
SparkStreaming之視窗函式
WindowOperations(視窗操作)
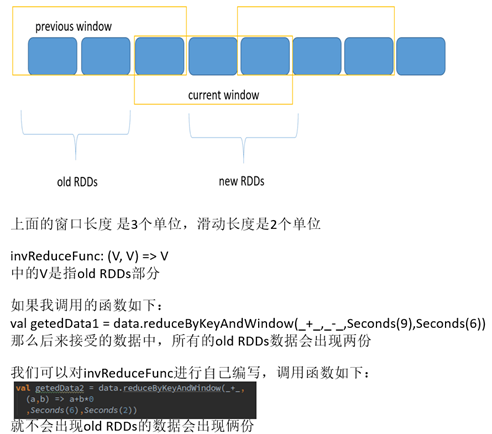
Spark還提供了視窗的計算,它允許你使用一個滑動視窗應用在資料變換中。下圖說明了該滑動視窗。
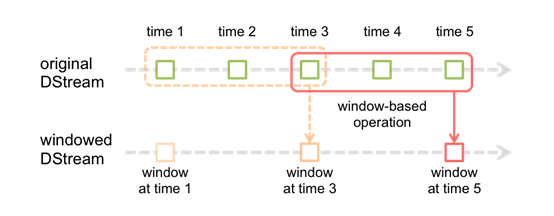
如圖所示,每個時間視窗在一個個DStream中劃過,每個DSteam中的RDD進入Window中進行合併,操作時生成為
視窗化DSteam的RDD。在上圖中,該操作被應用在過去的3個時間單位的資料,和劃過了2個時間單位。這說明任
何視窗操作都需要指定2個引數。
- window length(視窗長度):視窗的持續時間(上圖為3個時間單位)
- sliding interval (滑動間隔)- 視窗操作的時間間隔(上圖為2個時間單位)。
上面的2個引數的大小,必須是接受產生一個DStream時間的倍數
讓我們用一個例子來說明視窗操作。比如說,你想用以前的WordCount的例子,來計算最近30s的資料的中的單詞
數,10S接受為一個DStream。為此,我們要用reduceByKey操作來計算最近30s資料中每一個DSteam中關於
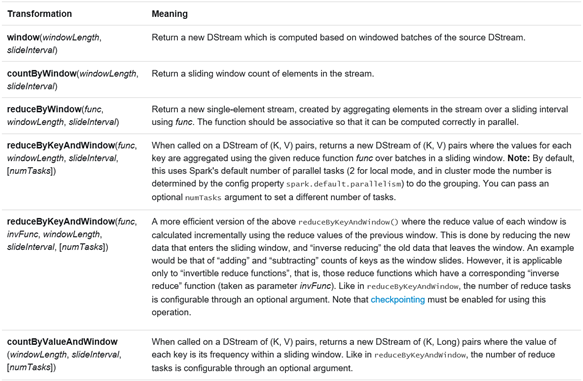
(word,1)的pair操作。它可以用reduceByKeyAndWindow操作來實現。一些常見的視窗操作如下。所有這些操作
都需要兩個引數--- window length(視窗長度)和sliding interval(滑動間隔)。
-------------------------實驗資料----------------------------------------------------------------------
spark
Streaming
better
than
storm
you
need
it
yes
do
it
(每秒在其中隨機抽取一個,作為Socket端的輸入),socket端的資料模擬和實驗函式等程式見附錄百度雲連結
-----------------------------------------------window操作-------------------------------------------------------------------------//輸入:視窗長度(隱:輸入的滑動視窗長度為形成Dstream的時間) //輸出:返回一個DStream,這個DStream包含這個滑動視窗下的全部元素 def window(windowDuration: Duration): DStream[T] = window(windowDuration, this.slideDuration) //輸入:視窗長度和滑動視窗長度 //輸出:返回一個DStream,這個DStream包含這個滑動視窗下的全部元素 def window(windowDuration: Duration, slideDuration: Duration): DStream[T] = ssc.withScope { new WindowedDStream(this, windowDuration, slideDuration) }
import org.apache.log4j.{Level, Logger}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object windowOnStreaming {
def main(args: Array[String]) {
/**
* this is test of Streaming operations-----window
*/
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.Server").setLevel(Level.OFF)
val conf = new SparkConf().setAppName("the Window operation of SparK Streaming").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc,Seconds(2))
//set the Checkpoint directory
ssc.checkpoint("/Res")
//get the socket Streaming data
val socketStreaming = ssc.socketTextStream("master",9999)
val data = socketStreaming.map(x =>(x,1))
//def window(windowDuration: Duration): DStream[T]
val getedData1 = data.window(Seconds(6))
println("windowDuration only : ")
getedData1.print()
//same as
// def window(windowDuration: Duration, slideDuration: Duration): DStream[T]
//val getedData2 = data.window(Seconds(9),Seconds(3))
//println("Duration and SlideDuration : ")
//getedData2.print()
ssc.start()
ssc.awaitTermination()
}
}
--------------------reduceByKeyAndWindow操作--------------------------------
/**通過對每個滑動過來的視窗應用一個reduceByKey的操作,返回一個DSream,有點像
* `DStream.reduceByKey(),但是隻是這個函式只是應用在滑動過來的視窗,hash分割槽是採用spark叢集
* 預設的分割槽樹
* @param reduceFunc 從左到右的reduce 函式
* @param windowDuration 視窗時間
* 滑動視窗預設是1個batch interval
* 分割槽數是是RDD預設(depend on spark叢集core)
*/
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
windowDuration: Duration
): DStream[(K, V)] = ssc.withScope {
reduceByKeyAndWindow(reduceFunc, windowDuration, self.slideDuration, defaultPartitioner())
}
/**通過對每個滑動過來的視窗應用一個reduceByKey的操作,返回一個DSream,有點像
* `DStream.reduceByKey(),但是隻是這個函式只是應用在滑動過來的視窗,hash分割槽是採用spark叢集
* 預設的分割槽樹
* @param reduceFunc 從左到右的reduce 函式
* @param windowDuration 視窗時間
* @param slideDuration 滑動時間
*/
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration
): DStream[(K, V)] = ssc.withScope {
reduceByKeyAndWindow(reduceFunc, windowDuration, slideDuration, defaultPartitioner())
}
/**通過對每個滑動過來的視窗應用一個reduceByKey的操作,返回一個DSream,有點像
* `DStream.reduceByKey(),但是隻是這個函式只是應用在滑動過來的視窗,hash分割槽是採用spark叢集
* 預設的分割槽樹
* @param reduceFunc 從左到右的reduce 函式
* @param windowDuration 視窗時間
* @param slideDuration 滑動時間
* @param numPartitions 每個RDD的分割槽數.
*/
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration,
numPartitions: Int
): DStream[(K, V)] = ssc.withScope {
reduceByKeyAndWindow(reduceFunc, windowDuration, slideDuration,
defaultPartitioner(numPartitions))
}
/**
/**通過對每個滑動過來的視窗應用一個reduceByKey的操作,返回一個DSream,有點像
* `DStream.reduceByKey(),但是隻是這個函式只是應用在滑動過來的視窗,hash分割槽是採用spark叢集
* 預設的分割槽樹
* @param reduceFunc 從左到右的reduce 函式
* @param windowDuration 視窗時間
* @param slideDuration 滑動時間
* @param numPartitions 每個RDD的分割槽數.
* @param partitioner 設定每個partition的分割槽數
*/
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration,
partitioner: Partitioner
): DStream[(K, V)] = ssc.withScope {
self.reduceByKey(reduceFunc, partitioner)
.window(windowDuration, slideDuration)
.reduceByKey(reduceFunc, partitioner)
}
/**
*通過對每個滑動過來的視窗應用一個reduceByKey的操作.同時對old RDDs進行了invReduceFunc操作
* hash分割槽是採用spark叢集,預設的分割槽樹
* @param reduceFunc從左到右的reduce 函式
* @param invReduceFunc inverse reduce function; such that for all y, invertible x:
* `invReduceFunc(reduceFunc(x, y), x) = y`
* @param windowDuration視窗時間
* @param slideDuration 滑動時間
* @param filterFunc 來賽選一定條件的 key-value 對的
*/
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
invReduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration = self.slideDuration,
numPartitions: Int = ssc.sc.defaultParallelism,
filterFunc: ((K, V)) => Boolean = null
): DStream[(K, V)] = ssc.withScope {
reduceByKeyAndWindow(
reduceFunc, invReduceFunc, windowDuration,
slideDuration, defaultPartitioner(numPartitions), filterFunc
)
}
/**
*通過對每個滑動過來的視窗應用一個reduceByKey的操作.同時對old RDDs進行了invReduceFunc操作
* hash分割槽是採用spark叢集,預設的分割槽樹
* @param reduceFunc從左到右的reduce 函式
* @param invReduceFunc inverse reduce function; such that for all y, invertible x:
* `invReduceFunc(reduceFunc(x, y), x) = y`
* @param windowDuration視窗時間
* @param slideDuration 滑動時間
* @param partitioner 每個RDD的分割槽數.
* @param filterFunc 來賽選一定條件的 key-value 對的
*/
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
invReduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration,
partitioner: Partitioner,
filterFunc: ((K, V)) => Boolean
): DStream[(K, V)] = ssc.withScope {
val cleanedReduceFunc = ssc.sc.clean(reduceFunc)
val cleanedInvReduceFunc = ssc.sc.clean(invReduceFunc)
val cleanedFilterFunc = if (filterFunc != null) Some(ssc.sc.clean(filterFunc)) else None
new ReducedWindowedDStream[K, V](
self, cleanedReduceFunc, cleanedInvReduceFunc, cleanedFilterFunc,
windowDuration, slideDuration, partitioner
)
}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object reduceByWindowOnStreaming {
def main(args: Array[String]) {
/**
* this is test of Streaming operations-----reduceByKeyAndWindow
*/
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.Server").setLevel(Level.OFF)
val conf = new SparkConf().setAppName("the reduceByWindow operation of SparK Streaming").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc,Seconds(2))
//set the Checkpoint directory
ssc.checkpoint("/Res")
//get the socket Streaming data
val socketStreaming = ssc.socketTextStream("master",9999)
val data = socketStreaming.map(x =>(x,1))
//def reduceByKeyAndWindow(reduceFunc: (V, V) => V, windowDuration: Duration ): DStream[(K, V)]
//val getedData1 = data.reduceByKeyAndWindow(_+_,Seconds(6))
val getedData2 = data.reduceByKeyAndWindow(_+_,
(a,b) => a+b*0
,Seconds(6),Seconds(2))
val getedData1 = data.reduceByKeyAndWindow(_+_,_-_,Seconds(9),Seconds(6))
println("reduceByKeyAndWindow : ")
getedData1.print()
ssc.start()
ssc.awaitTermination()
}
}
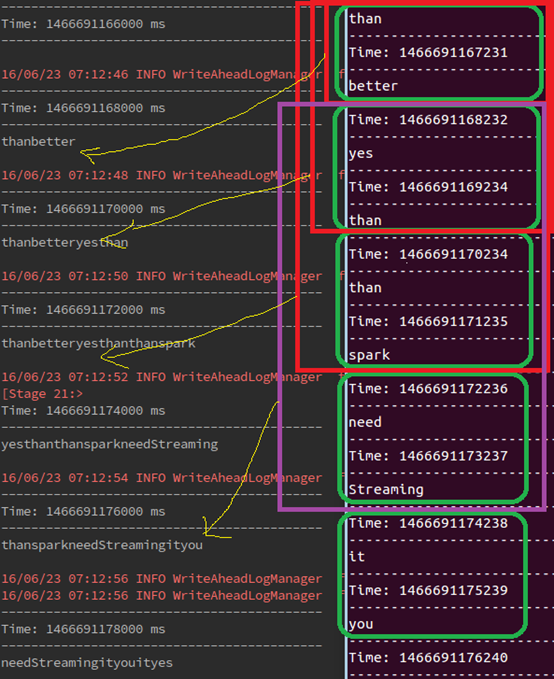
這裡出現了invReduceFunc函式這個函式有點特別,一不注意就會出錯,現在通過分析原始碼中的
ReducedWindowedDStream這個類內部來進行說明:
------------------reduceByWindow操作---------------------------
/輸入:reduceFunc、視窗長度、滑動長度
//輸出:(a,b)為從幾個從左到右一次取得兩個元素
//(,a,b)進入reduceFunc,
def reduceByWindow(
reduceFunc: (T, T) => T,
windowDuration: Duration,
slideDuration: Duration
): DStream[T] = ssc.withScope {
this.reduce(reduceFunc).window(windowDuration, slideDuration).reduce(reduceFunc)
}
/**
*輸入reduceFunc,invReduceFunc,視窗長度、滑動長度
*/
def reduceByWindow(
reduceFunc: (T, T) => T,
invReduceFunc: (T, T) => T,
windowDuration: Duration,
slideDuration: Duration
): DStream[T] = ssc.withScope {
this.map((1, _))
.reduceByKeyAndWindow(reduceFunc, invReduceFunc, windowDuration, slideDuration, 1)
.map(_._2)
}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by root on 6/23/16.
*/
object reduceByWindow {
def main(args: Array[String]) {
/**
* this is test of Streaming operations-----reduceByWindow
*/
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.Server").setLevel(Level.OFF)
val conf = new SparkConf().setAppName("the reduceByWindow operation of SparK Streaming").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc,Seconds(2))
//set the Checkpoint directory
ssc.checkpoint("/Res")
//get the socket Streaming data
val socketStreaming = ssc.socketTextStream("master",9999)
//val data = socketStreaming.reduceByWindow(_+_,Seconds(6),Seconds(2))
val data = socketStreaming.reduceByWindow(_+_,_+_,Seconds(6),Seconds(2))
println("reduceByWindow: count the number of elements")
data.print()
ssc.start()
ssc.awaitTermination()
}
}
-----------------------------------------------countByWindow操作---------------------------------
/**
* 輸入 視窗長度和滑動長度,返回視窗內的元素數量
* @param windowDuration 視窗長度
* @param slideDuration 滑動長度
*/
def countByWindow(
windowDuration: Duration,
slideDuration: Duration): DStream[Long] = ssc.withScope {
this.map(_ => 1L).reduceByWindow(_ + _, _ - _, windowDuration, slideDuration)
//視窗下的DStream進行map操作,把每個元素變為1之後進行reduceByWindow操作
}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by root on 6/23/16.
*/
object countByWindow {
def main(args: Array[String]) {
/**
* this is test of Streaming operations-----countByWindow
*/
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.Server").setLevel(Level.OFF)
val conf = new SparkConf().setAppName("the reduceByWindow operation of SparK Streaming").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc,Seconds(2))
//set the Checkpoint directory
ssc.checkpoint("/Res")
//get the socket Streaming data
val socketStreaming = ssc.socketTextStream("master",9999)
val data = socketStreaming.countByWindow(Seconds(6),Seconds(2))
println("countByWindow: count the number of elements")
data.print()
ssc.start()
ssc.awaitTermination()
}
}
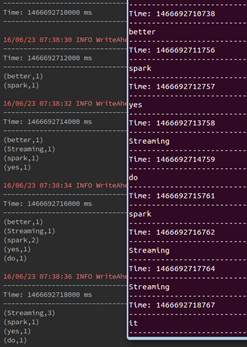
-------------------------------- countByValueAndWindow-------------
/**
*輸入 視窗長度、滑動時間、RDD分割槽數(預設分割槽是等於並行度)
* @param windowDuration width of the window; must be a multiple of this DStream's
* batching interval
* @param slideDuration sliding interval of the window (i.e., the interval after which
* the new DStream will generate RDDs); must be a multiple of this
* DStream's batching interval
* @param numPartitions number of partitions of each RDD in the new DStream.
*/
def countByValueAndWindow(
windowDuration: Duration,
slideDuration: Duration,
numPartitions: Int = ssc.sc.defaultParallelism)
(implicit ord: Ordering[T] = null)
: DStream[(T, Long)] = ssc.withScope {
this.map((_, 1L)).reduceByKeyAndWindow(
(x: Long, y: Long) => x + y,
(x: Long, y: Long) => x - y,
windowDuration,
slideDuration,
numPartitions,
(x: (T, Long)) => x._2 != 0L
)
}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by root on 6/23/16.
*/
object countByValueAndWindow {
def main(args: Array[String]) {
/**
* this is test of Streaming operations-----countByValueAndWindow
*/
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.Server").setLevel(Level.OFF)
val conf = new SparkConf().setAppName("the reduceByWindow operation of SparK Streaming").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc,Seconds(2))
//set the Checkpoint directory
ssc.checkpoint("/Res")
//get the socket Streaming data
val socketStreaming = ssc.socketTextStream("master",9999)
val data = socketStreaming.countByValueAndWindow(Seconds(6),Seconds(2))
println("countByWindow: count the number of elements")
data.print()
ssc.start()
ssc.awaitTermination()
}
}
附錄
連結:http://pan.baidu.com/s/1slkqwBb 密碼:d92r
相關推薦
SparkStreaming之視窗函式
WindowOperations(視窗操作) Spark還提供了視窗的計算,它允許你使用一個滑動視窗應用在資料變換中。下圖說明了該滑動視窗。 如圖所示,每個時間視窗在一個個DStream中劃過,每個DSteam中的RDD進入Window中進行合併,操作時生成為 視窗化DS
postgresql系列之視窗函式
本文是《sql基礎教程》《postgresql實戰》的讀書筆記;具體可以參考這兩本書相關章節。 一、 視窗函式 1.1 基本概念 視窗函式可以進行排序、生成序列號等一般的聚合函式無法實現的高階操作;聚合函式將結果集進行計算並且通常返回一行。視窗函式也是基於結果集
大資料學習之路105-視窗函式及foreachRDD,foreachPartition,foreach對比
sparkstreaming的視窗函式: 視窗函式的作用主要是計算一段時間之內的資料的變化,那麼就會有人產生疑問,為什麼視窗與視窗之間需要重疊呢? 其實不重疊也是可以的,但是如果不重疊的話,將來做出來的報表一個時間段與另一個時間段的資料就會產生劇烈的變化。 視窗函式可以讓我們一下子操
使用pandas時間視窗函式rolling完成量化交易之移動平均線
要想理解移動平均線,先來理解移動平均的概念。移動平均線、乖離率、相對強弱指數、均量線等技術指標都是在移動平均基礎上建立起來的。 移動平均線<–移動平均數<–移動平均<–算術平均。 1、2、3、4、5、6、7、8、9、10、11、12、13 前十個數的平均值是5.
hive視窗函式之sum,avg,min,max
在hive的統計分析中,其實視窗函式還是比較常用也重要的。 今天整理下hive中視窗函式的sum,avg,min,max,後續再整理其他常用的。 首先模擬建立一張通話記錄表:欄位有主叫號碼,主叫時間,通話時長 > create table `call_test` ( `
SparkStreaming視窗函式的應用
package windon import org.apache.log4j.{Level, Logger} import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext
[大資料]連載No16之 SparkSql函式+SparkStreaming運算元
本次總結圖如下SparkSql可以自定義函式、聚合函式、開窗函式作用說明:自定義一個函式,並且註冊本身,這樣就能在SQL語句中使用 使用方式sqlContext.udf().register(函式名,函式(輸入,輸出),返回型別))程式碼public static void
Hive視窗函式之累積值、平均值、首尾值的計算學習
Hive視窗函式可以計算一定範圍內、一定值域內、或者一段時間內的累積和以及移動平均值等;可以結合聚集函式SUM() 、AVG()等使用;可以結合FIRST_VALUE() 和LAST_VALUE(),返回視窗的第一個和最後一個值。- 如果只使用partition by子句,
Postgres中視窗函式lag以lead
sql中我們經常會用到聚合函式,聚合之後它會減少資料量,但是如果我們想把聚合之後的資料和原始資料同時展示出來,那麼我們需要用到視窗函式。 lag視窗函式通過條件把資料劃分成子類,在子類中進行排序 視窗函式的通用寫法 select name ,orderdate, cost, su
c++筆記之CArray函式
謹以此文獻給因為我菜雞同時裝了VS2013和2017導致vs各種衝突,以至於只能重灌系統的新電腦!哭泣.... CArray屬於MFC,是一個數組模板類。MFC的陣列類支援的陣列類似於常規陣列,可以存放任何資料型別。常規陣列在使用前必須將其定義成能夠容納所有可能需要的元素,即先確定大小,而M
Shell之function函式的定義及呼叫
文章目錄 `function`函式的定義及呼叫 `function`函式的定義 `function`函式的呼叫【位置傳參】 函式使用return返回值【位置傳參】 函式的呼叫【陣列傳參】
Excel操作之VLOOKUP函式
1、作用 VLOOKUP函式是Excel中的一個縱向查詢函式,它與LOOKUP函式和HLOOKUP函式屬於一類函式,在工作中都有廣泛應用,例如可以用來核對資料,多個表格之間快速匯入資料等函式功能。功能是按列查詢,最終返回該列所需查詢列序所對應的值;與之對應的HLOOKUP是按行查詢的。 2、語法規則
golang教程之一類函式
文章目錄 一類函式 什麼是一類函式? 匿名函式 使用者定義的函式型別 高階函式 從其他函式返回函式 閉包 一類函式的使用 一類函式 原文:https://golan
Function 之 Read_Text 函式的使用方法
在SAP系統中,有時候會有大段文字內容需要儲存.例如:銷售發貨(VL03N),在單據的概覽中 ,有一個[文字]項,在此處可以填寫單據的大段文字描述,那麼該內容儲存在哪裡呢?第一反應是找對應表的欄位,那麼你可能要失望了。在SAP系統中,可以供我們使用的資料庫欄位最大長度是255個文字字元(注:此處可能
地理位置geo處理之mysql函式
目前越來越多的業務都會基於LBS,附近的人,外賣位置,附近商家等等,現就討論離我最近這一業務場景的解決方案。 原文:https://www.jianshu.com/p/455d0468f6d4 目前已知解決方案有: mysql 自定義函式計算
MahApps.Metro之視窗標題工具欄
<Controls:MetroWindow.LeftWindowCommands> //視窗工具欄左邊部分 <Controls:WindowCommands> //窗口布局 &nbs
Python函式之系統函式的呼叫
全部測試程式碼 #!/usr/bin/evn python3 #_*_conding:utf-8 _*_ #系統內建函式 #1.abs():檢視絕對值,如果傳入的引數不對,會報TypeError print('-100的絕對值--',abs(-100)) #2.max():檢
學渣學python之map函式
map()函式是Python內建的高階函式,它接收一個函式f和一個list,並把函式f作用在list的每個元素上。從而得到一個f處理過的新的list返回。下面舉個栗子: 1. 例1 list [1, 2, 3, 4, 5, 6, 7] 我們要得到list的每個元素都平方後的,新的li
pytho系統學習:第二週之字串函式練習
# Author : Sunny# 雙下劃線的函式基本沒用# 定義字串name = 'i am sunny!'# 首字母大寫函式:capitalizeprint('-->capitalize:', name.capitalize())# 判斷結尾函式:endswithprint('-->endsw
matlab之sortrows()函式
sortrows()函式的格式: sortrows(A,column) A是一個矩陣,如果沒有第二個引數column,則預設按照第一列升序排列,如果遇到重複數字,則按照第二列升序排列,依次類推。。。 如果存在第二個引數column,則按照指定的列排序,當指定的列有重複元素的時候,則重複元素所在的行保持原