
Linux 伺服器監控
概述
文字主要講述使用linux自帶的幾個命令監控io、CPU、磁碟、記憶體、伺服器整體資訊等。
IO監控
iostat命令
主要用於監控系統裝置的IO負載情況
檢視命令幫助
iostat --help [ -c ] [ -d ] [ -N ] [ -n ] [ -h ] [ -k | -m ] [ -t ] [ -V ] [ -x ] [ -z ][ <裝置> [...] | ALL ] [ -p [ <裝置> [,...] | ALL ] ]
iostat
Linux 2.6.32-71.el6.x86_64 (localhost.localdomain) 2015年12月24日 _x86_64_(1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
1.98 0.00 0.80 3.04 0.00 94.18
%user:程序處於使用者狀態所佔CPU時間百分比
%nice: 改變過優先順序的程序的佔用CPU的百分比.
%system:程序處於核心狀態所佔CPU時間百分比
%iowait:CPU等等IO操作所佔用的CPU百分比,當磁碟IO比較大的時候該值會增加。
%steal:分配給虛擬機器佔用的CPU百分比
%idle:CPU空閒時間的百分比
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 17.78 128.39 1107.66 9968098 86000772
tps: 每秒鐘傳送到的I/O請求數(可以理解成每秒磁碟IO處理的請求,這樣可能更好理解)Blk_read /s: 每秒讀取的block數Blk_wrtn/s: 每秒寫入的block數
Blk_read: 讀入的block總數
Blk_wrtn: 寫入的block總數
-c引數:
分成CPU的狀態,也就是上面的CPU部分
-d引數
分析磁碟裝置狀態,也就是上面的Device部分。
-n引數
分析檔案系統的狀態
Filesystem: rBlk_nor/s wBlk_nor/s rBlk_dir/s wBlk_dir/s rBlk_svr/s wBlk_svr/s ops/s rops/s wops/s
[-N或者-h]引數
和直接執行iostat的區別主要是device部分,這裡顯示的是裝置每秒的讀寫、讀寫位元組情況,預設是kB
avg-cpu: %user %nice %system %iowait %steal %idle
2.06 0.00 0.82 3.09 0.00 94.03
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 18.20 65.63 556.45 5169933 43834154
kB_read/s:每秒從裝置讀的KB數
kB_wrtn/s:每秒寫入裝置的KB數
kB_read:每秒從裝置讀的KB位元組
kB_wrtn:每秒寫入裝置的KB位元組
[ -k | -m ]引數
是單位,分別是KB和MB,預設單位是KB,用來做磁碟分析的時候使用
例如iostat -d -M(以MB作為單位顯示)
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 18.65 0.06 0.55 5102 43654
-t引數
顯示的時候打印出時間
2015年12月24日 09時39分31秒
avg-cpu: %user %nice %system %iowait %steal %idle
2.07 0.00 0.83 3.17 0.00 93.94
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 18.59 131.96 1128.88 10450530 89403980
[-v或-Z]引數
暫時沒發現什麼特別的功能
-x引數
最詳細的顯示CPU和裝置資訊
avg-cpu: %user %nice %system %iowait %steal %idle
2.06 0.00 0.83 3.16 0.00 93.96
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 1.58 125.86 2.49 16.04 131.51 1124.71 67.80 0.41 22.29 2.69 4.98
其中CPU部分沒有什麼變化,這裡主要來看device部分:
rrqm/s:將讀入請求合併後,每秒傳送到裝置的讀入請求數.
wrqm/s:將寫入請求合併後,每秒傳送到裝置的寫入請求數.
r/s:每秒傳送到裝置的讀入請求數.
w/s:每秒傳送到裝置的寫入請求數.
rsec/s:每秒從裝置讀入的扇區數.
wsec/s:每秒向裝置寫入的扇區數.
rkB/s:每秒從裝置讀入的資料量,單位為K.
wkB/s:每秒向裝置寫入的資料量,單位為K.
avgrq-sz:傳送到裝置的請求的平均大小,單位是扇區.
avgqu-sz:傳送到裝置的請求的平均佇列長度.
await:I/O請求平均執行時間.包括髮送請求和執行的時間.單位是毫秒.
svctm:傳送到裝置的I/O請求的平均執行時間.單位是毫秒.
%uti:在I/O請求傳送到裝置期間,佔用CPU時間的百分比.用於顯示裝置的頻寬利用率.
當這個值接近100%時,表示裝置頻寬已經佔滿.
-P引數
分析指定的裝置:例如sda,sdb
iostat -p sda
avg-cpu: %user %nice %system %iowait %steal %idle
2.05 0.00 0.82 3.13 0.00 93.99
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 18.40 130.78 1116.56 10472250 89406772
sda1 0.01 0.07 0.00 5232 28
sda2 16.72 118.34 1089.36 9476202 87228408
sda3 0.36 12.36 27.20 989616 2178336
常見的用法:
顯示裝置和CPU狀態,每秒列印一次,並顯示時間
iostat -x -k -t 1
顯示裝置和CPU狀態,每秒顯示一次,顯示10次,並顯示時間
iostat -x -k -t 1 10
顯示裝置sda和CPU狀態,每秒顯示一次,顯示10次,並顯示時間
iostat -x -k -t -p sda 1 10
CPU監控
mpstat
mpstat命令主要用來分析CPU的效能,並且可以分析單個cpu的效能狀態。
mpstat -P ALL
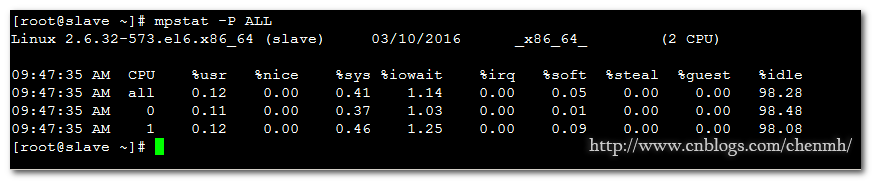
%user:程序處於使用者狀態所佔CPU時間百分比
%nice: 改變過優先順序的程序的佔用CPU的百分比.
%system:程序處於核心狀態所佔CPU時間百分比
%iowait:CPU等等IO操作所佔用的CPU百分比,當磁碟IO比較大的時候該值會增加。
%steal:分配給虛擬機器佔用的CPU百分比
%idle:CPU空閒時間的百分比
記憶體監控
free命令
free total used free shared buffers cached Mem: 32830608 32501660 328948 0 285540 10956472 -/+ buffers/cache: 21259648 11570960 Swap: 16383992 216520 16167472
free:記憶體中剩餘未被使用的空間大小
buffers:檔案快取大小,linux本身就是一個檔案型系統,所以linux會為每個檔案進行快取用來加速檔案的查詢。
cached:頁快取,所有以頁為單位的快取都會被快取到這來,所以從這裡其實也可以大概看出伺服器的記憶體使用情況,因為大部分的記憶體都是以頁進行快取的
total=used+free
total=(-buffers/cache)+(+buffers/cache)
-/+ buffers/cache:反應的是記憶體的實際使用情況
-buffers/cache:21259648=used-buffers-cached,這部分也是真正被使用掉的記憶體
+buffers/cache:11570960=(free+buffers+cached),這部分是可以直接拿來用的記憶體,所以看記憶體的剩餘可用情況可以參考+buffers/cache
檢視檔案/etc/proc/ meminfo
注意:還需要關注swap:used,如果swap:used使用很高那麼可能需要考慮記憶體是否夠用。
磁碟監控
df命令
檢視檔案cat /etc/proc/diskstats
程序監控
top命令
例:檢視mysql使用者程序
top -u mysql
top - 11:45:50 up 1 day, 23:39, 1 user, load average: 0.04, 0.01, 0.00 Tasks: 185 total, 2 running, 183 sleeping, 0 stopped, 0 zombie Cpu(s): 0.1%us, 0.2%sy, 0.0%ni, 99.5%id, 0.1%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 32864496k total, 4749428k used, 28115068k free, 167268k buffers Swap: 1048572k total, 0k used, 1048572k free, 259776k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2285 mysql 20 0 27.5g 3.8g 8236 S 0.3 12.1 7:56.92 mysqld
top這行資訊可以參考下面的uptime的解釋。load average分別表示5分鐘內的、10分鐘內的、15分鐘內排隊的程序數,只要第一個數字即5分鐘內的負載不大於5,系統就是健康的
tasks:185個程序總數,2個正在執行的程序,183個睡眠的程序,0個停止的程序,0個殭屍程序
cpu:0.1%us(使用者佔用), 0.2%sy(系統佔用), 0.0%ni, 99.5%id(空閒), 0.1%wa(等待輸入輸出的CPU時間百分比), 0.0%hi, 0.0%si, 0.0%st
Mem: 32864496k total(總記憶體), 4749428k used(已使用記憶體), 28115068k free(未使用的記憶體), 167268k buffers(核心快取)
Swap: 1048572k total(交換區總大小), 0k used(已使用), 1048572k free(未使用), 259776k cached(緩衝的交換區總量)
PID:程序ID
USER:使用者
PR:優先順序
NI:nice值。負值表示高優先順序,正值表示低優先順序
S:程序狀態(R:執行,S:睡眠,T:停止,Z:殭屍程序,D:不可中斷的睡眠狀態)
%CPU:佔用的CPU百分比
%MEM:佔用的記憶體百分比
TIME+:累計佔用的CPU時間
COMMAND:命令
程序資訊只列舉了一些重要的欄位,其它的欄位如果想了解可以去檢視資料。
這裡有每個程序的檔案:/etc/proc
注意:在top裡面除了關注每個程序的記憶體使用情況,還需要關注的就是{load average: 0.04, 0.01, 0.00}程序負載情況。
系統負載
uptime命令
10:18:23 up 22:43, 3 users, load average: 0.00, 0.00, 0.79
- 當前時間 10:18:23
- 系統已執行的時間 22小時43分鐘
- 當前線上使用者 3 user
- 平均負載:0.00, 0.00, 0.79最近1分鐘、5分鐘、15分鐘系統的負載
檢視檔案
cat /proc/loadavg
0.00 0.00 0.70 1/317 41562
除了前3個數字表示平均程序數量外,後面的1個分數,分母表示系統程序總數,分子表示正在執行的程序數;最後一個數字表示最近執行的程序ID
系統平均負載被定義為在特定時間間隔內執行佇列中的平均程序數。如果一個程序滿足以下條件則其就會位於執行佇列中:
- 它沒有在等待I/O操作的結果
- 它沒有主動進入等待狀態(也就是沒有呼叫'wait')
- 沒有被停止(例如:等待終止)
一般來說,每個CPU核心當前活動程序數不大於3,則系統執行表現良好!當然這裡說的是每個cpu核心,也就是如果你的主機是四核cpu的話,那麼只要uptime最後輸出的一串字元數值小於12即表示系統負載不是很嚴重.當然如果達到20,那就表示當前系統負載非常嚴重,估計開啟執行web指令碼非常緩慢.
uptime部分摘自:http://www.cnblogs.com/kaituorensheng/p/3602812.html
vmstat命令
該命令可以用來分析整個伺服器的基本情況,包括記憶體、交換分割槽、IO、system、cpu
vmstat

網路流量監控
可以使用nload工具來做網路流量監控,該工具可以動態的顯示流入和流出的網路流量
yum -y install nload

其它:
1.程序磁碟io寫入分析查詢
iotop命令
安裝方法1:
yum -y install iotop
安裝方法2:
wget http://guichaz.free.fr/iotop/files/iotop-0.4.4.tar.gz tar zxf iotop-0.4.4.tar.gz python setup.py build python setup.py install
總結
linux系統自帶的這幾個命令做為日常監控使用還是挺不錯的,當然還有很多第三方工具也很不錯,比如監控IO的dstat工具,後面有時間會單獨講一下dstat工具的使用。
|
備註: 本站點所有隨筆都是原創,歡迎大家轉載;但轉載時必須註明文章來源,且在文章開頭明顯處給明連結,否則保留追究責任的權利。 《歡迎交流討論》 |
相關推薦
深入進階02 - linux伺服器監控效能測試
Linux 命令 man ls man是檢視幫助命令
Linux 伺服器監控
概述 文字主要講述使用linux自帶的幾個命令監控io、CPU、磁碟、記憶體、伺服器整體資訊等。 IO監控 iostat命令 主要用於監控系統裝置的IO負載情況 檢視命令幫助 iostat --help [ -c ] [ -d ] [ -N ] [ -n ] [ -h ]
Linux常用監控伺服器效能命令
列舉比較常用的幾種監控伺服器效能的Linux命令。其實,在我看來,目前針對Linux系統記憶體、硬碟、TCP/IP等等相關的指標,Linux本身自帶的或者是一些開源專案等基本上都能達到這個獲取伺服器效能資訊的目的。看著這麼多,讀者也許會眼花繚亂,個人給個建議,建議弄明白Linux自帶的top、free及其相關
實時監控linux伺服器網絡卡流量命令 iftop
iftop是類似於linux下面top的實時流量監控工具。 iftop可以用來監控網絡卡的實時流量(可以指定網段)、反向解析IP、顯示埠資訊等,詳細的將會在後面的使用引數中說明。 yum install -y iftop iftop 介面說明 介面頭部: 流量刻度
linux伺服器系統資源監控
> 1.檢視記憶體使用情況 free -g linux系統很卡的基本排查方法介紹 當觀察到free欄已為0的時候,表示記憶體基本被吃完了,那就釋放記憶體吧。 釋放記憶體: sync echo 3 > /proc/sys/vm/drop_caches sync表示將記憶體快取區
Zabbix批量新增linux伺服器埠監控
我們在監控生產環境的服務的時候,通常需要對多個埠進行監控,如果我們手動的一個一個的新增,這回讓我們崩潰,所以批量新增埠監控是一個非常常見的需求,當然這對於zabbix來說肯定是支援的,需要使用zabbix的Discovery功能來實現,下面就給大家分享一下批量新增埠的佔用。 第一:自動掃描埠
jprofile 監控遠端linux伺服器上tomcat 效能配置
前提條件: 1. 測試環境 伺服器:Linux X64;tomcat 7.0;jdk 1.7;jprofiler_linux_9_2.sh 客戶端:Windows10;jprofiler_windows-x64_9_2.exe 2. JProfiler軟體下載
Linux伺服器---流量監控bandwidthd
Bandwidthd Bandwidthd是一款免費的流量監控軟體,它可以用圖示的方式展現出網路流量行為,並且可區分出ftp、tcp等各種協議的流量。 1、安裝一些依賴軟體 [[email protected]
Linux伺服器---流量監控MRTG
MRTG MRTG可以分析網路流量,但是它必須依賴SNMP協議。將收集到的資料生成HTML檔案,以圖片的形式展示出來 1、安裝一些依賴軟體 [[email protected] bandwidthd-2.0.1]# yum install -y net-s
Linux伺服器上監控網路頻寬的18個常用命令
一些命令可以顯示單個程序所使用的頻寬。這樣一來,使用者很容易發現過度使用網路頻寬的某個程序。這些工具使用不同的機制來製作流量報告。nload等一些工具可以讀取"proc/net/dev"檔案,以獲得流量統計資訊;而一些工具使用pcap庫來捕獲所有資料包,然後計算總資料量,從而估計流量負載。下面是按功能劃分的命
Linux伺服器---流量監控webalizer
webalize webzlizer是一個免費的web server分析工具,它能夠分析apache、ftp等日誌,將結果以html形式展示。 1、安裝一些依賴軟體 [[email protected] band
效能測試篇(2)-監控Linux伺服器資源
1、用root賬號登入系統; 2、建立目錄 #mkdir /test,也可直接在上傳工具中建立資料夾; 3、把nmon上傳到test目錄下,也可直接上傳要用的nmon檔案,但是要搞清楚是幾位的系統,例如64位的系統應上傳64位的即nmon_x86_64_centos6;若傳
linux伺服器硬體資源指標、jvm監控 、儲存資料庫、redis監控
linux 監控命令 nmon dstat top iostat vmstat iftop iotop lsof netstat 伺服器硬體資源指標(cpu、記憶體、磁碟、網路) dstat top iotop iostat vmstat Iostat/iotop:
linux伺服器記憶體監控-shell指令碼
前提:伺服器能上網際網路(ping),就可通過發郵件的方式來提醒管理員系統記憶體的使用情況。 第一步:安裝linux下面的一個郵件客戶端msmtp軟體(類似於一個foxmail的工具) 2、建立msmtp配置檔案和日誌檔案(host為郵件域名,郵件使用者名稱tes
遠端監控Linux伺服器上的tomcat的JDK狀況
1.查詢JDK安裝目錄: echo $JAVA_HOME 2.在%JAVA_HOME%/jre/lib/management目錄下,找到jmxremote.password.template,並複製一份命名為jmxremote.password: cp jmxremote.
linux web監控伺服器資源工具 netdata
具體的netdata介紹請參照GIT:https://github.com/firehol/netdata/wiki 以下只介紹centos下的netdata的安裝與使用: 1、安裝Netdata需要的基本編譯環境安裝: yum install zlib-devel gcc
java實現Linux伺服器記憶體監控預警
1.需求場景 利用java程式監控Linux伺服器記憶體變化,根據設定的記憶體閾值發報警郵件 2.專案環境 普通java專案,jar形式 3.解決方法 (1)讀取Linux 記憶體監控檔案(/proc/meminfo),獲取記憶體資訊。 public static
如何監控 Linux 伺服器狀態?
Linux 伺服器我們天天打交道,特別是 Linux 工程師更是如此。為了保證伺服器的安全與效能,我們經常需要監控伺服器的一些狀態,以保證工作能順利開展。 本文介紹的幾個命令,不僅僅適用於伺服器監控,也適用於我們日常情況下的開發。 #### 1. watch watch 命令我們的使用頻率很高,它的基本
Linux 系統監控 硬盤分區及格式化
所在 占用 disk str 性能 多個進程 buffer 使用情況 alt top linux系統中性能分析工具,實時顯示系統中各個進程的資源占用情況,類似windows中的資源管理器。 free命令 顯示內存的使用情況,total,used,free,b
linux系統監控與硬盤分區/格式化/文件系統管理
時間 運行 輸入 -c 進程pid 死循環 running ddl 變慢 1.系統監控 1) 系統監視和進程控制的工具----> Top 與 free 類似於windows的資源管理器。 進程運行的三種狀態: tips: 進程(Proce