
Flink,Spark Streaming,Storm對比分析
1.Flink架構及特性分析
Flink是個相當早的專案,開始於2008年,但只在最近才得到注意。Flink是原生的流處理系統,提供high level的API。Flink也提供 API來像Spark一樣進行批處理,但兩者處理的基礎是完全不同的。Flink把批處理當作流處理中的一種特殊情況。在Flink中,所有 的資料都看作流,是一種很好的抽象,因為這更接近於現實世界。
1.1 基本架構
下面我們介紹下Flink的基本架構,Flink系統的架構與Spark類似,是一個基於Master-Slave風格的架構。
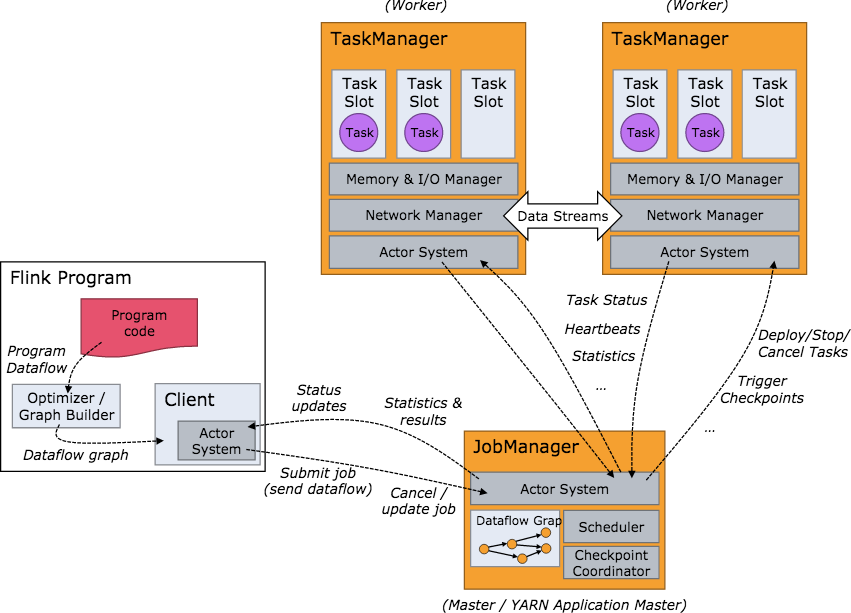
當 Flink 叢集啟動後,首先會啟動一個 JobManger 和一個或多個的 TaskManager。由 Client 提交任務給 JobManager, JobManager 再排程任務到各個 TaskManager 去執行,然後 TaskManager 將心跳和統計資訊彙報給 JobManager。 TaskManager 之間以流的形式進行資料的傳輸。上述三者均為獨立的 JVM 程序。
Client 為提交 Job 的客戶端,可以是執行在任何機器上(與 JobManager 環境連通即可)。提交 Job 後,Client 可以結束程序 (Streaming的任務),也可以不結束並等待結果返回。
JobManager 主要負責排程 Job 並協調 Task 做 checkpoint,職責上很像 Storm 的 Nimbus。從 Client 處接收到 Job 和 JAR 包 等資源後,會生成優化後的執行計劃,並以 Task 的單元排程到各個 TaskManager 去執行。
TaskManager 在啟動的時候就設定好了槽位數(Slot),每個 slot 能啟動一個 Task,Task 為執行緒。從 JobManager 處接收需要 部署的 Task,部署啟動後,與自己的上游建立 Netty 連線,接收資料並處理。
JobManager
JobManager是Flink系統的協調者,它負責接收Flink Job,排程組成Job的多個Task的執行。同時,JobManager還負責收集Job 的狀態資訊,並管理Flink叢集中從節點TaskManager。JobManager所負責的各項管理功能,它接收到並處理的事件主要包括:
RegisterTaskManager
在Flink叢集啟動的時候,TaskManager會向JobManager註冊,如果註冊成功,則JobManager會向TaskManager回覆訊息 AcknowledgeRegistration。
SubmitJob
Flink程式內部通過Client向JobManager提交Flink Job,其中在訊息SubmitJob中以JobGraph形式描述了Job的基本資訊。
CancelJob
請求取消一個Flink Job的執行,CancelJob訊息中包含了Job的ID,如果成功則返回訊息CancellationSuccess,失敗則返回訊息 CancellationFailure。
UpdateTaskExecutionState
TaskManager會向JobManager請求更新ExecutionGraph中的ExecutionVertex的狀態資訊,更新成功則返回true。
RequestNextInputSplit
執行在TaskManager上面的Task,請求獲取下一個要處理的輸入Split,成功則返回NextInputSplit。
JobStatusChanged
ExecutionGraph向JobManager傳送該訊息,用來表示Flink Job的狀態發生的變化,例如:RUNNING、CANCELING、 FINISHED等。
TaskManager
TaskManager也是一個Actor,它是實際負責執行計算的Worker,在其上執行Flink Job的一組Task。每個TaskManager負責管理 其所在節點上的資源資訊,如記憶體、磁碟、網路,在啟動的時候將資源的狀態向JobManager彙報。TaskManager端可以分成兩個 階段:
註冊階段
TaskManager會向JobManager註冊,傳送RegisterTaskManager訊息,等待JobManager返回AcknowledgeRegistration,然 後TaskManager就可以進行初始化過程。
可操作階段
該階段TaskManager可以接收並處理與Task有關的訊息,如SubmitTask、CancelTask、FailTask。如果TaskManager無法連線 到JobManager,這是TaskManager就失去了與JobManager的聯絡,會自動進入“註冊階段”,只有完成註冊才能繼續處理Task 相關的訊息。
Client
當用戶提交一個Flink程式時,會首先建立一個Client,該Client首先會對使用者提交的Flink程式進行預處理,並提交到Flink叢集中處 理,所以Client需要從使用者提交的Flink程式配置中獲取JobManager的地址,並建立到JobManager的連線,將Flink Job提交給 JobManager。Client會將使用者提交的Flink程式組裝一個JobGraph, 並且是以JobGraph的形式提交的。一個JobGraph是一個 Flink Dataflow,它由多個JobVertex組成的DAG。其中,一個JobGraph包含了一個Flink程式的如下資訊:JobID、Job名稱、配 置資訊、一組JobVertex等。
1.2 基於Yarn層面的架構
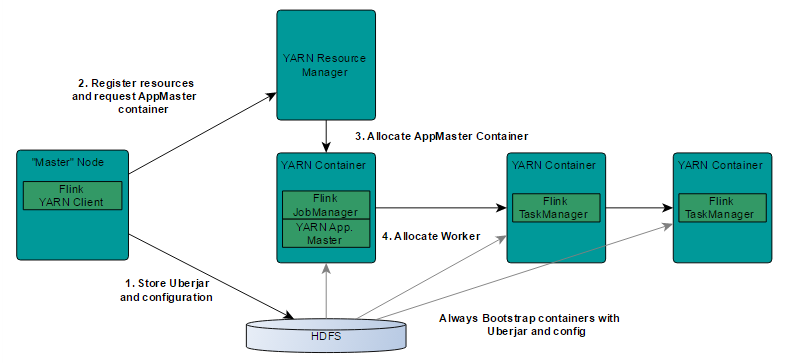
基於yarn層面的架構類似spark on yarn模式,都是由Client提交App到RM上面去執行,然後RM分配第一個container去執行 AM,然後由AM去負責資源的監督和管理。需要說明的是,Flink的yarn模式更加類似spark on yarn的cluster模式,在cluster模式 中,dirver將作為AM中的一個執行緒去執行,在Flink on yarn模式也是會將JobManager啟動在container裡面,去做個driver類似 的task排程和分配,YARN AM與Flink JobManager在同一個Container中,這樣AM可以知道Flink JobManager的地址,從而 AM可以申請Container去啟動Flink TaskManager。待Flink成功執行在YARN叢集上,Flink YARN Client就可以提交Flink Job到 Flink JobManager,並進行後續的對映、排程和計算處理。
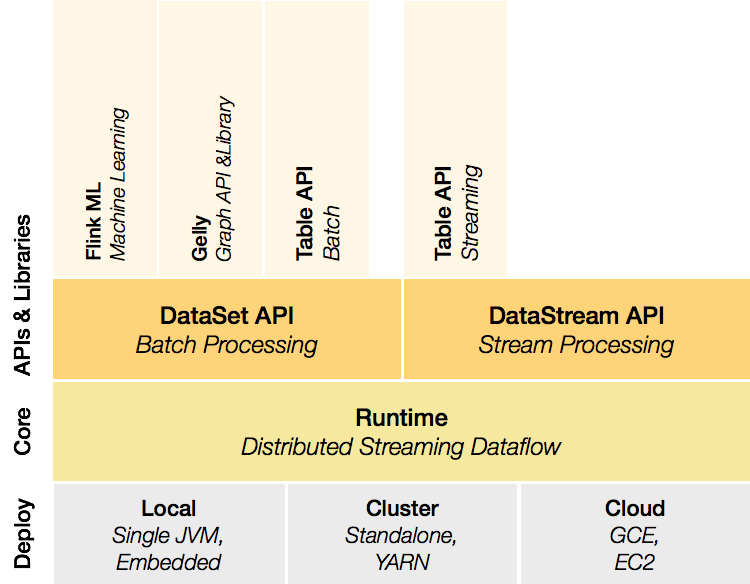
1.3 元件棧
Flink是一個分層架構的系統,每一層所包含的元件都提供了特定的抽象,用來服務於上層元件。
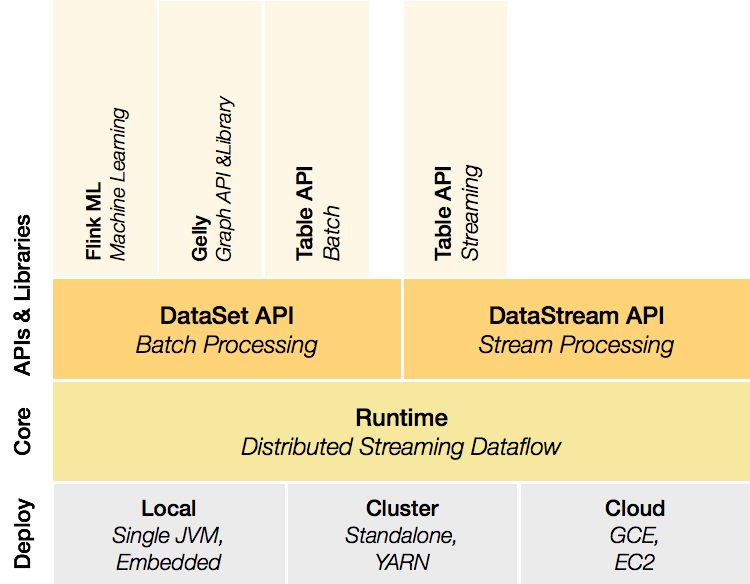
Deployment層
該層主要涉及了Flink的部署模式,Flink支援多種部署模式:本地、叢集(Standalone/YARN)、雲(GCE/EC2)。Standalone 部署模式與Spark類似,這裡,我們看一下Flink on YARN的部署模式
Runtime層
Runtime層提供了支援Flink計算的全部核心實現,比如:支援分散式Stream處理、JobGraph到ExecutionGraph的對映、排程等 等,為上層API層提供基礎服務。
API層
API層主要實現了面向無界Stream的流處理和麵向Batch的批處理API,其中面向流處理對應DataStream API,面向批處理對應DataSet API。
Libraries層
該層也可以稱為Flink應用框架層,根據API層的劃分,在API層之上構建的滿足特定應用的實現計算框架,也分別對應於面向流處理 和麵向批處理兩類。面向流處理支援:CEP(複雜事件處理)、基於SQL-like的操作(基於Table的關係操作);面向批處理支援: FlinkML(機器學習庫)、Gelly(圖處理)。
從官網中我們可以看到,對於Flink一個最重要的設計就是Batch和Streaming共同使用同一個處理引擎,批處理應用可以以一種特 殊的流處理應用高效地執行。
這裡面會有一個問題,就是Batch和Streaming是如何使用同一個處理引擎進行處理的。
1.4 Batch和Streaming是如何使用同一個處理引擎。
下面將從程式碼的角度去解釋Batch和Streaming是如何使用同一處理引擎的。首先從Flink測試用例來區分兩者的區別。
Batch WordCount Examples
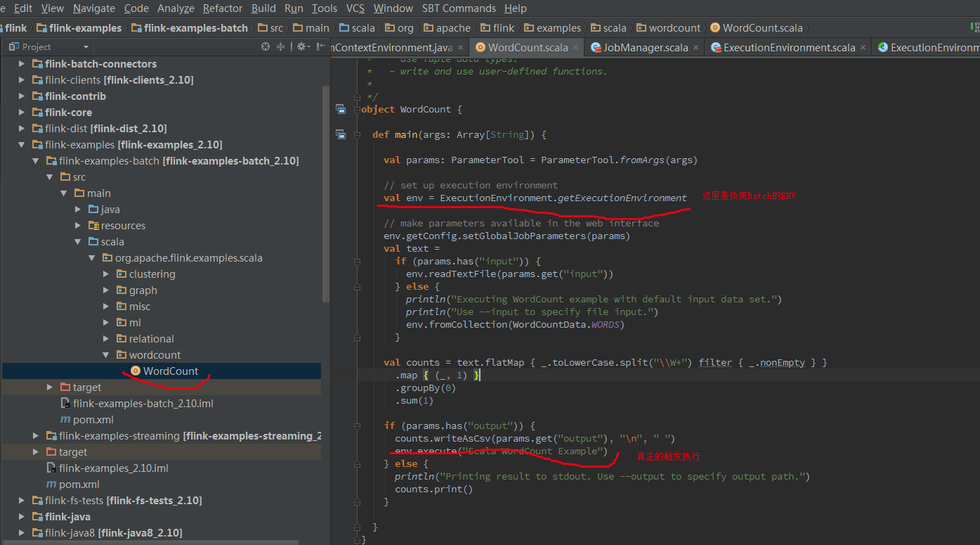
Streaming WordCount Examples
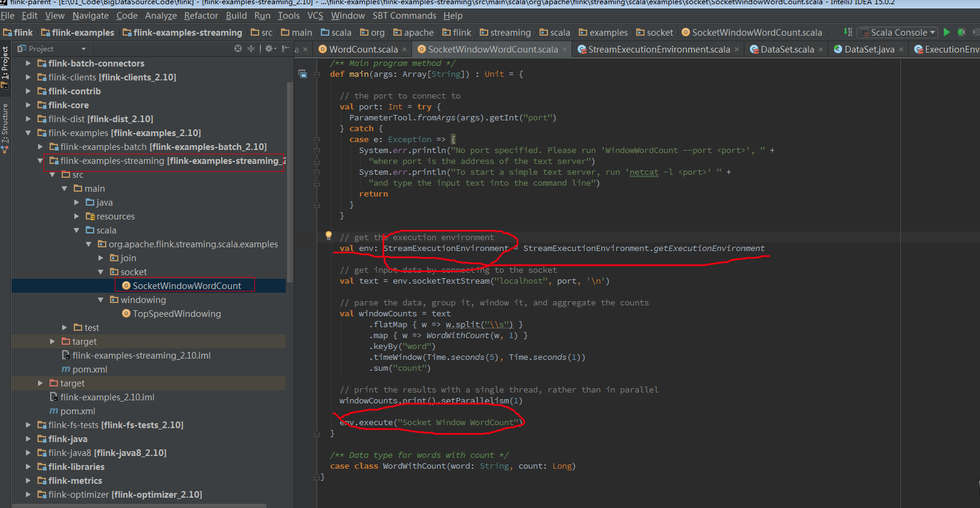
Batch和Streaming採用的不同的ExecutionEnviroment,對於ExecutionEnviroment來說讀到的源資料是一個DataSet,而 StreamExecutionEnviroment的源資料來說則是一個DataStream。
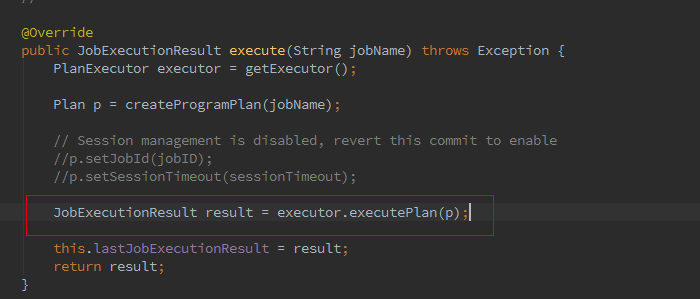
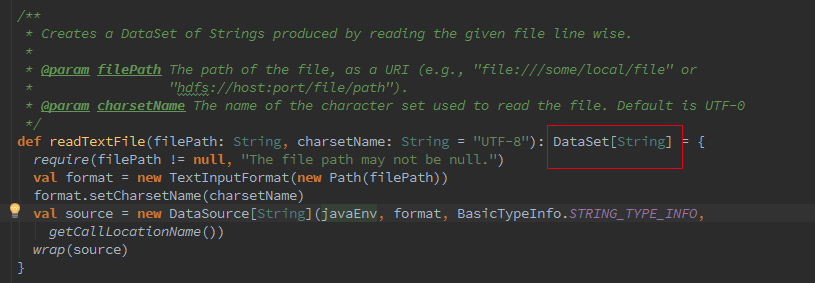
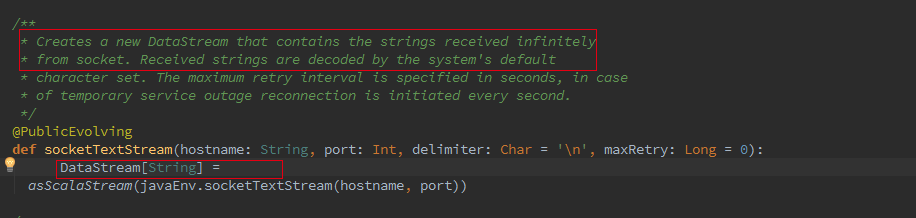
接著我們追蹤下Batch的從Optimzer到JobGgraph的流程,這裡如果是Local模式構造的是LocalPlanExecutor,這裡我們只介紹 Remote模式,此處的executor為RemotePlanExecutor
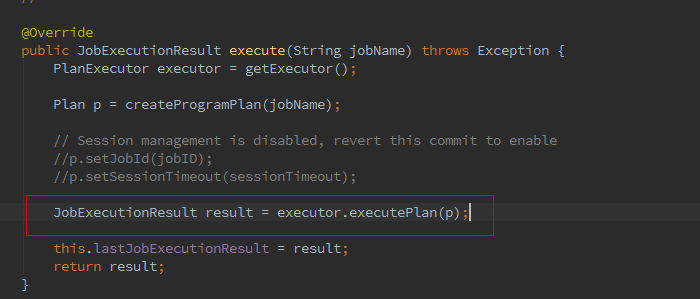
最終會呼叫ClusterClient的run方法將我們的應用提交上去,run方法的第一步就是獲取jobGraph,這個是client端的操作,client 會將jobGraph提交給JobManager轉化為ExecutionGraph。Batch和streaming不同之處就是在獲取JobGraph上面。
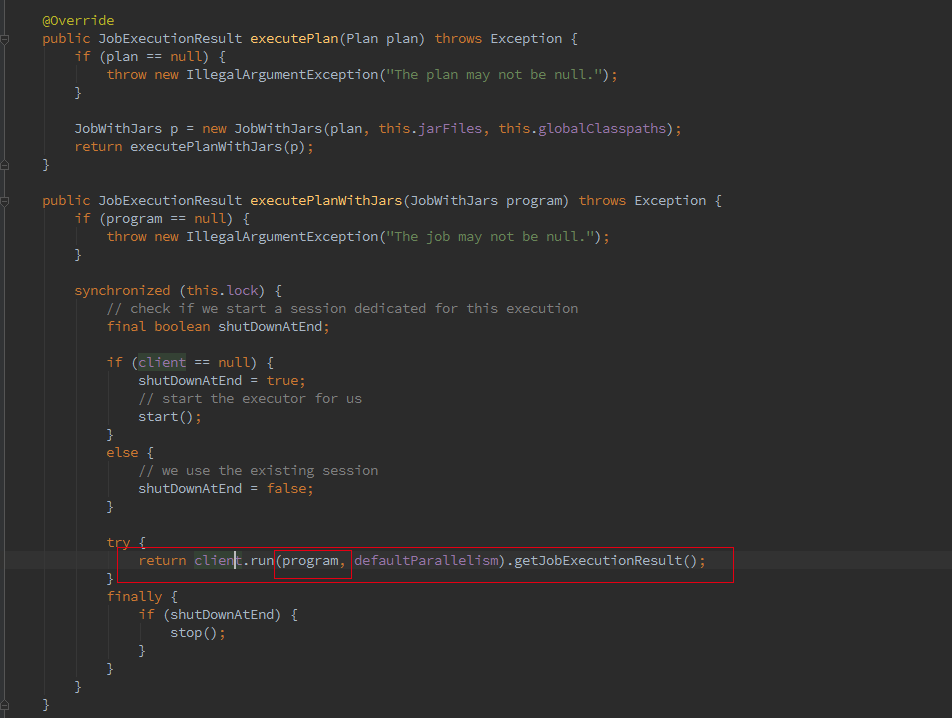
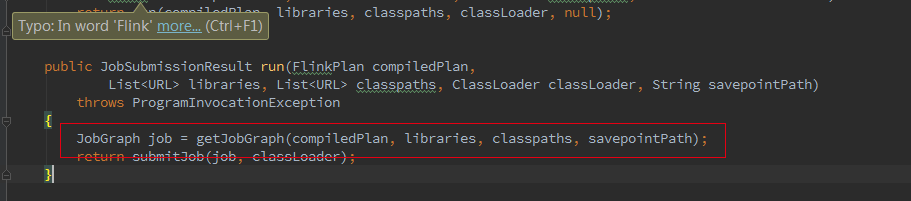
如果我們初始化的FlinkPlan是StreamingPlan,則首先構造Streaming的StreamingJobGraphGenerator去將optPlan轉為 JobGraph,Batch則直接採用另一種的轉化方式。
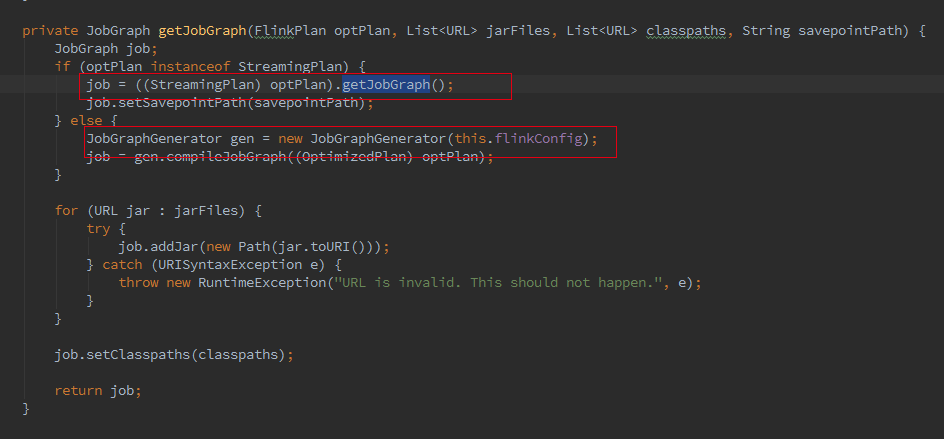
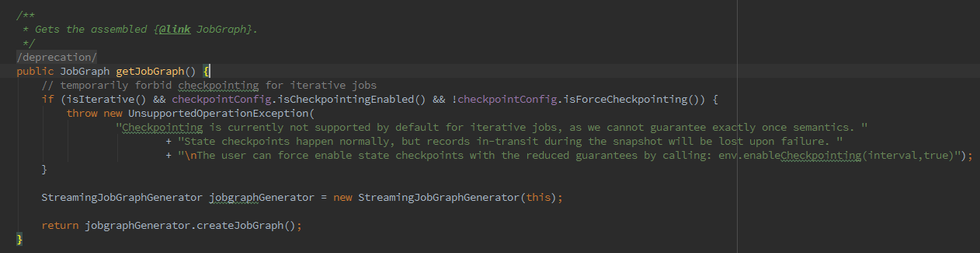
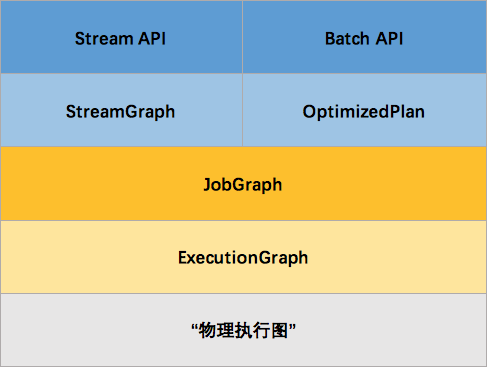
簡而言之,Batch和streaming會有兩個不同的ExecutionEnvironment,不同的ExecutionEnvironment會將不同的API翻譯成不同 的JobGgrah,JobGraph 之上除了 StreamGraph 還有 OptimizedPlan。OptimizedPlan 是由 Batch API 轉換而來的。 StreamGraph 是由 Stream API 轉換而來的,JobGraph 的責任就是統一 Batch 和 Stream 的圖。
1.5 特性分析
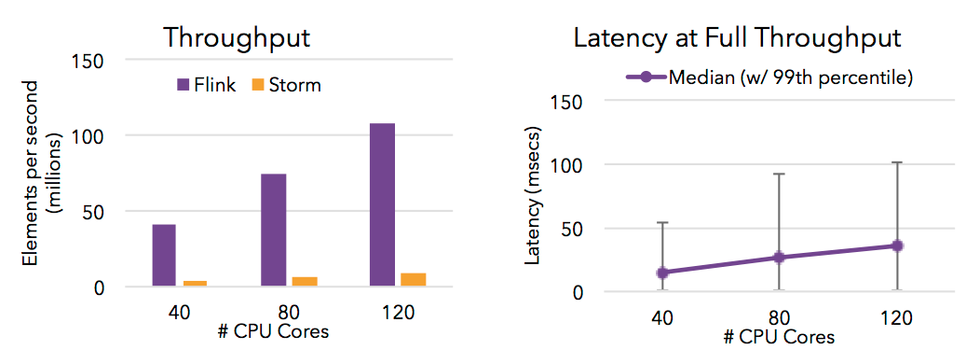
高吞吐 & 低延遲
Flink 的流處理引擎只需要很少配置就能實現高吞吐率和低延遲。下圖展示了一個分散式計數的任務的效能,包括了流資料 shuffle 過程。
支援 Event Time 和亂序事件
Flink 支援了流處理和 Event Time 語義的視窗機制。
Event time 使得計算亂序到達的事件或可能延遲到達的事件更加簡單。
狀態計算的 exactly-once 語義
流程式可以在計算過程中維護自定義狀態。
Flink 的 checkpointing 機制保證了即時在故障發生下也能保障狀態的 exactly once 語義。
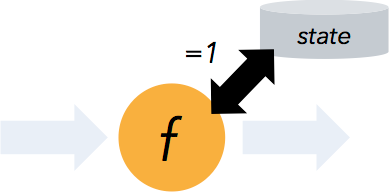
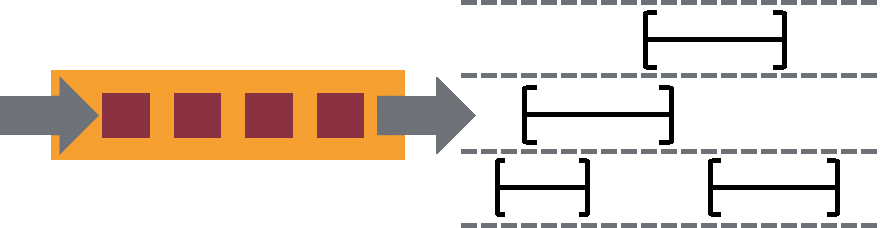
高度靈活的流式視窗
Flink 支援在時間視窗,統計視窗,session 視窗,以及資料驅動的視窗
視窗可以通過靈活的觸發條件來定製,以支援複雜的流計算模式。
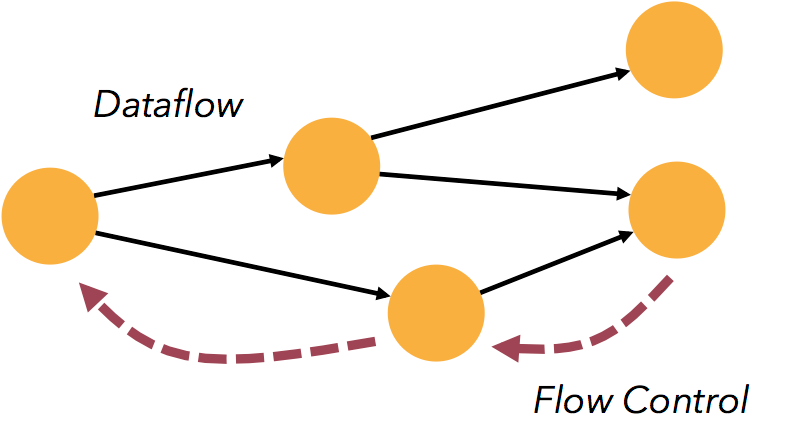
帶反壓的連續流模型
資料流應用執行的是不間斷的(常駐)operators。
Flink streaming 在執行時有著天然的流控:慢的資料 sink 節點會反壓(backpressure)快的資料來源(sources)。
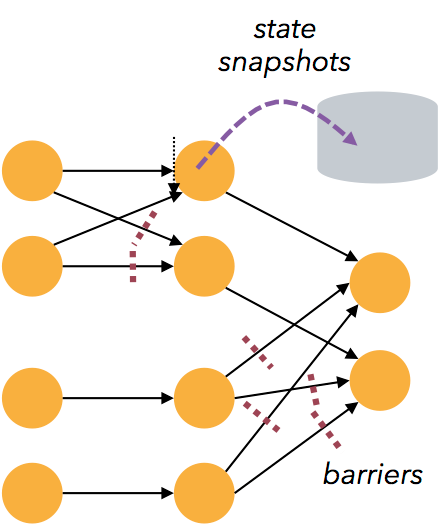
容錯性
Flink 的容錯機制是基於 Chandy-Lamport distributed snapshots 來實現的。
這種機制是非常輕量級的,允許系統擁有高吞吐率的同時還能提供強一致性的保障。
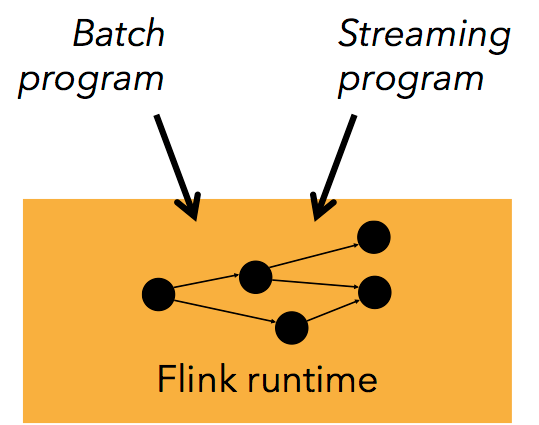
Batch 和 Streaming 一個系統流處理和批處理共用一個引擎
Flink 為流處理和批處理應用公用一個通用的引擎。批處理應用可以以一種特殊的流處理應用高效地執行。
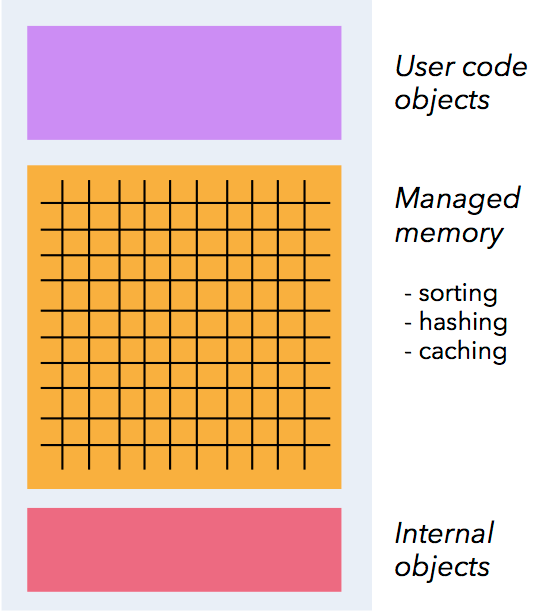
記憶體管理
Flink 在 JVM 中實現了自己的記憶體管理。
應用可以超出主記憶體的大小限制,並且承受更少的垃圾收集的開銷。
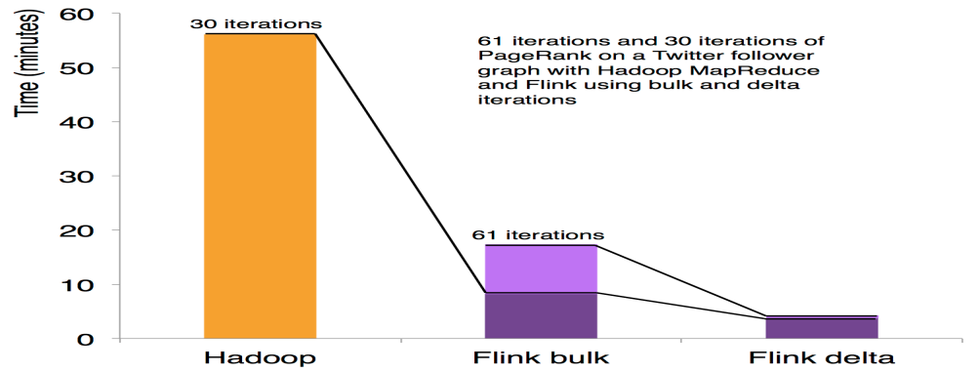
迭代和增量迭代
Flink 具有迭代計算的專門支援(比如在機器學習和圖計算中)。
增量迭代可以利用依賴計算來更快地收斂。
程式調優
批處理程式會自動地優化一些場景,比如避免一些昂貴的操作(如 shuffles 和 sorts),還有快取一些中間資料。

API 和 類庫
流處理應用
DataStream API 支援了資料流上的函式式轉換,可以使用自定義的狀態和靈活的視窗。
右側的示例展示瞭如何以滑動視窗的方式統計文字資料流中單詞出現的次數。
val texts:DataStream[String] = ...
val counts = text .flatMap { line => line.split("\\W+") } .map { token => Word(token, 1) } .keyBy("word") .timeWindow(Time.seconds(5), Time.seconds(1)) .sum("freq")
批處理應用
Flink 的 DataSet API 可以使你用 Java 或 Scala 寫出漂亮的、型別安全的、可維護的程式碼。它支援廣泛的資料型別,不僅僅是 key/value 對,以及豐富的 operators。
右側的示例展示了圖計算中 PageRank 演算法的一個核心迴圈。
case class Page( pageId: Long, rank:Double) case class Adjacency( id: Long, neighbors:Array[Long])
val result = initialRanks.iterate(30) { pages => pages.join(adjacency).where("pageId").equalTo("pageId") { (page, adj, out : Collector[Page]) => { out.collect(Page(page.id, 0.15 / numPages)) for (n <- adj.neighbors) { out.collect(Page(n, 0.85*page.rank/adj.neighbors.length)) } } } .groupBy("pageId").sum("rank") }
類庫生態
Flink 棧中提供了提供了很多具有高階 API 和滿足不同場景的類庫:機器學習、圖分析、關係式資料處理。當前類庫還在 beta 狀 態,並且在大力發展。
廣泛整合
Flink 與開源大資料處理生態系統中的許多專案都有整合。
Flink 可以執行在 YARN 上,與 HDFS 協同工作,從 Kafka 中讀取流資料,可以執行 Hadoop 程式程式碼,可以連線多種資料儲存 系統。

部署
Flink可以單獨脫離Hadoop進行部署,部署只依賴Java環境,相對簡單
網易有數
企業級大資料視覺化分析平臺。面向業務人員的自助式敏捷分析平臺,採用PPT模式的報告製作,更加易學易用,具備強大的探索分析功能,真正幫助使用者洞察資料發現價值。
Flink 叢集啟動後架構圖。

當 Flink 叢集啟動後,首先會啟動一個 JobManger 和一個或多個的 TaskManager。由 Client 提交任務給 JobManager,JobManager 再排程任務到各個 TaskManager 去執行,然後 TaskManager 將心跳和統計資訊彙報給 JobManager。TaskManager 之間以流的形式進行資料的傳輸。上述三者均為獨立的 JVM 程序。
- Client 為提交 Job 的客戶端,可以是執行在任何機器上(與 JobManager 環境連通即可)。提交 Job 後,Client 可以結束程序(Streaming的任務),也可以不結束並等待結果返回。
- JobManager 主要負責排程 Job 並協調 Task 做 checkpoint,職責上很像 Storm 的 Nimbus。從 Client 處接收到 Job 和 JAR 包等資源後,會生成優化後的執行計劃,並以 Task 的單元排程到各個 TaskManager 去執行。
- TaskManager 在啟動的時候就設定好了槽位數(Slot),每個 slot 能啟動一個 Task,Task 為執行緒。從 JobManager 處接收需要部署的 Task,部署啟動後,與自己的上游建立 Netty 連線,接收資料並處理。
可以看到 Flink 的任務排程是多執行緒模型,並且不同Job/Task混合在一個 TaskManager 程序中。雖然這種方式可以有效提高 CPU 利用率,但是個人不太喜歡這種設計,因為不僅缺乏資源隔離機制,同時也不方便除錯。類似 Storm 的程序模型,一個JVM 中只跑該 Job 的 Tasks 實際應用中更為合理。
Job 例子
本文所示例子為 flink-1.0.x 版本
我們使用 Flink 自帶的 examples 包中的 SocketTextStreamWordCount ,這是一個從 socket 流中統計單詞出現次數的例子。
首先,使用 netcat 啟動本地伺服器:
$ nc -l 9000
然後提交 Flink 程式
- $ bin/flink run examples/streaming/SocketTextStreamWordCount.jar \
- --hostname 10.218.130.9 \
- --port 9000
在netcat端輸入單詞並監控 taskmanager 的輸出可以看到單詞統計的結果。
SocketTextStreamWordCount 的具體程式碼如下:
- publicstaticvoidmain(String[] args)throws Exception {
- // 檢查輸入
- final ParameterTool params = ParameterTool.fromArgs(args);
- ...
- // set up the execution environment
- final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- // get input data
- DataStream<String> text =
- env.socketTextStream(params.get("hostname"), params.getInt("port"), '\n', 0);
- DataStream<Tuple2<String, Integer>> counts =
- // split up the lines in pairs (2-tuples) containing: (word,1)
- text.flatMap(new Tokenizer())
- // group by the tuple field "0" and sum up tuple field "1"
- .keyBy(0)
- .sum(1);
- counts.print();
- // execute program
- env.execute("WordCount from SocketTextStream Example");
- }
我們將最後一行程式碼 env.execute 替換成 System.out.println(env.getExecutionPlan()); 並在本地執行該程式碼(併發度設為2),可以得到該拓撲的邏輯執行計劃圖的 JSON 串,將該 JSON 串貼上到 http://flink.apache.org/visualizer/ 中,能視覺化該執行圖。

但這並不是最終在 Flink 中執行的執行圖,只是一個表示拓撲節點關係的計劃圖,在 Flink 中對應了 SteramGraph。另外,提交拓撲後(併發度設為2)還能在 UI 中看到另一張執行計劃圖,如下所示,該圖對應了 Flink 中的 JobGraph。

Graph
看起來有點亂,怎麼有這麼多不一樣的圖。實際上,還有更多的圖。Flink 中的執行圖可以分成四層:StreamGraph -> JobGraph -> ExecutionGraph -> 物理執行圖。
- StreamGraph: 是根據使用者通過 Stream API 編寫的程式碼生成的最初的圖。用來表示程式的拓撲結構。
- JobGraph: StreamGraph經過優化後生成了 JobGraph,提交給 JobManager 的資料結構。主要的優化為,將多個符合條件的節點 chain 在一起作為一個節點,這樣可以減少資料在節點之間流動所需要的序列化/反序列化/傳輸消耗。
- ExecutionGraph: JobManager 根據 JobGraph 生成的分散式執行圖,是排程層最核心的資料結構。
- 物理執行圖: JobManager 根據 ExecutionGraph 對 Job 進行排程後,在各個TaskManager 上部署 Task 後形成的“圖”,並不是一個具體的資料結構。
例如上文中的 2個併發度的 SocketTextStreamWordCount 四層執行圖的演變過程如下圖所示(點選檢視大圖):

這裡對一些名詞進行簡單的解釋。
- StreamGraph: 根據使用者通過 Stream API 編寫的程式碼生成的最初的圖。
- StreamNode:用來代表 operator 的類,並具有所有相關的屬性,如併發度、入邊和出邊等。
- StreamEdge:表示連線兩個StreamNode的邊。
- JobGraph: StreamGraph經過優化後生成了 JobGraph,提交給 JobManager 的資料結構。
- JobVertex:經過優化後符合條件的多個StreamNode可能會chain在一起生成一個JobVertex,即一個JobVertex包含一個或多個operator,JobVertex的輸入是JobEdge,輸出是IntermediateDataSet。
- IntermediateDataSet:表