
基於樸素貝葉斯的定位演算法
1 定位背景介紹
一說到定位大家都會想到gps,然而gps定位有首次定位緩慢(具體可以參考之前的博文《LBS定位技術》)、室內不能使用、耗電等缺陷,這些缺陷大大限制了gps的使用。在大多數移動網際網路應用例如google地圖、百度地圖等,往往基於wifi、基站來進行定位。
一般APP在請求定位的時候會上報探測到的wifi訊號、基站訊號。以wifi為例,手機會探測到周圍各個wifi(mac地址)對應的訊號強度(RSSI),即收集到訊號向量(<WF1, RSSI1> <WF2, RSSI2> ... <WFN, RSSIN>)。服務端收到客戶端請求後會將訊號向量傳給
定位引擎工作基於兩部分:1)大規模的資料收集;2)精細的演算法模型。
如圖所示,使用者在請求app尤其是地圖類app的時候,時常會手動開啟GPS定位模式,而這時app會將收集到的基站wifi訊號以及gps定位到的座標傳送給服務端,服務端將gps定位座標(x, y)與訊號向量(<WF1, RSSI1> <WF2, RSSI2> ... <WFN, RSSIN>)關聯起來入庫。
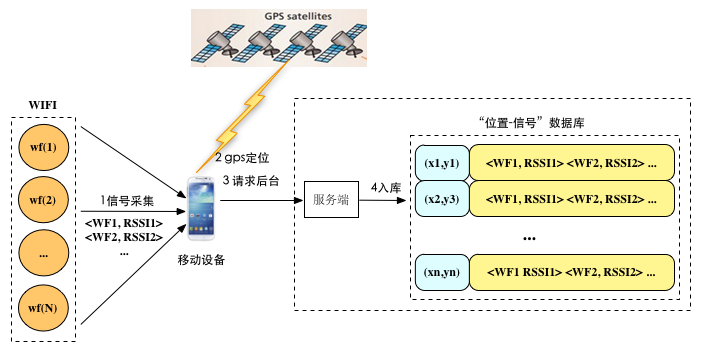
只要使用者足夠多就能快速積累
通過閱讀文獻,本文設計了一種基於樸素貝葉斯的定位模型。
2 基於樸素貝葉斯的定位模型
我們從概率的角度看待定位問題。
我們目標是計算在已知訊號向量m(<WF1, RSSI1> <WF2, RSSI2> ... <WFN, RSSIN>)的情況下,找到一處位置p使得這種情況的可能性最大,目標公式如下:
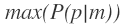
直接求解該公式非常困難,但我們可以對該公式進行貝葉斯的轉換:
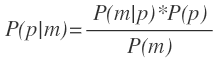
分母P(m)表示訊號向量m出現的概率,對於使用者這一次請求來說是常量,因此可以忽略,因此目標公式轉換為:
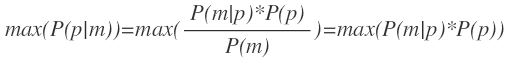
其中P(p)表示位置p出現的概率,P(m|p)表示在位置p出現訊號向量m的概率。簡化起見我們這裡假設位置p出現的概率均等(應該是不均等,比如位置在湖泊中和在市中心大街兩者出現的概率顯然不一樣,以後可以考慮使用此項)。這樣目標公式轉換為:
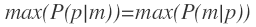
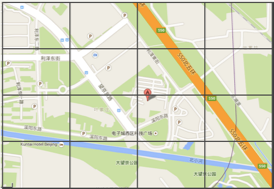
max(P(m|p))指的是在地理空間上找到一個點p,使得訊號向量m出現的概率最大。我們可以窮舉,計算空間上每一個點出現訊號向量m的概率,並找出概率最大的點。由於地理空間是二維平面,存在無窮個點,這種計算不可接受,我們可以通過對地理空間進行網格離散化來簡化計算(如下圖所示)。我們將地理空間劃分為M*N大小的網格(可以通過geohash對網格進行編碼,參考之前的博文《geohash》),因此max(P(m|p))就轉換為在地理空間找到一個網格,使得訊號向量m出現的概率最大。
如何計算某網格p出現訊號向量m的概率呢?
通過對“位置-訊號”資料庫的清洗,可以統計每一個網格出現的訊號向量的個數,即得到直方圖。

得到了網格p的訊號向量直方圖後,我們就可以求P(m|p)的概率(p點所在的格子出現訊號向量m的概率)。
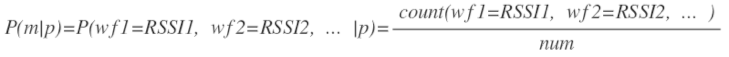
然而實際上,對訊號向量進行count幾乎不可能,儘管有很多請求百度定位的結果落在網格p內,但這些請求攜帶的訊號向量幾乎不一樣,想得到有統計意義的直方圖幾乎不可能。
因此,我們繼續對公式進行簡化,我們假設各個wifi訊號之間相互獨立,這個假設也是合理的。於是公式轉換為:
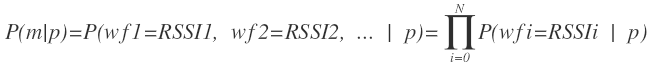
現在問題關鍵是求解P(wfi=RSSIi | p),即在網格p內,mac地址為wfi且訊號強度為RSSIi出現的概率。我們可以事先統計一個網格p內每一個wifi訊號的直方圖,這樣形成統計意義的直方圖較容易。
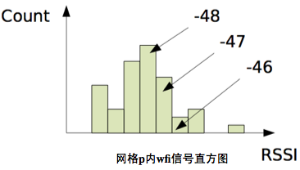
上述模型要求我們對地理空間進行網格化,並預先計算出每個網格內各個wifi對應的訊號直方圖,並進行儲存。然而在實際應用我們網格數目將會非常多,儲存直方圖的開銷較大,因此要儘可能節省網格里攜帶的資訊。因此一種思路是用高斯分佈曲線模擬直方圖,這樣對於一個網格,只需要儲存各個wifi對應的高斯分佈的幾個引數即可。
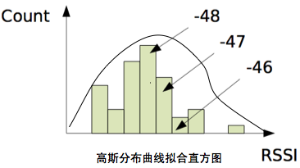
當然,每個網格的直方圖曲線並不一定都能用高斯分佈曲線來近似,一些文獻指出可能存在各種形態的曲線例如雙峰曲線等,因此也可以採用核密度估計的方法。
通過上述方法我們可以求出訊號向量m出現最大可能性的網格,並取網格的中心點座標返回即可。當然有些時候很難判別,比如我們求得A和B兩個格子的概率幾乎相等,這個時候僅僅返回A或者B就不太合適,加權插值是更為合理的選擇。一種比較魯棒的方法是我們找出topk個網格,然後進行插值。

3 問題及解決方法
1)離散網格大小如何確定?
如果網格過小,儲存量巨大,並且很多網格沒有任何訊號直方圖;如果過大,精度得不到保證。一種方法網格大小為固定值,根據實驗結果來確定網格大小;更好的方法是自適應網格大小,對於訊號較密急的地方(市區)網格設小,對於訊號稀疏的地方(郊區)網格設大。
2)當用戶請求的訊號向量裡存在一些新的mac地址對應的訊號怎麼辦?
如果直接應用下述公式進行計算,那麼得到的概率將會是0,因為我們是概率連乘,只要一項概率為0,整體結果就為0。為了去掉零概率,一個簡單的方法是採用加一平滑(add-one smoothing)或稱拉普拉斯平滑(Laplace smoothing)。
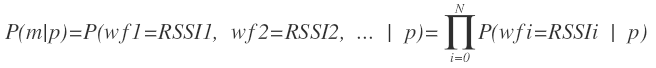
3)如何提高計算效率?
理論上使用者來一個請求,我們需要遍歷計算資料庫每個網格對應的概率,並將最大概率網格對應的中心點返回。假設我們格子是10*10米大小,那麼將北京全部網格化就有1.6億個格子,遍歷計算開銷十分巨大。
一種提高計算效率的方法是首先根據使用者的訊號向量求解出大致空間範圍,然後計算該空間範圍的每一個格子的概率。
4 參考文獻
Practical Metropolitan-Scale Positioning for GSM Phones
CellSense: A Probabilistic RSSI-based GSM Positioning System
An Improved Algorithm to Generate a Wi-Fi Fingerprint Database for Indoor Positioning
Topical Issues: Location Fingerprinting
基於區間數聚類的無線感測器網路定位方法
基於一種優化的KNN演算法在室內定位中的應用研究
相關推薦
基於樸素貝葉斯分類演算法實現垃圾郵箱分類
貝葉斯決策理論 在機器學習中,樸素貝葉斯是基於貝葉斯決策 的一種簡單形式,下面給出貝葉斯的基本公式,也是最重要的公式: 其中X是一個m*n的矩陣,m為他的樣本數,n為特徵的個數,即我們要求的是:在已知的樣本情況下的條件概率。 )表示
《機器學習實戰》基於樸素貝葉斯分類演算法構建文字分類器的Python實現
Python程式碼實現:#encoding:utf-8 from numpy import * #詞表到向量的轉換函式 def loadDataSet(): postingList = [['my','dog','has','flea','problems','help','please'],
資料探勘:基於樸素貝葉斯分類演算法的文字分類實踐
前言: 如果你想對一個陌生的文字進行分類處理,例如新聞、遊戲或是程式設計相關類別。那麼貝葉斯分類演算法應該正是你所要找的了。貝葉斯分類演算法是統計學中的一種分類方法,它利用概率論中的貝葉斯公式進行擴充套件。所以,這裡建議那些沒有概率功底或是對概率論已經忘記差不多的讀者可
基於樸素貝葉斯的定位演算法
1 定位背景介紹 一說到定位大家都會想到gps,然而gps定位有首次定位緩慢(具體可以參考之前的博文《LBS定位技術》)、室內不能使用、耗電等缺陷,這些缺陷大大限制了gps的使用。在大多數移動網際網路應用例如google地圖、百度地圖等,往往基於wifi、基站來進行定位。 一般
Python--基於樸素貝葉斯演算法的情感分類
環境 win8, python3.7, jupyter notebook 正文 什麼是情感分析?(以下引用百度百科定義) 情感分析(Sentiment analysis),又稱傾向性分析,意見抽取(Opinion extraction),意見挖掘(Opinion mining),情感挖掘(Sentiment
基於樸素貝葉斯分類器的文字分類演算法(上)
轉載請保留作者資訊: 作者:phinecos(洞庭散人) Preface 本文緣起於最近在讀的一本書-- Tom M.Mitchell的書中第6章詳細講解了貝葉斯學習的理論知識,為了將其應用到實際中來,參考了網上許多資料,從而得此文。文章將分為兩個部分,第一部分將介紹貝葉斯學習的相關理論()。第二部
樸素貝葉斯分類演算法簡單理解
樸素貝葉斯分類演算法簡單理解 貝葉斯分類是一類分類演算法的總稱,這類演算法均以貝葉斯定理為基礎,故統稱為貝葉斯分類。而樸素樸素貝葉斯分類是貝葉斯分類中最簡單,也是常見的一種分類方法。這篇文章我儘可能用直白的話語總結一下我們學習會上講到的樸素貝葉斯分類演算法,希望有利於他人理解。 1
基於樸素貝葉斯分類器的 20-news-group分類及結果對比(Python3)
之前看了很多CSDN文章,很多都是根據stack overflow 或者一些英文網站的照搬。導致我看了一整天最後一點收穫都沒有。 這個作業也借鑑了很多外文網站的幫助 但是是基於自己理解寫的,算是一個學習筆記吧。環境是python3(海外留學原因作業是英文的,渣英語見諒吧)程式碼最後附上。 M
基於樸素貝葉斯算法的情感分類
set 求最大值 記錄 變焦 def ... rop ros 結果 環境 win8, python3.7, jupyter notebook 正文 什麽是情感分析?(以下引用百度百科定義) 情感分析(Sentiment analysis),又稱傾向性分析,意見抽取(Opi
分類與監督學習,樸素貝葉斯分類演算法
1.理解分類與監督學習、聚類與無監督學習。 簡述分類與聚類的聯絡與區別。 簡述什麼是監督學習與無監督學習。 區別:分類:我們是知道這個資料集是有多少種類的,然後對它們分類歸納。比如對一個學校的在校大學生進行性別分類,我們會下意識很清楚知道分為“男”,“女”。 聚類:對資料集操作時,我們是不
機器學習--樸素貝葉斯分類演算法學習筆記
一、基於貝葉斯決策理論的分類方法 優點:在資料較少的情況下仍然有效,可以處理多類別問題。 缺點:對於輸入資料的準備方式較為敏感。 適用資料型別:標稱型資料。 現在假設有一個數據集,它由兩類資料構
kaggle | 基於樸素貝葉斯分類器的語音性別識別
概要: 本實驗基於kaggle上的一個資料集,採用樸素貝葉斯分類器,實現了通過語音識別說話人性別的功能。本文將簡要介紹這一方法的原理、程式碼實現以及在程式設計過程中需要注意的若干問題,程式碼仍然是用MATLAB寫成的。 關鍵字: MATLAB; 語音性別識別
MINIST | 基於樸素貝葉斯分類器的0-9數字手寫體識別
概要: 本實驗基於MINIST資料集,採用樸素貝葉斯分類器,實現了0-9數字手寫體的識別。本文將簡要介紹這一方法的原理、程式碼實現以及在程式設計過程中需要注意的若干問題,程式碼仍然是用MATLAB寫成的。 關鍵字: MATLAB; 影象處理; 數字手寫體識別
基於樸素貝葉斯的垃圾郵件過濾
1.文字切分 #對於一個文字字串,可以使用Python的string.split()方法將其切分 mySent = 'This book is the best book on python or M.L. I have ever laid eyes upon' word
樸素貝葉斯分類演算法python實現
1 #==================================== 2 # 輸入: 3 # 空 4 # 輸出: 5 # postingList: 文件列表 6 # classVec: 分類標籤列表 7 #===
樸素貝葉斯分類演算法
概率論只不過是把常識用數學公式表達了出來。 ——拉普拉斯 記得讀本科的時候,最喜歡到城裡的計算機書店裡面去閒逛,一逛就是好幾個小時;有一次,在書店看到一本書,名叫貝葉斯方法。當時數學系的課程還沒有學到概率統計。我心想,一個方法能夠專門寫出一本書來,肯定很牛逼。
樸素貝葉斯分類演算法原理
目錄 概述 原理 要點 1、概述 樸素貝葉斯分類演算法是貝葉斯分類演算法中最簡單的一種,貝葉斯分類演算法以樣本可能屬於某類的概率來作為分類依據。貝葉斯分類演算法是一大類分類演算法的總稱。 2、原理 如果一個事物在一些屬性條件發生的情況下,事物屬於A的概率大於
一步步教你輕鬆學樸素貝葉斯模型演算法理論篇1
導讀:樸素貝葉斯模型是機器學習常用的模型演算法之一,其在文字分類方面簡單易行,且取得不錯的分類效果。所以很受歡迎,對於樸素貝葉斯的學習,本文首先介紹理論知識即樸素貝葉斯相關概念和公式推導,為了加深理解,採用一個維基百科上面性別分類例子進行形式化描述。然後通過程式設計實現樸素貝葉斯分類演算法,並在遮蔽社
貝葉斯公式和樸素貝葉斯分類演算法
先上問題吧,我們統計了14天的氣象資料(指標包括outlook,temperature,humidity,windy),並已知這些天氣是否打球(play)。如果給出新一天的氣象指標資料:sunny,cool,high,TRUE,判斷一下會不會去打球。 table 1 outlook temperat
基於樸素貝葉斯的關於網際網路金融新聞分類(python實現)
中國網際網路金融發展迅速,2014年是中國網際網路金融起步的一年,但在短短的一年時間內,網際網路金融創業者們融資額度一再創高,雨後春筍般湧現出各類網際網路金融產品讓使用者眼花繚亂,隨著創業門檻的降低,在即將到來的2015年,網際網路金融必將在中國掀起熱潮。