
Tensorflow使用Inception思想實現CIFAR-10十分類demo
阿新 • • 發佈:2018-12-09
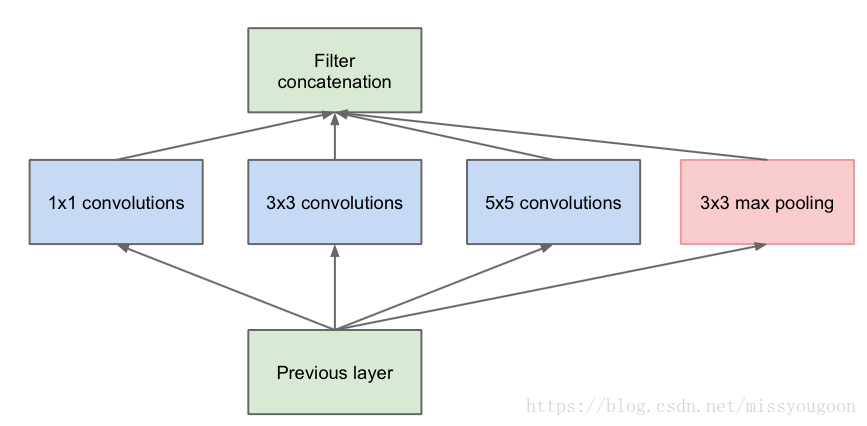
使用Inception思想實現一個簡單的CIFAR-10十分類.最主要的是領會Inception的結構.
Inception結構圖如下:
# -*- coding:utf-8 -*-
"""
@author:老艾
@file: neuton.py
@time: 2018/08/22
"""
import tensorflow as tf
import