
Oracle索引 詳解
一.索引介紹
1.1 索引的建立語法:
CREATE UNIUQE | BITMAP INDEX <schema>.<index_name>
ON <schema>.<table_name>
(<column_name> | <expression> ASC | DESC,
<column_name> | <expression> ASC | DESC,...)
TABLESPACE <tablespace_name>
STORAGE <storage_settings>
LOGGING | NOLOGGING
COMPUTE STATISTICS
NOCOMPRESS | COMPRESS<nn>
NOSORT | REVERSE
PARTITION | GLOBAL PARTITION<partition_setting>
相關說明
1) UNIQUE | BITMAP:指定UNIQUE為唯一值索引,BITMAP為點陣圖索引,省略為B-Tree索引。2)<column_name> | <expression> ASC | DESC:可以對多列進行聯合索引,當為expression時即“基於函式的索引”
3)TABLESPACE:指定存放索引的表空間(索引和原表不在一個表空間時效率更高)
4)STORAGE:可進一步設定表空間的儲存引數
5)LOGGING | NOLOGGING:是否對索引產生重做日誌(對大表儘量使用NOLOGGING來減少佔用空間並提高效率)
6)COMPUTE STATISTICS
7)NOCOMPRESS | COMPRESS<nn>:是否使用“鍵壓縮”(使用鍵壓縮可以刪除一個鍵列中出現的重複值)
8)NOSORT | REVERSE:NOSORT表示與表中相同的順序建立索引,REVERSE表示相反順序儲存索引值
9)PARTITION | NOPARTITION:可以在分割槽表和未分割槽表上對建立的索引進行分割槽
1.2 索引特點:
第一,通過建立唯一性索引,可以保證資料庫表中每一行資料的唯一性。
第二,可以大大加快資料的檢索速度,這也是建立索引的最主要的原因。
第三,可以加速表和表之間的連線,特別是在實現資料的參考完整性方面特別有意義。
第四,在使用分組和排序子句進行資料檢索時,同樣可以顯著減少查詢中分組和排序的時間。
第五,通過使用索引,可以在查詢的過程中,使用優化隱藏器,提高系統的效能。
1.3 索引不足:
第一,建立索引和維護索引要耗費時間,這種時間隨著資料量的增加而增加。
第二,索引需要佔物理空間,除了資料表佔資料空間之外,每一個索引還要佔一定的物理空間,如果要建立聚簇索引,那麼需要的空間就會更大。
第三,當對錶中的資料進行增加、刪除和修改的時候,索引也要動態的維護,這樣就降低了資料的維護速度。
1.4 應該建索引列的特點:
1)在經常需要搜尋的列上,可以加快搜索的速度;
2)在作為主鍵的列上,強制該列的唯一性和組織表中資料的排列結構;
3)在經常用在連線的列上,這些列主要是一些外來鍵,可以加快連線的速度;
4)在經常需要根據範圍進行搜尋的列上建立索引,因為索引已經排序,其指定的範圍是連續的;
5)在經常需要排序的列上建立索引,因為索引已經排序,這樣查詢可以利用索引的排序,加快排序查詢時間;
6)在經常使用在WHERE子句中的列上面建立索引,加快條件的判斷速度。
1.5 不應該建索引列的特點:
第一,對於那些在查詢中很少使用或者參考的列不應該建立索引。這是因為,既然這些列很少使用到,因此有索引或者無索引,並不能提高查詢速度。相反,由於增加了索引,反而降低了系統的維護速度和增大了空間需求。
第二,對於那些只有很少資料值的列也不應該增加索引。這是因為,由於這些列的取值很少,例如人事表的性別列,在查詢的結果中,結果集的資料行佔了表中資料行的很大比例,即需要在表中搜索的資料行的比例很大。增加索引,並不能明顯加快檢索速度。
第三,對於那些定義為blob資料型別的列不應該增加索引。這是因為,這些列的資料量要麼相當大,要麼取值很少。
第四,當修改效能遠遠大於檢索效能時,不應該建立索引。這是因為,修改效能和檢索效能是互相矛盾的。當增加索引時,會提高檢索效能,但是會降低修改效能。當減少索引時,會提高修改效能,降低檢索效能。因此,當修改效能遠遠大於檢索效能時,不應該建立索引。
1.6 限制索引
限制索引是一些沒有經驗的開發人員經常犯的錯誤之一。在SQL中有很多陷阱會使一些索引無法使用。下面討論一些常見的問題:
1.6.1 使用不等於操作符(<>、!=)
下面的查詢即使在cust_rating列有一個索引,查詢語句仍然執行一次全表掃描。
select cust_Id,cust_name from customers where cust_rating <> 'aa';
把上面的語句改成如下的查詢語句,這樣,在採用基於規則的優化器而不是基於代價的優化器(更智慧)時,將會使用索引。
select cust_Id,cust_name from customers where cust_rating < 'aa' or cust_rating > 'aa';
特別注意:通過把不等於操作符改成OR條件,就可以使用索引,以避免全表掃描。
1.6.2 使用IS NULL 或IS NOT NULL
使用IS NULL 或IS NOT NULL同樣會限制索引的使用。因為NULL值並沒有被定義。在SQL語句中使用NULL會有很多的麻煩。因此建議開發人員在建表時,把需要索引的列設成 NOT NULL。如果被索引的列在某些行中存在NULL值,就不會使用這個索引(除非索引是一個位圖索引,關於點陣圖索引在稍後在詳細討論)。
1.6.3 使用函式
如果不使用基於函式的索引,那麼在SQL語句的WHERE子句中對存在索引的列使用函式時,會使優化器忽略掉這些索引。 下面的查詢不會使用索引(只要它不是基於函式的索引)
select empno,ename,deptno from emp where trunc(hiredate)='01-MAY-81';
把上面的語句改成下面的語句,這樣就可以通過索引進行查詢。
select empno,ename,deptno from emp where hiredate<(to_date('01-MAY-81')+0.9999);
1.6.4 比較不匹配的資料型別
也是比較難於發現的效能問題之一。 注意下面查詢的例子,account_number是一個VARCHAR2型別,在account_number欄位上有索引。
下面的語句將執行全表掃描:
select bank_name,address,city,state,zip from banks where account_number = 990354;
Oracle可以自動把where子句變成to_number(account_number)=990354,這樣就限制了索引的使用,改成下面的查詢就可以使用索引:
select bank_name,address,city,state,zip from banks where account_number ='990354';
特別注意:不匹配的資料型別之間比較會讓Oracle自動限制索引的使用,即便對這個查詢執行Explain Plan也不能讓您明白為什麼做了一次“全表掃描”。
1.7 查詢索引
查詢DBA_INDEXES檢視可得到表中所有索引的列表,注意只能通過USER_INDEXES的方法來檢索模式(schema)的索引。訪問USER_IND_COLUMNS檢視可得到一個給定表中被索引的特定列。
1.8組合索引
當某個索引包含有多個已索引的列時,稱這個索引為組合(concatented)索引。在 Oracle9i引入跳躍式掃描的索引訪問方法之前,查詢只能在有限條件下使用該索引。比如:表emp有一個組合索引鍵,該索引包含了empno、 ename和deptno。在Oracle9i之前除非在where之句中對第一列(empno)指定一個值,否則就不能使用這個索引鍵進行一次範圍掃描。
特別注意:在Oracle9i之前,只有在使用到索引的前導索引時才可以使用組合索引!
1.9 ORACLE ROWID
通過每個行的ROWID,索引Oracle提供了訪問單行資料的能力。ROWID其實就是直接指向單獨行的線路圖。如果想檢查重複值或是其他對ROWID本身的引用,可以在任何表中使用和指定rowid列。
1.10 選擇性
使用USER_INDEXES檢視,該檢視中顯示了一個distinct_keys列。比較一下唯一鍵的數量和表中的行數,就可以判斷索引的選擇性。選擇性越高,索引返回的資料就越少。
1.11 群集因子(Clustering Factor)
Clustering Factor位於USER_INDEXES檢視中。該列反映了資料相對於已建索引的列是否顯得有序。如果Clustering Factor列的值接近於索引中的樹葉塊(leaf block)的數目,表中的資料就越有序。如果它的值接近於表中的行數,則表中的資料就不是很有序。
1.12 二元高度(Binary height)
索引的二元高度對把ROWID返回給使用者程序時所要求的I/O量起到關鍵作用。在對一個索引進行分析後,可以通過查詢DBA_INDEXES的B- level列檢視它的二元高度。二元高度主要隨著表的大小以及被索引的列中值的範圍的狹窄程度而變化。索引上如果有大量被刪除的行,它的二元高度也會增加。更新索引列也類似於刪除操作,因為它增加了已刪除鍵的數目。重建索引可能會降低二元高度。
1.13 快速全域性掃描
從Oracle7.3後就可以使用快速全域性掃描(Fast Full Scan)這個選項。這個選項允許Oracle執行一個全域性索引掃描操作。快速全域性掃描讀取B-樹索引上所有樹葉塊。初始化檔案中的 DB_FILE_MULTIBLOCK_READ_COUNT引數可以控制同時被讀取的塊的數目。
1.14 跳躍式掃描
從Oracle9i開始,索引跳躍式掃描特性可以允許優化器使用組合索引,即便索引的前導列沒有出現在WHERE子句中。索引跳躍式掃描比全索引掃描要快的多。
下面的比較他們的區別:
SQL> set timing on
SQL> create index TT_index on TT(teamid,areacode);
索引已建立。
已用時間: 00: 02: 03.93
SQL> select count(areacode) from tt;
COUNT(AREACODE)
---------------
7230369
已用時間: 00: 00: 08.31
SQL> select /*+ index(tt TT_index )*/ count(areacode) from tt;
COUNT(AREACODE)
---------------
7230369
已用時間: 00: 00: 07.37
1.15 索引的型別
B-樹索引 點陣圖索引 HASH索引 索引編排表
反轉鍵索引 基於函式的索引 分割槽索引 本地和全域性索引
二. 索引分類
Oracle提供了大量索引選項。知道在給定條件下使用哪個選項對於一個應用程式的效能來說非常重要。一個錯誤的選擇可能會引發死鎖,並導致資料庫效能急劇下降或程序終止。而如果做出正確的選擇,則可以合理使用資源,使那些已經運行了幾個小時甚至幾天的程序在幾分鐘得以完成,這樣會使您立刻成為一位英雄。下面就將簡單的討論每個索引選項。
下面討論的索引型別:
B樹索引(預設型別)
點陣圖索引
HASH索引
索引組織表索引
反轉鍵(reverse key)索引
基於函式的索引
分割槽索引(本地和全域性索引)
點陣圖連線索引
2.1 B樹索引(預設型別)
B樹索引在Oracle中是一個通用索引。在建立索引時它就是預設的索引型別。B樹索引可以是一個列的(簡單)索引,也可以是組合/複合(多個列)的索引。B樹索引最多可以包括32列。
在下圖的例子中,B樹索引位於僱員表的last_name列上。這個索引的二元高度為3;接下來,Oracle會穿過兩個樹枝塊(branch block),到達包含有ROWID的樹葉塊。在每個樹枝塊中,樹枝行包含鏈中下一個塊的ID號。
樹葉塊包含了索引值、ROWID,以及指向前一個和後一個樹葉塊的指標。Oracle可以從兩個方向遍歷這個二叉樹。B樹索引儲存了在索引列上有值的每個資料行的ROWID值。Oracle不會對索引列上包含NULL值的行進行索引。如果索引是多個列的組合索引,而其中列上包含NULL值,這一行就會處於包含NULL值的索引列中,且將被處理為空(視為NULL)。
技巧:索引列的值都儲存在索引中。因此,可以建立一個組合(複合)索引,這些索引可以直接滿足查詢,而不用訪問表。這就不用從表中檢索資料,從而減少了I/O量。
B-tree 特點:
適合與大量的增、刪、改(OLTP)
不能用包含OR操作符的查詢;
適合高基數的列(唯一值多)
典型的樹狀結構;
每個結點都是資料塊;
大多都是物理上一層、兩層或三層不定,邏輯上三層;
葉子塊資料是排序的,從左向右遞增;
在分支塊和根塊中放的是索引的範圍;
2.2 點陣圖索引
點陣圖索引非常適合於決策支援系統(Decision Support System,DSS)和資料倉庫,它們不應該用於通過事務處理應用程式訪問的表。它們可以使用較少到中等基數(不同值的數量)的列訪問非常大的表。儘管點陣圖索引最多可達30個列,但通常它們都只用於少量的列。
例如,您的表可能包含一個稱為Sex的列,它有兩個可能值:男和女。這個基數只為2,如果使用者頻繁地根據Sex列的值查詢該表,這就是點陣圖索引的基列。當一個表內包含了多個位圖索引時,您可以體會到點陣圖索引的真正威力。如果有多個可用的點陣圖索引,Oracle就可以合併從每個點陣圖索引得到的結果集,快速刪除不必要的資料。
Bitmapt 特點:
適合與決策支援系統;
做UPDATE代價非常高;
非常適合OR操作符的查詢;
基數比較少的時候才能建點陣圖索引;
技巧:對於有較低基數的列需要使用點陣圖索引。性別列就是這樣一個例子,它有兩個可能值:男或女(基數僅為2)。點陣圖對於低基數(少量的不同值)列來說非常快,這是因為索引的尺寸相對於B樹索引來說小了很多。因為這些索引是低基數的B樹索引,所以非常小,因此您可以經常檢索表中超過半數的行,並且仍使用點陣圖索引。
當大多數條目不會向點陣圖新增新的值時,點陣圖索引在批處理(單使用者)操作中載入表(插入操作)方面通常要比B樹做得好。當多個會話同時向表中插入行時不應該使用點陣圖索引,在大多數事務處理應用程式中都會發生這種情況。
示例
下面來看一個示例表PARTICIPANT,該表包含了來自個人的調查資料。列Age_Code、Income_Level、Education_Level和Marital_Status都包括了各自的點陣圖索引。下圖顯示了每個直方圖中的資料平衡情況,以及對訪問每個點陣圖索引的查詢的執行路徑。圖中的執行路徑顯示了有多少個位圖索引被合併,可以看出效能得到了顯著的提高。
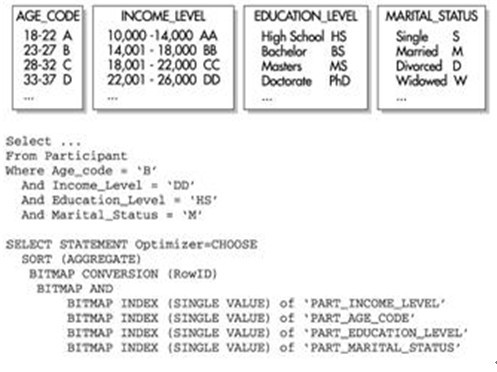
如上圖圖所示,優化器依次使用4個單獨的點陣圖索引,這些索引的列在WHERE子句中被引用。每個點陣圖記錄指標(例如0或1),用於指示表中的哪些行包含點陣圖中的已知值。有了這些資訊後,Oracle就執行BITMAP AND操作以查詢將從所有4個位圖中返回哪些行。該值然後被轉換為ROWID值,並且查詢繼續完成剩餘的處理工作。注意,所有4個列都有非常低的基數,使用索引可以非常快速地返回匹配的行。
技巧:在一個查詢中合併多個位圖索引後,可以使效能顯著提高。點陣圖索引使用固定長度的資料型別要比可變長度的資料型別好。較大尺寸的塊也會提高對點陣圖索引的儲存和讀取效能。
下面的查詢可顯示索引型別。
SQL> select index_name, index_type from user_indexes;
INDEX_NAME INDEX_TYPE
------------------------------ ----------------------
TT_INDEX NORMAL
IX_CUSTADDR_TP NORMAL
B樹索引作為NORMAL列出;而點陣圖索引的型別值為BITMAP。
技巧:如果要查詢點陣圖索引列表,可以在USER _INDEXES檢視中查詢index_type列。
建議不要在一些聯機事務處理(OLTP)應用程式中使用點陣圖索引。B樹索引的索引值中包含ROWID,這樣Oracle就可以在行級別上鎖定索引。點陣圖索引儲存為壓縮的索引值,其中包含了一定範圍的ROWID,因此Oracle必須針對一個給定值鎖定所有範圍內的ROWID。這種鎖定型別可能在某些DML語句中造成死鎖。SELECT語句不會受到這種鎖定問題的影響。
點陣圖索引的使用限制:
基於規則的優化器不會考慮點陣圖索引。
當執行ALTER TABLE語句並修改包含有點陣圖索引的列時,會使點陣圖索引失效。
點陣圖索引不包含任何列資料,並且不能用於任何型別的完整性檢查。
點陣圖索引不能被宣告為唯一索引。
點陣圖索引的最大長度為30。
技巧:不要在繁重的OLTP環境中使用點陣圖索引
2.3 HASH索引
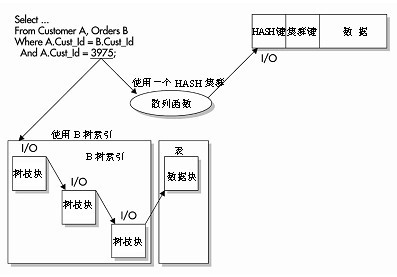
使用HASH索引必須要使用HASH叢集。建立一個叢集或HASH叢集的同時,也就定義了一個叢集鍵。這個鍵告訴Oracle如何在叢集上儲存表。在儲存資料時,所有與這個叢集鍵相關的行都被儲存在一個數據庫塊上。如果資料都儲存在同一個資料庫塊上,並且將HASH索引作為WHERE子句中的確切匹配,Oracle就可以通過執行一個HASH函式和I/O來訪問資料——而通過使用一個二元高度為4的B樹索引來訪問資料,則需要在檢索資料時使用4個I/O。如下圖所示,其中的查詢是一個等價查詢,用於匹配HASH列和確切的值。Oracle可以快速使用該值,基於HASH函式確定行的物理儲存位置。
HASH索引可能是訪問資料庫中資料的最快方法,但它也有自身的缺點。叢集鍵上不同值的數目必須在建立HASH叢集之前就要知道。需要在建立HASH叢集的時候指定這個值。低估了叢集鍵的不同值的數字可能會造成叢集的衝突(兩個叢集的鍵值擁有相同的HASH值)。這種衝突是非常消耗資源的。衝突會造成用來儲存額外行的緩衝溢位,然後造成額外的I/O。如果不同HASH值的數目已經被低估,您就必須在重建這個叢集之後改變這個值。
ALTER CLUSTER命令不能改變HASH鍵的數目。HASH叢集還可能浪費空間。如果無法確定需要多少空間來維護某個叢集鍵上的所有行,就可能造成空間的浪費。如果不能為叢集的未來增長分配好附加的空間,HASH叢集可能就不是最好的選擇。如果應用程式經常在叢集表上進行全表掃描,HASH叢集可能也不是最好的選擇。由於需要為未來的增長分配好叢集的剩餘空間量,全表掃描可能非常消耗資源。
在實現HASH叢集之前一定要小心。您需要全面地觀察應用程式,保證在實現這個選項之前已經瞭解關於表和資料的大量資訊。通常,HASH對於一些包含有序值的靜態資料非常有效。
技巧:HASH索引在有限制條件(需要指定一個確定的值而不是一個值範圍)的情況下非常有用。
2.4 索引組織表
索引組織表會把表的儲存結構改成B樹結構,以表的主鍵進行排序。這種特殊的表和其他型別的表一樣,可以在表上執行所有的DML和DDL語句。由於表的特殊結構,ROWID並沒有被關聯到表的行上。對於一些涉及精確匹配和範圍搜尋的語句,索引組織表提供了一種基於鍵的快速資料訪問機制。基於主鍵值的UPDATE和DELETE語句的效能也同樣得以提高,這是因為行在物理上有序。由於鍵列的值在表和索引中都沒有重複,儲存所需要的空間也隨之減少。
如果不會頻繁地根據主鍵列查詢資料,則需要在索引組織表中的其他列上建立二級索引。不會頻繁根據主鍵查詢表的應用程式不會了解到使用索引組織表的全部優點。對於總是通過對主鍵的精確匹配或範圍掃描進行訪問的表,就需要考慮使用索引組織表。
技巧:可以在索引組織表上建立二級索引。
2.5 反轉鍵索引
當載入一些有序資料時,索引肯定會碰到與I/O相關的一些瓶頸。在資料載入期間,某部分索引和磁碟肯定會比其他部分使用頻繁得多。為了解決這個問題,可以把索引表空間存放在能夠把檔案物理分割在多個磁碟上的磁碟體系結構上。
為了解決這個問題,Oracle還提供了一種反轉鍵索引的方法。如果資料以反轉鍵索引儲存,這些資料的值就會與原先儲存的數值相反。這樣,資料1234、1235和1236就被儲存成4321、5321和6321。結果就是索引會為每次新插入的行更新不同的索引塊。
技巧:如果您的磁碟容量有限,同時還要執行大量的有序載入,就可以使用反轉鍵索引。
不可以將反轉鍵索引與點陣圖索引或索引組織表結合使用。因為不能對點陣圖索引和索引組織表進行反轉鍵處理。
2.6 基於函式的索引
可以在表中建立基於函式的索引。如果沒有基於函式的索引,任何在列上執行了函式的查詢都不能使用這個列的索引。例如,下面的查詢就不能使用JOB列上的索引,除非它是基於函式的索引:
select * from emp where UPPER(job) = 'MGR';
下面的查詢使用JOB列上的索引,但是它將不會返回JOB列具有Mgr或mgr值的行:
select * from emp where job = 'MGR';
可以建立這樣的索引,允許索引訪問支援基於函式的列或資料。可以對列表達式UPPER(job)建立索引,而不是直接在JOB列上建立索引,如:
create index EMP$UPPER_JOB on emp(UPPER(job));
儘管基於函式的索引非常有用,但在建立它們之前必須先考慮下面一些問題:
能限制在這個列上使用的函式嗎?如果能,能限制所有在這個列上執行的所有函式嗎
是否有足夠應付額外索引的儲存空間?
在每列上增加的索引數量會對針對該表執行的DML語句的效能帶來何種影響?
基於函式的索引非常有用,但在實現時必須小心。在表上建立的索引越多,INSERT、UPDATE和DELETE語句的執行就會花費越多的時間。
注意:對於優化器所使用的基於函式的索引來說,必須把初始引數QUERY _REWRITE _ ENABLED設定為TRUE。
示例:
select count(*) from sample where ratio(balance,limit) >.5;
Elapsed time: 20.1 minutes
create index ratio_idx1 on sample (ratio(balance, limit));
select count(*) from sample where ratio(balance,limit) >.5;
Elapsed time: 7 seconds!!!
2.7 分割槽索引
分割槽索引就是簡單地把一個索引分成多個片斷。通過把一個索引分成多個片斷,可以訪問更小的片斷(也更快),並且可以把這些片斷分別存放在不同的磁碟驅動器上(避免I/O問題)。B樹和點陣圖索引都可以被分割槽,而HASH索引不可以被分割槽。可以有好幾種分割槽方法:表被分割槽而索引未被分割槽;表未被分割槽而索引被分割槽;表和索引都被分割槽。不管採用哪種方法,都必須使用基於成本的優化器。分割槽能夠提供更多可以提高效能和可維護性的可能性
有兩種型別的分割槽索引:本地分割槽索引和全域性分割槽索引。每個型別都有兩個子型別,有字首索引和無字首索引。表各列上的索引可以有各種型別索引的組合。如果使用了點陣圖索引,就必須是本地索引。把索引分割槽最主要的原因是可以減少所需讀取的索引的大小,另外把分割槽放在不同的表空間中可以提高分割槽的可用性和可靠性。
在使用分割槽後的表和索引時,Oracle還支援並行查詢和並行DML。這樣就可以同時執行多個程序,從而加快處理這條語句。
2.7.1.本地分割槽索引(通常使用的索引)可以使用與表相同的分割槽鍵和範圍界限來對本地索引分割槽。每個本地索引的分割槽只包含了它所關聯的表分割槽的鍵和ROWID。本地索引可以是B樹或點陣圖索引。如果是B樹索引,它可以是唯一或不唯一的索引。
這種型別的索引支援分割槽獨立性,這就意味著對於單獨的分割槽,可以進行增加、擷取、刪除、分割、離線等處理,而不用同時刪除或重建索引。Oracle自動維護這些本地索引。本地索引分割槽還可以被單獨重建,而其他分割槽不會受到影響。
2.7.1.1 有字首的索引
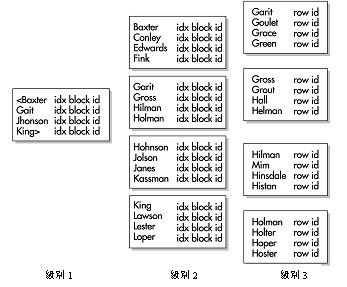
有字首的索引包含了來自分割槽鍵的鍵,並把它們作為索引的前導。例如,讓我們再次回顧participant表。在建立該表後,使用survey_id和survey_date這兩個列進行範圍分割槽,然後在survey_id列上建立一個有字首的本地索引,如下圖所示。這個索引的所有分割槽都被等價劃分,就是說索引的分割槽都使用表的相同範圍界限來建立。
技巧:本地的有字首索引可以讓Oracle快速剔除一些不必要的分割槽。也就是說沒有包含WHERE條件子句中任何值的分割槽將不會被訪問,這樣也提高了語句的效能。
2.7.1.2 無字首的索引
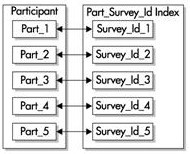
無字首的索引並沒有把分割槽鍵的前導列作為索引的前導列。若使用有同樣分割槽鍵(survey_id和survey_date)的相同分割槽表,建立在survey_date列上的索引就是一個本地的無字首索引,如下圖所示。可以在表的任一列上建立本地無字首索引,但索引的每個分割槽只包含表的相應分割槽的鍵值。
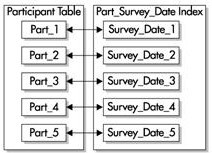
如果要把無字首的索引設為唯一索引,這個索引就必須包含分割槽鍵的子集。在這個例子中,我們必須把包含survey和(或)survey_id的列進行組合(只要survey_id不是索引的第一列,它就是一個有字首的索引)。
技巧:對於一個唯一的無字首索引,它必須包含分割槽鍵的子集。
2.7.2.全域性分割槽索引
全域性分割槽索引在一個索引分割槽中包含來自多個表分割槽的鍵。一個全域性分割槽索引的分割槽鍵是分割槽表中不同的或指定一個範圍的值。在建立全域性分割槽索引時,必須定義分割槽鍵的範圍和值。全域性索引只能是B樹索引。Oracle在預設情況下不會維護全域性分割槽索引。如果一個分割槽被擷取、增加、分割、刪除等,就必須重建全域性分割槽索引,除非在修改表時指定ALTER TABLE命令的UPDATE GLOBAL INDEXES子句。
2.7.2.1 有字首的索引
通常,全域性有字首索引在底層表中沒有經過對等分割槽。沒有什麼因素能限制索引的對等分割槽,但Oracle在生成查詢計劃或執行分割槽維護操作時,並不會充分利用對等分割槽。如果索引被對等分割槽,就必須把它建立為一個本地索引,這樣Oracle可以維護這個索引,並使用它來刪除不必要的分割槽,如下圖所示。在該圖的3個索引分割槽中,每個分割槽都包含指向多個表分割槽中行的索引條目。
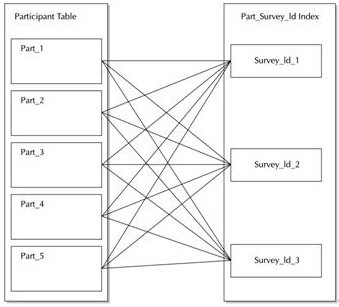
分割槽的、全域性有字首索引
技巧:如果一個全域性索引將被對等分割槽,就必須把它建立為一個本地索引,這樣Oracle可以維護這個索引,並使用它來刪除不必要的分割槽。
2.7.2.2 無字首的索引
Oracle不支援無字首的全域性索引。
2.8 點陣圖連線索引
點陣圖連線索引是基於兩個表的連線的點陣圖索引,在資料倉庫環境中使用這種索引改進連線維度表和事實表的查詢的效能。建立點陣圖連線索引時,標準方法是連線索引中常用的維度表和事實表。當用戶在一次查詢中結合查詢事實表和維度表時,就不需要執行連線,因為在點陣圖連線索引中已經有可用的連線結果。通過壓縮點陣圖連線索引中的ROWID進一步改進效能,並且減少訪問資料所需的I/O數量。
建立點陣圖連線索引時,指定涉及的兩個表。相應的語法應該遵循如下模式:
create bitmap index FACT_DIM_COL_IDX on FACT(DIM.Descr_Col) from FACT, DIM
where FACT.JoinCol = DIM.JoinCol;
點陣圖連線的語法比較特別,其中包含FROM子句和WHERE子句,並且引用兩個單獨的表。索引列通常是維度表中的描述列——就是說,如果維度是CUSTOMER,並且它的主鍵是CUSTOMER_ID,則通常索引Customer_Name這樣的列。如果事實表名為SALES,可以使用如下的命令建立索引:
create bitmap index SALES_CUST_NAME_IDX
on SALES(CUSTOMER.Customer_Name) from SALES, CUSTOMER
where SALES.Customer_ID=CUSTOMER.Customer_ID;
如果使用者接下來使用指定Customer_Name列值的WHERE子句查詢SALES和CUSTOMER表,優化器就可以使用點陣圖連線索引快速返回匹配連線條件和Customer_Name條件的行。
點陣圖連線索引的使用一般會受到限制:
1)只可以索引維度表中的列。
2)用於連線的列必須是維度表中的主鍵或唯一約束;如果是複合主鍵,則必須使用連線中的每一列。
3)不可以對索引組織表建立點陣圖連線索引,並且適用於常規點陣圖索引的限制也適用於點陣圖連線索引。
注: 本文整理自《Oracle Database 10g 效能調整與優化》
相關推薦
Oracle索引詳解
png 匹配 時間 相同 空間 表示 單列 設置 ogg Oracle索引詳解(一) ### --索引介紹 ??索引對於Oracle學習來說,非常重要,在數據量巨大的狀況下,使用恰到好處的索引,將會使得數據查詢時間大大減少,於2017/12/25暫時對Oracle中的索引進
Oracle索引 詳解
一.索引介紹 1.1 索引的建立語法: CREATE UNIUQE | BITMAP INDEX <schema>.<index_name> ON <schema>.<table_name>
ORACLE分割槽表、分割槽索引詳解
ORACLE分割槽表、分割槽索引ORACLE對於分割槽表方式其實就是將表分段儲存,一般普通表格是一個段儲存,而分割槽表會分成多個段,所以查詢資料過程都是先定位根據查詢條件定位分割槽範圍,即資料在那個分割槽或那幾個內部,然後在分割槽內部去查詢資料,一個分割槽一般保證四十多萬條
ORACLE重建索引詳解
一、重建索引的前提 1、表上頻繁發生update,delete操作; 2、表上發生了alter table ..move操作(move操作導致了rowid變化)。 二、重建索引的標準 1、索引重建是否有必要,一般看索引是否傾斜的嚴重,是否浪費了空間, 那應該如何
oracle序列詳解
pan 知識庫 引用 dpt 默認 數據 指定 sta ima 序列: 是oacle提供的用於產生一系列唯一數字的數據庫對象。 l 自動提供唯一的數值 l 共享對象 l 主要用於提供主鍵值 l 將序列值裝入內存可以提高訪問效率 創建序列: 1、 要有創建序列的權限
【Oracle】詳解Oracle中NLS_LANG變量的使用
make fault tro territory font pin onclick 添加 其中 目錄結構: // contents structure [-] 關於NLS_LANG參數 NSL_LANG常用的值 在MS-DOS模式和Batch模式中
mysql 索引詳解
mysqlmysql 索引詳解
ORACLE觸發器詳解
etc 遊標 target with get ger 獨立 erer mon 作者:indexman 觸發器是許多關系數據庫系統都提供的一項技術。在oracle系統裏,觸發器類似過程和函數,都有聲明,執行和異常處理過程的PL/SQL塊。 8.1 觸發器類型 觸
MySQL之索引詳解
分布 i/o .cn 能夠 b+ images 電路 普通 磁道 這篇博客將要闡述為什麽使用b+樹作為索引,而不是b樹或者其他樹 1.什麽是b樹
Cassandra索引詳解
頻繁 什麽是 參考 根據 就是 token 3.1 primary create 轉自: https://www.cnblogs.com/bonelee/p/6278943.html 1.什麽是二級索引? 我們前面已經介紹過Cassandra之中有各種Key,比如Prima
搜索引擎系列五:Lucene索引詳解(IndexWriter詳解、Document詳解、索引更新)
let integer 自己 textfield app tdi AS query rect 一、IndexWriter詳解 問題1:索引創建過程完成什麽事? 分詞、存儲到反向索引中 1. 回顧Lucene架構圖: 介紹我們編寫的應用程序要完成數據的收集,再將數據
BTree和B+Tree和Hash索引詳解
b-tree 關系 查詢優化 刪除節點 eight node 常用 技術分享 遍歷 二叉查找樹 二叉樹具有以下性質:左子樹的鍵值小於根的鍵值,右子樹的鍵值大於根的鍵值。 如下圖所示就是一棵二叉查找樹, 對該二叉樹的節點進行查找發現深度為1的節點的查找次數為1,深度為2的查
elasticsearch系列三:索引詳解(分詞器、文檔管理、路由詳解)
ces com dex 合並 pda ams 最新 case dbi 一、分詞器 1. 認識分詞器 1.1 Analyzer 分析器 在ES中一個Analyzer 由下面三種組件組合而成: character filter :字符過濾器,對文本進行字符過濾處理,
PLSQL Developer連線遠端Oracle配置詳解
一、安裝Instant Client 1. 下載Instant Client(輕量級的客戶端),作為本地Oracle環境 。 https://download.csdn.net/download/qq_40110871/10747501 2.
mysql索引詳解
保存數據 關系 銀行卡號 訪問 問題 客戶 數據讀取 col 幫助 索引的定義 MySQL官方對索引的定義為:索引(Index)是幫助MySQL高效獲取數據的數據結構.可以得出索引的本質就是數據結構 你可以簡單理解為"排序好的快速查找數據結構" 在數據之外,數據
MySQL:索引詳解
轉1:https://www.2cto.com/database/201611/562165.html 轉2:https://www.cnblogs.com/lihuiyong/p/5623191.html 轉3:http://www.cnblogs.com/chenshishuo/p/
java程式設計師菜鳥進階(五)oracle基礎詳解(五)oracle資料庫體系架構詳解
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
MySQL的執行計劃和索引詳解
使用explain關鍵字可以模擬優化器執行sql語句,從而知道mysql是如何處理sql語句的,分析你的查詢語句或者是結構效能。 我們通過幾張表來使用explain的例子: 在select語句之前增加explain關鍵字,MySQL會在查詢的基礎上設定一個標記,執行查詢時,會返回執行計劃的資
Btree索引詳解
Btree索引(或Balanced Tree),是一種很普遍的資料庫索引結構,oracle預設的索引型別(本文也主要依據oracle來講)。其特點是定位高效、利用率高、自我平衡,特別適用於高基數字段,定位單條或小範圍資料非常高效。理論上,使用Btree在億條資料與100條資料中定位記錄的花銷相同。
Oracle約束詳解
一 約束的定義 約束是強加在表上的規則或條件。確保資料庫滿足業務規則。保證資料的完整性。當對錶進行DML或DDL操作時,如果此操作會造成表中的資料違反約束條件或規則的話,系統就會拒絕執行這個操作。約束可以是列一級別的 也可以是表級別的。定義約束時沒有給出約束的名字,OR