
Flink之一 Flink基本原理介紹
Flink介紹:
很多人可能都是在 2015 年才聽到 Flink 這個詞,其實早在 2008 年,Flink 的前身已經是柏林理工大學一個研究性專案, 在 2014 被 Apache 孵化器所接受,然後迅速地成為了 ASF(Apache Software Foundation)的頂級專案之一。Flink 的最新版本目前已經更新到了 0.10.0 了,在很多人感慨 Spark 的快速發展的同時,或許我們也該為 Flink 的發展速度點個贊。
Flink 是一個針對流資料和批資料的分散式處理引擎。它主要是由 Java 程式碼實現。目前主要還是依靠開源社群的貢獻而發展。對 Flink 而言,其所要處理的主要場景就是流資料,批資料只是流資料的一個極限特例而已。再換句話說,Flink 會把所有任務當成流來處理,這也是其最大的特點。Flink 可以支援本地的快速迭代,以及一些環形的迭代任務。
Flink的特性:
Flink是個分散式流處理開源框架:
1: 即使資料來源是無序的或者晚到達的資料,也能保持結果準確性
2:有狀態並且容錯,可以無縫的從失敗中恢復,並可以保持exactly-once
3:大規模分散式
Flink可以確保僅一次語義狀態計算;Flink有狀態意味著,程式可以保持已經處理過的資料;
Flink支援流處理和視窗事件時間語義,Flink支援靈活的基於時間視窗,計數,或會話資料驅動的窗戶;
Flink容錯是輕量級和在同一時間允許系統維持高吞吐率和提供僅一次的一致性保證,Flink從失敗中恢復,零資料丟失;
Flink能夠高吞吐量和低延遲;
Flink儲存點提供版本控制機制,從而能夠更新應用程式或再加工歷史資料沒有丟失並在最小的停機時間。
Flink相關概念:
Parallel Dataflows
Flink中把整個流處理過程叫做Stream Dataflow,從資料來源提取資料的操作叫做Source Operator,中間的map(),聚合、統計等操作可以統稱為Tranformation Operators,最後結果資料的流出被稱為sink operators,具體可以見下方圖示:
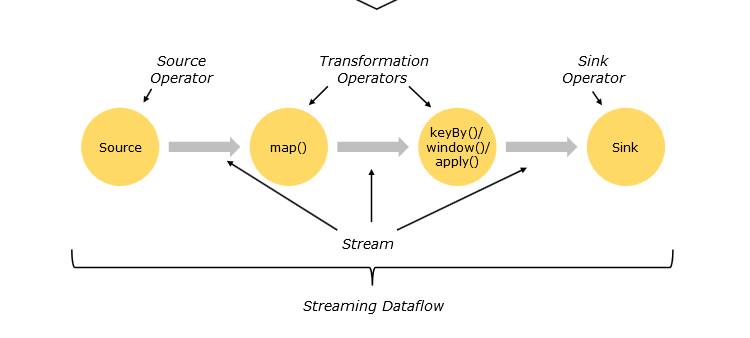
Flink的程式內在是並行和分散式的,資料流可以被分割槽成stream partitions,operators被劃分為operator subtasks;這些subtasks在不同的機器或容器中分不同的執行緒獨立執行;operator subtasks的數量在具體的operator就是平行計算數,程式不同的operator階段可能有不同的並行數;如下圖所示,source
operator的並行數為2,但最後的sink operator為1;
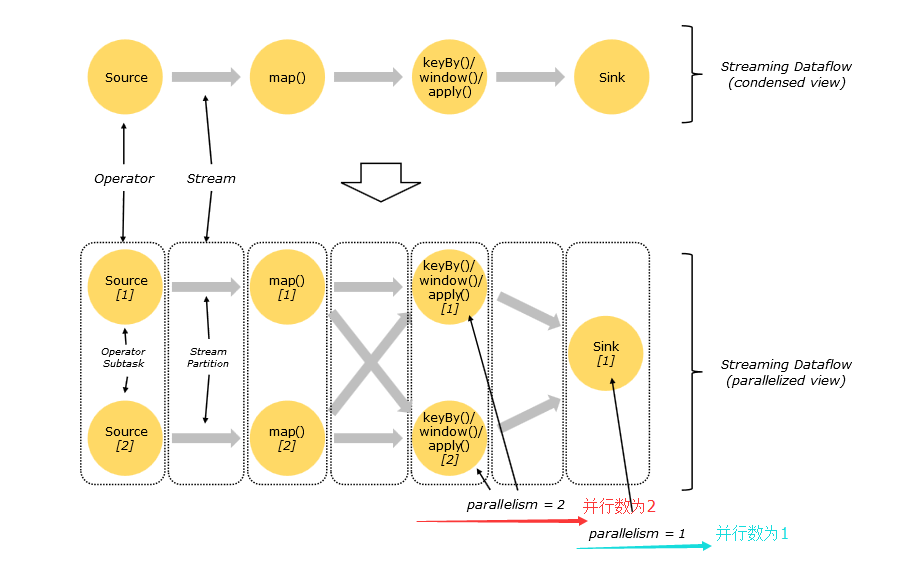
資料在兩個operator之間傳遞的時候有兩種模式:
一:one-to-one 模式:兩個operator用此模式傳遞的時候,會保持資料的分割槽數和資料的排序;
二:Redistributing 模式:這種模式會改變資料的分割槽數;每個一個operator subtask會根據選擇transformation把資料傳送到不同的目標subtasks,比如keyBy()會通過hashcode重新分割槽,broadcast()和rebalance()方法會隨機重新分割槽;
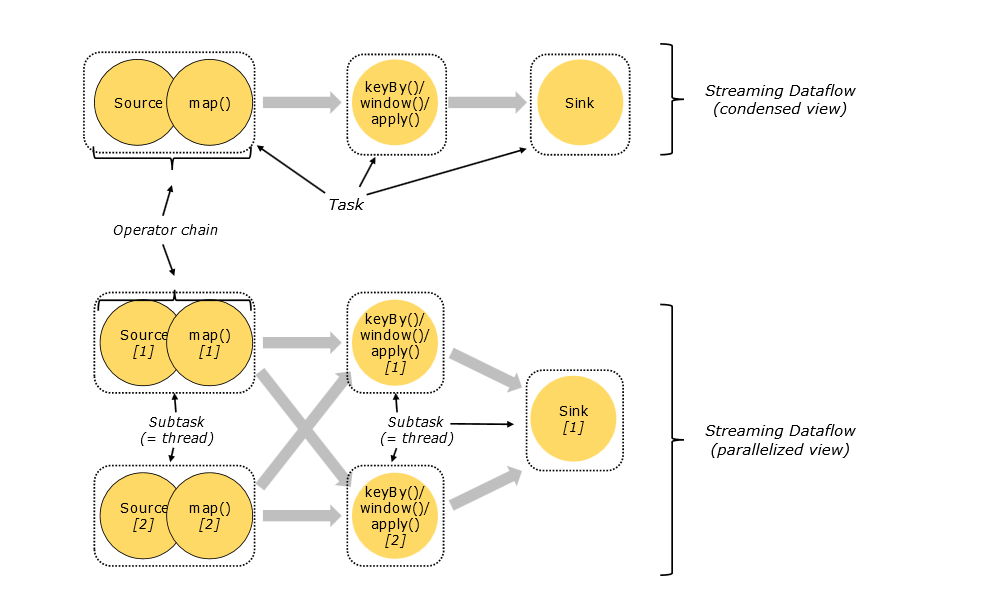
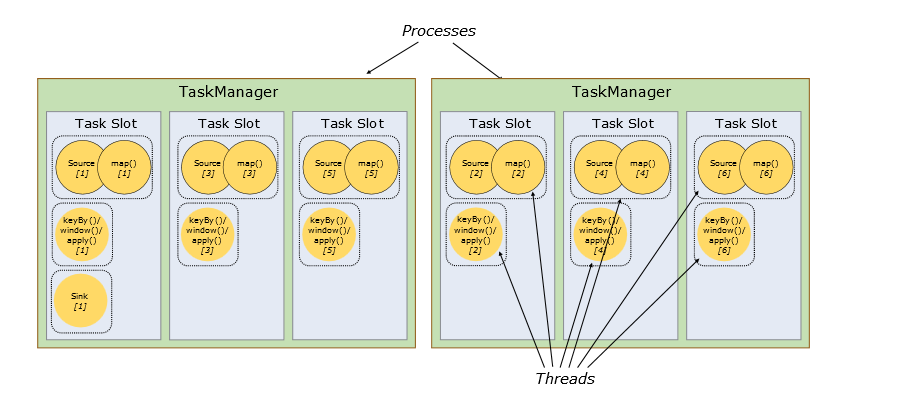
Tasks & Operator Chains
對於分散式計算,Flink封裝operator subtasks 鏈化為tasks;每個task由一個執行緒執行;把tasks鏈化有助於優化,它減少了開銷執行緒和執行緒之間的交接和緩衝;增加了吞吐量和減少延遲時間;鏈化的作用可以見下圖:在沒有鏈化之前,source operator和map operator 是兩個執行緒執行的兩個task,也就是說下面的dataflow 最初應該有7個subtasks;
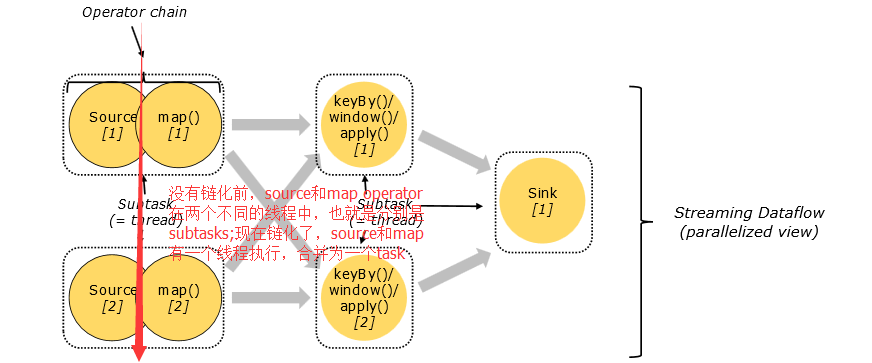
但經過優化鏈化後,source和map合併為一個task,有一個執行緒執行,這樣優化可以減少source operator 和map operator兩個執行緒之間的交接和快取開銷;鏈化後只有5個task;對於鏈化這個優化,筆者也有疑問:是否是operator之間資料傳遞模式相同才能鏈化?
Distributed Execution
Flink runTime 包括兩種型別程序(類似於第一代hadoop架構):
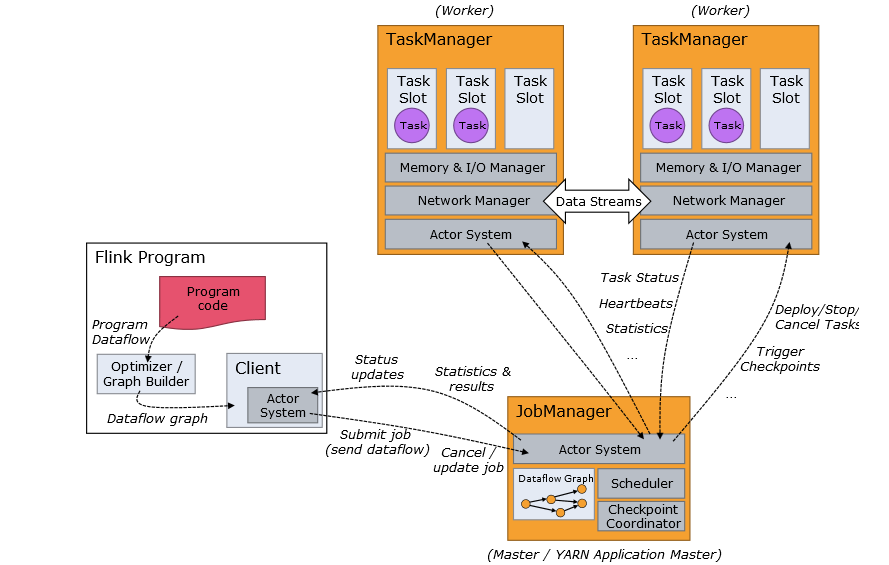
master程序;也叫作JobManager,協調各個節點工作;master排程task,協調checkpoints和容災;機器群中至少有一個master,高可用機器中可以有多個master,但要保證一個是leader,其他是standby;
work 型別程序;也叫taskManagers;具體執行tasks;
client 雖然不是執行和程式的一部分,但是客戶端常被用作準備和傳送dataflow給master;
flink作業提交架構流程可見下圖:
Workers, Slots, Resources
每一個TaskManager是個jvm,每個jvm中可以執行一個或者多個subtasks,jvm中taskSlot的數量決定了接受多少個task;每個tasksolt都有固定的資源,比如TaskManager有三個task solts,taskManager把平均把管理的記憶體分配到三個task slot中,這樣solt中的task不會跟其他的job競爭資源;預設上Flink許可subtasks去分享同一個是slots;但要保證這些subtask是不同的task,並且來自相同的Job;極端情況下,一個slot中執行整個job的task;solt分享有兩個重要的好處:
1:flink 機群中可以用到的最高的平行計算數,就是taskSolt的數量
2:可以容易的達到資源利用;
solt 資源共享是可以在api中設定種控制;resource group機制可以設定哪些tasks 共享slots;
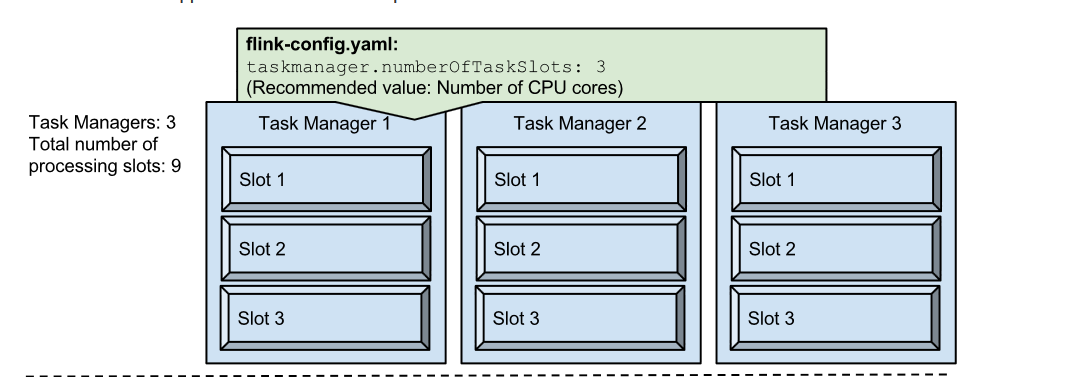
Configuring TaskManager processing slots
slot的數量通常設定是成正比的每個TaskManager可用CPU核的數量;一般建議,可用CPU核的數量正好是taskmanager.numberOfTaskSlots的數量,當開始Flink應用程式中,使用者可以提供slot的數量,可以在命令中加入-p(for paralleism)引數指定;另外也可以在API中設定;例如taskManager有三臺機器,並在flink-config.yaml中設定 taskmanager.numberOfTaskSlots:3(建議是cpu的核數);這樣每臺機器有3個slot,機器中共有9個processing taskslots,見下圖所示:
當設定parallelism.default:2 或者啟動的時候指定-p引數-./bin/flink -p2 或者程式碼中設定env.setParallelism(2),那邊task分配如下圖所示:

當然也可以把某個operator的並行度另外設定,比如把sink的並行度設定為1,那多task分配就會如下圖:

相關推薦
Flink之一 Flink基本原理介紹
Flink介紹: 很多人可能都是在 2015 年才聽到 Flink 這個詞,其實早在 2008 年,Flink 的前身已經是柏林理工大學一個研究性專案, 在 2014 被 Apache 孵化器所接受,然後迅速地成為了 ASF(Apache Software Foundati
消息服務百科全書——Kafka基本原理介紹
feature col 都是 指定 ESS 生成 接下來 另一個 追加 架構 1.1 總體架構 因為Kafka內在就是分布式的,一個Kafka集群通常包括多個代理。 為了均衡負載,將話題分成多個分區,每個代理存儲一或多個分區。多個生產者和消費者能夠同時生產和獲取消息。 一個
sqlite基本原理介紹與操作
sqlite 基本介紹 引題 為什麼使用資料庫: 之前的學習中,我們已經可以儲存資料,變數,讀寫本地檔案(txt,csv). 1. 持久化,記憶體中的變數當程式重啟和電腦斷電丟失資料,而硬碟可以長時間,持久地儲存資料,資料儲存到硬碟上的過程叫持久化, 2資料庫更加專業強大
909422229_資料爬蟲:爬蟲的基本原理介紹
一、什麼是爬蟲 爬蟲:請求網站並提取資料的自動化程式 百科:網路爬蟲(又被稱為網頁蜘蛛,網路機器人,在FOAF社群中間,更經常的稱為網頁追逐者),是一種按照一定的規則,自動地抓取全球資訊網資訊的程式或者指令碼。另外一些不常使用的名字還有螞蟻、自動索引、模擬程式或者蠕蟲。 如果我們把網
twemproxy0.4原理分析-基本原理介紹和優缺點分析
引言 接下來將會寫一個分析twemproxy的系列。該系列會對twemproxy最新版v0.4的原始碼進行分析,對設計原理進行剖析,力求用通俗的語言和圖來表達設計思想,並結合實際的使用達到深入淺出的效果。 概述 twemproxy是一個redis和memcached的輕量級分
rabbitmq - (訊息佇列) 的基本原理介紹
介紹 MQ全稱為Message Queue, 是一種分散式應用程式的的通訊方法,它是消費-生產者模型的一個典型的代表,producer往訊息佇列中不斷寫入訊息,而另一端consumer則可以讀取或者訂閱佇列中的訊息。RabbitMQ是MQ產品的典型代表,是一款基於AMQP協議可複用的企業訊息系統 系統架構
rabbitmq - (消息隊列) 的基本原理介紹
可復用 word conn 大致 hpa 服務 ges bind nor 介紹 MQ全稱為Message Queue, 是一種分布式應用程序的的通信方法,它是消費-生產者模型的一個典型的代表,producer往消息隊列中不斷寫入消息,而另一端consumer則可以讀取或者訂
kafka基本原理介紹,以及重新選舉,replica複製機制,isr等。
最近做的專案,通過資料庫的log日誌將資料庫某些千萬量級的表(這些表需要聯表查詢)資料同步到elasticsearch中,以減輕資料庫的查詢壓力,其中以kafka作為訊息中介軟體,以下是做該專案過程中對kafka的一些整理。 一、中介軟體 中介軟體,用於業務對於資料的時效
觸控式螢幕基本原理介紹【轉】
觸控式螢幕基本原理介紹一、輸入類裝置簡介1、IO輸入輸出,是計算機系統中的一個概念。計算機的主要功能就是從外部獲取資料然後進行計算加工得到輸出資料並輸出給外部(計算機可以看成資料處理器)。計算機和外部互動就是通過IO。每一臺計算機都有個標準輸入和標準輸出。2、常見的輸入類裝置
爬蟲基本原理介紹和初步實現(以抓取噹噹網圖書資訊為例)
本文程式碼等僅作學習記錄使用 一、爬蟲原理 網路爬蟲指按照一定的規則(模擬人工登入網頁的方式),自動抓取網路上的程式。簡單的說,就是講你上網所看到頁面上的內容獲取下來,並進行儲存。網路爬蟲的爬行策略分為深度優先和廣度優先。 (1)、深度優先 深度
語音識別基本原理介紹------dnn-hmm續
很久沒更新部落格了,最近找工作找的不是很順利,我一直很看好語音的應用,覺得需求很多,但或許對應屆生還是有些不一樣,等確定了再分享下找工作的經驗吧。這裡主要說下語音識別現在大家都用的模型-----dnn-hmm,我自己也不能更好的去解釋清楚,等我畢業前,我一定會把gmm-hm
Linux中斷(interrupt)子系統之一:中斷系統基本原理
兩個 ons ... req [0 共享 代碼 not spl 這個中斷系列文章主要針對移動設備中的Linux進行討論,文中的例子基本都是基於ARM這一體系架構,其他架構的原理其實也差不多,區別只是其中的硬件抽象層。內核版本基於3.3。雖然內核的版本不斷地提升,不過自從上一
LTE關鍵技術之一:OFDMA(OFDM基本原理及簡單例項應用)
OFDM即正交頻分複用(Orthogonal Frequency Division Multiplexing),是多載波調製的一種,通俗來說就是通過多條互相沒有關係的通道傳輸不同的資訊。OFDM現在主要用於4G通訊上
Flink的Checkpoint和Savepoint介紹
第一部分:Flink的Checkpoint 1. Flink Checkpoint原理介紹 Checkpoint是Flink實現容錯機制最核心的功能,它能夠根據配置週期性地基於Stream中各個Operator的狀態來生成Snapshot,從而將這些狀態資料定期持久化儲存下來,當
Flink架構及其工作原理
目錄 System Architecture Data Transfer in Flink Event Time Processing State Management Checkpoints, Savepoints, and State Recovery System Arch
Lucene學習總結之一:全文檢索的基本原理
一、總論 Lucene是一個高效的,基於Java的全文檢索庫。 所以在瞭解Lucene之前要費一番工夫瞭解一下全文檢索。 那麼什麼叫做全文檢索呢?這要從我們生活中的資料說起。 我們生活中的資料總體分為兩種:結構化資料和非結構化資料。 結構化資料:指具
Lucene學習總結之一:全文檢索的基本原理(03-01
浪費了“黃金五年”的Java程式設計師,還有救嗎? >>>
貝葉斯算法的基本原理和算法實現
utf shape less 流程 我們 def .sh 詞向量 貝葉斯算法 一. 貝葉斯公式推導 樸素貝葉斯分類是一種十分簡單的分類算法,叫它樸素是因為其思想基礎的簡單性:就文本分類而言,它認為詞袋中的兩兩詞之間的關系是相互獨立的,即一個對象 的特征向量
個性化推薦系統原理介紹(基於內容過濾/協同過濾/關聯規則/序列模式)
信息 來講 行為記錄 鏈接 方程 機器學習 沒有 比較 graph 個性化推薦根據用戶興趣和行為特點,向用戶推薦所需的信息或商品,幫助用戶在海量信息中快速發現真正所需的商品,提高用戶黏性,促進信息點擊和商品銷售。推薦系統是基於海量數據挖掘分析的商業智能平臺,推薦主要基
JAVA語言開發基本原理
源文件 cli lips font 實現 環境 java字節碼 類庫 java開發工具 1.java編譯運行過程 java源文件(.java)經過編譯,編譯為java字節碼文件(.class),JVM來加載.class文件並運行.class文件。 2.JVM 不同系