
Hadoop學習筆記—3.Hadoop RPC機制的使用
一、RPC基礎概念
1.1 RPC的基礎概念
RPC,即Remote Procdure Call,中文名:遠端過程呼叫;
(1)它允許一臺計算機程式遠端呼叫另外一臺計算機的子程式,而不用去關心底層的網路通訊細節,對我們來說是透明的。因此,它經常用於分散式網路通訊中。
RPC協議假定某些傳輸協議的存在,如TCP或UDP,為通訊程式之間攜帶資訊資料。在OSI網路通訊模型中,RPC跨越了傳輸層和應用層。RPC使得開發包括網路分散式多程式在內的應用程式更加容易。
(2)Hadoop的程序間互動都是通過RPC來進行的,比如Namenode與Datanode直接,Jobtracker與Tasktracker之間等。

因此,可以說:Hadoop的執行就是建立在RPC基礎之上的。
1.2 RPC的顯著特點
(1)透明性:遠端呼叫其他機器上的程式,對使用者來說就像是呼叫本地方法一樣;
(2)高效能:RPC Server能夠併發處理多個來自Client的請求;
(3)可控性:jdk中已經提供了一個RPC框架—RMI,但是該PRC框架過於重量級並且可控之處比較少,所以Hadoop RPC實現了自定義的PRC框架。
1.3 RPC的基本流程
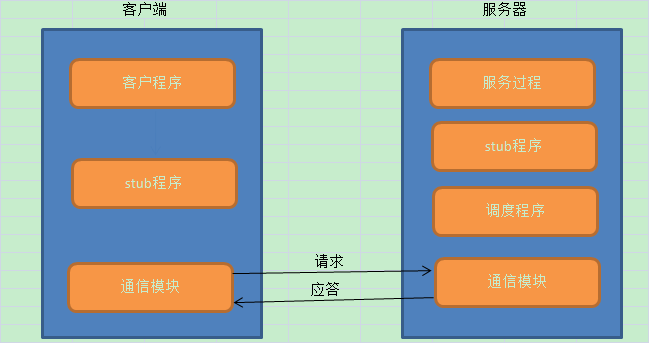
(1)RPC採用了C/S的模式;
(2)Client端傳送一個帶有引數的請求資訊到Server;
(3)Server接收到這個請求以後,根據傳送過來的引數呼叫相應的程式,然後把自己計算好的結果傳送給Client端;
(4)Client端接收到結果後繼續執行;
1.4 Hadoop中的RPC機制
同其他RPC框架一樣,Hadoop RPC分為四個部分:
(1)序列化層:Clent與Server端通訊傳遞的資訊採用了Hadoop裡提供的序列化類或自定義的Writable型別;
(2)函式呼叫層:Hadoop RPC通過動態代理以及java反射實現函式呼叫;
(3)網路傳輸層:Hadoop RPC採用了基於TCP/IP的socket機制;
(4)伺服器端框架層:RPC Server利用java NIO以及採用了事件驅動的I/O模型,提高RPC Server的併發處理能力;
Hadoop RPC在整個Hadoop中應用非常廣泛

1.5 Hadoop RPC設計技術
(1)動態代理
About:動態代理可以提供對另一個物件的訪問,同時隱藏實際物件的具體事實,代理物件對客戶隱藏了實際物件。目前Java開發包中提供了對動態代理的支援,但現在只支援對介面的實現。
(2)反射——動態載入類
(3)序列化
(4)非阻塞的非同步IO(NIO)
二、如何使用RPC
2.1 Hadoop RPC對外提供的介面
Hadoop RPC對外主要提供了兩種介面(見類org.apache.hadoop.ipc.RPC),分別是:
(1)public static <T> ProtocolProxy <T> getProxy/waitForProxy(…)
構造一個客戶端代理物件(該物件實現了某個協議),用於向伺服器傳送RPC請求。
(2)public static Server RPC.Builder (Configuration).build()
為某個協議(實際上是Java介面)例項構造一個伺服器物件,用於處理客戶端傳送的請求。
2.2 使用Hadoop RPC的四大步湊
(1)定義RPC協議
RPC協議是客戶端和伺服器端之間的通訊介面,它定義了伺服器端對外提供的服務介面。
(2)實現RPC協議
Hadoop RPC協議通常是一個Java介面,使用者需要實現該介面。
(3)構造和啟動RPC SERVER
直接使用靜態類Builder構造一個RPC Server,並呼叫函式start()啟動該Server。
(4)構造RPC Client併發送請求
使用靜態方法getProxy構造客戶端代理物件,直接通過代理物件呼叫遠端端的方法。
三、RPC應用例項
3.1 定義RPC協議
如下所示,我們定義一個IProxyProtocol 通訊介面,聲明瞭一個Add()方法。
public interface IProxyProtocol extends VersionedProtocol { static final long VERSION = 23234L; //版本號,預設情況下,不同版本號的RPC Client和Server之間不能相互通訊 int Add(int number1,int number2); }
需要注意的是:
(1)Hadoop中所有自定義RPC介面都需要繼承VersionedProtocol介面,它描述了協議的版本資訊。
(2)預設情況下,不同版本號的RPC Client和Server之間不能相互通訊,因此客戶端和服務端通過版本號標識。
3.2 實現RPC協議
Hadoop RPC協議通常是一個Java介面,使用者需要實現該介面。對IProxyProtocol介面進行簡單的實現如下所示:
public class MyProxy implements IProxyProtocol { public int Add(int number1,int number2) { System.out.println("我被呼叫了!"); int result = number1+number2; return result; } public long getProtocolVersion(String protocol, long clientVersion) throws IOException { System.out.println("MyProxy.ProtocolVersion=" + IProxyProtocol.VERSION); // 注意:這裡返回的版本號與客戶端提供的版本號需保持一致 return IProxyProtocol.VERSION; } }
這裡實現的Add方法很簡單,就是一個加法操作。為了檢視效果,這裡通過控制檯輸出一句:“我被呼叫了!”
3.3 構造RPC Server並啟動服務
這裡通過RPC的靜態方法getServer來獲得Server物件,如下程式碼所示:
public class MyServer { public static int PORT = 5432; public static String IPAddress = "127.0.0.1"; public static void main(String[] args) throws Exception { MyProxy proxy = new MyProxy(); final Server server = RPC.getServer(proxy, IPAddress, PORT, new Configuration()); server.start(); } }
這段程式碼的核心在於第5行的RPC.getServer方法,該方法有四個引數,第一個引數是被呼叫的java物件,第二個引數是伺服器的地址,第三個引數是伺服器的埠 。獲得伺服器物件後,啟動伺服器。這樣,伺服器就在指定埠監聽客戶端的請求。到此為止,伺服器就處於監聽狀態,不停地等待客戶端請求到達。
3.4 構造RPC Client併發出請求
這裡使用靜態方法getProxy或waitForProxy構造客戶端代理物件,直接通過代理物件呼叫遠端端的方法,具體如下所示:
public class MyClient { public static void main(String[] args) { InetSocketAddress inetSocketAddress = new InetSocketAddress( MyServer.IPAddress, MyServer.PORT); try { // 注意:這裡傳入的版本號需要與代理保持一致 IProxyProtocol proxy = (IProxyProtocol) RPC.waitForProxy( IProxyProtocol.class, IProxyProtocol.VERSION, inetSocketAddress, new Configuration()); int result = proxy.Add(10, 25); System.out.println("10+25=" + result); RPC.stopProxy(proxy); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
以上程式碼中核心在於RPC.waitForProxy(),該方法有四個引數,第一個引數是被呼叫的介面類,第二個是客戶端版本號,第三個是服務端地址。返回的代理物件,就是服務端物件的代理,內部就是使用java.lang.Proxy實現的。
經過以上四步,我們便利用Hadoop RPC搭建了一個非常高效的客戶機–伺服器網路模型。
3.5 檢視執行結果
(1)啟動服務端,開始監聽客戶端請求
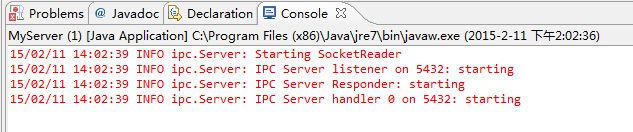
(2)啟動客戶端,開始向服務端發請求
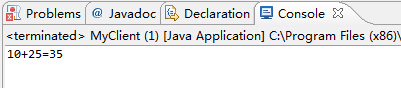
(3)檢視服務端狀態,是否被呼叫

SUMMARY:從上面的RPC呼叫中,可以看出:在客戶端呼叫的業務類的方法是定義在業務類的介面中的。該介面實現了VersionedProtocal介面。
(4)現在我們在命令列執行jps命令,檢視輸出資訊,會出現如下圖所示的:
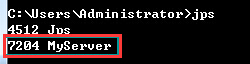
從上圖中可以看到一個java程序,是“MyServer”,該程序正是我們剛剛執行的RPC的服務端類MyServer。因此,大家可以聯想到我們搭建Hadoop環境時,也執行過該命令用來判斷Hadoop的相關程序是否全部啟動。
SUMMARY:那麼可以判斷,Hadoop啟動時產生的5個java程序也應該是RPC的服務端。
下面我們觀察NameNode的原始碼,如下圖所示,可以看到NameNode確實建立了RPC的服務端。
private void initialize(Configuration conf) throws IOException { ...... // create rpc server InetSocketAddress dnSocketAddr = getServiceRpcServerAddress(conf); if (dnSocketAddr != null) { int serviceHandlerCount = conf.getInt(DFSConfigKeys.DFS_NAMENODE_SERVICE_HANDLER_COUNT_KEY, DFSConfigKeys.DFS_NAMENODE_SERVICE_HANDLER_COUNT_DEFAULT); this.serviceRpcServer = RPC.getServer(this, dnSocketAddr.getHostName(), dnSocketAddr.getPort(), serviceHandlerCount, false, conf, namesystem.getDelegationTokenSecretManager()); this.serviceRPCAddress = this.serviceRpcServer.getListenerAddress(); setRpcServiceServerAddress(conf); } this.server = RPC.getServer(this, socAddr.getHostName(), socAddr.getPort(), handlerCount, false, conf, namesystem .getDelegationTokenSecretManager()); ...... }
參考資料
作者:周旭龍
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連結。
相關推薦
Hadoop學習筆記—3.Hadoop RPC機制的使用
一、RPC基礎概念 1.1 RPC的基礎概念 RPC,即Remote Procdure Call,中文名:遠端過程呼叫; (1)它允許一臺計算機程式遠端呼叫另外一臺計算機的子程式,而不用去關心底層的網路通訊細節,對我們來說是透明的。因此,它經常用於分散式網路通訊中。 RPC協議假定某些傳輸
Day5.Hadoop學習筆記3(偏向於實戰)
零、回顧 小Tips Google發表的一系列文章:GoogleFileSystem、MapReduce、BigTables、Spanner BigTables是Google設計的分散式資料儲存系統,用來處理海量的資料的一種非關係型的資料庫。
零基礎大資料HADOOP學習-筆記3-HDFS特點
HDFS的特點 優點: 1)處理超大檔案 這裡的超大檔案通常是指百MB、數百TB大小的檔案。目前在實際應用中, HDFS已經能用來儲存管理PB級的資料了。
零基礎大資料HADOOP學習-筆記3-安全模式 safemode
【安全模式 safemode】 3種方式 方式一:Namenode的一種狀態,啟動時會自動進入安全模式,在安全模式,檔案系統不 允許有任何修改,“只讀不寫”。目的,是在系統啟動時檢查各個DataNod
hadoop學習筆記2---hadoop的三種運行模式
hadoop1、單機模式安裝簡單,在一臺機器上運行服務,幾乎不用做任何配置,但僅限於調試用途。沒有分布式文件系統,直接讀寫本地操作系統的文件系統。2、偽分布式模式在單節點上同時啟動namenode、datanode、jobtracker、tasktracker、secondary namenode等進程,模擬
hadoop學習筆記1---Hadoop體系介紹
hadoop1、NamenodeHDFS的守護進程記錄文件時如何分割成數據塊的,以及這些數據塊被存儲到哪些節點上對內存和I/O進行集中管理是個單點,發生故障將使集群崩潰2、Secondary Namenode監控HDFS狀態的輔助後臺程序每個集群都有一個與NameNode進行通訊定期保存HDFS元數據快照當N
hadoop學習筆記(一)——hadoop安裝及測試
這幾天乘著工作之餘,學習了一下hadoop技術,跌跌撞撞的幾天,終於完成了一個初步的hadoop的安裝及測試,具體如下: 動力:工作中遇到的資料量太大,伺服器已經很吃力,sql語句執行老半天,故想用大
[Hadoop] Hadoop學習筆記之Hadoop基礎
1 Hadoop是什麼? Google公司發表了兩篇論文:一篇論文是“The Google File System”,介紹如何實現分散式地儲存海量資料;另一篇論文是“Mapreduce:Simplified Data Processing on Large Clusters”,介紹如何對分散式大規模
Hadoop學習筆記—6.Hadoop Eclipse外掛的使用
開篇:Hadoop是一個強大的並行軟體開發框架,它可以讓任務在分散式叢集上並行處理,從而提高執行效率。但是,它也有一些缺點,如編碼、除錯Hadoop程式的難度較大,這樣的缺點直接導致開發人員入門門檻高,開發難度大。因此,Hadop的開發者為了降低Hadoop的難度,開發出了Hadoop Eclipse外掛,它
【Hadoop學習筆記】——Hadoop基礎
大資料時代 當前時代是資料爆炸的時代,全球各個網站、電子裝置等都在源源不斷地產生著大量資料.2006年數字世界專案統計得出全球資料總量為0.18ZB,2011年全球資料量1.8
大資料技術學習筆記之Hadoop框架基礎3-網站日誌分析及MapReduce過程詳解
一、回顧 -》Hadoop啟動方式 -》單個程序 sbin/h
hadoop學習筆記肆--元資料管理機制
1、首先,認識幾個名詞 (1)、NameNode中讀、寫、以及DataNode對映等資訊叫做“元資料” ,NameNode元資料存放位置有、記憶體、fsimage、edits log三個位置。 (2)、edits log:記錄當前最新的元資料。 (3)、
Hadoop學習筆記(3)-搭建Hadoop偽分散式
0.前言 1.配置core-site.xml檔案 配置hadoop目錄下的etc/Hadoop/core-site.xml檔案。 新增如下內容: 官網上只配置了fs.defaultFS引數,這個引數是配置hdfs的url地址。配置好後就可
Hadoop學習筆記-入門偽分散式配置(Mac OS,0.21.0,Eclipse 3.6)
11/09/04 22:32:33 WARN conf.Configuration: DEPRECATED: hadoop-site.xml found in the classpath. Usage of hadoop-site.xml is deprecated. Instead use core-s
hadoop學習筆記-HDFS的REST接口
字段 edi -o created hadoop ftw rar hdfs lang 在學習HDFS的過程中,重點關註了HDFS的REST訪問接口。以前對REST的認識非常籠統,這次通過對HDFS的REST接口進行實際操作,形成很直觀的認識。 1? 寫文件操作 寫文件
Hadoop 學習筆記 (2) -- 關於MapReduce
規模 pre 分析 bsp 學習筆記 reduce 數據中心 階段 圖例 1. MapReduce 定義: 是一種可用於數據處理的編程的模型 優勢: MapReduce 本質上是並行運行的,因此可以將大規模的數據分析任務,分發給任何一個擁有足夠多機器
hadoop學習筆記(1)
ppi datanode ati fonts 管理系 ive 監控 system 分配 1.HDFS架構: NameNode保存元數據信息,包含文件的owner,permission。block存儲信息等。存儲在內存。 2.HDFS設計思想
Hadoop學習筆記:MapReduce框架詳解
object 好的 單點故障 提高 apr copy 普通 exce 代表性 開始聊mapreduce,mapreduce是hadoop的計算框架,我學hadoop是從hive開始入手,再到hdfs,當我學習hdfs時候,就感覺到hdfs和mapreduce關系的緊密。這個
七、Hadoop學習筆記————調優之Hadoop參數調優
node 參數 受限 .com 資源 mage 預留空間 嘗試 nod dfs.datanode.handler.count默認為3,大集群可以調整為10 傳統MapReduce和yarn對比 如果服務器物理內存128G,則容器內存建議為100比較合理 配置總
八、Hadoop學習筆記————調優之Hive調優
需要 cnblogs log logs nbsp .cn 集中 bsp 9.png 表1表2的join和表3表4的join同時運行 此法需要關註是否有數據傾斜(大量數據集中在某一區間段) 八、Hadoop學習筆記————調優之Hive調優