
Pytorch實戰2:ResNet-18實現Cifar-10影象分類(測試集分類準確率95.170%)(轉)
Pytorch實戰2:ResNet-18實現Cifar-10影象分類
實驗環境:
- torchvision 0.2.1
- Python 3.6
- CUDA8+cuDNN v7 (可選)
Win10+Pycharm
整個專案程式碼:點選這裡
ResNet-18網路結構:
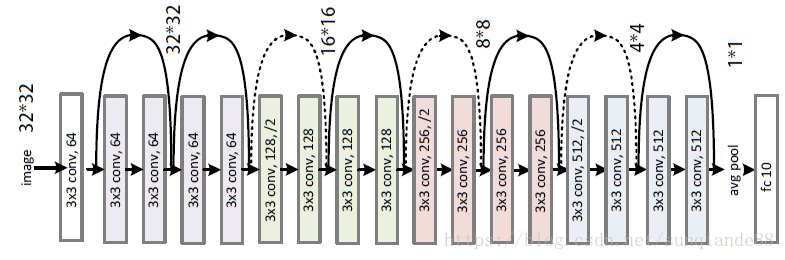
ResNet全名Residual Network殘差網路。Kaiming He 的《Deep Residual Learning for Image Recognition》獲得了CVPR最佳論文。他提出的深度殘差網路在2015年可以說是洗刷了影象方面的各大比賽,以絕對優勢取得了多個比賽的冠軍。而且它在保證網路精度的前提下,將網路的深度達到了152層,後來又進一步加到1000的深度。論文的開篇先是說明了深度網路的好處:特徵等級隨著網路的加深而變高,網路的表達能力也會大大提高。因此論文中提出了一個問題:是否可以通過疊加網路層數來獲得一個更好的網路呢?作者經過實驗發現,單純的把網路疊起來的深層網路的效果反而不如合適層數的較淺的網路效果。因此何愷明等人在普通平原網路的基礎上增加了一個shortcut, 構成一個residual block。此時擬合目標就變為F(x),F(x)就是殘差:
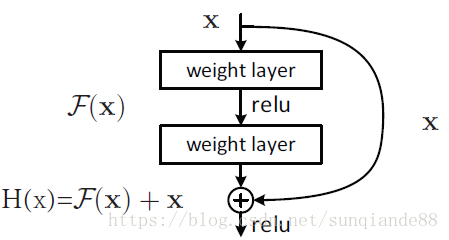 !
!
Pytorch上搭建ResNet-18:
'''ResNet-18 Image classfication for cifar-10 with PyTorch
Author 'Sun-qian'.
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
classResidualBlock(nn.Module):
def__init__(self, inchannel, outchannel, stride=1):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
Pytorch上訓練:
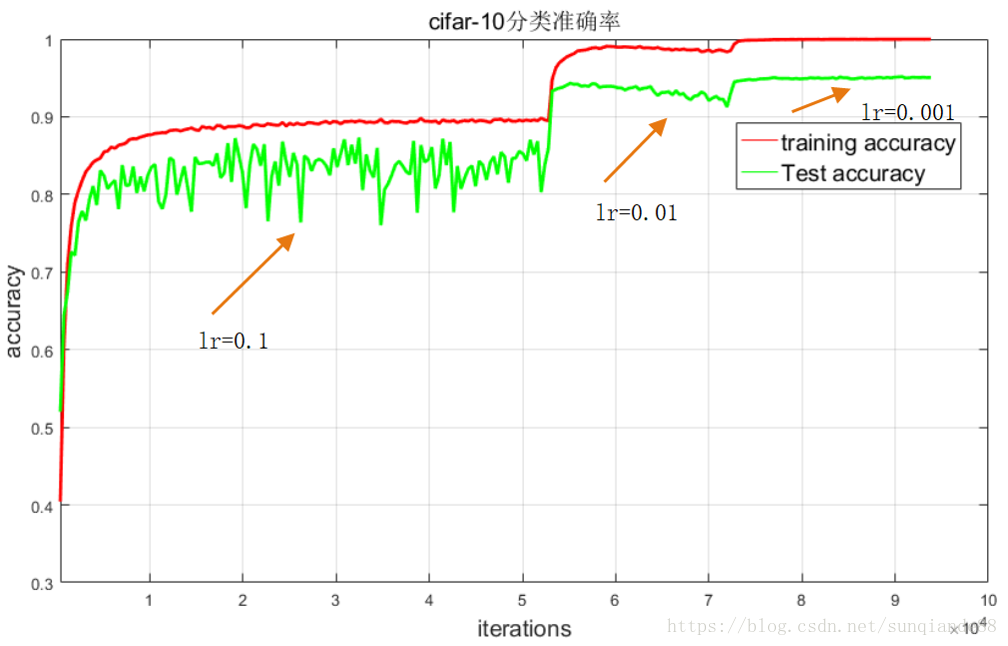
所選資料集為Cifar-10,該資料集共有60000張帶標籤的彩色影象,這些影象尺寸32*32,分為10個類,每類6000張圖。這裡面有50000張用於訓練,每個類5000張,另外10000用於測試,每個類1000張。訓練時人為修改學習率,當epoch:[1-135] ,lr=0.1;epoch:[136-185], lr=0.01;epoch:[186-240] ,lr=0.001。訓練程式碼如下:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import argparse
from resnet import ResNet18
# 定義是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 引數設定,使得我們能夠手動輸入命令列引數,就是讓風格變得和Linux命令列差不多
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--outf', default='./model/', help='folder to output images and model checkpoints') #輸出結果儲存路徑
parser.add_argument('--net', default='./model/Resnet18.pth', help="path to net (to continue training)") #恢復訓練時的模型路徑
args = parser.parse_args()
# 超引數設定
EPOCH = 135 #遍歷資料集次數
pre_epoch = 0 # 定義已經遍歷資料集的次數
BATCH_SIZE = 128 #批處理尺寸(batch_size)
LR = 0.1 #學習率
# 準備資料集並預處理
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), #先四周填充0,在吧影象隨機裁剪成32*32
transforms.RandomHorizontalFlip(), #影象一半的概率翻轉,一半的概率不翻轉
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), #R,G,B每層的歸一化用到的均值和方差
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train) #訓練資料集
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2) #生成一個個batch進行批訓練,組成batch的時候順序打亂取
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
# Cifar-10的標籤
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 模型定義-ResNet
net = ResNet18().to(device)
# 定義損失函式和優化方式
criterion = nn.CrossEntropyLoss() #損失函式為交叉熵,多用於多分類問題
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4) #優化方式為mini-batch momentum-SGD,並採用L2正則化(權重衰減)
# 訓練
if __name__ == "__main__":
best_acc = 85 #2 初始化best test accuracy
print("Start Training, Resnet-18!") # 定義遍歷資料集的次數
with open("acc.txt", "w") as f:
with open("log.txt", "w")as f2:
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
correct = 0.0
total = 0.0
for i, data in enumerate(trainloader, 0):
# 準備資料
length = len(trainloader)
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
# forward + backward
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 每訓練1個batch列印一次loss和準確率
sum_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('%03d %05d |Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('\n')
f2.flush()
# 每訓練完一個epoch測試一下準確率
print("Waiting Test!")
with torch.no_grad():
correct = 0
total = 0
for data in testloader:
net.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
# 取得分最高的那個類 (outputs.data的索引號)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('測試分類準確率為:%.3f%%' % (100 * correct / total))
acc = 100. * correct / total
# 將每次測試結果實時寫入acc.txt檔案中
print('Saving model......')
torch.save(net.state_dict(), '%s/net_%03d.pth' % (args.outf, epoch + 1))
f.write("EPOCH=%03d,Accuracy= %.3f%%" % (epoch + 1, acc))
f.write('\n')
f.flush()
# 記錄最佳測試分類準確率並寫入best_acc.txt檔案中
if acc > best_acc:
f3 = open("best_acc.txt", "w")
f3.write("EPOCH=%d,best_acc= %.3f%%" % (epoch + 1, acc))
f3.close()
best_acc = acc
print("Training Finished, TotalEPOCH=%d" % EPOCH)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
實驗結果:best_acc= 95.170%
相關推薦
Pytorch實戰2:ResNet-18實現Cifar-10影象分類(測試集分類準確率95.170%)(轉)
Pytorch實戰2:ResNet-18實現Cifar-10影象分類 實驗環境: torchvision 0.2.1 Python 3.6 CUDA8+cuDNN v7 (可選) Win10+Pycharm 整個專案程式碼:點選這裡 Res
Tensorflow使用Resnet思想實現CIFAR-10十分類demo
關於Resnet殘差網路的介紹已經非常多了,這裡就不在贅述.使用Tensorflow寫了一個簡單的Resnet,對CIFAR-10資料集進行十分類.關鍵步驟都寫了詳細註釋,雖然最後的精度不高,但還是學習Resnet的思想為主. import tensorf
python機器學習實戰2:實現決策樹
1.決策樹的相關知識 在之前的接觸中決策樹直觀印象應該就是if-else的迴圈,if會怎麼樣,else之後再繼續if-else直至最終的結果。在上節講的kNN它其實已經可以完成很多工,但是它最大的缺點就是無法給資料集的內在含義,決策樹的主要優勢在於資料形式非常
HP C7000刀片服務器實戰2:RAID1創建
pro http ini .com onf 完成 mini size 實戰 1.對刀片服務器系統磁盤做RAID 1 2.等待出現Smart Storage Administrator之後,點擊Smart Array P224br 在右邊Actions處點擊configu
爬蟲實戰2:爬出頭條網美圖
open exists read 地址 bsp lose col new 頭條 完整代碼經測試可成功運行,目的是抓取頭條網輸入街拍後的圖片 有幾個問題點不明白 1. 查看頭信息,參數表和代碼中params有些不同,不知道代碼中的參數是怎麽來的 offset: 40
Qt專案實戰2:圖片檢視器QImageViewer
在博文Qt學習筆記2:QMainWindow和QWidget的區別中介紹了使用空的Qt專案建立帶有選單欄、工具欄的介面。 這裡,使用一個簡單的圖片檢視器專案,來熟悉一下Qt的圖片顯示和基本操作。 該專案實現的主要功能: 實現圖片的開啟、關閉、居中顯示; 實現圖片上一
併發程式設計實戰(2):原子性、可見性和競態條件與複合操作
原子性 一個不可分割的操作,比如a=0;再比如:a++; 這個操作實際是a = a + 1;是可分割的,它其實包含三個獨立的操作:讀取a的值,將值加1,然後將計算結果寫入a,這是一個“讀取-修改-寫入”的操作序列,所以他不是一個原子操作。 可見性 可見性,是指執行緒之間的可見
Pytorch求索(2): Pytorch使用visdom進行視覺化
Pytorch使用visdom進行視覺化 文章目錄 Pytorch使用visdom進行視覺化 visdom介紹 visdom核心概念 visdom安裝與使用 常用API plot.scat
YOLOV3實戰2:訓練自己的資料集,你不可能出錯!
大家好,我是小p,今天給大家帶來一期用darknet版本YOLO V3訓練自己資料集的教程,希望大家喜歡。 歡迎加入物件檢測群813221712討論和交流,進群請看群公告! 一、搭建環境 搭建環境和驗證環境是否已經正確配置已在YOLOV3實戰1中詳細介紹,請一定
HTML5遊戲實戰 2 90行程式碼實現捕魚達人
捕魚達人是一款非常流行的遊戲,幾年裡賺取了數以千萬的收入,這裡借用它來介紹一下用Gamebuilder+CanTK開發遊戲的方法。其實賺錢的遊戲未必技術就很難,今天我們就僅用90來行程式碼來實現這個遊戲。 CanTK(Canvas ToolKit)是一個開源的遊戲引擎和APP框
商城專案實戰36:訂單系統實現
1 訂單系統實現 1.1 系統架構 1.2 訂單表結構 訂單表: 訂單商品表: 物流表: 1.3 介面 參見:淘淘商城-訂單系統介面.docx 1.4 建立訂單系統taotao-order 系統配置參考taotao-sso系統。 1.5 實現建
Android實戰技巧:用TextView實現Rich Text---在同一個TextView中設定不同的字型風格
背景介紹 在開發應用過程中經常會遇到顯示一些不同的字型風格的資訊猶如預設的LockScreen上面的時間和充電資訊。對於類似的情況,可能第一反應就是用不同的多個TextView來實現,對於每個TextView設定不同的字型風格以滿足需求。 這裡推薦的做法是使用android
C++併發實戰2:thread::join和thread::detach
thread::join()是個簡單暴力的方法,主執行緒等待子程序期間什麼都不能做,一般情形是主執行緒建立thread object後做自己的工作而不是簡單停留在join上。thread::join()還會清理子執行緒相關的記憶體空間,此後thread object
jquery實戰2:輪播圖和滑動導航效果
.banner{width:100%;height:450px;position:relative;z-index:0;} .banner .b-img{width:100%;height:450px;position:absolute;left:0px;top:0px;}/**/ .banner
[keras實戰] 小型CNN實現Cifar-10資料集84%準確率
實驗環境 程式碼基於python2.7, Keras1(部分介面在Keras2中已經被修改,如果你使用的是Keras2請查閱文件修改介面) 個人使用的是蟲資料提供的免費GPU主機,GTX1080顯示卡,因為是免費賬號,所以視訊記憶體最高只有1G。為了防止超視
Kotlin實戰案例:帶你實現RecyclerView分頁查詢功能(仿照主流電商APP,可切換列表和網格效果)
隨著Kotlin的推廣,一些國內公司的安卓專案開發,已經從Java完全切成Kotlin了。雖然Kotlin在各類程式語言中的排名比較靠後(據TIOBE釋出了 19 年 8 月份的程式語言排行榜,Kotlin竟然排名45位),但是作為安卓開發者,掌握該語言,卻已是大勢所趨了。 Kotlin的基礎用法,整
C++霧中風景番外篇2:Gtest 與 Gmock,聊聊C++的單元測試
argc 存儲 初始化 move 實的 每次 運行 相同 int32 正式工作之後,公司對於單元測試要求比較嚴格。(筆者之前比較懶,一般很少寫完整的單測~~)。作為一個合格的開發工程師,需要為所編寫代碼編寫適量的單元測試是十分必要的,在實際進行的開發工作之中,TDD(Te
Tensorflow使用Inception思想實現CIFAR-10十分類demo
使用Inception思想實現一個簡單的CIFAR-10十分類.最主要的是領會Inception的結構. Inception結構圖如下: 思想: 分別使用1*1,3*3,5*5卷積核和一個3*3最大池化層對上一層進行處理,然後將輸入進行合併.
機器學習學習筆記:用MiniVGGNet處理Cifar-10資料集
0. 引言 VGGNet,由Simonyan和Zisserman在2014年提出,論文名字是《Very Deep Learning Convolutional Neural Networks for Large-Scale Image Recognition》。他們做出的貢
Keras卷積神經網路識別CIFAR-10影象(2)
上一篇文章簡單介紹了卷積神經網路的結構,本篇文章則會利用上一篇文章的理論知識搭建神經網路模型來識別CIFAR-10影象。 2.Keras卷積神經網路識別CIFAR-10影象 首先簡單介紹一下什麼是CIFAR-10,CIFAR-10是是用於物件識別的已建立的計算機