
spring-cloud-sleuth+zipkin追蹤服務實現(二)
1. 簡述
在上一節《spring-cloud-sleuth+zipkin追蹤服務實現(一)》中,我們使用microservice-zipkin-server、microservice-zipkin-client、microservice-zipkin-client-backend 三個程式實現了使用http方式進行通訊,資料持久化到記憶體中的服務呼叫鏈路追蹤實現。
在這裡我們做兩點改動,首先是資料從儲存在記憶體中改為持久化到資料庫,其次是將http通訊改為mq非同步方式通訊。
我們還是使用之前上一節中的三個程式做修改,方便大家看到對比不同點。這裡每個專案名都加了一個stream,用來表示區別。
2、microservice-zipkin-stream-server
要將http方式改為通過MQ通訊,我們要將依賴的原來依賴的io.zipkin.java:zipkin-server換成spring-cloud-sleuth-zipkin-stream和spring-cloud-starter-stream-rabbit
同時要使用mysql持久化,我們需要新增mysql相關依賴。
全部maven依賴如下:
``` <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!--zipkin依賴--> <!--此依賴會自動引入spring-cloud-sleuth-stream並且引入zipkin的依賴包--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> <scope>runtime</scope> </dependency> <!--儲存到資料庫需要如下依賴--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> ```
新增以上maven依賴後,我們將啟動類ZipkinServer中@EnableZipkinServer註解替換成@EnableZipkinStreamServer,
具體如下:
package com.yangyang.cloud; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer; /** * Created by chenshunyang on 2017/5/24. */ @EnableZipkinStreamServer// //使用Stream方式啟動ZipkinServer @SpringBootApplication public class ZipkinStreamServerApplication { public static void main(String[] args) { SpringApplication.run(ZipkinStreamServerApplication.class,args); } }
點選@EnableZipkinStreamServer註解的原始碼我們可以看到它也引入了@EnableZipkinServer註解,同時還建立了一個rabbit-mq的訊息佇列監聽器。
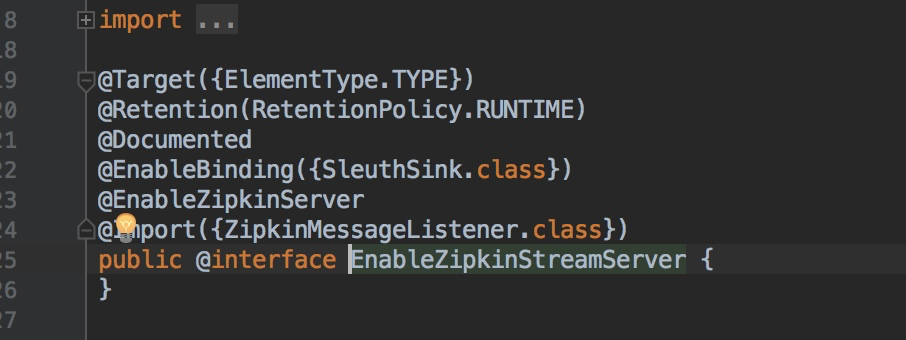
以方便接收從訊息客戶端收集發過來的mq訊息。
由於使用了訊息中介軟體rabbit mq以及mysql,所以我們還需要在配置檔案application.properties加入相關的配置:
server.port=11020
spring.application.name=microservice-zipkin-stream-server
#zipkin資料儲存到資料庫中需要進行如下配置
#表示當前程式不使用sleuth
spring.sleuth.enabled=false
#表示zipkin資料儲存方式是mysql
zipkin.storage.type=mysql
#資料庫指令碼建立地址,當有多個是可使用[x]表示集合第幾個元素
spring.datasource.schema[0]=classpath:/zipkin.sql
#spring boot資料來源配置
spring.datasource.url=jdbc:mysql://localhost:3306/zipkin?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.initialize=true
spring.datasource.continue-on-error=true
#rabbitmq配置
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
其中zipkin.sql直接到官網去拷貝,也可以從本demo中拷貝
為了避免http通訊的干擾,我們將原來的監聽埠有11008更改為11020,啟動程式,未報錯且能夠看到rabbit連線日誌,說明程式啟動成功。
3.microservice-zipkin-stream-client、microservice-zipkin-client-stream-backend
與上一節中的配置一樣,客戶端的配置也非常簡單,maven依賴只需要將原來的spring-cloud-starter-zipkin替換為如下兩個依賴即可
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>此外,在配置檔案中也加上連線MQ的配置
server:
port: 11021
spring:
application:
name: microservice-zipkin-stream-client
#rabbitmq配置
rabbitmq:
host: 127.0.0.1
port : 5672
username: guest
password: guest
當然為了以示區別,埠也做了相應的調整
4.測試
按照上一節的方式訪問:http://localhost:11021/call/1,我們可以上一節,說明rabbit-mq方式通訊的sleuth功能已經生效了。
我們多次訪問consumer的地址可以看到日誌中,請求的耗時時間不會再次出現突然耗時特長的情況。
為了體驗MQ通訊給我們帶來的資料不丟失的特點,我們將資料庫中的資料清空,然後重新整理zipkin server的介面,可以看到不再有資料
然後我們將zipkin-server程式想關閉,然後再多次訪問consumer的地址,之後,我們重啟zipkin server程式,啟動成功後訪問UI介面
很快看到Span Name選項有資料可以選擇了,同時資料庫中的記錄條數也不再是之前的0條了
如此說明我們的zipkin重啟後,從MQ中成功獲取出了在關閉這段時間裡provider和consumer產生的資訊資料。這樣我們使用spring-cloud-sleuth-stream+zipkin方式的rest服務呼叫追蹤功能就OK了。
5.專案原始碼:
https://git.oschina.net/shunyang/spring-cloud-microservice-study.git
https://github.com/shunyang/spring-cloud-microservice-study.git
6.參考文件:
spring cloud 官方文件:https://github.com/spring-cloud/spring-cloud-sleuth
第三方:https://yq.aliyun.com/articles/78128?utm_campaign=wenzhang&utm_medium=article&utm_source=QQ-qun&201758&utm_content=m_19862
相關推薦
spring-cloud-sleuth+zipkin追蹤服務實現(二)
1. 簡述 在上一節《spring-cloud-sleuth+zipkin追蹤服務實現(一)》中,我們使用microservice-zipkin-server、microservice-zipkin-client、microservice-zipkin-client-backend 三個程式實現了使用http
spring-cloud-sleuth+zipkin追蹤服務實現(四)
1.前言 在上一篇spring-cloud-sleuth+zipkin追蹤服務實現(三)的處理實現後,很多朋友告訴我,在zipkin server的管理頁面無法看到專案依賴關係。 當時也沒有多想,以為是spring cloud zipkin的一個bug,後來發現是自己看文件的疏忽。 文中寫到對於Cassan
spring-cloud-sleuth+zipkin追蹤服務實現(三)
1.前言 在上一篇spring-cloud-sleuth+zipkin追蹤服務實現(二)中我們講述了利用mq的方式傳送資料,儲存在mysql,實際生產過程中呼叫資料量非常的大,mysql儲存並不是很好的選擇,這時我們可以採用elasticsearch進行儲存。 我們還是使用之前上一節中的三個程式做修改,方便大
spring-cloud-sleuth+zipkin追蹤服務實現(一)
1.簡述 最近在學習spring cloud構建微服務,研究追蹤微服務rest服務呼叫鏈路的問題,接觸到zipkin,而spring cloud也提供了spring-cloud-sleuth來方便整合zipkin實現。 我們準備了三個必要的程式來做測試,分別是 1、microservice-zipkin-se
spring-cloud-sleuth+zipkin追蹤服務
本文簡單介紹瞭如何利用Zipkin對SpringCloud應用進行服務分析在實際的應用場景中,Zipkin可以結合壓力測試工具一起使用,分析系統在大壓力下的可用性和效能。設想這麼一種情況,如果你的微服務數量逐漸增大,服務間的依賴關係越來越複雜,怎麼分析它們之間的呼叫關係及相互
Spring Cloud Sleuth + zipkin 實現服務追蹤
工作 process image -o 唯一id dep 單元 圖片 zipkin 服務追蹤 Spring Cloud Sleuth實現了一種分布式的服務鏈路跟蹤解決方案,通過使用Sleuth可以讓我們快速定位某個服務的問題。 官方文檔地址如下: http://cloud
全鏈路追蹤spring-cloud-sleuth-zipkin
authorize 采樣 quest child 手機號 main rgs lin oot 微服務架構下 多個服務之間相互調用,在解決問題的時候,請求鏈路的追蹤是十分有必要的,鑒於項目中采用的spring cloud架構,所以為了方便使用,便於接入等 項目中采用了sprin
全鏈路spring cloud sleuth+zipkin
arc owa version public kafka 分享 cli self 兩個 http://blog.csdn.net/qq_15138455/article/details/72956232 版權聲明:@入江之鯨 一、About ZipKi
Spring Cloud 應用篇 之 Spring Cloud Sleuth + Zipkin(三)修改資料儲存方式
(一)簡介預設情況下,Zipkin Server 會將跟蹤資訊儲存在記憶體中,每次重啟 Zipkin Server 都會使之前收集的跟蹤資訊丟失,並且當有大量跟蹤資訊時,記憶體儲存也會造成效能瓶頸,所以通常我們都需要將跟蹤資訊儲存到外部元件中,如 Mysql。由於 Sprin
spring-cloud-sleuth+zipkin原始碼探究
1.1. 前言 粗略看了下spring cloud sleuth core原始碼,發現內容真的有點多,它支援了很多型別的鏈
Spring Cloud Alibaba學習筆記(23) - 呼叫鏈監控工具Spring Cloud Sleuth + Zipkin
隨著業務發展,系統拆分導致系統呼叫鏈路愈發複雜一個前端請求可能最終需要呼叫很多次後端服務才能完成,當整個請求陷入效能瓶頸或不可用時,我們是無法得知該請求是由某個或某些後端服務引起的,這時就需要解決如何快讀定位服務故障點,以對症下藥。於是就有了分散式系統呼叫跟蹤的誕生。 Spring Cloud Sleuth
springcloud服務追蹤Zipkin和spring cloud Sleuth
參考文章一: 摘要: 本文簡單介紹瞭如何利用Zipkin對SpringCloud應用進行服務分析。在實際的應用場景中,Zipkin可以結合壓力測試工具一起使用,分析系統在大壓力下的可用性和效能。 設想這麼一種情況,如果你的微服務數量逐漸增大,服務間的依賴關係越來越複雜,怎麼分析它們
微服務學習筆記--使用Spring Cloud Sleuth配合Zipkin實現微服務的跟蹤
在微服務架構中可以使用Zipkin來追蹤服務呼叫鏈路,可以知道各個服務的呼叫依賴關係。在Spring Cloud中,也提供了Spring Cloud Sleuth來方便整合Zipkin實現。 本文使用一個Zipkin Server,使用者微服務,電影微服務來實現
spring cloud 入門系列八:使用spring cloud sleuth整合zipkin進行服務鏈路追蹤
好久沒有寫部落格了,主要是最近有些忙,今天忙裡偷閒來一篇。 =======我是華麗的分割線========== 微服務架構是一種分散式架構,微服務系統按照業務劃分服務單元,一個微服務往往會有很多個服務單元,一個請求往往會有很多個單元參與,一旦請求出現異常,想要去定位問題點真心不容易,因此需要有個東西去跟蹤
Spring Cloud應用進行服務追蹤分析(Zipkin和spring cloud Sleuth)
參考文章二:(我參考的這個) 最近在學習spring cloud構建微服務,很多大牛都提供很多入門的例子幫助我們學習,對於我們這種英語不好的碼農來說,效率著實提高不少。這兩天學習到追蹤微服務rest服務呼叫鏈路的問題,接觸到zipkin,而spring cloud也提供了spring-cloud-sleu
業余草 SpringCloud教程 | 第九篇: 服務鏈路追蹤(Spring Cloud Sleuth)(Finchley版本)
描述 -s util ont packaging tdd res [] 新建 這篇文章主要講述服務追蹤組件zipkin,Spring Cloud Sleuth集成了zipkin組件。 一、簡介 Add sleuth to the classpath of a Spr
SpringCloud2.0版本入門 | 服務鏈路追蹤(Spring Cloud Sleuth)簡單入門
本文出自 [ 慌途L ] 最近開始寫部落格,一些問題可能瞭解也不夠透徹,寫一下快速入門並且踩過的坑,希望大家少踩坑。本文簡單介紹一下springcloud的服務鏈路追蹤,不足之處希望大家指出,我改正。不喜勿噴! 這篇文章主要講述服務追蹤元件zipkin,Spr
Spring Cloud Sleuth服務鏈路追蹤(mysql儲存鏈路資料)(Finchley版本)
在Spring Cloud Sleuth服務鏈路追蹤(Finchley版本)中,我們使用Spring Cloud Sleuth和zipkin的整合實現了服務鏈路的追蹤,但是遺憾的是鏈路資料儲存在記憶體中,無法持久化。zipkin的持久化可以結合Elasticsearch,MySQL實現。本節
springcloud(十二):使用Spring Cloud Sleuth和Zipkin進行分散式鏈路跟蹤
Spring Cloud Sleuth 一般的,一個分散式服務跟蹤系統,主要有三部分:資料收集、資料儲存和資料展示。根據系統大小不同,每一部分的結構又有一定變化。譬如,對於大規模分散式系統,資料儲存可分為實時資料和全量資料兩部分,實時資料用於故障排查(troubleshooting),全量資料用於系統優化;資
springcloud+springboot(十二):使用Spring Cloud Sleuth和Zipkin進行分散式鏈路跟蹤
Spring Cloud Sleuth 一般的,一個分散式服務跟蹤系統,主要有三部分:資料收集、資料儲存和資料展示。根據系統大小不同,每一部分的結構又有一定變化。譬如,對於大規模分散式系統,資料儲存可分為實時資料和全量資料兩部分,實時資料用於故障排查(troubleshooting),全量資料用於系統優化