
pandas小記:pandas資料結構和基本操作
pandas的資料 結構:Series、DataFrame、索引物件
pandas基本功能:重新索引,丟棄指定軸上的項,索引、選取和過濾,算術運算和資料對齊,函式應用和對映,排序和排名,帶有重複值的軸索引
Pandas介紹
pandas含有使資料分析工作變得更快更簡單的高階資料結構和操作工具。它是基於NumPy構建的,讓以NumPy為中心的應用變得更加簡單。
通常建議你先學習NumPy,一個支援多維陣列的庫。但因為NumPy越來越成為一個被其他庫所使用核心庫,這些庫通常具有更優雅的介面。使用NumPy(或者笨重的Matlab)達到同樣的目的會很麻煩。
pandas可以以各種格式(包括資料庫)輸入輸出資料、執行join以及其他SQL類似的功能來重塑資料、熟練地處理缺失值、支援時間序列、擁有基本繪圖功能和統計功能,等等還有很多。
pandas常量
pandas空值的表示(None, np.NaN, np.NaT, pd.NaT)
NaN: not a number, NaN is the default missing value marker forreasons of computational speed and convenience, we need to be able to easilydetect this value with data of different types: floating point, integer,boolean, and general object.
None: treats None like np.nan. In many cases, however, the Python None will arise and we wish to also consider that “missing” or “null”.
NaT: Datetimes, For datetime64[ns] types, NaT represents missing values. This is a pseudo-native sentinel value that can be represented by numpy in a singular dtype (datetime64[ns]). pandas objects provide intercompatibility between NaT and NaN.
inf: Prior to version v0.10.0 inf and -inf were also considered to be “null” in computations. This is no longer the case by default; use the mode.use_inf_as_null option to recover it.
Note: 缺失值的判斷要用np.isnan(),而不能使用a[0] == np.NaN.[numpy教程:邏輯函式Logic functions ]
Pandas資料結構
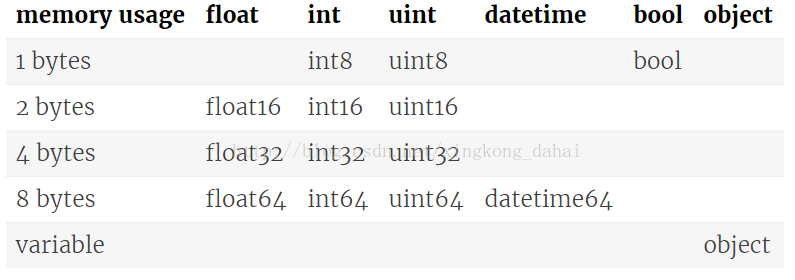
與Numpy一樣,用dtype屬性來顯示資料型別,Pandas主要有以下幾種dtype:
- object -- 代表了字串型別
- int -- 代表了整型
- float -- 代表了浮點數型別
- datetime -- 代表了時間型別
- bool -- 代表了布林型別
pandas安裝
pip install pandas
好像如果使用pd.read_excel要安裝xlrd:pip install xlrd
引入相關包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
pandas資料結構
pandas中的主要資料物件是Series和DataFrame。雖然它們不是沒一個問題的通用解決方案,但提供了一個堅實的,易於使用的大多數應用程式的基礎。
Series
Series是一個一維的類似的陣列物件,包含一個數組的資料(任何NumPy的資料型別)和一個與陣列關聯的資料標籤,被叫做索引 。Seriers的互動式顯示的字串表示形式是索引在左邊,值在右邊。
lz通過使用series自帶的函式,發現它和python dict型別太像了,基本一樣!就如下所述:Series是一個定長的,有序的字典,因為它把索引和值對映起來了。它可以適用於許多需要一個字典的函式。
總結說就是,他像一個數組,你可以像陣列那樣索引,他也想一個字典,你可以像字典那樣索引。
series物件建立
如果不給資料指定索引,一個包含整數0到 N-1 (這裡N是資料的長度)的預設索引被建立。 你可以分別的通過它的values 和index 屬性來獲取Series的陣列表示和索引物件:
最簡單的Series是由一個陣列的資料構成:
In [4]: obj = Series([4, 7, -5, 3])
In [5]: obj
Out[5]:
0 4
1 7
2 -5
3 3
In [6]: obj.values
Out[6]: array([ 4, 7, -5, 3])
In [7]: obj.index
Out[7]: Int64Index([0, 1, 2, 3])
通常,需要建立一個帶有索引來確定每一個數據點的Series:
In [8]: obj2 = Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
In [9]: obj2
Out[9]:
d 4
b 7
a -5
c 3
Note: pandas物件(series和dataframe)的index是可以修改的
df.index = range(len(df))重新將index的值修改成了從0開始。這也許是和dict的一個不同吧。
另一種思考的方式是,Series是一個定長的,有序的字典,因為它把索引和值對映起來了。它可以適用於許多需要一個字典的函式:
In [18]: 'b' in obj2
Out[18]: True
In [19]: 'e' in obj2
Out[19]: False
如果你有一些資料在一個Python字典中,你可以通過傳遞字典來從這些資料建立一個Series:
In [20]: sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
In [21]: obj3 = Series(sdata)
只傳遞一個字典的時候,結果Series中的索引將是排序後的字典的建。
In [23]: states = [‘California’, ‘Ohio’, ‘Oregon’, ‘Texas’]
In [24]: obj4 = Series(sdata, index=states)
In [25]: obj4
Out[25]:California NaNOhio 35000Oregon 16000Texas 71000
在這種情況下, sdata 中的3個值被放在了合適的位置,但因為沒有發現對應於 ‘California’ 的值,就出現了NaN (不是一個數),這在pandas中被用來標記資料缺失或NA 值。我使用“missing”或“NA”來表示數度丟失。
Series的字典也以巢狀的字典的字典格式的方式來處理:
In [62]: pdata = {'Ohio': frame3['Ohio'][:-1],
....: 'Nevada': frame3['Nevada'][:2]}
In [63]: DataFrame(pdata)
Out[63]:
Nevada Ohio
2000 NaN 1.5
2001 2.4 1.7
series物件轉換為字典dict
從series的字典構建中可以看出他們互相轉換的機制了:將series物件的index作為keys,對應的值作為dict的value。
obj2 = pd.Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
d 4
b 7
a -5
c 3
dtype: int64
In[27]: dict(obj2)
{'a': -5, 'b': 7, 'c': 3, 'd': 4}
series物件轉換為tuple列表
list(se.items())
pandas中用函式isnull 和notnull 來檢測資料丟失:
In [26]: pd.isnull(obj4) In [27]: pd.notnull(obj4)
Out[26]: Out[27]:
California True California False
Ohio False Ohio True
Oregon False Oregon True
Texas False Texas True
Series也提供了這些函式的例項方法:
In [28]: obj4.isnull()
Out[28]:
California True
Ohio False
Oregon False
Texas False
series物件操作
series物件迭代
Series.iteritems()
Lazily iterate over (index, value) tuples
[i.split(',') for _, i in df['VenueCategory'].iteritems()]與正規的NumPy陣列相比,你可以使用索引裡的值來選擇一個單一值或一個值集:
In [11]: obj2['a']
Out[11]: -5
In [12]: obj2['d'] = 6
In [13]: obj2[['c', 'a', 'd']]
Out[13]:
c 3
a -5
d 6
NumPy陣列操作,例如通過一個布林陣列過濾,純量乘法,使用數學函式,將會保持索引和值間的關聯:
In [14]: obj2
Out[14]:
d 6
b 7
a -5
c 3
In [15]: obj2[obj2 > 0] In [16]: obj2 * 2 In [17]: np.exp(obj2)
Out[15]: Out[16]: Out[17]:
d 6 d 12 d 403.428793
b 7 b 14 b 1096.633158
c 3 a -10 a 0.006738
c 6 c 20.085537
在許多應用中Series的一個重要功能是在算術運算中它會自動對齊不同索引的資料:
In [29]: obj3 In [30]: obj4
Out[29]: Out[30]:
Ohio 35000 California NaN
Oregon 16000 Ohio 35000
Texas 71000 Oregon 16000
Utah 5000 Texas 71000
In [31]: obj3 + obj4
Out[31]:
California NaN
Ohio 70000
Oregon 32000
Texas 142000
Utah NaN
Series物件本身和它的索引都有一個 name 屬性,它和pandas的其它一些關鍵功能整合在一起:
In [32]: obj4.name = 'population'
In [33]: obj4.index.name = 'state'
In [34]: obj4
Out[34]:
state
California NaN
Ohio 35000
Oregon 16000
Texas 71000
Name: population
Series索引更改
可以通過賦值就地更改:
In [35]: obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
In [36]: obj
Out[36]:
Bob 4
Steve 7
Jeff -5
Ryan 3
series值替換
ser.replace(1, 11)
可以使用字典對映:將1替換為11,將2替換為12
ser.replace({1:11, 2:12})
series列分割轉換成dataframe
s = pd.Series(['15,15', '17,17', '36,36', '24,24', '29,29'])
print(type(s))
print(s)
s = s.apply(lambda x: pd.Series(x.split(',')))
print(type(s))
print(s)<class 'pandas.core.series.Series'>
0 15,15
1 17,17
2 36,36
3 24,24
4 29,29
dtype: object
<class 'pandas.core.frame.DataFrame'>
0 1
0 15 15
1 17 17
2 36 36
3 24 24
4 29 29
Note: series物件直接應用apply方法是不會改變原series物件的,要賦值修改。
DataFrame
一個Datarame表示一個表格,類似電子表格的資料結構,包含一個經過排序的列表集,它們沒一個都可以有不同的型別值(數字,字串,布林等等)。Datarame有行和列的索引;它可以被看作是一個Series的字典(每個Series共享一個索引)。與其它你以前使用過的(如R 的data.frame )類似Datarame的結構相比,在DataFrame裡的面向行和麵向列的操作大致是對稱的。在底層,資料是作為一個或多個二維陣列儲存的,而不是列表,字典,或其它一維的陣列集合。
因為DataFrame在內部把資料儲存為一個二維陣列的格式,因此你可以採用分層索引以表格格式來表示高維的資料。分層索引是pandas中許多更先進的資料處理功能的關鍵因素。
構建DataFrame
| 二維ndarray | 一個數據矩陣,有可選的行標和列標 |
|---|---|
| 陣列,列表或元組的字典 | 每一個序列成為DataFrame中的一列。所有的序列必須有相同的長度。 |
| NumPy的結構/記錄陣列 | 和“陣列字典”一樣處理 |
| Series的字典 | 每一個值成為一列。如果沒有明顯的傳遞索引,將結合每一個Series的索引來形成結果的行索引。 |
| 字典的字典 | 每一個內部的字典成為一列。和“Series的字典”一樣,結合鍵值來形成行索引。 |
| 字典或Series的列表 | 每一項成為DataFrame中的一列。結合字典鍵或Series索引形成DataFrame的列標。 |
| 列表或元組的列表 | 和“二維ndarray”一樣處理 |
| 另一個DataFrame | DataFrame的索引將被使用,除非傳遞另外一個 |
| NumPy偽裝陣列(MaskedArray) | 除了矇蔽值在DataFrame中成為NA/丟失資料之外,其它的和“二維ndarray”一樣 |
字典或NumPy陣列
最常用的一個是用一個相等長度列表的字典或NumPy陣列:
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
frame = DataFrame(data)
由此產生的DataFrame和Series一樣,它的索引會自動分配,並且對列進行了排序:
In [38]: frame
Out[38]:
pop state year
0 1.5 Ohio 2000
1 1.7 Ohio 2001
2 3.6 Ohio 2002
3 2.4 Nevada 2001
4 2.9 Nevada 2002
如果你設定了一個列的順序,DataFrame的列將會精確的按照你所傳遞的順序排列:
DataFrame(data, columns=['year', 'state', 'pop'])
和Series一樣,如果你傳遞了一個行,但不包括在 data 中,在結果中它會表示為NA值:
In [40]: frame2 = DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
....: index=['one', 'two', 'three', 'four', 'five'])
In [41]: frame2
Out[41]:
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN
Creating a DataFrame by passing a numpy array, with a datetime indexand labeled columns:
In [6]: dates = pd.date_range('20130101', periods=6)
In [7]: dates
Out[7]:
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
In [8]: df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
In [9]: df
Out[9]:
A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-05 -0.424972 0.567020 0.276232 -1.087401
2013-01-06 -0.673690 0.113648 -1.478427 0.524988
巢狀的字典的字典格式
In [57]: pop = {'Nevada': {2001: 2.4, 2002: 2.9},
....: 'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
如果被傳遞到DataFrame,它的外部鍵會被解釋為列索引,內部鍵會被解釋為行索引:
In [58]: frame3 = DataFrame(pop)
In [59]: frame3
Nevada Ohio
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6
當然,你總是可以對結果轉置:
In [60]: frame3.T
2000 2001 2002
Nevada NaN 2.4 2.9
Ohio 1.5 1.7 3.6
內部字典的鍵被結合並排序來形成結果的索引。如果指定了一個特定的索引,就不是這樣的了:
In [61]: DataFrame(pop, index=[2001, 2002, 2003])
Nevada Ohio
2001 2.4 1.7
2002 2.9 3.6
2003 NaN NaN
通過series物件建立
df.median()就是一個series物件
pd.DataFrame([df.median(), df.mean(), df.std()], index=['median', 'mean', 'std'])dataframe資料轉換成其它格式
dataframe轉換為字典
簡單可知從字典構建dataframe就知道dataframe是如何轉換為字典的了,dataframe會轉換成巢狀dict。
如果只是選擇一列進行轉換,就相當於是將series物件轉換成dict。
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'], 'year': [2000, 2001, 2002, 2001, 2002], 'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
frame = pd.DataFrame(data, index = [2,3,4,5, 6])
pop state year
2 1.5 Ohio 2000
3 1.7 Ohio 2001
4 3.6 Ohio 2002
5 2.4 Nevada 2001
6 2.9 Nevada 2002
In[23]: dict(frame['year'])
{2: 2000, 3: 2001, 4: 2002, 5: 2001, 6: 2002}
In[24]: dict(frame[['pop', 'year']])
{'pop': 2 1.5
3 1.7
4 3.6
5 2.4
6 2.9
Name: pop, dtype: float64,
'year': 2 2000
3 2001
4 2002
5 2001
6 2002
Name: year, dtype: int64}
Note: 上面是一個巢狀dict,通過dict['pop'][2]可以得到1.5。
dataframe轉換成巢狀list
ltu_list = [col.tolist() for _, col in ltu_df.iterrows()]也就是對資料進行遍歷的方法
for index, row in data.iterrows()
Note: 也對index進行了遍歷。
pandas.dataframe轉換成numpy.ndarray
rat_array = rat_mat_df.values
存在的坑:
l_array = df['VenueLocation'].map(lambda s: np.array(s.split(','))).values
print(type(l_array))
print(l_array.shape)
<class 'numpy.ndarray'>
(483805,)而不是(483805, 2)
原因在於轉換後array中的元素不是當成兩列,而是一列,也就是將兩個元素當成了一個列表或者array元素,只有一列了。進行資料轉換時l_array.astype(float)就會出錯:ValueError: setting an array element with a sequence。這裡最好使用l_array = np.array([s.split(',') for s in l_array]).astype(float)。
dataframe資料型別轉換
使用 DataFrame.dtypes 可以檢視每列的資料型別,Pandas預設可以讀出int和float64,其它的都處理為object,需要轉換格式的一般為日期時間。
DataFrame.astype() 方法可對整個DataFrame或某一列進行資料格式轉換,支援Python和NumPy的資料型別。
Having specific dtypes. The main types stored in pandas objects are float, int, bool,datetime64[ns] and datetime64[ns, tz] (in >= 0.17.0), timedelta[ns],category and object. In addition these dtypes have item sizes, e.g.int64 and int32. 其它引數參考官網。
data_df['case_id'] = data_df['case_id'].astype('int64').astype('str')
檢視資料
See the top & bottom rows of the frame
In [14]: df.head()
Out[14]:
A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-05 -0.424972 0.567020 0.276232 -1.087401
In [15]: df.tail(3)
Out[15]:
A B C D
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-05 -0.424972 0.567020 0.276232 -1.087401
2013-01-06 -0.673690 0.113648 -1.478427 0.524988
Display the index, columns, and the underlying numpy data
dataframe資料遍歷和迭代iteration
-
for i in obj 方式,對不同資料結構不同;遍歷的只是df的columns names
- Series : 代表值
- DataFrame : 代表列label,即列名
- Panel : item label
-
.iteriems(),對DataFrame相當於對列迭代。
- Series: (index, value)
- DataFrame : (column, Series)
- Panel : (item, DataFrame)
-
df.iterrow(),對DataFrame的每一行進行迭代,返回一個Tuple (index, Series)
- df.itertuples(),也是一行一行地迭代,返回的是一個namedtuple,通常比iterrow快,因為不需要做轉換
for idx, row in df.iterrows():
print idx, row
for row in df.itertuples():
print row
for c, col in df.iteritems():
print c, col
檢視資料行列數
pandas返回整個dataframe資料的個數:df.size
pandas返回dataframe行數可能最快的方式:df.shape[0]
pandas返回dataframe列數:df.shape[1] 或者df.columns.size
資料型別
Having specific dtypes
In [12]: df2.dtypes
Out[12]:
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
列columns和行index的名字及資料值的檢視values
在R語言中,資料列和行的名字通過colnames和rownames來分別進行提取。在Python中,我們則使用columns和index屬性來提取。
In [16]: df.index
Out[16]:
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
In [17]: df.columns
Out[17]: Index([u'A', u'B', u'C', u'D'], dtype='object')像Series一樣, values 屬性返回一個包含在DataFrame中的資料的二維ndarray:
In [18]: df.values
Out[18]:
array([[ 0.4691, -0.2829, -1.5091, -1.1356],
[ 1.2121, -0.1732, 0.1192, -1.0442],
[-0.8618, -2.1046, -0.4949, 1.0718],
[ 0.7216, -0.7068, -1.0396, 0.2719],
[-0.425 , 0.567 , 0.2762, -1.0874],
[-0.6737, 0.1136, -1.4784, 0.525 ]])如果DataFrame各列的資料型別不同,則值陣列的資料型別就會選用能相容所有列的資料型別:
In [67]: frame2.values
Out[67]:
array([[2000, Ohio, 1.5, nan],
[2001, Ohio, 1.7, -1.2],
[2002, Ohio, 3.6, nan],
[2001, Nevada, 2.4, -1.5],
[2002, Nevada, 2.9, -1.7]], dtype=object)
index 和 columns 的 name
如果一個DataFrame的 index 和 columns 有它們的 name ,也會被顯示出來:
In [64]: frame3.index.name = 'year'; frame3.columns.name = 'state'
In [65]: frame3
Out[65]:
state Nevada Ohio
year
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6
在列名修改
s_group.columns = ['#user']
dataframe值的修改setting
修改方法有:
df['F'] = s1
df.at[dates[0],'A'] = 0
df.iat[0,1] = 0
df.loc[:,'D'] = np.array([5] * len(df))
列的修改和賦值
列可以通過賦值來修改。例如,空的 ‘debt’ 列可以通過一個純量或陣列來賦值:
In [46]: frame2['debt'] = 16.5
In [47]: frame2
Out[47]:
year state pop debt
one 2000 Ohio 1.5 16.5
two 2001 Ohio 1.7 16.5
three 2002 Ohio 3.6 16.5
four 2001 Nevada 2.4 16.5
five 2002 Nevada 2.9 16.5
In [48]: frame2['debt'] = np.arange(5.)
In [49]: frame2
Out[49]:
year state pop debt
one 2000 Ohio 1.5 0
two 2001 Ohio 1.7 1
three 2002 Ohio 3.6 2
four 2001 Nevada 2.4 3
five 2002 Nevada 2.9 4
#沒有第6列,增加第6列
df[6] = np.select([y_score < 0.0, y_score > 1.0, True], [0.0, 1.0, y_score])通過列表或陣列給一列賦值時,所賦的值的長度必須和DataFrame的長度相匹配。
如果你使用Series來賦值,它會代替在DataFrame中精確匹配的索引的值,並在說有的空洞插入丟失資料:
In [50]: val = Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
In [51]: frame2['debt'] = val
In [52]: frame2
Out[52]:
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 -1.2
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 -1.5
five 2002 Nevada 2.9 -1.7
給一個不存在的列賦值,將會建立一個新的列。
In [53]: frame2['eastern'] = frame2.state == 'Ohio'
In [54]: frame2
Out[54]:
year state pop debt eastern
one 2000 Ohio 1.5 NaN True
two 2001 Ohio 1.7 -1.2 True
three 2002 Ohio 3.6 NaN True
four 2001 Nevada 2.4 -1.5 False
five 2002 Nevada 2.9 -1.7 False
像字典一樣 del 關鍵字將會刪除列:
In [55]: del frame2['eastern']
In [56]: frame2.columns
Out[56]: Index([year, state, pop, debt], dtype=object)將dataframe的一列column分割成兩列column
ltu_df = ltu_df['VenueLocation'].apply(lambda s: pd.Series([float(i) for i in s.split(',')])).join(ltu_df).drop('VenueLocation', axis=1)或者
df = pd.concat([df, dates.apply(lambda x: pd.Series(json.loads(x)))], axis=1, ignore_index=True)或者
lista = [item.split(' ')[2] for item in df['Fecha']]
listb = p.Series([item.split(' ')[0] for item in df['Fecha']])
df['Fecha'].update(listb)
df['Hora'] = lista將dataframe的兩列column合併成一列column
In [10]: df
A B lat long
0 1.428987 0.614405 0.484370 -0.628298
1 -0.485747 0.275096 0.497116 1.047605
In [11]: df['lat_long'] = df[['lat', 'long']].apply(tuple, axis=1)
In [12]: df
A B lat long lat_long
0 1.428987 0.614405 0.484370 -0.628298 (0.484370195967, -0.6282975278)
1 -0.485747 0.275096 0.497116 1.047605 (0.497115615839, 1.04760475074)Note: apply裡面如果使用list來合併會失敗,df並不會有任何改變,目前lz還沒發現什麼原因。
合併兩列當然還可以使用np.dstack和zip等等方法。
[How to form tuple column from two columns in Pandas]
pandas.dataframe值替換
DataFrame.replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad', axis=None)
引數to_replace : str, regex, list, dict, Series, numeric, or None
dict: Nested dictionaries, e.g., {‘a’: {‘b’: nan}}, are read asfollows: look in column ‘a’ for the value ‘b’ and replace itwith nan. You can nest regular expressions as well. Note thatcolumn names (the top-level dictionary keys in a nesteddictionary) cannot be regular expressions.
Keys map to column names and values map to substitutionvalues. You can treat this as a special case of passing twolists except that you are specifying the column to search in.
ui_rec_df.replace({0: item_names_dict}, inplace=True)
不過字典的方法只能一列一列的將某個值替換為另一個值。
所以還可以這樣:
for key in item_names_dict:
ui_rec_df.replace(key, item_names_dict[key], inplace=True)要替換的值還可以是正則表示式regex : bool or same types as to_replace, default False
Whether to interpret to_replace and/or value as regular expressions. If this is True then to_replace must be a string. Otherwise, to_replace must be None because this parameter will be interpreted as a regular expression or a list, dict, or array of regular expressions.
pandas基本功能
本節將帶你穿過Series或DataFrame所包含的資料的基礎結構的相互關係。
從一個座標軸刪除條目drop
對於Series
丟棄某條軸上的一個或多個項很簡單,只要有一個索引陣列或列表即可。由於需要執行一些資料整理和集合邏輯,所以drop方法返回的是一個在指定軸上刪除了指定值的新物件:
In [94]: obj = Series(np.arange(5.), index=['a', 'b', 'c', 'd', 'e'])
In [95]: new_obj = obj.drop('c')
In [97]: obj.drop(['d', 'c'])
Out[97]:
a 0
b 1
e 4
對於DataFrame
可以從任何座標軸刪除索引值:axis 引數告訴函式到底捨棄列還是行,如果axis等於0,那麼就捨棄行。
In [98]: data = DataFrame(np.arange(16).reshape((4, 4)), index=['Ohio', 'Colorado', 'Utah', 'New York'], columns=['one', 'two', 'three', 'four'])
In [99]: data.drop(['Colorado', 'Ohio'])
Out[99]:
one two three four
Utah 8 9 10 11
New York 12 13 14 15
測試了一下,也可以使用df.drop(1)來刪除行1。
In [100]: data.drop('two', axis=1) In [101]: data.drop(['two', 'four'], axis=1) #等價於date.drop(date.columns[[1, 3]], axis = 1)
Out[100]: Out[101]:
one three four one three
Ohio 0 2 3 Ohio 0 2
Colorado 4 6 7 Colorado 4 6
Utah 8 10 11 Utah 8 10
New York 12 14 15 New York 12 14算術和資料對齊
算術運算及NA值
pandas的最重要的特性之一是在具有不同索引的物件間進行算術運算的行為。當把物件加起來時,如果有任何的索引對不相同的話,在結果中將會把各自的索引聯合起來。
對於Series
>>>s1 = Series([7.3, -2.5, 3.4, 1.5],index=['a', 'c', 'd', 'e'])
>>>s2 = Series([-2.1, 3.6, -1.5, 4, 3.1], index=['a', 'c', 'e', 'f', 'g'])
>>>s1+s2
a 5.2
c 1.1
d NaN
e 0.0
f NaN
g NaN
dtype: float64
內部資料對其,在索引不重合的地方引入了NA值。資料缺失在算術運算中會傳播。
對於DataFrame
對其在行和列上都表現的很好:
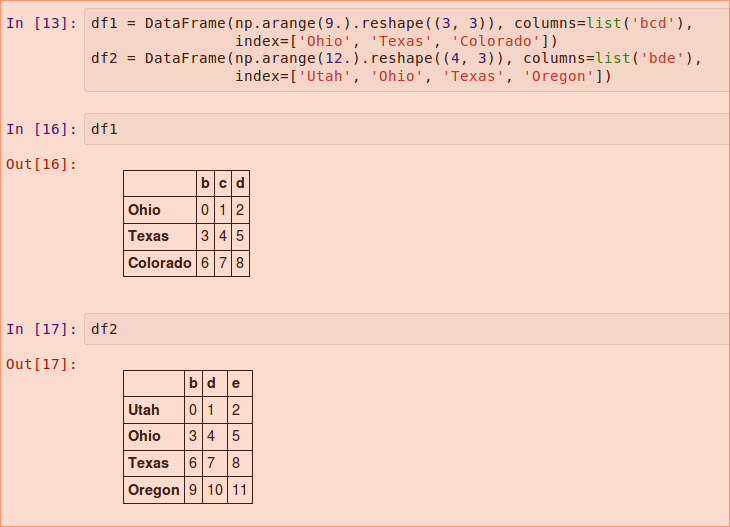
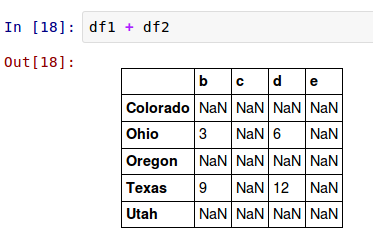
把這些加起來返回一個DataFrame,它的索引和列是每一個DataFrame對應的索引和列的聯合:
帶填充值的算術方法
在不同索引物件間的算術運算,當一個軸標籤在另一個物件中找不到時,你可能想要填充一個特定的值,如0:
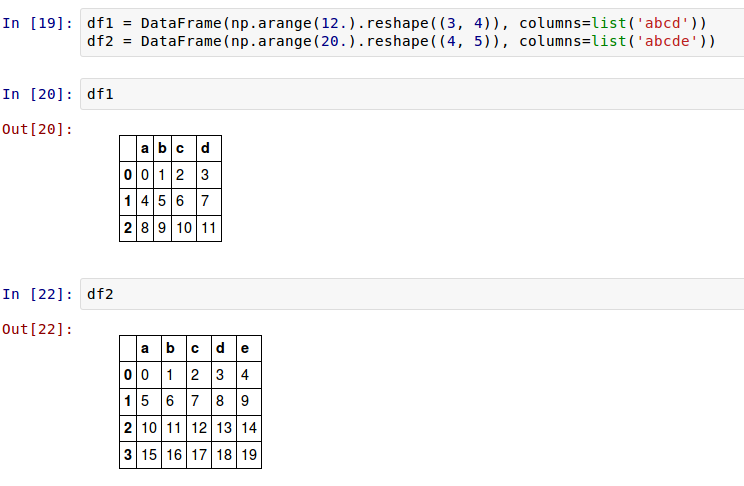
把它們加起來導致在不重合的位置出現NA值。
在 df1 上使用 add 方法,我把 df2 傳遞給它並給fill_value 賦了一個引數:
>>>df1.add(df2, fill_value=0)
與此類似,在對Series或DataFrame重新索引時,也可以指定一個填充值:

| add | 加法(+) |
|---|---|
| sub | 減法(-) |
| div | 除法(/) |
| mul | 乘法(*) |
DataFrame 和 Series 間的操作
與NumPy陣列一樣,很好的定義了DataFrame和Series間的算術操作。
首先,作為一個激發性的例子,考慮一個二維陣列和它的一個行間的差分,這被稱為 廣播 (broadcasting)。

在一個DataFrame和一個Series間的操作是類似的:
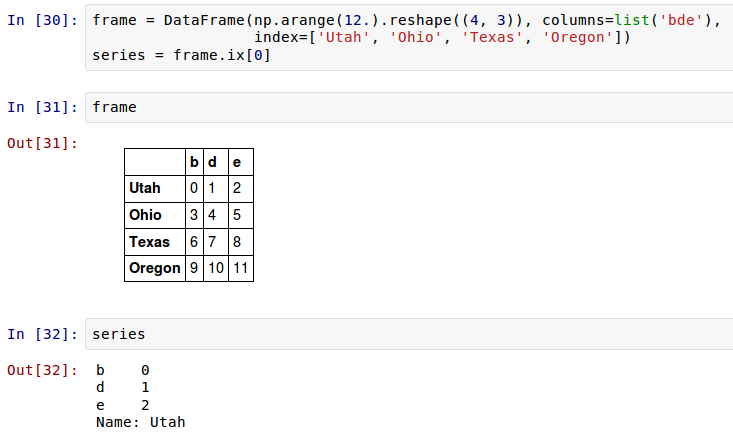
預設的,DataFrame和Series間的算術運算Series的索引將匹配DataFrame的列,並在行上擴充套件:
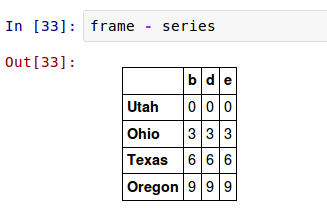
如果一個索引值在DataFrame的列和Series的索引裡都找不著,物件將會從它們的聯合重建索引:
如果想在行上而不是列上進行擴充套件,你要使用一個算術方法。例如:
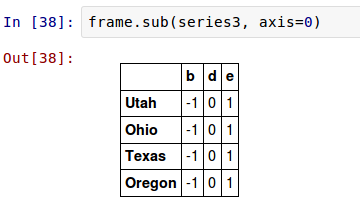
你所傳遞的座標值是將要匹配的 座標 。這種情況下是匹配DataFrame的行,並進行擴充套件。
函式應用和對映
NumPy的ufuncs (元素級陣列方法)用於操作pandas物件
np.abs(frame)
dataframe函式應用
apply()將一個函式作用於DataFrame中的每個行或者列,而applymap()是將函式做用於DataFrame中的所有元素(elements)。
函式應用到由各列或行所形成的一維陣列上apply
DataFrame的 apply方法即可實現此功能。許多最為常見的陣列統計功能都被實現成DataFrame的方法(如sum和mean),因此無需使用apply方法。
預設對列操作(axis=0),如傳入np.sum()是對每列求和。
返回標量值
>>>f = lambda x: x.max() - x.min()
>>>frame.apply(f)
>>>frame.apply(f, axis=1)
df.apply(np.cumsum)
除標量值外,傳遞給apply的函式還可以返回由多個值組成的Series
>>>def f(x):
return Series([x.min(), x.max()], index=['min', 'max'])
>>>frame.apply(f)
dataframe應用元素級的Python函式applymap
假如想得到frame中各個浮點值的格式化字串,使用applymap即可。
>>>format = lambda x: '%.2f' % x
>>>frame.applymap(format)
之所以叫做applymap,是因為Series有一個用於應用元素級函式的map方法:
>>>frame['e'].map(format)
只對df的某列進行變換就取那一列的series進行變換就好了
如將時間轉換成只有日期date沒有時間time
user_pay_df['time']=user_pay_df['time'].apply(lambda x:x.date())
Series函式應用
Series.apply(func, convert_dtype=True, args=(), **kwds)
Invoke function on values of Series. Can be ufunc (a NumPy functionthat applies to the entire Series) or a Python function that only workson single values
Series.map(arg, na_action=None)
Map values of Series using input correspondence (which can be a dict, Series, or function)
與apply的區別可能就只是應用的函式更多一點吧,如示例中series map到series上。
示例
>>> x
one 1
two 2
three 3
>>> y
1 foo
2 bar
3 baz
>>> x.map(y)
one foo
two bar
three baz
s3 = s.map(lambda x: 'this is a string {}'.format(x),
na_action='ignore')
0 this is a string 1.0
1 this is a string 2.0
2 this is a string 3.0
3 NaN
排序(sorting)
根據條件對資料集排序(sorting)也是一種重要的內建運算。
對行或列索引進行排序 (按字典順序)sort_index
sort_index方法,它將返回一個已排序的新物件:
>>>obj = Series(range(4), index=['d', 'a', 'b', 'c'])
>>>obj.sort_index()
a 1
b 2
c 3
d 0
dtype: int64
按值對Series進行排序order
>>>obj = Series([4, 7, -3, 2])
>>>obj.order()
2 -3
3 2
0 4
1 7
>>>obj = Series([4, np.nan, 1, np.nan, -3, 2])
>>>obj.order() #在排序時,缺失值預設都會被放到Series的末尾.
4 -3
2 1
5 2
0 4
1 NaN
NaN
DataFrame任意軸上索引進行排序
>>>frame = DataFrame(np.arange(8).reshape((2, 4)), index=['three', 'one'], columns=['d','a','b','c'])
>>>frame.sort_index()
>>>frame.sort_index(axis=1)
資料預設是按升序排序的,但也可以降序排序:
>>>frame.sort_index(axis=1, ascending=False)
DataFrame列的值排序
將一個或多個列的名字傳遞給by選項即可達到該目的:
>>>frame = DataFrame({'b': [4,7,-3,2], 'a':[0, 1, 0, 1]})
>>> frame.sort_index(by='b') #或者df.sort_values(by='b')
要根據多個列進行排序,傳入名稱的列表即可:>>>frame.sort_index(by=['a', 'b'])
或者syntax of sort:
DataFrame.sort(columns=None, axis=0, ascending=True, inplace=False, kind='quicksort',na_position='last')
we will sort the data by “2013” column
Insurance_rates.sort(['2013','State'],ascending=[1, 0])
排名(ranking)
跟排序關係密切,且它會增設一個排名值(從1開始,一直到陣列中有 效資料的數量)。
它跟numpy.argsort產生的間接排序索引差不多,只不過它可以根據某種規則破壞平級關係。
Series和DataFrame的rank方法:預設情況下,rank是通過“為各組分配一個平均排名”的方式破壞平級關係的:
>>> obj = Series([7,-5,7,4,2,0,4])
>>>obj
0 7
1 -5
2 7
3 4
4 2
5 0
6 4
>>> print obj.rank()
0 6.5
1 1.0
2 6.5
3 4.5
4 3.0
5 2.0
6 4.5
>>> obj.rank(method='first') #根據值在原資料中出現的順序給出排名:
0 6
1 1
2 7
3 4
4 3
5 2
5
>>> obj.rank(ascending=False, method='max') # 按降序進行排名:
0 2
1 7
2 2
3 4
4 5
5 6
6 4
排名時用於破壞平級關係的method選項
Method 說明
‘average’ 預設:在相等分組中,為各個值分配平均排名
‘min’ 使用整個分組的最小排名
‘max’ 使用整個分組的最大排名
‘first’ 按值在原始資料中的出現順序分配排名
DataFrame在行或列上計算排名
>>> frame =DataFrame({'b': [4.3, 7, -3, 2], 'a': [0, 1, 0, 1],
'c':[-2, 5, 8, -2.5]})
>>> frame.rank(axis=1)
ref:《利用Python進行資料分析》*
API Reference
]
pandas-cookbook
[Pandas 中的坑:index操作 遍歷操作]
相關推薦
pandas小記:pandas資料結構和基本操作
pandas的資料 結構:Series、DataFrame、索引物件 pandas基本功能:重新索引,丟棄指定軸上的項,索引、選取和過濾,算術運算和資料對齊,函式應用和對映,排序和排名,帶有重複值的軸索引 Pandas介紹 pandas含有使資料分析工作變得更快更簡單
pandas小記:pandas資料規整化-缺失和冗餘資料處理
處理缺失資料 缺失資料(missing data)在大部分資料分析應用中都很常見。pandas的設計目標之一就是讓缺失資料的處理任務儘量輕鬆,pandas物件上的所有描述統計都排除了缺失資料。 pandas使用浮點NaN (Not a Number)表示浮點和非浮點陣列
pandas小記:pandas計算工具-彙總統計
彙總和計算描述統計:統計函式 pandas物件擁有一組常用的數學和統計方法。它們大部分都屬於約簡和彙總統計,用於從Series中提取的個值(如sum或mean)或從DataFrame的行或列中提取一個Series。 跟對應的NumPy陣列方法相比,它們都是基於沒有缺失資料的
第一章:Python資料結構和演算法
第一章:Python資料結構和演算法 Python 提供了大量的內建資料結構,包括列表,集合以及字典。大多數情況下使用這些資料結構是很簡單的。 但是,我們也會經常碰到到諸如查詢,排序和過濾等等這些普遍存在的問題。 因此,這一章的目的就是討論這些比較常見的問題和演算法。 另外,我們也會
Leetcode開篇:複習資料結構和演算法
背景 讀研的時候從研一開始刷演算法題,Leetcode的程式碼絕大部分都刷完了。後來實習找工作也在繼續刷,但是感覺實習過程中研發崗用到演算法的機會並不是那麼多。所以慢慢的發現這方面能力開始退化了。 畢竟演算法是長遠之計,所以必須得溫故知新,額外之前刷題並沒有很好的做筆記
python學習之二:python資料結構和記憶體管理
python資料結構和記憶體管理思維導圖:對於資料結構的學習主要從這幾方面入手:初始化常用操作(增刪該查)常用內建函式,注意點有序序列主要分為字串,列表,和元組,一.有序序列定義:str1=‘python’//字串l1=['python','java','c',100] o
[資料結構&基操][C++]一個二維網狀資料結構及基本操作
一是因為上學期學了資料結構,二是因為面對物件的程式設計學的不精,我便用資料結構做了一個資訊管理系統作為C艹大作業。 沒想到居然拿了優秀 ψ(`∇´)ψ (不管難否,反正是筆者五級分制中唯一的優秀) 先上資料結構圖 貼程式碼 結構體: t
SSM:物件資料,實現基本操作
上期 基本配置 package com.cn.model; public class User { private int userId; private String userName; private int userSum; pub
python 內建資料結構的基本操作 —— tuple(1)
We saw that lists and strings have many common properties, such as indexing and slicing operations. They are two examples of sequen
二叉連結串列的儲存結構和基本操作(各種遍歷、求樹深度、求樹葉個數)
1.二叉樹的定義及性質 二叉樹是一種樹狀結構,它的特點是每個節點至多隻能有兩棵子樹,並且二叉樹的子樹有左右之分,其次序不能任意調換。 二叉樹具有以下重要性質: 性質 1 在二叉樹的第i層上至多有2^(i-1)個節點。 性質 2 深度為k的二叉樹至多有2^k-1個節點。 性
python 內建資料結構的基本操作 —— Set(1)
Python also includes a data type for sets. A set is an unordered collection with no duplicate elements. Basic uses include membersh
常用資料結構和演算法操作效率的對比總結
歡迎關注我新搭建的部落格:[http://www.itcodai.com/](http://www.itcodai.com/) 前面介紹了經典的資料結構和演算法,這一節我們對這些資料結構和演算法做一個總結,具體細節,請參見各個章節的詳細介紹,這裡我們用表
python 內建資料結構的基本操作 —— dict(2)
A mapping object maps hashable values to arbitrary objects. Mappings are mutable objects. There is currently only one standard mapp
python 內建資料結構的基本操作 —— list(2)
The list data type has some more methods. Here are all of the methods of list objects: list.append(x) Add an item to the end of t
c語言實現單鏈表資料結構及其基本操作
帶頭結點單鏈表。分三個檔案,分別為標頭檔案,測試檔案,原始碼檔案。 給出了單鏈表的部分操作,每個操作都有對應的註釋說明該函式功能。 test.c 檔案中,對輸入資料是否合法進行了檢測,但是並未實現輸入資料不合法時應該採取的措施。 測試檔案 通過一個選單來測試單鏈
Python 資料處理擴充套件包: pandas 模組的DataFrame介紹(建立和基本操作)
DataFrame是Pandas中的一個表結構的資料結構,包括三部分資訊,表頭(列的名稱),表的內容(二維矩陣),索引(每行一個唯一的標記)。 一、DataFrame的建立 有多種方式可以建立DataFrame,下面舉例介紹。 例1: 通過list建立 >
易學筆記-go語言-第4章:基本結構和基本資料型別/4.4 變數/4.4.3 函式體內最簡單的變數初始化
函式體內最簡單的變數賦值 格式: 變數名 := 值 舉例: var goos string = os.Getenv("GOOS") fmt.Printf("The operating system is: %s\n", goos) //函式體內最
易學筆記-go語言-第4章:基本結構和基本資料型別/4.4 變數/4.4.2 宣告和賦值語句結合
宣告和賦值語句結合 格式:var identifier [type] = value 這裡的type是可選的,具體的型別參照: 第4章:基本結構和基本資料型別/4.2 Go 程式的基本結構和要素/4.2.8 型別 顯式型別舉例: //整型 var a&nbs
易學筆記-go語言-第4章:基本結構和基本資料型別/4.4 變數/4.4.4 函式體內並行初始化
函式體內並行賦值 在 第4章:基本結構和基本資料型別/4.4 變數/4.4.3 函式體內最簡單的變數賦值基礎上,多個變數同時賦值 舉例: 程式碼: a, b, c := 5, 10, "易學筆記" fmt.Printf("a&n
易學筆記-Go語言-第4章:基本結構和基本資料型別/4.5 基本型別/4.5.2 整形
整形 固定位元組數整形:與作業系統無關 int 和 uint 在 32 位作業系統上,它們均使用 32 位(4 個位元組),在 64 位作業系統上,它們均使用 64 位(8 個位元組)。 uintptr 存放指標 指定位元組