
MySQL多資料來源筆記皇冠體育足球競猜網站開發分庫分表理論和各種中介軟體
一.使用中介軟體的好處皇冠體育足球競猜網站開發dsluntan.com 企娥3393756370皇冠體育足球競猜網站開發
使用中介軟體對於主讀寫分離新增一個從資料庫節點來說,可以不用修改程式碼,達到新增節點資料庫而不影響到程式碼的修改。因為如果不用中介軟體,那麼在程式碼中自己是先讀寫分離,如果新增節點,
你進行寫操作時,你的輪詢求模的資料量就要修改。但是中介軟體的維護也很麻煩的。
二.各種中介軟體
1.MYSQL官方的mysqlProxy,它可以實現讀寫分離,但是它使用率很低,搞笑的是MySQL官方都不推薦使用。
2.Amoeba:這是阿里巴巴工程司寫的,是開源的。使用也很少。
3.阿里開源的cobar,缺點查詢回來的資料沒有排序,和分頁,這些都要自己處理,用的少。
5.mycat:是根據cobar改造的。用的還算比較多
6.ShardingJDBC:這是噹噹網的。這近幾年比較流行,比較牛逼。
注意:如果我們單純的做讀寫分離,一般都會選擇用SpringAOP去做。並不是一定使用中介軟體就一定好。
讀寫分離做完,我們資料庫的壓力就解決了嗎?
並沒有,做完讀寫分離,我們都知道知識一個或幾個主庫,多個從庫,每個資料庫裡面的資料都是一樣的。只是一份複製。
這樣做的好處就是:
1。資料庫可以備份。
2.減輕資料庫的壓力。
資料庫的壓力問題就緩解了嗎?並沒有緩解的特別厲害,當你這真正的高併發,大資料量來的時候,你做讀寫分離也不夠用的。MySQL單表能承受多少資料量呢?
實踐來看的話,大概也就7000W-1億,這根據欄位量,和欄位裡面存的東西,這資料是根據業務走的,不一定那麼精確。
當達到這個數量級的時候你的多表關聯查詢什麼的,即便優化到位,我說的優化,第一是索引一定要設定合理,第二SQL優化,但是SQL優化做的很有限。
到這個資料量你去關聯那麼兩三個表,基本都是在5S,10S甚至更長的時間。
這時候就要考慮別的辦法了。走到這一步,那該怎麼辦呢?
那麼就要進行分庫分表:
1.垂直拆分:
基於領域模型做資料的垂直切分是一種最佳實踐。如將訂單、使用者、支付等領域模型劃分到不同的DB庫裡面。前提必須各領域資料之間join展示場景較少,在這種情況下分庫能獲得很高的價值,同時各個系統之間的擴充套件性得到很大程度的提高。
缺點:如果在拆分之前,系統中很多列表和詳情頁所需的資料是可以通過sql join來完成的。而拆分後,資料庫可能是分散式在不同例項和不同的主機上,join將變得非常麻煩。而且基於架構規範,效能,安全性等方面考慮,一般是禁止跨庫join的。
那該怎麼辦呢?首先要考慮下垂直分庫的設計問題,如果可以調整,那就優先調整。
解決辦法:
1.建立全域性表:系統中可能出現所有模組都可能會依賴到的一些表。比較類似我們理解的“資料字典”。為了避免跨庫join查詢,我們可以將這類表在其他每個資料庫中均儲存一份。這種做法叫做建立全域性表
同時,這類資料通常也很少發生修改(幾乎不會),一般不用太擔心“一致性”問題。
2.進行資料同步:比如,使用者庫中的tab_a表和訂單庫中tbl_b有關聯,可以定時將指定的表做同步。當然,同步本來會對資料庫帶來一定的影響,需要效能影響和資料時效性中取得一個平衡。這樣來避免複雜的跨庫查詢。
3.系統層面組裝:呼叫不同模組的元件或者服務,獲取到資料並進行欄位拼裝。不要想著這很容易,實踐起來可真沒有那麼容易,尤其是資料庫設計上存在問題但又無法輕易調整的時候。具體情況通常會比較複雜。
組裝的時候要避免迴圈呼叫服務,迴圈RPC,迴圈查詢資料庫,最好一次性返回所有資訊,在程式碼裡做組裝。
4.適當的進行欄位冗餘:比如“訂單表”中儲存“賣家Id”的同時,將賣家的“Name”欄位也冗餘,這樣查詢訂單詳情的時候就不需要再去查詢“賣家使用者表”。
如下圖:
拆分前:
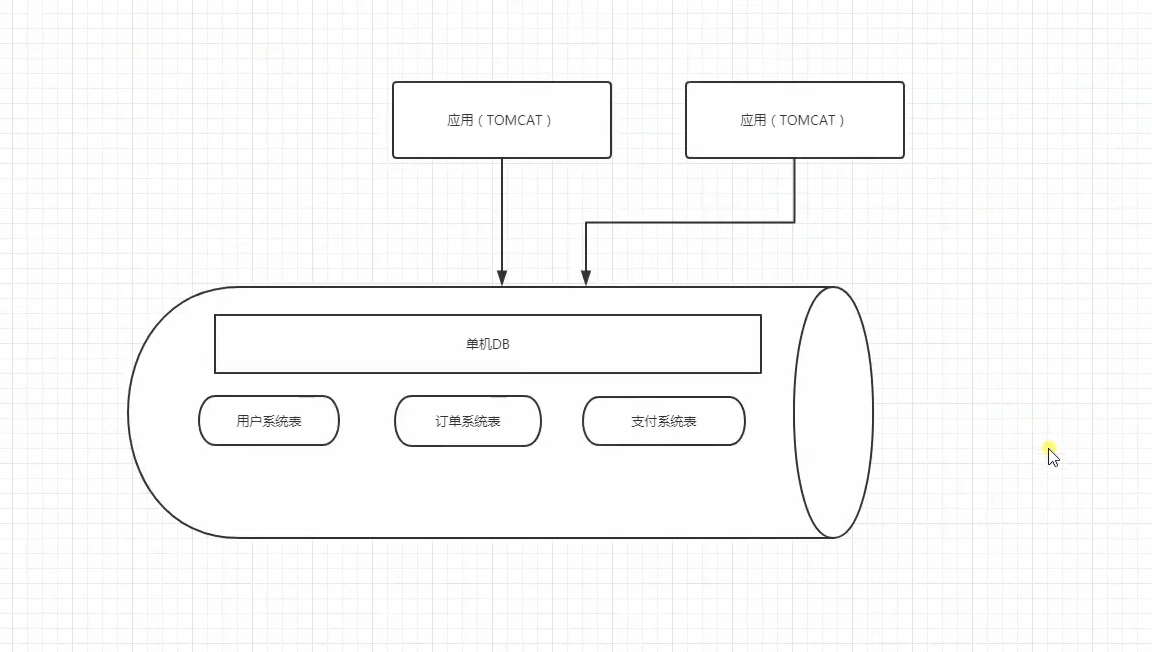
拆分後:

這樣的話能夠緩解一下壓力,我們還可以對每一個獨立的DB在進行讀寫分離。
當然拆分也會出現問題的。比如說分散式事務。比如支付系統支付失敗了回滾,那麼你訂單系統也要回滾的。但是你們都不在同一個庫裡面,這是就需要分散式事務了。
如果走到這一步,你的系統還是緩解不了壓力,那麼說明你這系統比較厲害了。說明你公司在你的行業裡面能叫的上名字的了。
那麼我們就要進行水平拆分了。
2.水平拆分:垂直切分緩解了原來單叢集(所有的資料庫都存在一張表裡,)的壓力,但是在搶購時依然捉襟見肘。原有的訂單模型已經無法滿足業務需求,於是就要進行水平分表也稱為橫向分表,
比較容易理解,就是將表中不同的資料行按照一定規律分佈到不同的資料庫表中(這些表儲存在同一個資料庫中),這樣來降低單表資料量,優化查詢效能。
最常見的方式就是通過主鍵或者時間等欄位進行Hash和取模後拆分。
如下圖:
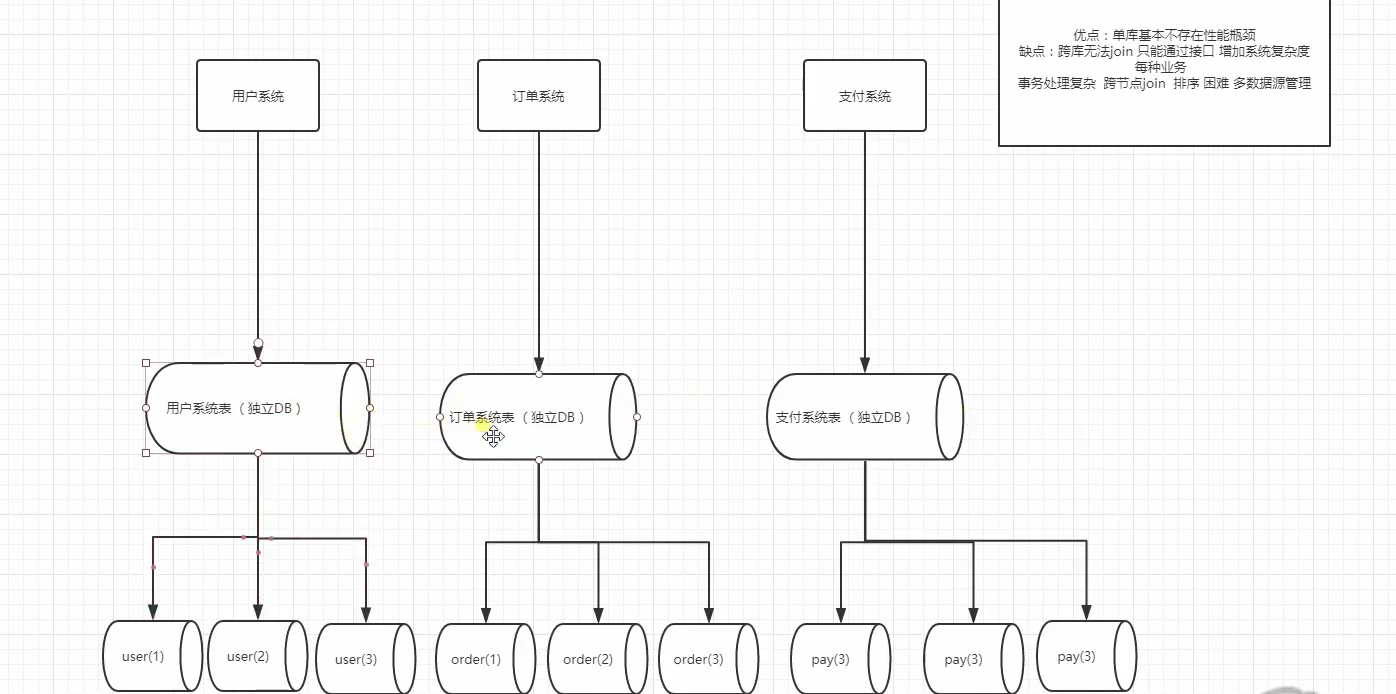
如果資料壓力還是比較大怎麼呢?,還能怎麼辦,繼續進行水平拆分咯,比如,user(1)user(2)user(3)繼續驚醒水平拆分。
水平拆分所帶來的問題:
1.常見分片規則問題
1。一致性hash:依據Sharding Key對5取模,根據餘數將資料散落到目標表中。比如將資料均勻的分佈在5張user表中,如下圖:

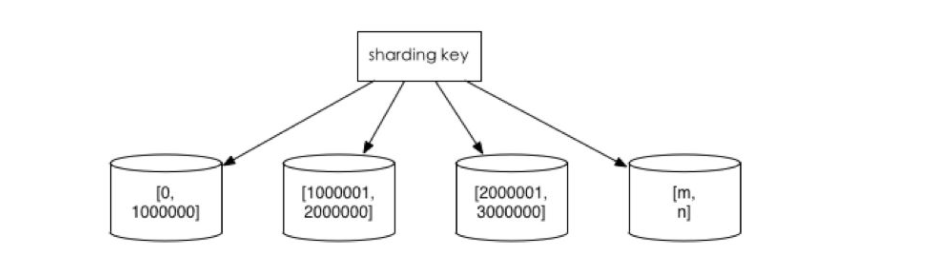
2.範圍切分:比如按照時間區間或ID區間來切分。
優點:單表大小可控,天然水平擴充套件。
缺點:無法解決集中寫入瓶頸的問題
如下圖:
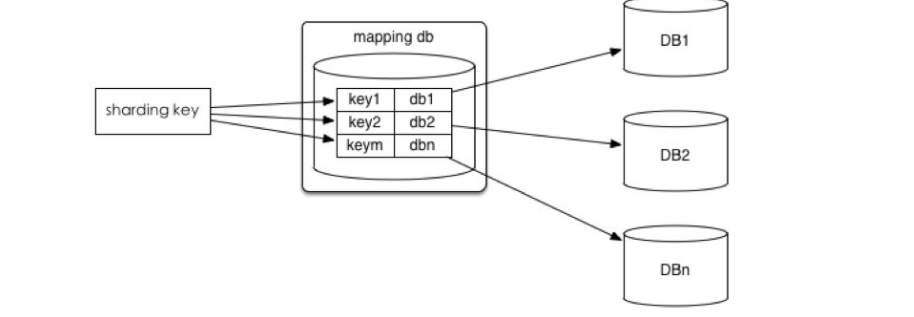
3.將ID和庫的Mapping關係記錄在一個單獨的庫中。
優點:ID和庫的Mapping演算法可以隨意更改。
缺點:引入額外的單點。
如下圖:
資料遷移問題
很少有專案會在初期就開始考慮分片設計的,一般都是在業務高速發展面臨效能和儲存的瓶頸時才會提前準備。因此,不可避免的就需要考慮歷史資料遷移的問題。
一般做法就是通過程式先讀出歷史資料,這些資料量非常大,不涉及事務,實時性要求低,這是你就要考慮一下非關係資料庫了,比如MongoDB,Hbase,這些資料庫
擴充套件性非常好,這些NoSQL天然就是分片的。彈性非常好。然後按照指定的分片規則再將資料寫入到各個分片節點中。
這裡還要知道一下什麼是OLTP,OLAP:
OLTP(on-line transaction processing) 主要是執行基本日常的事務處理,比如資料庫記錄的增刪查改。比如在銀行的一筆交易記錄,就是一個典型的事務。
OLTP的特點一般有:
1.實時性要求高。我記得之前上大學的時候,銀行異地匯款,要隔天才能到賬,而現在是分分鐘到賬的節奏,說明現在銀行的實時處理能力大大增強。
2.資料量不是很大,生產庫上的資料量一般不會太大,而且會及時做相應的資料處理與轉移。
3.交易一般是確定的,比如銀行存取款的金額肯定是確定的,所以OLTP是對確定性的資料進行存取
4.高併發,並且要求滿足ACID原則。比如兩人同時操作一個銀行卡賬戶,比如大型的購物網站秒殺活動時上萬的QPS請求。
聯機分析處理OLAP(On-Line Analytical Processing) 是資料倉庫系統的主要應用,支援複雜的分析操作,側重決策支援,並且提供直觀易懂的查詢結果。典型的應用就是複雜的動態的報表系統。
OLAP的特點一般有:
1.實時性要求不是很高,比如最常見的應用就是天級更新資料,然後出對應的資料報表。
2.資料量大,因為OLAP支援的是動態查詢,所以使用者也許要通過將很多資料的統計後才能得到想要知道的資訊,例如時間序列分析等等,所以處理的資料量很大;
3.OLAP系統的重點是通過資料提供決策支援,所以查詢一般都是動態,自定義的。所以在OLAP中,維度的概念特別重要。一般會將使用者所有關心的維度資料,存入對應資料平臺
跨分片的排序分頁
在分庫分表的情況下,為了快速(分頁)查詢資料,分表策略的選擇就顯得非常重要了,需要盡最大限度將需要跨範圍查詢的資料儘量集中,多數情況下在我們做了最大限度的努力之後,資料仍然可能是分散式的。
為了進一步提高查詢的效能,維持查詢的中間變數資訊是我們在分庫分表模式下提高分頁查詢速度的另一個手段:我們每次翻頁查詢時,通過中間資訊的分析,就可以直接定位到目標表的目標位置,通過這種方式提供了近似於在單表模式下的分頁查詢能力。
但另一方面也需要在業務上做出一定的犧牲:限制查詢區段,提高檢索速度。
如下圖:
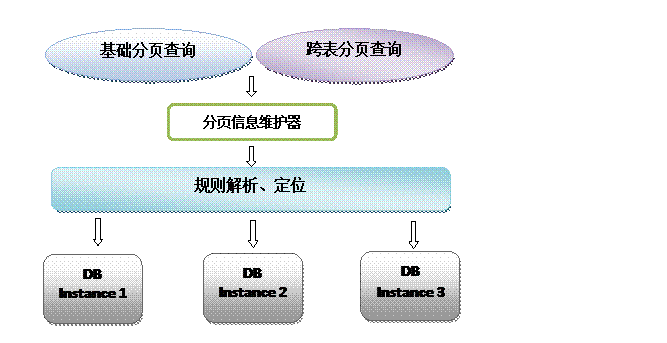
跨分片的函式處理
在使用Max、Min、Sum、Count之類的函式進行統計和計算的時候,需要先在每個分片資料來源上執行相應的函式處理,然後再將各個結果集進行二次處理,最終再將處理結果返回。
跨分片join
Join是關係型資料庫中最常用的特性,但是在分片叢集中,join也變得非常複雜。應該儘量避免跨分片的join查詢(這種場景,比上面的跨分片分頁更加複雜,而且對效能的影響很大)。
通常有以下幾種方式來避免:
1.全域性表
全域性表的概念之前在“垂直分庫”時提過。基本思想一致,就是把一些類似資料字典又可能會產生join查詢的表資訊放到各分片中,從而避免跨分片的join。
2.ER分片
在關係型資料庫中,表之間往往存在一些關聯的關係。如果我們可以先確定好關聯關係,並將那些存在關聯關係的表記錄存放在同一個分片上,那麼就能很好的避免跨分片join問題。在一對多關係的情況下,我們通常會選擇按照資料較多的那一方進行拆分。
3.記憶體計算
隨著spark記憶體計算的興起,理論上來講,很多跨資料來源的操作問題看起來似乎都能夠得到解決。可以將資料丟給spark叢集進行記憶體計算,最後將計算結果返回。
總結
並非所有表都需要水平拆分,要看增長的型別和速度,水平拆分是大招,拆分後會增加開發的複雜度,不到萬不得已不使用。
在大規模併發的業務上,儘量做到線上查詢和離線查詢隔離,交易查詢和運營/客服查詢隔離。
拆分維度的選擇很重要,要儘可能在解決拆分前問題的基礎上,便於開發。
資料庫沒你想象的那麼堅強,需要保護,儘量使用簡單的、良好索引的查詢,這樣資料庫整體可控,也易於長期容量規劃以及水平擴充套件。
相關推薦
MySQL多資料來源筆記皇冠體育足球競猜網站開發分庫分表理論和各種中介軟體
一.使用中介軟體的好處皇冠體育足球競猜網站開發dsluntan.com 企娥3393756370皇冠體育足球競猜網站開發使用中介軟體對於主讀寫分離新增一個從資料庫節點來說,可以不用修改程式碼,達到新增節點資料庫而不影響到程式碼的修改。因為如果不用中介軟體,那麼在程式碼中自己是
世界杯皇冠體育足球競猜系統整體架構設計
ref 缺少 默認 == targe 架構設計 body left 結果 競猜業務邏輯很簡單世界杯皇冠體育足球源碼下載dsluntan.com 企娥3393756370世界杯皇冠體育足球源碼下載、普遍用於各種賽事中、籃球賽、足球賽、包括最近興起的遊戲電競賽事,對於社區產品來
systemd皇冠體育足球競猜原始碼下載的作用
早上群上討論了一下systemd的作用,還導致了一個人的直接退群,出於求知心理,搜尋了一些systemd,對此也作出了一些相應的整理;一、systemd的誕生:學習嵌入式bootloader與kernel銜接的時候,就入門了init程序;init程序也就是系統的第一個程序,P
MyBatis實現Mysql數據庫分庫分表操作和總結
用戶表 設計 行數 百萬 出現問題 網絡 自增 .html tro 閱讀目錄 前言 MyBatis實現分表最簡單步驟 分離的方式 分離的策略 分離的問題 分離的原則 實現分離的方式 總結 前言 作為一個數據庫,作為數據庫中的一張表,隨著用戶的增多隨著時間的推移,總有一
MyBatis實現Mysql資料庫分庫分表操作和總結
前言 作為一個數據庫,作為資料庫中的一張表,隨著使用者的增多隨著時間的推移,總有一天,資料量會大到一個難以處理的地步。這時僅僅一張表的資料就已經超過了千萬,無論是查詢還是修改,對於它的操作都會很耗時,這時就需要進行資料庫切分的操作了。 MyBatis實現分表最簡單步驟 既
MySQL多資料來源 二(基於spring+aop實現讀寫分離)
一,為什麼要進行讀寫分離呢? 因為資料庫的“寫操作”操作是比較耗時的(寫上萬條條資料到Mysql的可能要1分鐘分鐘)。但是資料庫的“讀操作”卻比“寫操作”耗時要少的多(從Mysql的讀幾萬條資料條資料可能只要十秒鐘),而我們在開發過程中大多數也是查詢操作比較多。所以讀寫分離解決的是,資料庫的
Mysql多資料來源 一(主從同步)
mysql版本:Mysql 5.7配置 1:複製mysql檔案到別的位置 由於下載的mysql預設情況下沒有my-default.ini配置檔案所以我從網上覆制了一份 如下: # For advice
Spring-Boot+Mybaits+MySql多資料來源+通用分頁外掛PageHelper的使用
一、專案目錄結構圖二、pom依賴<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLoc
Spring Boot使用spring-data-jpa配置Mysql多資料來源
轉載請註明出處 :Spring Boot使用spring-data-jpa配置Mysql多資料來源 我們在之前的文章中已經學習了Spring Boot中使用mysql資料庫 在單資料來源的情況下,Spring Boot的配置非常簡單,只需要在application.propert
MySQL多資料來源 二(基於spring+aop實現讀寫分離)
一、為什麼要進行讀寫分離呢? 因為資料庫的“寫操作”操作是比較耗時的(寫上萬條條資料到Mysql可能要1分鐘分鐘)。但是資料庫的“讀操作”卻比“寫操作”耗時要少的多(從Mysql讀幾萬條資料條資料可能只要十秒鐘),而我們在開發過程中大多數也是查詢操作比較多。所以讀寫分離解決
springboot mysql 多資料來源配置,可實現讀寫分離
1、程式碼實現 import com.zaxxer.hikari.HikariDataSource; import javas
MySQL主從(MySQL proxy Lua讀寫分離設置,一主多從同步配置,分庫分表方案)
否則 count user username 2個 ons 基礎 zxvf 路徑 Mysql Proxy Lua讀寫分離設置一.讀寫分離說明讀寫分離(Read/Write Splitting),基本的原理是讓主數據庫處理事務性增、改、刪操作(INSERT、UPDATE、DE
資料庫分庫分表 sharding 系列 四 多資料來源的事務處理
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
day81_淘淘商城專案_14_專案釋出 + Linux下安裝mysql + tomcat熱部署 + 資料庫分庫分表 + Mycat學習_匠心筆記
第十四天: 1、Linux上mysql的安裝 2、系統的部署 3、mycat的介紹 4、專案總結 5、面試中的問題 1、開發流程淺解 2、專案釋出前的準備 1、測試 a) 本地單元測試 b) 測試環境測試(1,2,3,4,5) c) 使用
Mysql叢集和一主多從之後如何分庫分表的方案實現(三)
4-3、使用MyCat配置橫向拆分 之前文章中我們介紹瞭如何使用MyCat進行讀寫分離,類似的關係型資料庫的讀寫分離儲存方案可以在保持上層業務系統透明度的基礎上滿足70%業務系統的資料承載規模要求和效能要求。比起單純使用LVS + Replicaion的讀寫分離方案而言最大的優勢在於更能增加對上層業務系
MySQL訂單分庫分表多維度查詢
以訂單表為例, 按照使用者ID mod 64 分成 64個數據庫. 按照使用者的維度查詢很快,因為最終的查詢落在一臺伺服器上. 但是如果按照商戶的維度查詢,則代價非常高. 需要查詢全部64臺伺服器. 在分頁的情況下,更加惡化. 比如某個商戶查詢第10頁的資料(按照訂單的建立時間).需要在每臺數據庫伺服器上查詢
MySQL分庫分表多維度查詢——比較好的方法
MySQL分庫分表,一般只能按照一個維度進行查詢.以訂單表為例, 按照使用者ID mod 64 分成 64個數據庫.按照使用者的維度查詢很快,因為最終的查詢落在一臺伺服器上.但是如果按照商戶的維度查詢,則代價非常高.需要查詢全部64臺伺服器.在分頁的情況下,更加惡化.比如某個商戶查詢第10頁的資料(按照訂單的
day81_淘淘商城專案_14_專案釋出 + Linux下安裝mysql + tomcat熱部署 + 反向代理的配置 + 資料庫分庫分表 + Mycat學習_匠心筆記
淘淘商城專案_14 1、開發流程淺解 2、專案釋出前的準備 3、專案部署 3.1、Linux下安裝mysql 3.2、專案架構講解 3.3、系統功能介紹 3.4、網路拓撲圖 3.5
MySQL分庫分表備份腳本
數據庫備份數據庫腳本[[email protected]/* */ script]# cat store_backup.sh #!/bin/shMYUSER=rootMYPASS=qwe123SOCKET=/data/3306/mysql.sockMYLOGIN="mysql -u$MYUSER
16、MySQL數據庫分庫分表備份腳本
mysql數據庫分庫分表備份腳本MySQL數據庫分庫分表備份腳本===================學員分享分庫分表==========================腳本單雙引號的區別:單引號是強引用,強制輸出是所見即所得。雙引號是解析變量 和 多個字符串、數字等連接一個字符串條件1 || 條件2