
簡單應用復旦FNLP自然語言處理工具(一)
FNLP是一個基於機器學習的中文自然語言文字處理的開發工具包,FNLP主要是為中文自然語言處理而開發的工具包,也包含為實現這些任務的機器學習演算法和資料集。
----------百度百科
- 資訊檢索 文字分類 新聞聚類
- 中文處理: 中文分詞 詞性標註 實體名識別 關鍵詞抽取 依存句法分析 時間短語識別
- 結構化學習: 線上學習 層次分類 聚類
在看這篇文章之前,請確定已經裝好了Eclipse,如果沒有安裝Eclipse,請看這裡JSP環境安裝
因為FNLP在Github上已經有了很詳盡的入門教程,所以在這裡我只是把這些教程的順序、要點和要注意的地方寫出來:
首先先下載最新的fnlp版本檔案,點這裡............................:)IE瀏覽器有可能會點不動
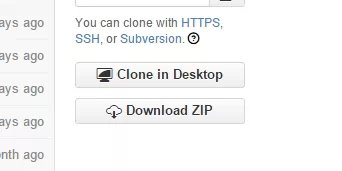
往下找有一個入門教程連結

入門教程有兩個,我感覺第二個教程唯一有用的是一篇介紹Eclipse安裝Maven外掛的文章,在這裡:Eclipse安裝Maven外掛
在使用fnlp工具之前,我們需要先安裝Maven工具,Maven和maven外掛我已經傳到了網盤裡,這裡是地址Maven網盤檔案
現在簡單的測試一下你的環境配置有沒有成功,開啟cmd,分別輸入java -version javac -version mvn -version


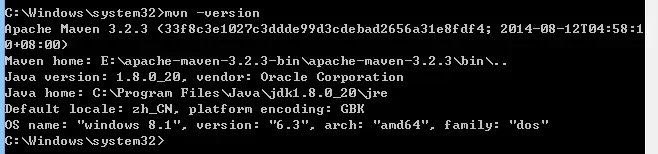
進行到這一步可能有的同學會出現問題,提示沒有JAVA_HOME變數,進入電腦系統屬性-環境變數,新建系統變數JAVA_HOME,變數值為java/jdk的安裝目錄,java安裝目錄在cmd下可以用java -verbose檢視

最後一行的地址就是你的java安裝地址,以我的電腦為例,JAVA_HOME的變數名就是C:\Program Files\Java\jdk1.8.0_20
好了,現在環境已經配置好了,其實有一些步驟我也是借鑑的第一篇教程,現在開始看第一篇fnlp入門教程:
為了方便,官方給的模型檔案、兩個jar包的連結在這裡直接貼出來http://pan.baidu.com/s/1D7CVc
接下來按教程走

cmd進入fnlp原始碼目錄,如我的fnlp檔案放在E:/fnlp下,
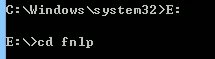
執行上面的命令:mvn install -Dmaven.test.skip=true,編譯fnlp
接下來就簡單多了,不過要注意官方教程裡命令列呼叫中,包與包的間隔用的 : 號,windows使用者要改成 ; 號,英文狀態下。
在Eclipse專案中引用FNLP中需要注意的是,新建一個java Project,如果沒有找到,請注意右上角
然後只要按照Github上的第一個教程就好了
其實好多都是官方已經說明的,嗯,先感謝一下FNLP專案組成員!!!下面介紹幾個常見錯誤解決辦法(百度來的,經過驗證)
一、命令列執行報錯模型檔案版本錯誤
用網盤的模型檔案就好了,這種錯誤是因為你的模型檔案和FNLP版本號不符,網盤裡永遠是最新的
二、命令列報錯找不到或無法載入主類
首先請確定你的系統變數配置正確,Path,CLASSPATH還有JAVA_HOME
系統變數的正確配置是類似

只要把JAVA_HOME換成你的jdk目錄就好了
三、如果報錯空指標異常之類的錯誤,怎麼也檢查不到程式碼錯誤,或者乾脆是cmd執行卻還是報空指標異常
額,恭喜你,估計是原始檔有問題,歡迎加群253541693,報告管理員。
四、無論是maven,fnlp或者jdk,安裝目錄都不要用中文,否則奇奇怪怪的問題就來了。雖然,我的是英文路徑。
因為本人也是剛剛認識的FNLP,在安裝使用的過程中遇到了問題,也走了彎路,所以特地將安裝使用過程詳細的整理了下,希望能給想要使用FNLP的同學以幫助!
最後,歡迎有問題有錯誤的同學到這裡一起討論,共同進步。轉載請註明來自任祥磊。
相關推薦
簡單應用復旦FNLP自然語言處理工具(一)
FNLP是一個基於機器學習的中文自然語言文字處理的開發工具包,FNLP主要是為中文自然語言處理而開發的工具包,也包含為實現這些任務的機器學習演算法和資料集。 ----------百度百科 資訊
簡單應用復旦FNLP自然語言處理工具
FNLP是一個基於機器學習的中文自然語言文字處理的開發工具包,FNLP主要是為中文自然語言處理而開發的工具包,也包含為實現這些任務的機器學習演算法和資料集。 ----------百度百科 資訊檢索 文
自然語言處理隨筆(一)
索引 中國 大學 import pip for earch 清華 北京 安裝jieba中文分詞命令:pip install jieba 簡單的例子: import jiebaseg_list = jieba.cut("我來到北京清華大學", cut_all=True)pri
【數學之美筆記】自然語言處理部分(一).md
strip BE 模擬 ges arr 實驗 語句 次數 而不是 文字、數字、語言 、信息 數字、文字和自然語言一樣,都是信息的載體,他們的產生都是為了記錄和傳播信息。 但是貌似數學與語言學的關系不大,在很長一段時間內,數學主要用於天文學、力學。 本章,我們將回顧一下信息時
自然語言處理NLP(一)
rac 控制臺 分析 arm ont 正則表達 stop python none NLP 自然語言:指一種隨著社會發展而自然演化的語言,即人們日常交流所使用的語言; 自然語言處理:通過技術手段,使用計算機對自然語言進行各種操作的一個學科; NLP研究的內容
自然語言處理技術(NLP)在推薦系統中的應用
作者: 張相於,58集團演算法架構師,轉轉搜尋推薦部負責人,負責搜尋、推薦以及演算法相關工作。多年來主要從事推薦系統以及機器學習,也做過計算廣告、反作弊等相關工作,並熱衷於探索大資料和機器學習技術在其他領域的應用實踐。 責編:何永燦([email
自然語言處理入門(4)——中文分詞原理及分詞工具介紹
本文首先介紹下中文分詞的基本原理,然後介紹下國內比較流行的中文分詞工具,如jieba、SnowNLP、THULAC、NLPIR,上述分詞工具都已經在github上開源,後續也會附上github連結,以供參考。 1.中文分詞原理介紹 1.1 中文分詞概述 中
自然語言處理NLP(二)
哪些 一個 圖片 ali cor res https 的區別 進行 詞性標註 標註語料庫; 各詞性標註及其含義 自動標註器; 默認標註器; 正則表達式標註器; 查詢標註器; N-gram標註器; 一元標註器; 分離訓練和測試數據; 一般的N-gram的標註
自然語言處理NLP(三)
樣本點中的關鍵度量指標:距離 定義: 常用距離: 歐氏距離,euclidean–通常意義下的距離; 馬氏距離,manhattan–考慮到變數間的相關性,且與變數單位無關; 餘弦距離,cosi
自然語言處理NLP(四)
實體識別 實體識別–分塊型別: 名詞短語分塊; 標記模式分塊; 正則表示式分塊; 分塊的表示方法:標記和樹狀圖; 分塊器評估; 命名實體識別; 命名實體定義:指特定型別的個體,是一些確切的名詞短語
自然語言處理入門(2)——中文文字處理利器snownlp
SnowNLP是一個python寫的類庫,可以方便的處理中文文字內容。如中文分詞、詞性標註、情感分析、文字分類、提取文字關鍵詞、文字相似度計算等。 snownlp示例如下所示: # -*- coding: utf-8 -*- """ Created on
Python自然語言處理實戰(3):中文分詞技術
3.1、中文分詞簡介 在英文中,單詞本身就是“詞”的表達,一篇英文文章就是“單詞”加分隔符(空格)來表示的,而在漢語中,詞以字為基本單位的,但是一篇文章的語義表達卻仍然是以詞來劃分的。 自中文自動分詞被提出以來,歷經將近30年的探索,提出了很多方法,可
Python自然語言處理實戰(8):情感分析技術
實戰電影評論情感分析 情感分析是一段文字表達的情緒狀態。其中,一段文字可以使一個句子、一個段落或者一個文件。主要涉及兩個問題:文字表達和文字分類。在深度學習出現之前,主流的表示方法有BOW(詞袋模型)和topic model(主題模型),分類模型主要有SVM
自然語言處理基礎(1)--基本分詞方法
基本的分詞方法包括最大匹配法、最大概率法(最短加權路徑法)、最少分詞法、基於HMM的分詞法、基於互現資訊的分詞方法、基於字元標註的方法和基於例項的漢語分詞方法等。 1.最大匹配法 最大匹配法需要一個詞表,分詞的過程中用文字的候選
Python+NLTK自然語言處理學習(二):常用方法(similar、common_contexts、generate)
一、similar 用來識別文章中和搜尋詞相似的詞語,可以用在搜尋引擎中的相關度識別功能中。 text1.similar("monstrous") 查詢出了text1中與monstrous相關的所有詞語: 二、common_contexts 用來識別2個
Python自然語言處理實戰(1):NLP基礎
從建模的角度看,為了方便計算機處理,自然語言可以被定義為一組規則或符號的集合,我們組合集合中的符號來傳遞各種資訊。自然語言處理研究表示語言能力、語言應用的模型,通過建立計算機框架來實現這樣的語言模型,並且不斷完善這樣的語言模型,還需要根據語言模型來設計各種實用的系
自然語言處理工具包 HanLP在 Spring Boot中的應用
本文共 782字,閱讀大約需要 2分鐘 ! 概 述 HanLP 是基於 Java開發的 NLP工具包,由一系列模型與演算法組成,目標是普及自然語言處理在生產環境中的應用。而且 HanLP具備功能完善、效能高效、架構清晰、語料時新、可自定義的特點,因此十分好上手,本文就結合 Spring Bo
Hanlp自然語言處理工具的使用演練
Hanlp是由一系列模型與演算法組成的工具包,目標是普及自然語言處理在生產環境中的應用。Hanlp具備功能完善、效能高效、架構清洗、語料時新、可自定義的特點;提供詞法分析(中文分詞、磁性標註、命名實體識別)、句法分析、文字分類和情感分析等功能。 本篇將使用者輸入的語句根據詞庫進行分詞、關鍵詞提取、摘要提取、
哈工大自然語言處理工具pyltp的本地安裝方法
在研究中發現,哈工大的LTP在分詞、實體識別等方面的效果甚至要優於中科院ICTCLAS,而且LTP還具備了目前在中文資訊處理領域較為罕見的語義角色標註(SRL)功能。以前我都是直接以get方式通過LTP-Cloud去使用的,但是由於受限於網速,當語料較大時 執行速度較慢。於是近期考慮在自己的機子
Spring Boot中對自然語言處理工具包hanlp的呼叫詳解
概 述 HanLP 是基於 Java開發的 NLP工具包,由一系列模型與演算法組成,目標是普及自然語言處理在生產環境中的應用。而且 HanLP具備功能完善、效能高效、架構清晰、語料時新、可自定義的特點,因此十分好上手,本文就結合 Spring Boot來將 HanLP用起來!