
動態ip代理教你:如何用爬蟲實現前端頁面渲染

不知大夥兒有沒有聽說過,前端渲染相比於後端渲染,是不利於進行SEO的,因為對網絡爬蟲不友好。究其原因,就是因為前端渲染的頁面是需要在瀏覽器端執行JavaScript代碼(即AJAX請求)才能獲取後端數據,隨後才能拼裝成完整的HTML頁面。
針對這類情況,當前也是已經有很多解決方案,最常用的就是借助PhantomJS、puppeteer這類Headless瀏覽器工具,相當於在網絡爬蟲中內置1個瀏覽器內核,對爬取的頁面先渲染(執行Javascript腳本),隨後再對頁面內容進行爬取。
不過,要使用這類技術,通常全全都是需要使用Javascript來開發網絡爬蟲工具,對於我這種寫慣了Python的人來說的確有些痛苦。
直到某1天,kennethreitz大神發布了開源項目requests-html,看到項目介紹中的那句FullJavaScriptsupport!時不禁熱淚盈眶,就是它了!該項目在GitHub上發布後不到三天,star數就達到5000以上,足見其影響力。
requests-html為啥會這麽火?
寫過Python的人,幾乎全都會使用requests這麽1個HTTP庫,說它是最好的HTTP庫1點也是不誇張(不限編程語言),對於其介紹語HTTPRequestsforHumans也是當之無愧。也是是因為這個原因,Locust和HttpRunner全全都是基於requests來進行開發的。
而requests-html,則是kennethreitz在requests的基礎上開發的另1個開源項目,除了可以復用requests的全部功能外,還實現了對HTML頁面的解析,即支持對Javascript的執行,和利用CSS和XPath對HTML頁面元素進行提取的功能,這些全全都是編寫網絡爬蟲工具非常需要的功能。
在實現Javascript執行方面,requests-html也是並沒有自己造輪子,而是借助了pyppeteer這個開源項目。還記得前面提到的puppeteer項目麽,這是GoogleChrome官方實現的NodeAPI;而pyppeteer這個項目,則相當於是使用Python語言對puppeteer的非官方實現,幾乎具有puppeteer的所有功能。
理清了以上關系後,相信大夥兒對requests-html也是就有了更好的理解。
在使用方面,requests-html也是十分簡單,用法與requests幾乎相同,只是多了render功能。
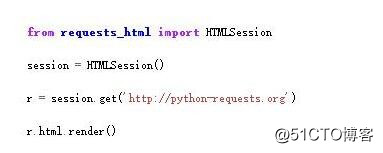
在執行render()之後,返回的就是經過渲染後的頁面內容。
動態ip代理教你:如何用爬蟲實現前端頁面渲染