
一點一點重學統計學(二)——二項、泊松和正態分佈
貝努裡大數定律:當試驗在不變的條件下,重複次數無限大,抽樣群體某一個概率與理論概率的差值,必定小於一個任意小的正數,所以這兩者可以基本相等,也可以用線性模型來解釋,隨著抽樣的總數增加誤差的平均會越來越小。
如果群體只有兩種型別,則使用二項分佈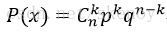
如果某事件概率很小,而群體很大,即有很小的p值和很大的n值,則使用泊松分佈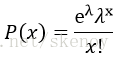
實驗誤差的分佈一般服從正態分佈;u為平均數,o為總體標準差;x=u+

相關推薦
一點一點重學統計學(二)——二項、泊松和正態分佈
貝努裡大數定律:當試驗在不變的條件下,重複次數無限大,抽樣群體某一個概率與理論概率的差值,必定小於一個任意小的正數,所以這兩者可以基本相等,也可以用線性模型來解釋,隨著抽樣的總數增加誤差的平均會越來越
一點一點重學統計學(六.完)——抽樣方法
抽樣的容量必須估計出我們能夠接受的誤差大小,通常以樣本平均數的95%置信區間內允許的誤差,實際上自己根據經驗或者需求來設定比較好: 所需樣本容量估計:n=4s*s/(L*L) s為標準差 L為允許誤差 所需樣本百分比容量估計:n=4pq/(L*L) 抽樣方法: 簡單、分層
通過C學Python(1)關於語言、數值類型和變量
而在 有一種 float char 有用 運行時 復數運算 單獨的數 數值類型 強類型語言,不可能出現“程序執行出錯後仍可繼續執行,並且該錯誤導致的問題使後續執行可能出現任意行為”這類錯誤,這類錯誤的例子,如C裏的緩沖區溢出、Jump到錯誤地址。 弱類型語言,類型檢查更不嚴
Maven入門實戰(二)——依賴新增、依賴範圍和SpringMVC的結合
上一節中我們介紹了Maven的作用以及相關的安裝配置方法和一個非常簡單的例項,接下來我們更近一步,為了加深對專案的影響,我們將結合SpringMVC進行Maven專案的實戰。 1 Maven的依賴新增 首先我們先建立一個Maven工程,建立方法同上一節中的方法,
Windows10下python3和python2同時安裝(二)python2.exe、python3.exe和pip2、pip3設定
Windows10下python3和python2同時安裝(二)python2.exe、python3.exe和pip2、pip3設定說明:安裝安裝python3和python2請參考本系列教程(一)1
跟我一起學python(三),python基本資料型別和函式
三元運算: 三元運算(三目運算),是對簡單的條件語句的縮寫。 # 書寫格式 result = 值1 if 條件 else 值2 # 如果條件成立,那麼將 “值1” 賦值給result變數,否則,將“值2”賦值給result變數 if a == 1:
Python的學習(二)----單引號、雙引號和三雙引號的區別
Python單引號、雙引號和三雙引號的區別 python字串通常有單引號('...')、雙引號("...")、三引號("""...""")或('''...''')包圍,三引號包含的字串可由多行組成,一般可表示大段的敘述性字串。在使用時基本沒有差別,但雙引號和三引號("""
Kafka 入門(二)--資料日誌、副本機制和消費策略
一、Kafka 資料日誌 1.主題 Topic Topic 是邏輯概念。 主題類似於分類,也可以理解為一個訊息的集合。每一條傳送到 Kafka 的訊息都會帶上一個主題資訊,表明屬於哪個主題。 Kafka 的主題是支援多使用者訂閱的,即一個主題可以有零個、一個或者多個消費者來訂閱該主題的訊息。 2.
Python學習記錄——Ubuntu(一)基本配置、快捷鍵和系統啟停命令行
輸入 中間 設置時間 etc oot cond ubuntu 格式化 當前時間 一.常用的獲取幫助方法: 1.-h 2.--help 3.man man 章節 查找的信息 #用於查詢某指令在某章節中的幫助信息 man -f #精確查找 man -k #模糊查
C Primer Plus學習筆記(四)- 運算符、表達式和語句
post 函數表 浮點 ima 數據存儲 定義 數據對象 其他 符號整型 基本運算符 賦值運算符:= 在C語言中,=不是“相等”,而是賦值運算符,把左邊的值賦給右邊的變量 a = 2018; //把值2018賦給變量a 賦值表達式語句的目的是把值儲存到內存位置上,用
《JavaScript高級程序設計》讀書筆記(四)變量、作用域和內存問題
att 數量 線程 添加屬性 限制 mil web 全局 正常 內容---理解基本類型和引用類型的值---理解執行環境---理解垃圾收集 --JavaScript變量松散類型的本質--決定了它只是在特定時間用於保存特定值的一個名字而已--變量的值及其數據類型可以在腳本的生命
Java基礎鞏固(四)-流(Stream)、檔案(File)和IO
Java流(Stream)、檔案(File)和IO Java.io 包幾乎包含了所有操作輸入、輸出需要的類。所有這些流類代表了輸入源和輸出目標。 Java.io 包中的流支援很多種格式,比如:基本型別、物件、本地化字符集等等。 一個流可以理解為一個數據的序列。輸入流表示從一個源讀取資
交換機(三)接入層、匯聚層和核心層交換機的特點
做網路相關行業的朋友們,一定不會對接入層、匯聚層、核心層這些跟交換機相關的網路術語感到陌生,那麼它們究竟代表什麼含義,什麼樣的交換機適合放在接入層、匯聚層和核心層呢?小編希望在本文裡能以淺顯易懂的語言和適當的例子為還不十分明白的朋友們解釋清楚這幾個概念。
深入淺出解讀"多巴胺(Dopamine)論文"、環境配置和例項分析
Paper: Dopamine–a research framework for deep reinforcement Learning Github: https://github.com/google/dopamine 論文的首頁明顯告訴我們,這是一篇Google出的論文(
【無私分享:從入門到精通ASP.NET MVC】從0開始,一起搭框架、做專案 (10)部門管理、崗位管理和員工管理
1 USE [wkmvc_db] 2 GO 3 /****** Object: Table [dbo].[SYS_POST_USER] Script Date: 2016/6/20 16:28:44 ******/ 4 SET ANSI_NULLS ON 5 GO
深入JVM 原理(七)老年代、永久代和元空間
目錄 老年代 老年代主要接收由年輕代傳送過來的物件,一般情況下,經過了數次Minor GC 之後還會儲存下來的物件才會進入到老年代。如果要儲存的物件超過了伊甸園區的大小,此物件也將直接儲存在老年代之中,當老年代記憶體不足時,將引發 “major GC”,
Hive(一)資料型別、檔案格式和資料定義
1、基本資料型別 Hive支援多種不同長度的整型和浮點型資料型別,支援布林型別,也支援無長度限制的字串型別,後續的Hive增加了時間戳資料型別和二進位制陣列資料型別。 和其他的SQL語言一樣,這些都是保留字。需要注意的是所有的這些資料型別都是對Jav
《深度探索C++物件模型》筆記(三)建構函式、拷貝構造和初始化列表
歡迎檢視系列部落格: -------------------------------------------------------------------------------------------------------------- 看了這一章
Servlet(10)Http協議、HTTP請求和響應頭及其詳解(檔案下載)
1 HTTP協議 HTTP協議是網際網路上應用最廣泛的一種網路協議。是工作在TCP/IP協議基礎上的,所有的www檔案都必須遵守這個標準。設計HTTP的最初目的是為了提供一種釋出和接受HTML頁面的方法。 HTTP是TCP/IP協議的一個應用層協議,也是we
JSP學習筆記(1)——Jsp指令、動作元素和內建物件
簡單來說,javaweb技術就是讓伺服器端能夠執行Java程式碼,之後返回資料給客戶端(瀏覽器)讓客戶端顯示資料 jsp頁面中可以巢狀java程式碼(java小指令碼)和巢狀Web前端(html,css,js)來顯示資料。 伺服器解析一個jsp,其實就是把jsp中的java程式碼編譯並執行,之後再返回一個St