
【Hadoop學習筆記】——Hadoop基礎

大資料時代
當前時代是資料爆炸的時代,全球各個網站、電子裝置等都在源源不斷地產生著大量資料.2006年數字世界專案統計得出全球資料總量為0.18ZB,2011年全球資料量1.8ZB,2013全球資料量4.4ZB,2014年全球資料總量在6.2ZB左右,2015年全球資料總量在8.6ZB左右,2016年12ZB左右,2020年的時候,全球的資料總量將達到40ZB。(小編的印象裡,高中時用的手機記憶體卡是512M,當時就感覺已經很牛逼了,現在16G、32G都感覺不夠用~)
1KB=1024B
1MB=1024KB
1GB=1024MB
1TB=1024GB
1PB=1024TB
1EB=1024PB 
Hadoop初識
隨著資料量的急劇增加,遇到的兩個最直接的問題就是資料儲存和計算(分析/利用)。
Hadoop是一個用Java實現的分散式基礎框架,也可以看做是一個支援開發、執行由通用計算裝置組成的大型叢集上的分散式應用的平臺。Hadoop中的兩個最重要的元件—HDFS和MapReduce就是用來解決海量資料(分散式)儲存、海量資料(分散式)計算的。
HDFS(HadoopDistributedFileSystem):Hadoop分散式檔案儲存系統,可以利用多臺價格低廉的機器,分散式儲存海量的資料。HDFS有兩種節點,NameNode和DataNode。DataNode主要用來儲存資料,NameNode管理著整個檔案系統的互動。相對於普通的檔案系統,HDFS顯著的特點是分散式海量儲存、備份機制。
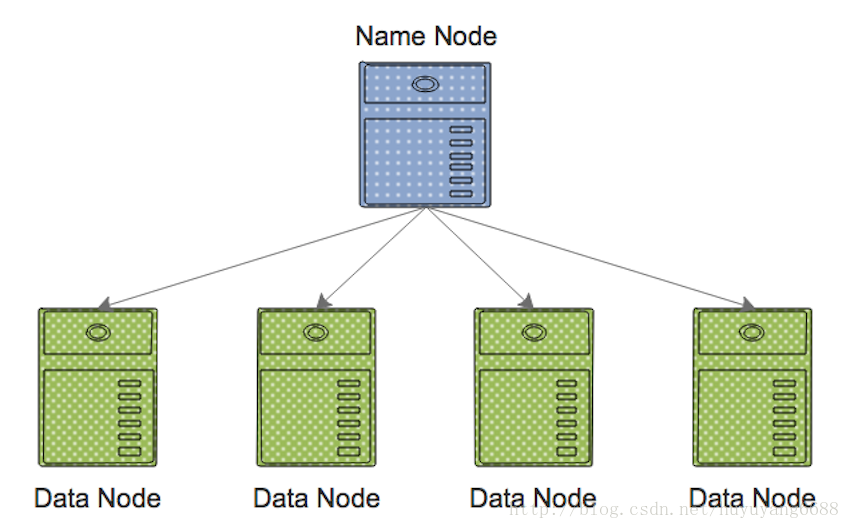
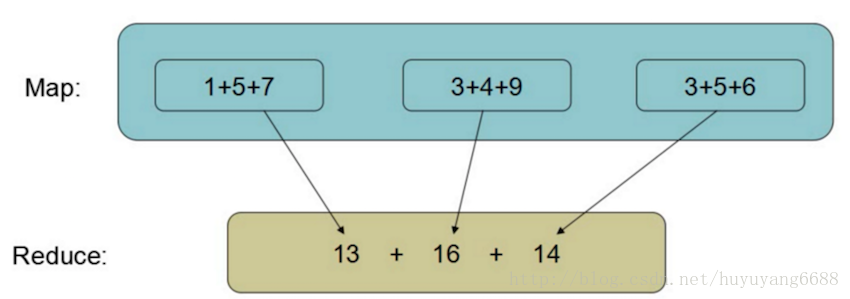
MapReduce:平行計算框架,MapReduce其實是一種分散式計算模型,多個計算機平行計算,共同做一件事情。
用一個簡單的例子來說明MapReduce,比如要做如下公式的求和結果,當涉及到的計算量比較大時,可以把任務拆分成幾個部分,每個部分分別有一臺計算機處理,然後每臺計算機處理的結果再進行彙總。
Hadoop應用場景
簡單認識了什麼是Hadoop,再來了解一下Hadoop一般都適用於哪些場景。
Hadoop主要應用於大資料量的離線場景,特點是大資料量、離線。
1、資料量大:一般真正線上用Hadoop的,叢集規模都在上百臺到幾千臺的機器。這種情況下,T級別的資料也是很小的。
另外,由於HDFS設計的特點,Hadoop適合處理檔案塊大的檔案。大量的小檔案使用Hadoop來處理效率會很低。
Hadoop常用的場景有:
●大資料量儲存:分散式儲存(各種雲盤,百度,360~還有云平臺均有hadoop應用)
●日誌處理
●海量計算,平行計算
●資料探勘(比如廣告推薦等)
●行為分析,使用者建模等
……