
Spark學習筆記4——spark執行機制
Spark架構及執行機制
Spark執行架構包括叢集資源管理器(Cluster Manager)、執行作業任務的工作節點(Worker Node)、每個應用的任務控制節點(Driver)和每個工作節點上負責具體任務的執行程序(Executor)。其中,叢集資源管理器可以是Spark自帶的資源管理器,也可以是YARN或Mesos等資源管理框架。
與Hadoop MapReduce計算框架相比,Spark所採用的Executor有兩個優點:一是利用多執行緒來執行具體的任務(Hadoop MapReduce採用的是程序模型),減少任務的啟動開銷;二是Executor中有一個BlockManager儲存模組,會將記憶體和磁碟共同作為儲存裝置,當需要多輪迭代計算時,可以將中間結果儲存到這個儲存模組裡,下次需要時,就可以直接讀該儲存模組裡的資料,而不需要讀寫到HDFS等檔案系統裡,因而有效減少了IO開銷;或者在互動式查詢場景下,預先將表快取到該儲存系統上,從而可以提高讀寫IO效能。
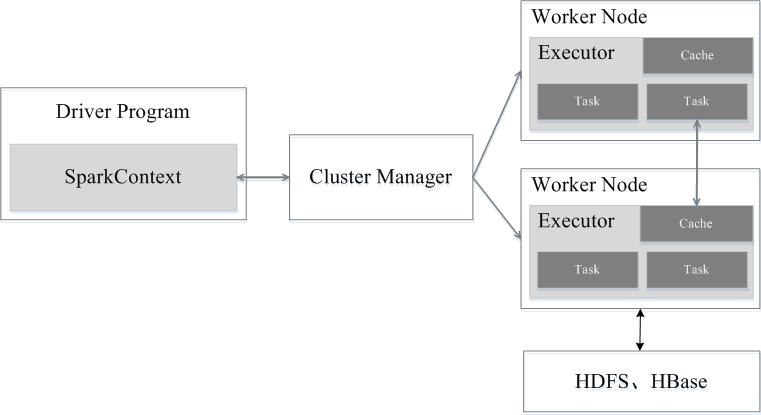 Spark執行架構
Spark執行架構
總體而言,如上圖所示,在Spark中,一個應用(Application)由一個任務控制節點(Driver)和若干個作業(Job)構成,一個作業由多個階段(Stage)構成,一個階段由多個任務(Task)組成。當執行一個應用時,任務控制節點會向叢集管理器(Cluster Manager)申請資源,啟動Executor,並向Executor傳送應用程式程式碼和檔案,然後在Executor上執行任務,執行結束後,執行結果會返回給任務控制節點,或者寫到HDFS或者其他資料庫中。
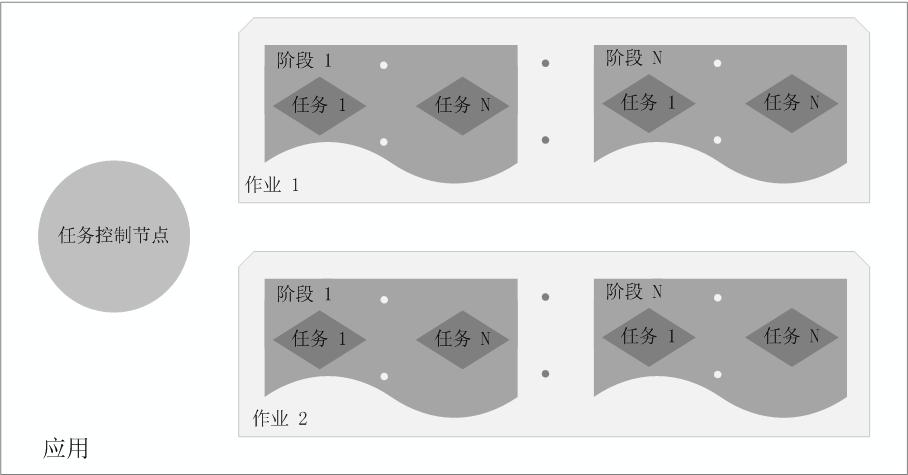
Spark執行基本流程
Spark的基本執行流程如下:
(1)當一個Spark應用被提交時,首先需要為這個應用構建起基本的執行環境,即由任務控制節點(Driver)建立一個SparkContext,由SparkContext負責和資源管理器(Cluster Manager)的通訊以及進行資源的申請、任務的分配和監控等。SparkContext會向資源管理器註冊並申請執行Executor的資源;
(2)資源管理器為Executor分配資源,並啟動Executor程序,Executor執行情況將隨著“心跳”傳送到資源管理器上;
(3)SparkContext根據RDD的依賴關係構建DAG圖,DAG圖提交給DAG排程器(DAGScheduler)進行解析,將DAG圖分解成多個“階段”(每個階段都是一個任務集),並且計算出各個階段之間的依賴關係,然後把一個個“任務集”提交給底層的任務排程器(TaskScheduler)進行處理;Executor向SparkContext申請任務,任務排程器將任務分發給Executor執行,同時,SparkContext將應用程式程式碼發放給Executor;
(4)任務在Executor上執行,把執行結果反饋給任務排程器,然後反饋給DAG排程器,執行完畢後寫入資料並釋放所有資源。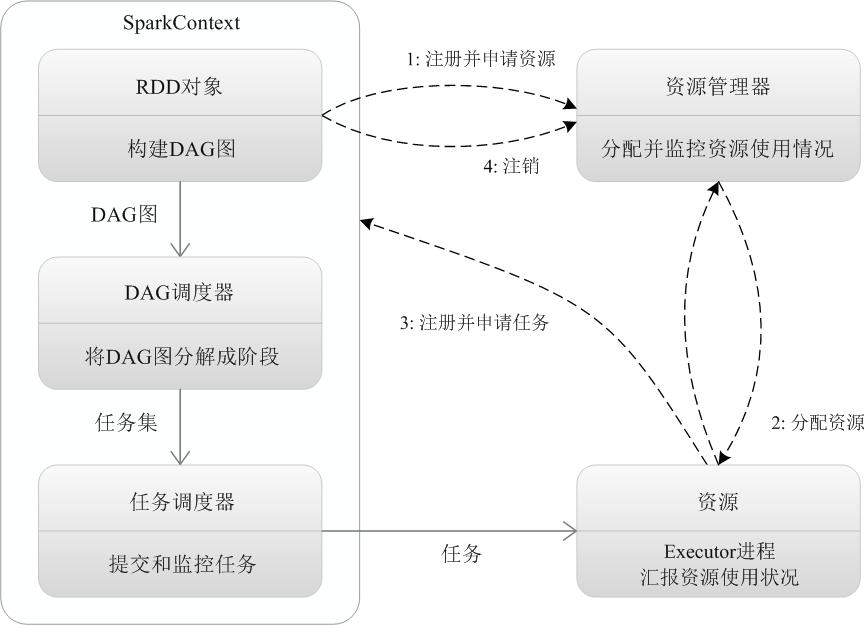
總體而言,Spark執行架構具有以下特點:
(1)每個應用都有自己專屬的Executor程序,並且該程序在應用執行期間一直駐留。Executor程序以多執行緒的方式執行任務,減少了多程序任務頻繁的啟動開銷,使得任務執行變得非常高效和可靠;
(2)Spark執行過程與資源管理器無關,只要能夠獲取Executor程序並保持通訊即可;
(3)Executor上有一個BlockManager儲存模組,類似於鍵值儲存系統(把記憶體和磁碟共同作為儲存裝置),在處理迭代計算任務時,不需要把中間結果寫入到HDFS等檔案系統,而是直接放在這個儲存系統上,後續有需要時就可以直接讀取;在互動式查詢場景下,也可以把表提前快取到這個儲存系統上,提高讀寫IO效能;
(4)任務採用了資料本地性和推測執行等優化機制。資料本地性是儘量將計算移到資料所在的節點上進行,即“計算向資料靠攏”,因為移動計算比移動資料所佔的網路資源要少得多。而且,Spark採用了延時排程機制,可以在更大的程度上實現執行過程優化。比如,擁有資料的節點當前正被其他的任務佔用,那麼,在這種情況下是否需要將資料移動到其他的空閒節點呢?答案是不一定。因為,如果經過預測發現當前節點結束當前任務的時間要比移動資料的時間還要少,那麼,排程就會等待,直到當前節點可用。
相關推薦
Spark學習筆記4——spark執行機制
Spark架構及執行機制 Spark執行架構包括叢集資源管理器(Cluster Manager)、執行作業任務的工作節點(Worker Node)、每個應用的任務控制節點(Driver)和每個工作節點上負責具體任務的執行程序(Executor)。其中,叢集資源管理器可以是S
Spark計算Pi執行過程詳解---Spark學習筆記4
上回運行了一個計算Pi的例子 那麼Spark究竟是怎麼執行的呢? 我們來看一下指令碼 #!/bin/sh export YARN_CONF_DIR=/home/victor/software/hadoop-2.2.0/etc/hadoop SPARK_JAR=./ass
Spark學習筆記4:數據讀取與保存
讀取數據 chapter byte hadoop tar .lib 文件中 api sequence Spark對很多種文件格式的讀取和保存方式都很簡單。Spark會根據文件擴展名選擇對應的處理方式。 Spark支持的一些常見文件格式如下: 1、文本文件 使用文件
Spark SQL 筆記(4)——Spark SQL 介紹
1 Spark SQL 背景介紹 1.1 Hive 介紹 類似 sql 的 Hive QL 語言, sql -> mapreduce 改進: hive on tez,hive on spark, hive on mapreduce 1.2 Spark
Spark學習筆記(一)----spark運算元操作
1.前言 最近在幫公司瞭解大資料方面的技術,涉及到spark的相關內容,所以想寫個筆記記錄一下。目前用到的時spark2.1.0的版本,僅供學習參考。 2.正文 2.1spark官網運算元的分類 spark官網上面有對於運算元的描述,但是spark對於運算元的分類粒度較粗,大致為transform
Spark學習筆記之-Spark遠端除錯
Spark遠端除錯 本例子介紹簡單介紹spark一種遠端除錯方法,使用的IDE是IntelliJ IDEA。 1、瞭解jvm一些引數屬性 -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,addres
【spark 學習筆記】Spark學習筆記精華(1)
好記性不如爛筆頭,順便就開始用手機練習打字了,也分享給感興趣的朋友學習下。 1.take可以檢視RDD中前面幾個元素,而且代價很小。 rdd.take(5) 2.可以用takeSample對資料
Spark學習筆記:Spark Streaming與Spark SQL協同工作
Spark Streaming與Spark SQL協同工作 Spark Streaming可以和Spark Core,Spark SQL整合在一起使用,這也是它最強大的一個地方。 例項:實時統計搜尋次數大於3次的搜尋詞 package StreamingDemo i
Spark學習筆記(10)—— wordcount 執行流程分析
1 啟動叢集 啟動 HDFS start-dfs.sh 啟動 Spark 叢集 /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/sbin/start-all
大資料實時計算Spark學習筆記(4)—— Spak核心 API 模組介紹
1 Spark 介紹 1.1 Spark 特點 速度:在記憶體中儲存中間結果 支援多種語言 內建 80+ 的運算元 高階分析:MR,SQL/ Streaming/Mlib/Graph 1.2 Spark 模組 core : 通用執行
蝸龍徒行-Spark學習筆記【五】IDEA中叢集執行模式的配置
問題現象 在IDEA中執行sparkPI,報錯: Exception in thread “main” org.apache.spark.SparkException: A master URL must be set in your configurati
Spark學習筆記——文本處理技術
使用 ken ins main 最小 leg tran sparse rain 1.建立TF-IDF模型 import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.mllib.lin
Spark學習筆記——泰坦尼克生還預測
cti build case model 學習筆記 classes gre dict path package kaggle import org.apache.spark.SparkContext import org.apache.spark.SparkConf i
Spark學習筆記(一)
-s 環境 從數據 多個 成了 lib one python ted 概念: Spark是加州大學伯克利分校AMP實驗室,開發的通用內存並行計算框架。 支持用scala、java和Python等語言編寫應用程序。相較於Hdoop,往往有更好的運行效率。 Spark包括了Sp
Spark 學習筆記之 MONGODB SPARK CONNECTOR 插入性能測試
log font span 技術 strong mongos str server 學習 MONGODB SPARK CONNECTOR 測試數據量: 測試結果: 116萬數據通過4個表的join,從SQL Server查出,耗時1分多。MongoSp
Spark學習筆記3:鍵值對操作
對象 常用 ava java 參數 通過 頁面 ascend 處理過程 鍵值對RDD通常用來進行聚合計算,Spark為包含鍵值對類型的RDD提供了一些專有的操作。這些RDD被稱為pair RDD。pair RDD提供了並行操作各個鍵或跨節點重新進行數據分組的操作接口。 Sp
spark 學習筆記-spark2.2.0
submit -- org hdf doc kpi jdk profile apach master:192.168.11.2 s1:192.168.11.3 s2 :192.168.11.4 共三個節點 第一步配置(三臺一樣) http://
Spark 學習筆記之 Standalone與Yarn啟動和運行時間測試
span ima 上傳 運行 yarn erl 技術分享 word wordcount Standalone與Yarn啟動和運行時間測試: 寫一個簡單的wordcount: 打包上傳運行: Standalone啟動: 運行時間:
Spark 學習筆記之 Streaming Window
min .cn spa pan tex def rec mas clas Streaming Window: 上圖意思:每隔2秒統計前3秒的數據 slideDuration: 2 windowDuration: 3 例子: import org.apach
Spark學習筆記
function 調度 mas split each 架構 char ase 一個 註意: 問題:Failed:execution error: return code 1 from org.apache.hadoop.hive.ql.exec.DDL Task MetaE