
淺說深度學習(1):核心概念
此為系列首篇,旨在提供直觀簡明的深度學習引導,涵蓋深度學習的基本概念,而不設計很多數學和理論細節。當然如果要做更深入的研究,數學肯定是必不可少的,但是本系列主要還是用圖片和類比等方式,幫助初學者快速建立大局觀。
第一節介紹深度學習的主要概念。第二節交代一些歷史背景,並解釋訓練過程、演算法和實用技巧。第三節主講序列學習,包括迴圈神經網路、LSTM和機器翻譯中的編碼-解碼系統。第四節將轉進到增強學習領域。
核心概念
機器學習(Machine Learning)
在機器學習中,我們(1)讀取資料,(2)訓練模型,(3)使用模型對新資料做預測。訓練可以看作是當模型拿到新資料的時候、逐步學習一個的過程。在每一步,模型做出預測並且得到準確度的反饋。反饋的形式即是某種衡量標準(比如與正確解的距離)下的誤差,再被用於修正預測誤差。
學習是一個在引數空間裡迴圈往復的過程:當你調整引數改正一次預測,但是模型卻可能把原先對的又搞錯了。需要很多次的迭代,模型才能具有良好的預測能力,這一“預測-修正”的過程一直持續到模型再無改良空間。
特徵工程(Feature Engineering)
特徵工程從資料中提取有用的模式,使之更容易被機器學習模型進行分類。比如,把一堆綠色或藍色的畫素區域作為標準,來判斷照片上是陸生動物還是水生動物。這一特徵對於機器學習模型十分有效,因為其限制了需要考慮的類別數量。
在多數預測任務中,特徵工程是取得好結果的必備技能。然而,因為不同的資料集有著不同的特徵工程方法,所以很難得出普遍規律,只有一些大概的經驗,這使得特徵工程更是一門藝術而非科學。一個數據集裡極其關鍵的特徵,到了另一個數據集裡可能沒有卵用(比如下一個資料集裡全是植物)。正因為特徵工程這麼難,才會有科學家去研發自動提取特徵的演算法。
很多工已經可以自動化(比如物體識別、語音識別),特徵工程還是複雜任務中最有效的技術(比如Kaggle機器學習競賽中的大多數任務)。
特徵學習(Feature Learning)
特徵學習演算法尋找同類之間的共有模式,並自動提取用以分類或迴歸。特徵學習就是由演算法自動完成的特徵工程。在深度學習中,卷積層就極其擅長尋找圖片中的特徵,並對映到下一層,形成非線性特徵的層級結構,複雜度逐漸提升(例如:圓圈,邊緣 -> 鼻子,眼睛,臉頰)。最後一層使用所有生成的特徵來進行分類或迴歸(卷積網路的最後一層,本質上就是多項式邏輯迴歸)。
 圖1:深度學習演算法學得的層級特徵。每個特徵都相當於一個濾波器,用特徵(比如鼻子)去過濾輸入圖片。如果這個特徵找到了,相應的單元就會產生高激勵,在之後的分類階段中,就是此類別存在的高指標。
圖1:深度學習演算法學得的層級特徵。每個特徵都相當於一個濾波器,用特徵(比如鼻子)去過濾輸入圖片。如果這個特徵找到了,相應的單元就會產生高激勵,在之後的分類階段中,就是此類別存在的高指標。
圖1顯示了深度學習演算法生成的特徵,很難得的是,這些特徵意義都很明確,因為大多數特徵往往不知所云,特別是迴圈神經網路、LSTM或特別深的深度卷積網路。
深度學習(Deep Learning)
在層級特徵學習中,我們提取出了好幾層的非線性特徵,並傳遞給分類器,分類器整合所有特徵做出預測。我們有意堆疊這些深層的非線性特徵,因為層數少了,學不出複雜特徵。數學上可以證明,單層神經網路所能學習的最好特徵,就是圓圈和邊緣,因為它們包含了單個非線性變換所能承載的最多資訊。為了生成資訊量更大的特徵,我們不能直接操作這些輸入,而要對第一批特徵(邊緣和圓圈)繼續進行變換,以得到更復雜的特徵。
研究顯示,人腦有著相同的工作機理:視錐細胞接受資訊的第一層神經,對邊緣和圓圈更加敏感,而更深處的大腦皮層則對更加複雜的結構敏感,比如人臉。
層級特徵學習誕生在深度學習之前,其結構面臨很多嚴重問題,比如梯度消失——梯度在很深的層級處變得太小,以致於不能提供什麼學習資訊了。這使得層級結構反而表現不如一些傳統機器學習演算法(比如支援向量機)。
為解決梯度消失問題,以便我們能夠訓練幾十層的非線性層及特徵,很多新的方法和策略應運而生,“深度學習”這個詞就來自於此。在2010年代早期,研究發現在GPU的幫助下,激勵函式擁有足以訓練出深層結構的梯度流,從此深度學習開始了穩步發展。
深度學習並非總是與深度非線性層級特徵繫結,有時也與序列資料中的長期非線性時間依賴相關。對於序列資料,多數其他演算法只有最後10個時間步的記憶,而LSTM迴圈神經網路(1997年由Sepp Hochreiter和Jürgen Schmidhuber發明),使網路能夠追溯上百個時間步之前的活動以做出正確預測。儘管LSTM曾被雪藏將近10年,但自從2013年與卷積網路結合以來,其應用飛速成長。
基本概念
邏輯迴歸(Logistic Regression)
迴歸分析預測統計輸入變數之間的關係,以預測輸出變數。邏輯迴歸用輸入變數,在有限個輸類別變數中產生輸出,比如“得癌了” / “沒得癌”,或者圖片的種類如“鳥” / “車” / “狗” / “貓” / “馬”。
邏輯迴歸使用logistic sigmoid函式(見圖2)給輸入值賦予權重,產生二分類的預測(多項式邏輯迴歸中,則是多分類)。
 圖2:logistic
sigmoid函式f(x)=11+e−x
圖2:logistic
sigmoid函式f(x)=11+e−x
邏輯迴歸與非線性感知機或沒有隱藏層的神經網路很像。主要區別在於,只要輸入變數滿足一些統計性質,邏輯迴歸就很易於解釋而且可靠。如果這些統計性質成立,只需很少的輸入資料,就能產生很穩的模型。因而邏輯迴歸在很多資料稀疏的應用中,具有極高價值。比如醫藥或社會科學,邏輯迴歸被用來分析和解釋實驗結果。因為邏輯迴歸簡單、快速,所以對大資料集也很友好。
在深度學習中,用於分類的神經網路中,最後幾層一般就是邏輯迴歸。本系列將深度學習演算法看作若干特徵學習階段,然後將特徵傳遞給邏輯迴歸,對分類進行輸入。
人工神經網路(Aritificial Neural Network)
人工神經網路(1)讀取輸入資料,(2)做計算加權和的變換,(3)對變換結果應用非線性函式,計算出一箇中間狀態。這三步合起來稱為一“層”,變換函式則稱為一個“單元”。中間狀態——特徵——也是另一層的輸入。
通過這些步驟的重複,人工神經網路學的了很多層的非線性特徵,最後再組合起來得出一個預測。神經網路的學習過程是產生誤差訊號——網路預測與期望值的差——再用這些誤差調整權重(或其他引數)使預測結果更加準確。
單元(Unit)
單元有時指一層中的激勵函式,輸入正是經由這些非線性激勵函式進行變換,比如logistic sigmoid函式。通常一個單元會連線若干輸入和多個輸出,也有更加複雜的,比如長短期記憶(LSTM)單元就包含多個激勵函式,並以特別的佈局連線到非線性函式,或最大輸出單元。LSTM經過對輸入的一系列非線性變換,計算最終的輸出。池化,卷積及其他輸入變換函式一般不稱作單元。
人工神經元(Artificial Neuron)
人工神經元——或神經元——與“單元”是同義詞,只不過是為了表現出與神經生物學和人腦的緊密聯絡。實際上深度學習和大腦沒有太大關係,比如現在認為,一個生物神經元更像是一整個多層感知機,而不是單個人工神經元。神經元是在上一次AI寒冬時期被提出來的,目的是將最成功的神經網路與失敗棄置的感知機區別開來。不過自從2012年以後深度學習的巨大成功以來,媒體經常拿“神經元”這個詞來說事兒,並把深度學習比作人腦的擬態。這其實是具有誤導性,對深度學習領域來講也是危險的。如今業界不推薦使用“神經元”這個詞,而改用更準確的“單元”。
激勵函式(Acitivation Function)
激勵函式讀取加權資料(輸入資料和權重進行矩陣乘法),輸出資料的非線性變換。比如output = max(0, weight_{data})就是修正線性激勵函式(本質上就是把負值變成0)。“單元”和“激勵函式”之間的區別是,單元可以更加複雜,比如一個單元可以包含若干個激勵函式(就像LSTM單元)或者更復雜的結構(比如Maxout單元)。
線性激勵函式,與非線性激勵函式的區別,可以通過一組加權值之間的關係體現:想象4個點A1, A2, B1, B2。點(A1 / A2),和(B1 / B2)很接近,但是A1和B1, B2都很遠,A2亦然。
經過線性變換,點之間的關係會變化,比如A1和A2遠離了,但同時B1和B2也遠離了。但是(A1 / A2)和(B1 / B2)的關係不變。
而非線性變換則不同,我們可以增加A1和A2的距離,同時減小B1和B2的距離,如此就建立了複雜度更高的新關係。在深度學習中,每一次層的非線性激勵函式都創造了更復雜的特徵。
而純線性變換,哪怕有1000層,也可以用一個單層來表示(因為一連串的矩陣相乘可以用一個矩陣乘法來表示)。這就是為什麼非線性激勵函式在深度學習中如此重要。
層(Layer)
層是深度學習更高階的基本構成單位。一層,就是接受加權輸入、經過非線性激勵函式變換、作為輸出傳遞給下一層的容器。一層通常只含一種激勵函式,池化、卷積等等,所以可以簡單地與網路其他部分作對比。第一層和最後一層分別稱為“輸入層”和“輸出層”,中間的都稱作“隱藏層”。
卷積深度學習
卷積(Convolution)
卷積是一種數學操作,表述了混合兩個函式或兩塊資訊的規則:(1)特徵對映或輸入資料嗎,與(2)卷積核混合,形成(3)變換特徵對映。卷積也經常被當做是一種濾波器,卷積核(kernel)過濾特徵對映以找到某種資訊,比如一個卷積核可能是隻找邊緣,而拋掉其他資訊。
 圖3:用邊緣檢測卷積核,對影象進行卷積操作。
圖3:用邊緣檢測卷積核,對影象進行卷積操作。
卷積在物理和數學中都很重要,因為他建立了時域和空間(位置(0,30)的,畫素值147)以及頻域(幅度0.3,頻率30Hz,相位60度)的橋樑。這一橋樑的建立是通過傅立葉變換:當你對卷積核與特徵對映都做傅立葉變換時,卷積操作就被極大簡化了(積分變成了相乘)。
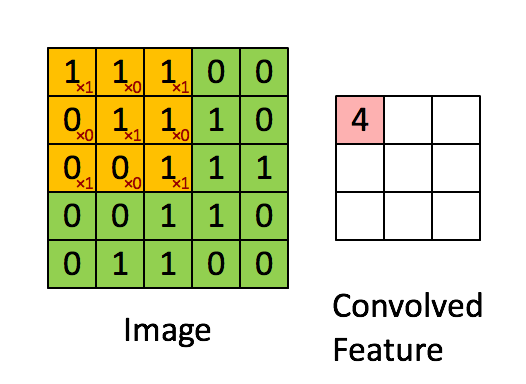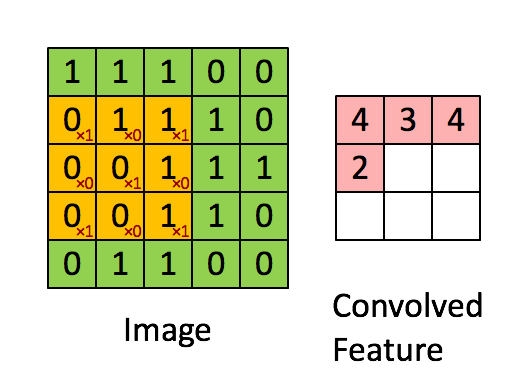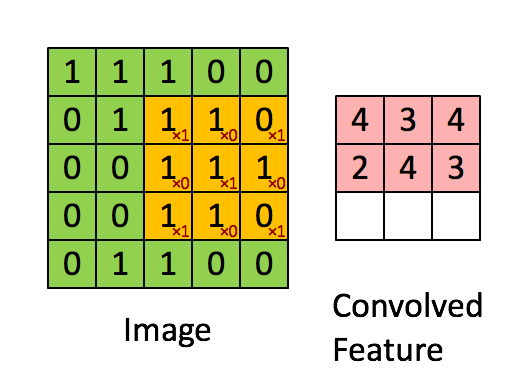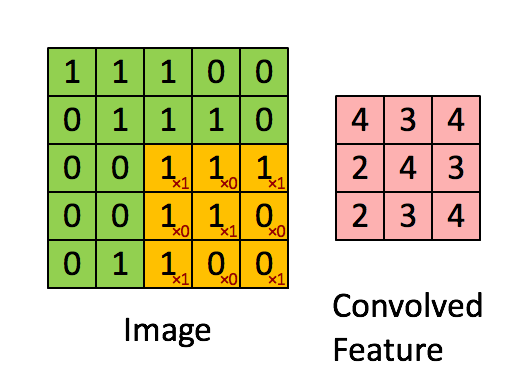 圖4:用影象窗在整個影象上滑動計算卷積。原始影象(綠色)的影象窗(黃色)與卷積核(紅字)相乘再相加,得到特徵對映中的一個想租(Convolved
Feature裡的粉紅單元)。
圖4:用影象窗在整個影象上滑動計算卷積。原始影象(綠色)的影象窗(黃色)與卷積核(紅字)相乘再相加,得到特徵對映中的一個想租(Convolved
Feature裡的粉紅單元)。
卷積,可以描述資訊的擴散。比如當你把牛奶倒進咖啡卻不攪拌,這是擴散就發生了,而且可以通過卷積精確描述(畫素向著影象邊緣擴散)。在量子力學當中,這描述了當你測量一個量子的位置時,其在特定位置出現的概率(畫素在邊緣處於最高位置的概率)。在概率論中,者描述了互相關,也就是兩個序列的相似度(如果一個特徵(如鼻子)裡的畫素,與一個影象(比如臉)重疊,那麼相似度就高)。在統計學中,卷積描述了正太輸入血獵的加權動平均(邊緣權重高,其他地方權重低)。另有其它很多不同角度的解釋。

不過對於深度學習,我們也不知道卷積的哪一種解釋才是正確的,互相關(cross-correlation)解釋是目前最有效的:卷積濾波器是特徵檢測器,輸入(特徵對映)被某個特徵(kernel)所過濾,如果該特徵被檢測到了,那麼輸出就高。這也是影象處理中互相關的解釋。
 圖5:
影象的互相關。卷積核上下倒過來,就是互相關了。核Kernel可以解釋為特徵檢測器,如果檢測到了,就會產生高輸出(白色),反之則為低輸出(黑色)。
圖5:
影象的互相關。卷積核上下倒過來,就是互相關了。核Kernel可以解釋為特徵檢測器,如果檢測到了,就會產生高輸出(白色),反之則為低輸出(黑色)。
池化/下采樣(Pooling/Sub-Sampling)
池化過程從特定區域讀取輸入,並壓縮為一個值(下采樣)。在卷積神經網路中,資訊的集中是種很有用的性質,這樣輸出連線通常接收的都是相似資訊(資訊像經過漏斗一樣,流向對應下一個卷積層的正確位置)。這提供了基本的旋轉/平移不變性。比如,如果臉不在圖片的中心位置,而是略有偏移,這應該不影響識別,因為池化操作將資訊匯入到了正確位置,故卷積濾波器仍能檢測到臉。
池化區域越大,資訊壓縮就越多,從而產生更“苗條”的網路,也更容易配合視訊記憶體。但是如果池化面積太大,丟失資訊太多,也會降低預測能力。
卷積神經網路(Convolutional Neural Network, CNN)
卷積神經網路,或卷積網路,使用卷積層過濾輸入以獲得有效資訊。卷積層有的引數是自動學習獲得的,濾波器自動調整以提取最有用的資訊(特徵學習)。比如對於一個普適的物體識別任務,物體的形狀可能是最有用的;而對於鳥類識別人物,顏色可能是最有用的(因為鳥的形狀都差不多,而顏色卻五花八門)。
一般我們使用多個卷積層過濾影象,每一層之後獲得的資訊,都越來越抽象(層級特徵)。
卷積網路使用池化層,獲得有限的平移/旋轉不變性(即使目標不在通常位置,也能檢測出來)。池化也降低了記憶體消耗,從而能夠使用更多卷積層。
最近的卷積網路使用inception模組,即1x1的卷積核進一步降低記憶體消耗,加速計算和訓練過程。
 圖6:一個交通標誌影象被4個5x5卷積核濾波,生成了4個特徵對映,這些特徵對映經過“最大池化”。下一層對之前下采樣過的影象應用10個5x5卷積核,並在此池化。最後一層是全連線層,所有的特徵都組合起來傳遞給分類器(本質上就是邏輯迴歸)。
圖6:一個交通標誌影象被4個5x5卷積核濾波,生成了4個特徵對映,這些特徵對映經過“最大池化”。下一層對之前下采樣過的影象應用10個5x5卷積核,並在此池化。最後一層是全連線層,所有的特徵都組合起來傳遞給分類器(本質上就是邏輯迴歸)。
Inception
卷積網路中,inception模組的設計初衷是為了以更高的計算效率,執行更深、更大的卷積層。Inception使用1x1的卷積核,生成很小的特徵對映。比如192個28x28的特徵對映,可以經過64個1x1的卷積,被壓縮成64個28x28的特徵對映。因為尺寸縮小了,這些1x1的卷積後面還可以跟跟大的卷積,比如3x3,5x5。除了1x1卷積,最大池化也用來降維。
Inception模組的輸出,所有的大卷積都拼接成一個大的特徵對映,再傳遞給下一層(或inception模組)。
相關推薦
淺說深度學習(1):核心概念
此為系列首篇,旨在提供直觀簡明的深度學習引導,涵蓋深度學習的基本概念,而不設計很多數學和理論細節。當然如果要做更深入的研究,數學肯定是必不可少的,但是本系列主要還是用圖片和類比等方式,幫助初學者快速建立大局觀。 第一節介紹深度學習的主要概念。第二節交代一些歷史背景,並解釋訓練過程、演算法和實用技巧。第三節
深度學習分割:(1)資料彙總
時間關係,備份一些深度學習分割演算法相關的部落格和介紹文章。 分割演算法綜述 介紹了幾個比較經典且非常重要的深度學習分割演算法。 原作地址:https://blog.csdn.net/weixin_41923961/article/details/80946586 更加全面的一篇
【讀書1】【2017】MATLAB與深度學習——示例:多元分類(4)
讓我們逐一檢視。 Let’s take a look one by one. 對於第一幅影象,神經網路認為該圖為4的概率為96.66%。 For the first image, the neural networkdecided it was a 4 by 96.66% pro
【讀書1】【2017】MATLAB與深度學習——示例:MNIST(2)
函式MnistConv使用反向傳播演算法訓練網路,獲取神經網路的權重和訓練資料,並返回訓練後的權重。 The function MnistConv, which trains thenetwork using the back-propagation algorithm, takes t
【讀書1】【2017】MATLAB與深度學習——示例:MNIST(1)
因此,我們有8000幅MNIST影象用於訓練,2000幅影象用於神經網路的效能驗證。 Therefore, we have 8,000 MNIST images fortraining and 2,000 images for validation of the performance
【讀書1】【2017】MATLAB與深度學習——示例:MNIST(3)
程式碼的小批量訓練部分被單獨提取出來並顯示在下面的列表中。 The minibatch portion of the code isextracted and shown in the following listing. bsize = 100; blist = 1:bsize
【讀書1】【2017】MATLAB與深度學習——示例:MNIST(4)
程式碼中的變數y是該網路的最終輸出。 The variable y of this code is the finaloutput of the network. … x = X(:, :, k); %Input, 28x28 y1 = Conv(x, W1);% Convo
【讀書1】【2017】MATLAB與深度學習——示例:多元分類(2)
使用交叉熵驅動的學習規則,輸出節點的增量計算如下: Using the cross entropy-driven learningrule, the delta of the output node is calculated as follows: e =d
深度學習與計算機視覺: 深度學習必知基本概念以及鏈式求導
深度學習與計算機視覺,開篇。 深度學習的幾個基本概念 反向傳播演算法中的鏈式求導法則。 關於反向傳播四個基本方程的推導過程,放在下一篇。 深度學習基礎 深度學習的幾度沉浮的歷史就不多說了,這裡梳理下深度學習的一些基本概念,做個總結記錄,內容多來源於網路。 神
深度學習筆記:稀疏自編碼器(1)——神經元與神經網路
筆者在很久以前就已經學習過UFLDL深度學習教程中的稀疏自編碼器,近期需要用到的時候發現有些遺忘,溫習了一遍之後決定在這裡做一下筆記,本文不是對神經元與神經網路的介紹,而是筆者學習之後做的歸納和整理,打算分為幾篇記錄。詳細教程請見UFLDL教程,看完教程之後
rn學習1:
https you abs exp 1.8 -a eating oca 2.0 /usr/local/bin/react-native -> /usr/local/lib/node_modules/react-native-cli/index.js/usr/local
Docker 學習筆記之 核心概念
api rest api 核心概念 log 筆記 try nbsp .com ont Docker核心概念: Docker Daemon Docker Container Docker Registry Docker Client 通過rest API 和Docker
UML建模學習1:UML統一建模語言簡單介紹
教授 分法 之間 實例 層次 ech 集成 視覺 行業 一什麽是UML? Unified Modeling Language(UML又稱為統一建模語言或標準建模語言)是國際對象管理組織OMG制定的一個通 用的、可視化建模語言標準。
機器學習1:數據預處理
出了 替代 線性復雜 邊際 大數據 關系 虛擬 引入 分類 1、 缺失值處理 首先根據df.info( )可查看各列非空值個數;df.isnull( ).sum( )可查看數據框各列缺失值個數 >>>import pandas as pd >>
CNTK 搞深度學習-1
激活 result dll desc mman caf element 有用 成了 CNTK 搞深度學習 Computational Network Toolkit (CNTK) 是微軟出品的開源深度學習工具包。本文介紹CNTK的基本內容,如何寫CNTK的網絡定義語言,以及
Python機器學習(1):KMeans聚類
ima mea arr src ont array imp rom open Python進行KMeans聚類是比較簡單的,首先需要import numpy,從sklearn.cluster中import KMeans模塊: import numpy as np f
ELK-學習-1:elasticsearch6.3安裝和配置
home true 地址 修改配置 iss HA 5.2.1 oop bubuko 安裝elacticsearch: 1,安裝jdk 要求1.8以上 2,安裝elacticsearch rpm –ivh https://artifacts.elastic.co/downl
spring基礎(1:基本概念)
poj 操作 共享問題 元素 組成 The 開發 let 可選值 本系列筆記來自對《Spring實戰》第三版的整理,Spring版本為3.0 ??spring是為了解決企業級應用開發的復雜性而創建的,spring最根本的使命是:簡化Java開發。為降低開發復雜性有以下四種關
spring學習1:1.基於註解的bean
成了 返回值 ins location for onf 默認 san Coding <?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/sch
《深度學習入門:基於Python的理論與實現》高清中文版PDF+源代碼
mark 原理 col 外部 tps follow src term RoCE 下載:https://pan.baidu.com/s/1nk1IHMUYbcuk1_8tj6ymog 《深度學習入門:基於Python的理論與實現》高清中文版PDF+源代碼 高清中文版PDF,3