前,也可以向後查
資料結構習題(1):單鏈表
(部分基於之前的程式碼) 1.設順序表va中的資料元素遞增有序。 試寫一演算法,將x插入到順序表的適當位置上,以保持該表的有序性。 int InsertSort(PDSeqList pl,ELEM_TYPE val) { if(pl == NULL) { ret
資料結構之連結串列操作(c++實現)
1、單向連結串列(頭結點不含資料,不佔長度),C++實現: #include <iostream> #include <stack> using namespace std; /*****定義節點****/ typedef struct node{ int va
資料結構——連結串列(1)如何找出連結串列中的倒數第k個元素
方法一:①遍歷連結串列,得到連結串列的長度n的值;②將倒數的k的序號轉換到順序排號(n-k+1);③遍歷連結串列,直到找到第(n-k+1)個元素。兩次遍歷,時間複雜度為O(n)。 方法二:從第一個元素開始,遍歷k個元素,判斷呢是否為NULL,若為空,則找到第k
javascript資料結構與演算法筆記(六):雙向連結串列
javascript資料結構與演算法筆記(六):雙向連結串列 一:簡介 二:ES6版DoublyLinkedList類 一:簡介 雙向連結串列和普通連結串列的區別在於,在連結串列中,一個節點只有鏈向下一個節點的連結,而
javascript資料結構與演算法筆記(五):連結串列
javascript資料結構與演算法筆記(五):連結串列 一:簡介 二:ES6版LinkedList類 一:簡介 連結串列儲存有序的元素集合,但不同於陣列,連結串列中的元素在記憶體中並不是連續放置的。每個 元素由一個儲
動態資料結構——動態連結串列(malloc函式的使用)
所謂建立動態連結串列,是指在程式執行過程中從無到有地建立一個連結串列。即我們需要一個個地去開闢新節點,並且去輸入節點的資料資訊,然後建立起前後相連的關係。 下面我們開始嘗試建立起一個動態連結串列: 1.結構體部分: struct weapon{ int pric
C 資料結構迴圈連結串列(帶環連結串列)基本操作
經典迴圈連結串列之約瑟夫問題:標號從1到n的n個人圍成一個圈,從1開始計數到m的人退出圈子,然後從退出的下一個人開始接著從1計數,數到m的人後繼續退出,最後只剩下一個人,求剩下人的編號。這便是約瑟夫問題的模型。 經典迴圈連結串列之魔術師發牌問題:魔術師手中有A、2、3……J
1.4 python資料結構之連結串列——移除重複項及帶隨機指標的連結串列複製
這一篇是LeetCode上關於連結串列的兩道題目,難度都是中等,但是我認為難度很大了,尤其是複製連結串列一題,思路清奇。 1)82. Remove Duplicates from Sorted List II (從有序列表中移除重複項) Given a sorted li
資料結構-雙向連結串列(Python實現)
資料結構在程式設計世界中一直是非常重要的一環,不管是開發還是演算法,哪怕是單純為了面試,資料結構都是必修課,今天我們介紹連結串列中的一種——雙向連結串列的程式碼實現。 好了,話不多說直接上程式碼。 雙向連結串列 首先,我們定義一個節點類:Node class Node: def __init__(se
資料結構與演算法入門(1)
一、資料結構 資料之間相互存在的一種或多種特定的關係的元素的集合。 邏輯結構 資料物件中資料元素之間的相互關係 1.集合結構 在資料結構中,如果不考慮資料元素之間的關係,這種結構稱為集合結構。 各個元素是平等的,共同屬性是屬於同一個集合 2.線性結構 線性結構中的資料元素之間
資料結構之連結串列C語言實現以及使用場景分析
連結串列是資料結構中比較基礎也是比較重要的型別之一,那麼有了陣列,為什麼我們還需要連結串列呢!或者說設計連結串列這種資料結構的初衷在哪裡? 這是因為,在我們使用陣列的時候,需要預先設定目標群體的個數,也即陣列容量的大小,然而實時情況下我們目標的個數我們是不確定的,因此我們總是要把陣列的容量設定的
資料結構——排序與查詢(1)——排序與查詢簡介
排序與查詢 排序,是指將一系列無序的記錄,通過某種方式或者演算法,將其變為有序的過程。如果排出來的順序是由小到大排列,我們就稱這種排序叫升序排序。如果是由大到小,我們就稱為降序排序。例如有一組資料 : 開始時為: 2 4 7 1 9 升序排序: 1 2 4 7 9 降序排序: 9 7
Leetcode題解之連結串列(6) 環形連結串列
題目:https://leetcode-cn.com/explore/interview/card/top-interview-questions-easy/6/linked-list/46/ 題目描述: 給定一個連結串列,判斷連結串列中是否有環。 進階: 你能否不使用額外空間解決此
資料結構之堆疊佇列(一)
目錄 資料結構值堆疊佇列 1.堆 2.棧 -- 作業系統在建立某個程序時或者執行緒為這個執行緒建立儲存區域 3.堆、棧區別總結: 4.佇列 5.堆、棧、佇列三者區別