
MySQL InnoDB儲存引擎
介紹
本篇文章是對Innodb儲存引擎的概念進行一個整體的概括,innodb儲存引擎的概念是mysql資料庫中最關鍵的幾個概念之一,涉及的內容非常的廣;由於個人的理解能力有限如果有不對的地方還見諒。

MySQL對應InnoDB版本
MySQL 5.1》InnoDB 1.0.X
MySQL 5.5》InnoDB 1.1.X
MySQL 5.6》InnoDB 1.2.X
後臺執行緒
1.Master Thread
負責將緩衝池中的資料非同步重新整理到磁碟,保證資料的一致性;包括重新整理髒頁、合併插入緩衝、undo頁的回收。
2.IO Thread
innodb儲存引擎中大量使用了AIO(Async IO)來處理寫IO請求來提高資料庫的併發效能,共有四類IO執行緒,分別是:insert buffer thread、log thread、read thread、write thread。其中read thread和write thread分別有四個執行緒,可以通過innodb_read_io_threads和innodb_write_io_threads來配置。
SHOW VARIABLES LIKE 'innodb_%io_threads' 或者 SHOW ENGINE INNODB STATUS \G;
3.Purge Thread執行緒
purge Thread執行緒用來回收事務提交後其被分配的undo頁,預設是開啟的,可以通過innodb_purge_threads=1配置多個Purge Thread執行緒。
show variables like 'innodb_purge_threads';
配置2個Purge thread,只能修改配置檔案配置,不能線上修改
innodb_purge_threads=2
4.Page Cleaner Thread
用於多版本控制功能中回收delete和update操作產生的髒頁,用來執行將髒頁重新整理到磁碟。
5.Binlog Dump執行緒
當配置了複製後,會在主伺服器生成一個binlog Dump執行緒來讀取二進位制修改記錄。
6.lock執行緒
用於鎖控制和死鎖檢測
記憶體
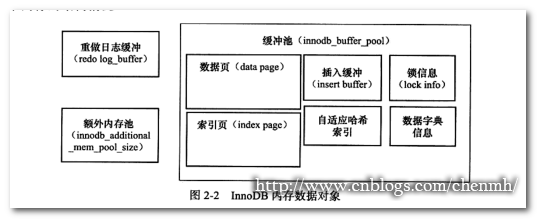
不要理解以為記憶體中就只有innodb buffer,還包括重做日誌緩衝、額外的記憶體池(目前還不知道比如join buffer、order buffer、key buffer、table cache buffer等是在緩衝池內部還是獨立於緩衝池在記憶體中)
1.快取池
快取的資料主要有資料頁、索引頁、重做日誌頁(undolog)、節點資訊、系統資料、插入緩衝、自適應雜湊索引、資料字典、鎖資訊等
檢視緩衝池的大小,單位位元組,轉化為MB需要/1024/1024 show variables like 'innodb_buffer_pool_size';
預設innodb有8個緩衝池,可以通過配置innodb_buffer_pool_instances
查詢
show engine innodb status \G;
或者
SELECT * FROM information_schema.innodb_buffer_pool_status;
讀操作:
資料是以頁為儲存單位,在緩衝池中快取了很多資料頁,當第一次讀取時首先將頁從磁碟讀取到快取池中,當下一次再去讀相同的資料頁時如果該也在快取池中就直接從緩衝池中讀取而不需要再去磁碟讀,最理想的方式是將所有的磁碟資料都快取到緩衝池中但是這得記憶體足夠大才行。
修改操作
innodb儲存引擎對資料的修改也是先修改緩衝池中的資料頁(如果存在),然後根據一定的頻率重新整理到磁碟來修改資料檔案,這涉及到checkpoint機制,
插入操作(insert buffer)
因為資料是按照聚集索引的順序排列的,所有針對聚集索引的插入一般會非常快,而非聚集索引的插入就不一定是順序的,這個時候需要離散的訪問非聚集索引頁,插入的效能往往會很差,有一種情況可能例外就是非聚集索引的時間欄位,而時間往往是順序的,這種情況會比較快,針對非聚集索引的這種情況就引入了插入緩衝。
innodb中引入了插入緩衝(insert buffer),insert buffer只針不唯一的非聚集索引,對於非聚集索引的插入和更新操作不是每次直接插入到索引檔案中,而是先判斷插入的非聚集索引頁是否存在緩衝池中,如果存在則直接插入緩衝池的非聚集索引檔案中,否則先放入到一個insert buffer物件當中,但是給人的感覺它已經插入到了索引檔案中,但是實際並沒有,然後再以一定的頻率插入到索引檔案當中,在這個過程中如果存在多個相同的索引頁的插入會合並插入,大大的提高了非聚集索引的插入效能,
因為每次插入是先插入到緩衝池當中不去查詢索引頁來判斷記錄的唯一性,因為去做判斷需要去離散查詢,所以插入緩衝不針對唯一性的非聚集索引。
在密集寫操作的情況下,插入緩衝會佔用過多的緩衝池的記憶體,預設最大可以佔到50%,原始碼中的IBUF_POOL_SIZE_PER_MAX_SIZE=2,如果將其修改為3,則最大隻能使用1/3的緩衝池的記憶體。
2.LRU List、Free List、Flush List
innodb緩衝池中的頁預設大小為16KB,緩衝池通過LRU(Latest Recent Used 最新少使用)演算法來進行管理,將最頻繁的使用的頁放在LRU列表的前端,而最近少使用的頁放在尾端,當快取池中的空間不足的時會先刪除尾端的頁來釋放空間。LRU有一個midpoint位置,預設在LRU的37%的位置,左邊表示old列表,右邊表示new列表(熱點資料),新插入緩衝池中的頁先放在midpoint的位置,如果新插入的頁一來就移動到new列表的話可能會導致new列表中的某些活動也被移除到old列表中,比如表掃描操作一次性可能需要訪問很多的資料頁而這些資料頁可能以後很少被使用,新插入的頁何時才會被被放入new列表中呢,為了解決這個問題innodb引入了innodb_old_blocks_time引數,該引數用來控制新插入的資料頁在mid位置多久後才被加入到new列表中。
檢視midpoint的位置,如果覺得熱點資料空間需要更多可以將該值設小 show variables like 'innodb_old_blocks_pct'
查詢innodb_old_blocks_time值,單位毫秒,預設是1000毫秒即1秒
show variables like 'innodb_old_blocks_time'
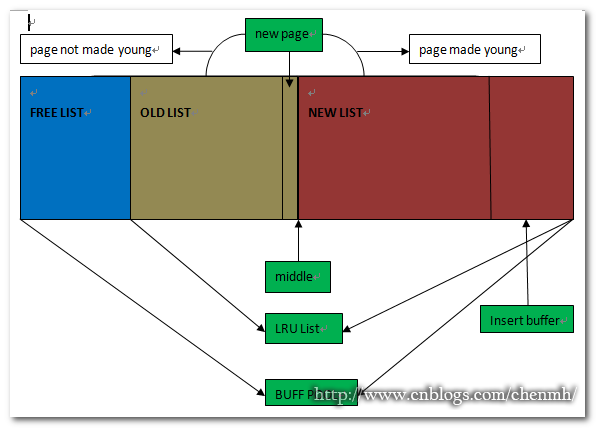
檢視緩衝池中所有頁的資訊,包括空閒頁,所有的資料頁*16KB其實也就是緩衝池的總大小. select * from information_schema.INNODB_BUFFER_PAGE; 檢視LUR列表的資訊,包括new list和old list但是不包括free list,表中的欄位記錄了當前的資料頁的資訊,包括緩衝池ID,頁的型別(資料頁、索引頁、undo log、other),表名,索引名,是否是old list的頁,是否屬於壓縮頁(可以將原本16K的頁壓縮為1K、2K、4K、8K),壓縮頁的大小,是否屬於髒頁。 select POOL_ID,LRU_POSITION,SPACE,PAGE_TYPE,FLUSH_TYPE,NEWEST_MODIFICATION,OLDEST_MODIFICATION,INDEX_NAME,DATA_SIZE,COMPRESSED_SIZE,COMPRESSED,IS_OLD from information_schema.INNODB_BUFFER_PAGE_LRU;
OLDEST_MODIFICATION>0表示髒頁的數量也就是(modified db pages)
IS_OLD='YES'代表OLD List頁
COMPRESSED<>0代表壓縮頁
flush list:值的就是LRU中的髒頁,flust list存在於New List中,即OLDEST_MODIFICATION>0(modified db pages)
3.日誌緩衝(log buffer):對應innodb日誌檔案
檢視重做日誌緩衝 show variables like 'innodb_log_buffer_size%';
InnoDB儲存引擎首先將重做日誌資訊先放入到重做日誌緩衝中,然後按照一定的頻率將其重新整理到重做日誌檔案當中。預設緩衝大小是8M,8M基本可以滿足需求,不需要配置太大的重做日誌緩衝。
重新整理機制:
1.Master Thread 每一秒將重做日誌緩衝重新整理到重做日誌檔案;
2.每個事務提交時會將重做日誌緩衝重新整理到重做日誌檔案;
3.當重做日誌緩衝池剩餘空間小於1/2時
注意:innodb_log_buffer_size的大小應該要比最大的事務大小要打,否則事務還未提交innodb_log_buffer_size就已經寫滿就需要進行重新整理操作,會造成一個事務需要多次進行磁碟日誌重新整理操作,導致效率低。
4.額外的記憶體
平時我們的伺服器MySQL程序所使用的記憶體會比配置的InnoDB緩衝池的記憶體要大,那是因為MySQL除了緩衝池中快取的記憶體額外還需要一部分記憶體用來控制緩衝池內部的一些資源資訊,比如LRU、鎖資源、等待等。
CheckPoint機制
為了解決CPU和磁碟直接速度的問題採用了緩衝池,所以對資料的操作都是先在緩衝池中完成,緩衝池中的資料頁往往比磁碟上的資料頁要新,我們將在緩衝池中已經修改但是還未應用到磁碟的資料頁叫“髒頁”,資料頁最終還是需要更新到磁碟中,中間會涉及到CheckPoint機制。
同時為了解決因為突然伺服器停機導致緩衝池中還未來得及重新整理到磁碟的髒頁丟失的問題,加入了重做日誌檔案(重做日誌檔案預設是配置2個,預設名稱是ib_logfile開頭,重做日誌檔案預設大小是48M,兩個重做日誌檔案採取迴圈寫的方式),當事務提交時先寫重做日誌,當發生伺服器停機後可以通過重做日誌來完成恢復(伺服器重啟之後自己預設會恢復),所以得保證重做日誌檔案有剩餘空間,預設機制是當重做日誌檔案空間達到75%-90%時就重新整理一部分髒頁到磁碟同時清空對應的重做日誌空間。
每次重新整理多少頁到磁碟:
Sharp Checkpoint:資料庫關閉時將所有髒頁都重新整理回磁碟,預設方式,引數:innodb_fast_shutdown=1
Fuzzy Checkpoint:重新整理部分髒頁,具體分為以下四種情況
1.Master Thread Checkpoint
Master Thread每隔幾秒鐘從緩衝池中將髒頁重新整理回磁碟
2.FLUSH_LRU_LIST CheckPoint
在5.6版本之後需要保證LRU預設存在1024個可用頁,如果可用頁不足1024頁重新整理部分髒頁回磁碟,通過引數“innodb_lru_scan_dapth”配置。
3.Async/Sync Flush Checkpoint
指的是因為重做日誌檔案空間不足導致的同步或非同步重新整理髒頁回磁碟,當重做日誌空間已使用的空間達到75%-90%就觸發非同步重新整理,如果超過90%就觸發同步重新整理,一般不會觸發同步重新整理操作,除非重做日誌檔案太小並且進行LOAD DATA的BULK INSERT操作。
4.Dirty Page too much
保證緩衝池中髒頁的比例,當緩衝池中的髒頁比例達到75%時就觸發重新整理髒頁操作,通過引數“innodb_max_dirty_pages_pct”配置。
總結
innodb儲存引擎的概念非常的多,隨便一個知識點都不止一篇文章可以寫下,所以本篇只是會整體做一個描述後面會針對每一個知識點進行更細的分析。
|
備註: 本站點所有隨筆都是原創,歡迎大家轉載;但轉載時必須註明文章來源,且在文章開頭明顯處給明連結。 《歡迎交流討論》 |
相關推薦
MySQL InnoDB儲存引擎:事務實現
事務基礎知識 1、事務ACID特性: Atomic(原子性): 事務要麼成功,要麼失敗。 Consistency(一致性): 事務會把資料庫從一種一致狀態轉換為另一種一致狀態。 &
MySQL Innodb儲存引擎:索引
1,Innodb儲存引擎索引的使用的B+樹索引本身並不能找到具體的一條記錄,能找到只是該記錄所在的頁。然後資料庫通過把頁讀入到記憶體,再在記憶體中進行查詢,最後得到要查詢的資料。 B+樹的葉子節點是資料頁。頁中有多條記錄。 2、B+樹特點:所有記錄節點都是按鍵值的大小順序存放在同一層的葉
MySQL InnoDB儲存引擎體系架構 —— 索引高階
眾所周知,在MySQL的InnoDB引擎,為了提高查詢速度,可以在欄位上新增索引,索引就像一本書的目錄,通過目錄來定位書中的內容在哪一頁。 InnoDB支援的索引有如下幾種: B+樹索引 全文索引 雜湊索引 筆者上一篇文
談談MySQL InnoDB儲存引擎事務的ACID特性
在執行purge過程中,InnoDB儲存引擎首先從history list中找到第一個需要被清理的記錄,這裡為trx1,清理之後InnoDB儲存引擎會在trx1所在的Undo page中繼續尋找是否存在可以被清理的記錄,這裡會找到事務trx3,接著找到trx5,但是發現trx5被其他事務所引用而不能清理,故再
Mysql-InnoDB儲存引擎中-鎖介紹
最近資料庫的學習都是基於InnoDB儲存引擎的,這一篇去學習第6章鎖的部分。之前有一篇是關於資料庫ACID是基於什麼保證的,ACD都分析過了,今天關於I-隔離性資料庫中是基於鎖來保證的。1. lock 和latchlatch主要保證併發執行緒操作臨界資源的正確性,沒有死鎖檢測
MySQL InnoDB儲存引擎
介紹 本篇文章是對Innodb儲存引擎的概念進行一個整體的概括,innodb儲存引擎的概念是mysql資料庫中最關鍵的幾個概念之一,涉及的內容非常的廣;由於個人的理解能力有限如果有不對的地方還見諒。 MySQL對應InnoDB版本 MySQL 5.1》InnoDB 1.0.X M
MySQL InnoDB儲存引擎 聚集和非聚集索引
B+樹索引 索引的目的在於提高查詢效率,可以類比字典,如果要查“mysql”這個單詞,我們肯定需要定位到m字母,然後從下往下找到y字母,再找到剩下的sql。如果沒有索引,那麼你可能需要把所有單詞看一遍才能找到你想要的,如果我想找到m開頭的單詞呢?或者ze開頭的
MySQL InnoDB儲存引擎之表(一)
主要介紹InnoDB儲存引擎表的邏輯儲存以及實現。重點介紹資料在表中是如何組織和存放的。 1.索引組織表(index organized table) 在InnoDB儲存引擎中,表都是根據主鍵順序組織存放的,這種儲存方式的表叫索引組織表。在InnoDB存在引擎表中,
MySql Innodb儲存引擎--鎖和事務
lock和latch的比較latch 一般稱為閂鎖(輕量級的鎖) 因為其要求鎖定的時間非常短,若遲勳時間長,則應用效能非常差,在InnoDB儲存引擎中,latch有可以分為mutex(互斥鎖)和rwlock(讀寫鎖)其目的用來保證併發執行緒操作臨界資源的正確性,並且沒有死鎖檢
MySQL InnoDB儲存引擎隔離級別及髒讀、不重複讀、幻讀
前記: ORACLE不支援Read Uncommitted和Repeatable Read事務隔離級別; InnoDB預設是RR,使用Next-Key Lock演算法避免幻讀,達到Serializable隔離級別; 隔離級別越低,事務請求所越少或保持鎖的時間越短;
探祕MySQL InnoDB 儲存引擎
浪費了“黃金五年”的Java程式設計師,還有救嗎? >>>
MySQL InnoDB 儲存引擎原理淺析
版權說明: 本文章版權歸本人及部落格園共同所有,轉載請標明原文出處( https://www.cnblogs.com/mikevictor07/p/12013507.html ),以下內容為個人理解,僅供參考。 前言: 本文主要基於MySQL 5.6以後版本編
MySQL技術內幕 InnoDB儲存引擎:一致性鎖定讀
在前一小節中講到,在預設配置下,即事務的隔離級別為 REPEATABLE READ 模式下, InnoDB 儲存引擎的 SELECT 操作使用一致性非鎖定讀。但是在某些情況下,使用者需要顯式地對資料庫讀取操作進行加鎖以保證資料邏輯的一致性。而這要求資料庫支援加鎖語句,即使是對於SELEC
MySQL技術內幕 InnoDB儲存引擎:一致性非鎖定讀
一致性的非鎖定行讀(consistent nonlocking read)是指InnoDB儲存引擎通過行多版本控制(multi versioning)的方式來讀取當前執行時間資料庫中行的資料。如果讀取的行正在執行DELETE、UPDATE操作,這是讀取操作不會因此而會等待行上鎖的釋放,相
MySQL技術內幕 InnoDB儲存引擎:B+樹索引的使用
1、聯合索引 MySQL允許對錶上的多個列進行索引,聯合索引的建立方法與單個索引建立的方法一樣,不同之處僅在於有多個索引列。 CREATE TABLE t( a INT, b INT, PRIMARY KEY(a), KEY idx_a_b(a, b) )ENGINE=InnoD
MySQL技術內幕 InnoDB儲存引擎:Cardinality
並不是所有在查詢條件中出現的列都需要新增索引,對於什麼時候新增B+樹索引,一般的經驗是,在訪問表中很少一部分行是使用B+樹索引才有意義。檢視索引是否是高選擇性的,可以通過SHOW INDEX語句中的Cardinality列來觀察。Cardinality是一個估計值,在實際中,Cardin
MySQL技術內幕 InnoDB儲存引擎:B+樹索引
B+ 樹索引並不能找到一個給定鍵值的具體行。 B+ 樹索引能找到的只是被查詢資料所在的頁。 然後資料庫通過把頁讀入到記憶體, 再在記憶體中進行查詢, 最後得到要查詢的資料。 平衡二叉樹 平衡二叉樹的定義如下:首先符合二叉查詢樹的定義,其次必須滿足任何節點的兩個字數的
MySQL技術內幕 InnoDB儲存引擎:分割槽表
一、MySQL分割槽表介紹 分割槽是一種表的設計模式,正確的分割槽可以極大地提升資料庫的查詢效率,完成更高質量的SQL程式設計。但是如果錯誤地使用分割槽,那麼分割槽可能帶來毀滅性的的結果。 分割槽功能並不是在儲存引擎層完成的,因此不只有InnoDB儲存引擎支援分割槽,常見的儲存引
MySQL技術內幕 InnoDB儲存引擎:阻塞、死鎖、鎖升級
1、堵塞 因為不同鎖之間的相容性關係,在有些時刻一個事務中的鎖需要等待另外一個事務中的鎖釋放它所佔用的資源,這就是堵塞。 引數innodb_lock_wait_timeout用來控制等待的時間,預設50秒,是可以動態設定的。 引數innodb_rollback_on
MySQL技術內幕 InnoDB儲存引擎:鎖問題(髒讀、不可重複讀)
1、髒讀 在理解髒讀(Dirty Read)之前,需要理解髒資料的概念。但是髒資料和之前所介紹的髒頁完全是兩種不同的概念。髒頁指的是在緩衝池中已經被修改的頁,但是還沒有重新整理到磁碟中,即資料庫例項記憶體中的頁和磁碟中的頁的資料是不一致的,當然在重新整理到磁碟之前,日誌都已經被寫人到