
自然語言處理技術(NLP)在推薦系統中的應用
作者: 張相於,58集團演算法架構師,轉轉搜尋推薦部負責人,負責搜尋、推薦以及演算法相關工作。多年來主要從事推薦系統以及機器學習,也做過計算廣告、反作弊等相關工作,並熱衷於探索大資料和機器學習技術在其他領域的應用實踐。
責編:何永燦([email protected])
本文為《程式設計師》原創文章,更多精彩文章請訂閱《程式設計師》
概述
個性化推薦是大資料時代不可或缺的技術,在電商、資訊分發、計算廣告、網際網路金融等領域都起著重要的作用。具體來講,個性化推薦在流量高效利用、資訊高效分發、提升使用者體驗、長尾物品挖掘等方面均起著核心作用。在推薦系統中經常需要處理各種文字類資料,例如商品描述、新聞資訊、使用者留言等等。具體來講,我們需要使用文字資料完成以下任務:
- 候選商品召回。候選商品召回是推薦流程的第一步,用來生成待推薦的物品集合。這部分的核心操作是根據各種不同的推薦演算法來獲取到對應的物品集合。而文字類資料就是很重要的一類召回演算法,具有不依賴使用者行為、多樣性豐富等優勢,在文字資訊豐富或者使用者資訊缺乏的場合中具有非常重要的作用。
- 相關性計算。相關性計算充斥著推薦系統流程的各個步驟,例如召回演算法中的各種文字相似度演算法以及使用者畫像計算時用到的一些相關性計算等。
- 作為特徵參與模型排序(CTR/CVR)。在候選集召回之後的排序層,文字類特徵常常可以提供很多的資訊,從而成為重要的排序特徵。
但是相比結構化資訊(例如商品的屬性等),文字資訊在具體使用時具有一些先天缺點。
首先,文字資料中的結構資訊量少。嚴格來說,文字資料通常是沒有什麼結構的,一般能夠有的結構可能只是“標題”、“正文”、“評論”這樣區分文字來源的結構,除此以外一般就沒有更多的結構資訊了。為什麼我們要在意結構資訊呢?因為結構代表著資訊量,無論是使用演算法還是業務規則,都可以根據結構化資訊來制定推薦策略,例如“召回所有顏色為藍色的長款羽絨服”這樣一個策略裡就用到了“顏色”和“款式”這兩個結構化資訊。但是如果商品的描述資料庫中沒有這樣的結構化資訊,只有一句“該羽絨服為藍色長款羽絨服”的自由文字,那麼就無法利用結構資訊制定策略了。
其次,文字內容的資訊量不確定。與無結構化相伴隨的,是文字資料在內容的不確定性,這種不確定性體現在內容和數量上,例如不同使用者對同一件二手商品的描述可能差異非常大,具體可能在用詞、描述、文字長短等方面都具有較大差異。同樣的兩個物品,在一個物品的描述中出現的內容在另外一個物品中並不一定會出現。這種差異性的存在使得文字資料往往難以作為一種穩定可靠的資料來源來使用,尤其是在UGC化明顯的場景下更是如此。
再次,自由文字中的歧義問題較多。歧義理解是自然語言處理中的重要研究課題,同時歧義也影響著我們在推薦系統中對文字資料的使用。例如使用者在描述自己的二手手機時可能會寫“出售iPhone6一部,打算湊錢買iPhone7”這樣的話,這樣一句對人來說意思很明確的話,卻對機器造成了很大困擾:這個手機究竟是iPhone6還是iPhone7?在這樣的背景下如何保證推薦系統的準確率便成為了一個挑戰。
但是文字資料也不是一無是處,有缺點的同時也具有一些結構化資料所不具有的優點:
- 資料量大。無結構化的文字資料一般來說是非常容易獲得的,例如各種UGC渠道,以及網路爬取等方法,都可穿獲得大量文字資料。
- 多樣性豐富。無結構化是一把雙刃劍,不好的一面已經分析過,好的一面就是由於其開放性,導致具有豐富的多樣性,會包含一些結構規定以外的資料。
- 資訊及時。在一些新名詞,新事物出現之後,微博、朋友圈常常是最先能夠反應出變化的地方,而這些都是純文字的資料,對這些資料的合理分析,能夠最快得到結構化、預定義資料所無法得到的資訊,這也是文字資料的優勢。
綜上所述,文字資料是一類量大、複雜、豐富的資料,對推薦系統起著重要的作用,本文將針對上面提到的幾個方面,對推薦系統中常見的文字處理方法進行介紹。
從這裡出發:詞袋模型
詞袋模型(Bag of Words,簡稱BOW模型)是最簡單的文字處理方法,其核心假設非常簡單,就是認為一篇文件是由文件中的片語成的多重集合(多重集合與普通集合的不同在於考慮了集合中元素的出現次數)構成的。這是一種最簡單的假設,沒有考慮文件中諸如語法、詞序等其他重要因素,只考慮了詞的出現次數。這樣簡單的假設顯然丟掉了很多資訊,但是帶來的好處是使用和計算都比較簡單,同時也具有較大的靈活性。
在推薦系統中,如果將一個物品看作一個詞袋,我們可以根據袋中的詞來召回相關物品,例如使用者瀏覽了一個包含“羽絨服”關鍵詞的商品,我們可以召回包含“羽絨服”的其他商品作為該次推薦的候選商品,並且可以根據這個詞在詞袋中出現的次數(詞頻)對召回商品進行排序。
這種簡單的做法顯然存在著很多問題:
首先,將文字進行分詞後得到的詞裡面,並不是每個詞都可以用來做召回和排序,例如“的地得你我他”這樣的“停用詞”就該去掉,此外,一些出現頻率特別高或者特別低的詞也需要做特殊處理,否則會導致召回結果相關性低或召回結果過少等問題。
其次,使用詞頻來度量重要性也顯得合理性不足。以上面的“羽絨服”召回為例,如果在羽絨服的類別裡使用“羽絨服”這個詞在商品描述中的出現頻率來衡量商品的相關性,會導致所有的羽絨服都具有類似的相關性,因為在描述中大家都會使用類似數量的該詞彙。所以我們需要一種更為科學合理的方法來度量文字之間的相關性。
除了上面的用法,我們還可以將詞袋中的每個詞作為一維特徵加入到排序模型中。例如,在一個以LR為模型的CTR排序模型中,如果這一維特徵的權重為w,則可解釋為“包含這個詞的樣本相比不包含這個詞的樣本在點選率的log odds上要高出w”。在排序模型中使用詞特徵的時候,為了增強特徵的區分能力,我們常常會使用簡單詞袋模型的一種升級版——N-gram詞袋模型。
N-gram指的就是把N個連續的詞作為一個單位進行處理,例如:“John likes to watch movies.Mary likes movies too.”這句話處理為簡單詞袋模型後的結果為:
["John":1, "likes":2, "to":1, "watch":1, "movies":2, "Mary":1, "too":1]而處理為bigram(2-gram)後的結果為:
["John likes":1, "likes to":1, "to watch":1, "watch movies":1, "Mary likes":1, "likes movies":1, "movies too":1]做這樣的處理有什麼好處呢?如果將bigram作為排序模型的特徵或者相似度計算的特徵,最明顯的好處就是增強了特徵的區分能力,簡單來講就是:兩個有N個bigram重合的物品,其相關性要大於有N個詞重合的物品。從根本上來講,是因為bigram的重合機率要低於1-gram(也就是普通詞)的重合機率。那麼是不是N-gram中的N越大就越好呢?N的增大雖然增強了特徵的區分能力,但是同時也加大了資料的稀疏性,從極端情況來講,假設N取到100,那麼幾乎不會有兩個文件有重合的100-gram了,那這樣的特徵也就失去了意義。一般在實際應用中,bigram和trigram(3-gram)能夠在區分性和稀疏性之間取到比較好的平衡,N如果繼續增大,稀疏性會有明顯增加,但是效果卻不會有明顯提升,甚至還會有降低。
綜合來看,雖然詞袋模型存在著明顯的弊端,但是隻需要對文字做簡單處理就可以使用,所以不失為一種對文字資料進行快速處理的使用方法,並且在預處理(常用的預處理包括停用詞的去除,高頻/低頻詞的去除或降權等重要性處理方法,也可以藉助外部高質量資料對自由文字資料進行過濾和限定,以求獲得質量更高的原始資料)充分的情況下,也常常能夠得到很好的效果。
統一度量衡:權重計算和向量空間模型
從上文我們看到簡單的詞袋模型在經過適當預處理之後,可以用來在推薦系統中召回候選物品。但是在計算物品和關鍵詞的相關性,以及物品之間的相關性時,僅僅使用簡單的詞頻作為排序因素顯然是不合理的。為了解決這個問題,我們可以引入表達能力更強的基於TF-IDF的權重計算方法。在TF-IDF方法中,一個詞t在文件d中權重的計算方法為:
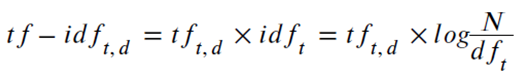
其中tft,d代表t在d中出現的頻次,而dft指的是包含t的文件數目,N代表全部文件的數目。
TF-IDF以及其各種改進和變種(關於TF-IDF變種和改進的詳細介紹,可參考《Introduction to Information Retrieval》的第六章。)相比簡單的TF方法,核心改進在於對一個詞的重要性度量,例如:
- 原始TF-IDF在TF的基礎上加入了對IDF的考慮,從而降低了出現頻率高而導致無區分能力的詞的重要性,典型的如停用詞。
- 因為詞在文件中的重要性和出現次數並不是完全線性相關,非線性TF縮放對TF進行log縮放,從而降低出現頻率特別高的詞所佔的權重。
- 詞在文件中出現的頻率除了和重要性相關,還可能和文件的長短相關,為了消除這種差異,可以使用最大TF對所有的TF進行歸一化。
這些方法的目的都是使對詞在文件中重要性的度量更加合理,在此基礎之上,我們可以對基於詞頻的方法進行改進,例如,可以將之前使用詞頻來對物品進行排序的方法,改進為根據TF-IDF得分來進行排序。
但是除此以外,我們還需要一套統一的方法來度量關鍵詞和文件,以及文件和文件之間的相關性,這套方法就是向量空間模型(Vector Space Model,簡稱VSM)。
VSM的核心思想是將一篇文件表達為一個向量,向量的每一維可以代表一個詞,在此基礎上,可以使用向量運算的方法對文件間相似度進行統一計算,而這其中最為核心的計算,就是向量的餘弦相似度計算:
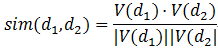
其中V(d1)和V(d2)分別為兩個文件的向量表示。這樣一個看似簡單的計算公式其實有著非常重要的意義。首先,它給出了一種相關性計算的通用思路,那就是隻要能將兩個物品用向量進行表示,就可以使用該公式進行相關性計算。其次,它對向量的具體表示內容沒有任何限制——基於使用者行為的協同過濾使用的也是同樣的計算公式,而在文字相關性計算方面,我們可以使用TFIDF填充向量,同時也可以用N-gram,以及後面會介紹的文字主題的概率分佈、各種詞向量等其他表示形式。只要對該公式的內涵有了深刻理解,就可以根據需求構造合理的向量表示。再次,該公式具有較強的可解釋性,它將整體的相關性拆解為多個分量的相關性的疊加,並且這個疊加方式可以通過公式進行調節,這樣一套方法很容易解釋,即使對非技術人員,也是比較容易理解的,這對於和產品、運營等非技術人員解釋演算法思路有很重要的意義。最後,這個公式在實際計算中可以進行一些很高效的工程優化,使其能夠從容應對大資料環境下的海量資料,這一點是其他相關性計算方法很難匹敵的。
VSM是一種“重劍無鋒,大巧不工”的方法,形態簡單而又變化多端,領會其精髓之後,可以發揮出極大的能量。
透過現象看本質:隱語義模型
前面介紹了文字資料的一些“顯式”使用方法,所謂顯式,是指我們將可讀可理解的文字本身作為了相關性計算、物品召回以及模型排序的特徵。這樣做的好處是簡單直觀,能夠清晰地看到起作用的是什麼,但是其弊端是無法捕捉到隱藏在文字表面之下的深層次資訊。例如,“羽絨服”和“棉衣”指的是類似的東西,“羽絨服”和“棉鞋”具有很強的相關性,類似這樣的深層次資訊,是顯式的文字處理所無法捕捉的,因此我們需要一些更復雜的方法來捕捉,而隱語義模型(Latent Semantic Analysis,簡稱LSA)便是這類方法的鼻祖之一。
隱語義模型中的“隱”指的是隱含的主題,這個模型的核心假設,是認為雖然一個文件由很多的片語成,但是這些詞背後的主題並不是很多。換句話說,詞不過是由背後的主題產生的,這背後的主題才是更為核心的資訊。這種從詞下沉到主題的思路,貫穿著我們後面要介紹到的其他模型,也是各種不同文字主體模型(Topic Model)的共同中心思想,因此理解這種思路非常的重要。
在對文件做LSA分解之前,我們需要構造文件和詞之間的關係,一個由5個文件和5個片語成的簡單例子如下:
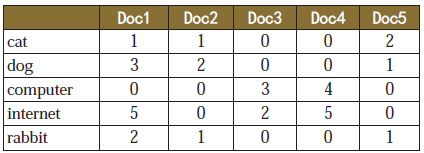
LSA的做法是將這個原始矩陣C進行如下形式的SVD分解:
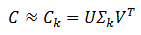
其中U是矩陣CCT的正交特徵向量矩陣,V是矩陣CTC的正交特徵向量矩陣,∑k是包含前k個奇異值的對角矩陣,k是事先選定的一個降維引數。
- 得到原始資料的一個低維表示,降低後的維度包含了更多的資訊,可以認為每個維度代表了一個主題。
- 降維後的每個維度包含了更豐富的資訊,例如可以識別近義詞和一詞多義。
- 可以將不在訓練文件中的文件d通過
變換為新向量空間內的一個向量(這樣的變換無法捕捉到新文件中的資訊,例如詞的共現,以及新詞的出現等等,所以該模型需要定期進行全量訓練。),從而可以在降維後的空間裡計算文件間相似度。由於新的向量空間包含了同義詞等更深層的資訊,這樣的變換會提高相似度計算的準確率和召回率。
為什麼LSA能具有這樣的能力?我們可以從這樣一個角度來看待:CCT中每個元素CCTi,j代表同時包含詞i和詞j的文件數量,而CTC中每個元素CTCi,j代表文件i和文件j共享的詞的數量。所以這兩個矩陣中包含了不同詞的共同出現情況,以及文件對詞的共享情況,通過分解這些資訊得到了類似主題一樣比關鍵詞資訊量更高的低維度資料。
從另外一個角度來看,LSA相當於是對文件進行了一次軟聚類,降維後的每個維度可看做是一個類,而文件在這個維度上的取值則代表了文件對於這個聚類的歸屬程度。
LSA處理之後的資料推薦中能做什麼用呢?首先,我們可以將分解後的新維度(主題維度)作為索引的單位對物品進行索引,來替代傳統的以詞為單位的索引,再將使用者對物品的行為對映為對新維度的行為。這兩個資料準備好之後,就可以使用新的資料維度對候選商品進行召回,召回之後可以使用VSM進行相似度計算,如前文所述,降維後的計算會帶來更高的準確率和召回率,同時也能夠減少噪音詞的干擾,典型的,即使兩個文件沒有任何共享的詞,它們之間仍然會存在相關性,而這正是LSA帶來的核心優勢之一。此外,還可以將其作為排序模型的排序特徵。
簡單來講,我們能在普通關鍵詞上面使用的方法,在LSA上面仍然全部可用,因為LSA的本質就是對原始資料進行了語義的降維,只需將其看作是資訊量更豐富的關鍵詞即可。
可以看到LSA相比關鍵詞來說前進了一大步,主要體現在資訊量的提升,維度的降低,以及對近義詞和多義詞的理解。但是LSA同時也具有一些缺點,例如:
- 訓練複雜度高。LSA的訓練時通過SVD進行的,而SVD本身的複雜度是很高的,在海量文件和海量詞彙的場景下難以計算,雖然有一些優化方法可降低計算的複雜度,但該問題仍然沒有得到根本解決。
- 檢索(召回)複雜度高。如上文所述,使用LSA做召回需要先將文件或者查詢關鍵詞對映到LSA的向量空間中,這顯然也是一個耗時的操作。
- LSA中每個主題下詞的值沒有概率含義,甚至可能出現負值,只能反應數值大小關係。這讓我們難以從概率角度來解釋和理解主題和詞的關係,從而限制了我們對其結果更豐富的使用。
概率的魔力:概率隱語義模型
為了進一步發揚隱語義模型的威力,並盡力克服LSA模型的問題,Thomas Hofmann在1999年提出了概率隱語義模型(probabilistic Latent Semantic Analysis,簡稱pLSA)。從前面LSA的介紹可以看出,雖然具體的優化方法使用的是矩陣分解,但是從另一個角度來講,我們可以認為分解後的U和V兩個矩陣中的向量,分別代表文件和詞在隱語義空間中的表示,例如一個文件的隱向量表示為(1,2,0)T, 代表其在第一維隱向量上取值為1,第二維上取值為2,第三維上取值為0。如果這些取值能夠構成一個概率分佈,那麼不僅模型的結果更利於理解,同時還會帶來很多優良的性質,這正是pLSA思想的核心:將文件和詞的關係看作概率分佈,然後試圖找出這個概率分佈來,有了文件和詞的概率分佈,我們就可以得到一切我們想要得到的東西了。
在pLSA的基本假設中,文件d和詞w的生成過程如下:
- 以 P(d) 的概率選擇文件d。
- 以 P(z|d) 的概率選擇隱類z。
- 以 P(w|z) 的概率從z生成w。
- P(z|d)和P(w|z) 均為多項式分佈。
將這個過程用聯合概率進行表達得到:
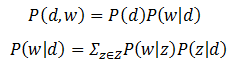
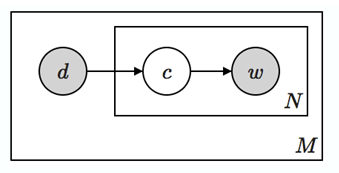
可以看到,我們將隱變數z作為中間橋樑,將文件和詞連線了起來,形成了一個定義良好、環環相扣的概率生成鏈條(如圖1所示)。雖然pLSA的核心是一種概率模型,但是同樣可以用類似LSI的矩陣分解形式進行表達。為此,我們將LSI中等號右邊的三個矩陣進行重新定義:
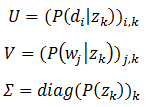
在這樣的定義下,原始的矩陣C仍然可以表述為C=U∑VT。這樣的對應關係讓我們更加清晰地看到了前面提到的pLSA在概率方面的良好定義和清晰含義,同時也揭示了隱語義概率模型和矩陣分解之間的密切關係(關於概率模型和矩陣分解的密切關係可參考這篇文件:http://www.cs.cmu.edu/~epxing/Class/10708-15/slides/LDA_SC.pdf)。在這樣的定義,隱變數z所代表的主題含義更加明顯,也就是說,我們可以明確的把一個z看作一個主題,主題裡的詞和文件中的主題都有著明確的概率含義。也正是由於這樣良好的性質,再加上優化方法的便捷性,使得從pLSA開始,文字主題開始在各種大資料應用中佔據重要地位。
從矩陣的角度來看,LSA和pLSA看上去非常像,但是它們的內涵卻有著本質的不同,這其中最為重要的一點就是兩者的優化目標是完全不同的:LSA本質上是在優化SVD分解後的矩陣和原始矩陣之間的平方誤差,而pLSA本質上是在優化似然函式,是一種標準的機器學習優化套路。也正是由於這一點本質的不同,導致了兩者在優化結果和解釋能力方面的不同。
至此我們看到,pLSA將LSA的思想從概率分佈的角度進行了一大步擴充套件,得到了一個性質更加優良的結果,但是pLSA仍然存在一些問題,主要包括:
- 由於pLSA為每個文件生成一組文件級引數,模型中引數的數量隨著與文件數成正比,因此在文件數較多的情況下容易過擬合。
- pLSA將每個文件d表示為一組主題的混合,然而具體的混合比例卻沒有對應的生成概率模型,換句話說,對於不在訓練集中的新文件,pLSA無法給予一個很好的主題分佈。簡言之,pLSA並非完全的生成式模型。
而LDA的出現,就是為了解決這些問題。
概率的概率:生成式概率模型
為了解決上面提到的pLSA存在的問題,David Blei等人在2003年提出了一個新模型,名為“隱狄利克雷分配”(Latent Dirichlet Allocation,簡稱LDA),這個名字念起來頗為隱晦,而且從名字上似乎也看不出究竟是個什麼模型,在這裡我們試著做一種可能的解讀:
- Latent:這個詞不用多說,是說這個模型仍然是個隱語義模型。
- Dirichlet:這個詞是在說該模型涉及到的主要概率分散式狄利克雷分佈。
- Allocation:這個詞是在說這個模型的生成過程就是在使用狄利克雷分佈不斷地分配主題和詞。
上面並非官方解釋,但希望能對理解這個模型能起到一些幫助作用。
LDA的中心思想就是在pLSA外面又包了一層先驗,使得文件中的主題分佈和主題下的詞分佈都有了生成概率,從而解決了上面pLSA存在的“非生成式”的問題,順便也減少了模型中的引數,從而解決了pLSA的另外一個問題。在LDA中為一篇文件di生成詞的過程如下:
- 從泊松分佈中抽樣一個數字N作為文件的長度(這一步並非必須,也不影響後面的過程)。
- 從狄利克雷分佈Dir(α)中抽樣一個樣本θi,代表該篇文件下主題的分佈。
- 從狄利克雷分佈Dir(β)中抽樣一組樣本Φk,代表每個主題下詞的分佈。
- 對於1到N的每個詞wn:
- 從多項式分佈Multinomial(θi) 中抽樣一個主題ci,j。
- 從多項式分佈Multinomial(Φi) 中抽樣一個詞wi,j。
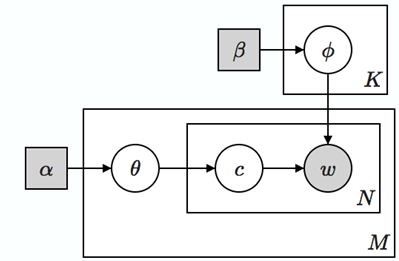
忽略掉最開始選擇文件長度的步驟,我們發現LDA的生成過程相比pLSA來講,在文件到主題的分佈和主題到詞的分佈上面都加了一層概率,使得這兩者都加上了一層不確定性,從而能夠很自然地容納訓練文件中沒有出現過的文件和詞,這使得LDA具有了比pLSA更好的概率性質。
LDA的應用
這部分我們介紹LDA在用作相似度計算和排序特徵時需要注意的一些地方,然後介紹以LDA為代表的文字主題在推薦系統中更多不同角度的應用。
相似度計算
上面提到LSA可以直接套用到VSM中進行相似度計算,在LDA中也可以做類似的計算,具體方法是把文件的主題分佈值向量化然後用餘弦公式進行計算。但是把餘弦相似度替換為KL divergence或Jensen–Shannon divergence效果更好,原因是LDA給出的主題分佈是含義明確的概率值,用度量概率之間相似度的方法來進行度量更為合理。
排序特徵
將物品的LDA主題作為排序模型的特徵是一種很自然的使用方法,但並不是所有的主題都有用。物品上的主題分佈一般有兩種情況:
- 有少數主題(三個或更少)佔據了比較大的概率,剩餘的主題概率加起來比較小。
- 所有主題的概率值都差不多,都比較小。
在第一種情況下,只有前面幾個概率比較大的主題是有用的,而在第二種情況下,基本上所有的主題都沒有用。那麼該如何識別這兩種情況呢?第一種方法,可以根據主題的概率值對主題做一個簡單的K-Means聚類,K選為2,如果是第一種情況,那麼兩個類中的主題數量會相差較大——一個類中包含少量有用主題,另一個類包含其他無用主題;而第二種情況下主題數量則相差不大,可以用這種方法來識別主題的重要性。第二種方法,可以計算主題分佈的資訊熵,第一種情況對應的資訊熵會比較小,而第二種情況會比較大,選取合適的閾值也可以區分這兩種情況。
物品打標籤&使用者打標籤
為物品計算出其對應的主題,以及主題下面對應的詞分佈之後,我們可以選取概率最大的幾個主題,然後從這幾個主題下選取概率最大的幾個詞,作為這個物品的標籤。在此基礎上,如果使用者對該物品發生了行為,則可以將這些標籤傳播到使用者身上。
這種方法打出的標籤,具有非常直觀的解釋,在適當場景下可以充當推薦解釋的理由。例如我們在做移動端個性化推送時,可供展示文案的空間非常小,可以通過上面的方式先為物品打上標籤,然後再根據使用者把標籤傳播到使用者身上,在推送時將這些標籤詞同時作為召回源和推薦理由,讓使用者明白為什麼給他做出這樣的推薦。
主題&詞的重要性度量
LDA訓練生成的主題中,雖然都有著同等的位置,但是其重要性卻是各不相同的,有的主題包含了重要的資訊,有的則不然。例如,一個主題可能包含“教育、讀書、學校”等詞,和這樣主題相關的文件,一般來說是和教育相關的主題,那麼這就是一個資訊量高的主題;相反,有的主題可能會包含“第一冊、第二冊、第三冊……”等詞(如果在一個圖書銷售網站的所有圖書上訓練LDA,就有可能得到這樣的主題,因為有很多套裝圖書都包含這樣的資訊),和這樣主題相關的文件卻有可能是任何主題,這樣的主題就是資訊量低的主題。
如何區分主題是否重要呢?從上面的例子中我們可以得到啟發:重要的主題不會到處出現,只會出現在小部分與之相關的文件中,而不重要的主題則可能在各種文章中都出現。基於這樣的思想,我們可以使用資訊熵的方法來衡量一個主題中的資訊量。通過對LDA輸出資訊做適當的變換,我們可以得到主題θi在不同文件中的概率分佈,然後我們對這個概率分佈計算其資訊熵,通俗來講資訊熵衡量了一個概率分佈中概率值分散程度,越分散熵越大,越集中熵越小。所以在我們的問題中,資訊熵越小的主題,說明該主題所對應的文件越少,主題的重要性越高。
使用類似的方法,我們還可以計算詞的重要性,在此不再贅述。
更多應用
除了上面提到的,LDA還有很多其他應用,甚至在文字領域以外的影象等領域也存在著廣泛應用。LSA/pLSA/LDA這些主題模型的核心基礎是詞在文件中的共現,在此基礎上才有了各種概率分佈,把握住這個核心基礎,就可以找到文字主體模型的更多應用。例如,協同過濾問題中,基礎資料也是使用者對物品的共同行為,這也構成了文字主題模型的基礎,因此也可以使用LDA對使用者對物品的行為進行建模,得到使用者行為的主題,以及主題下對應的物品,然後進行物品/使用者的推薦。
捕捉上下文資訊:神經概率語言模型
以LDA為代表的文字主題模型通過對詞的共現資訊的分解處理,得到了很多有用的資訊,但是pLSA/LDA有一個很重要的假設,那就是文件集合中的文件,以及一篇文件中的詞在選定了主題分佈的情況下都是相互獨立,可交換的,換句話說,模型中沒有考慮詞的順序以及詞和詞之間的關係,這種假設隱含了兩個含義:
- 在生成詞的過程中,之前生成的詞對接下來生成的詞是沒有影響的。
- 兩篇文件如果包含同樣的詞,但是詞的出現順序不同,那麼在LDA看來他們是完全相同的。
這樣的假設使得LDA會丟失一些重要的資訊,而近年來得到關注越來越多的以word2vec為代表的神經概率語言模型恰好在這方面和LDA形成了一定程度的互補關係,從而可以捕捉到LDA所無法捕捉到的資訊。
word2vector的中心思想用一句話來講就是:A word is characterized by the company it keeps(一個詞的特徵由它周圍的詞所決定)。
這是一句頗有哲理的話,很像是成語中的“物以類聚人以群分”。具體來講,詞向量模型使用“周圍的詞=>當前詞”或“當前詞=>周圍的詞”這樣的方式構造訓練樣本,然後使用神經網路來訓練模型,訓練完成之後,輸入詞的輸入向量表示便成為了該詞的向量表示,如圖3所示。
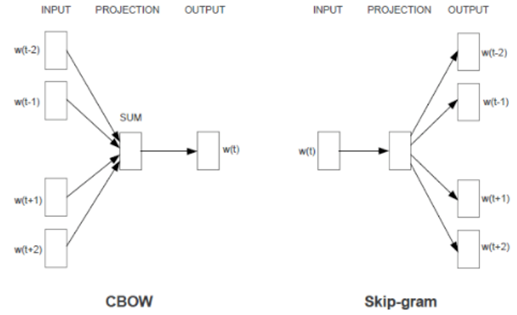
這樣的訓練方式,本質上是在說,如果兩個詞具有類似的上下文(上下文由周圍的片語成),那麼這兩個詞就會具有類似的向量表示。有了詞的向量表示之後,我們可以做很多事情,最常見的是將這一層向量表示作為更深層次模型的一個嵌入層。除了在深度學習中的使用以外,在推薦系統中還可以做很多其他的事情,其中之一就是做詞的聚類,以及尋找相似詞。我們知道LDA天然就可以做到詞的聚類和相似詞的計算,那麼使用word2vec計算出來的結果和LDA有什麼不同呢?它們之間的不同具體體現在兩點:第一是聚類的粒度不同,LDA關注的主題級別的粒度,層次更高,而詞向量關注的是更低層次的語法語義級別的含義。例如“蘋果”,“小米”和“三星”這三個詞,在LDA方法中很可能會被聚類在一個主題中,但是在詞向量的角度來看,“蘋果”和“小米”可能會具有更高的相似度,就像“喬布斯”和“雷軍”在詞向量下的關係一樣,所以在詞向量中可能會有:“vector(小米)- vector(蘋果)+vector(喬布斯)= vector(雷軍)”這樣的結果。
除此以外,由於word2vec有著“根據上下文預測當前內容”的能力,將其做適當修改之後,還可以用來對使用者行為喜好做出預測。首先我們將使用者的行為日誌進行收集,進行session劃分,得到類似文字語料的訓練資料,在這個資料上訓練word2vec模型,可以得到一個“根據上下文行為預測當前行為”的模型。但是原始的行為資料中行為的物件常常是id級的,例如商品、視訊的id等等,如果直接放到模型中訓練,會造成訓練速度慢、泛化能力差等問題,因此需要對原始行為做降維,具體來說可以將行為對映到搜尋詞、LDA Topic、類別等等低維度特徵上,然後再進行訓練。例如,我們可以對使用者的搜尋詞訓練一個word2vec模型,然後就可以根據使用者的歷史搜尋行為預測他的下一步搜尋行為,並在此基礎上進行推薦。這種方法考慮到了上下文,但是對前後關係並沒有做最恰當的處理,因為word2vec的思想是“根據上下文預測當前內容”,但我們希望得到的模型是“根據歷史行為預測下一步行為”,這兩者之間有著微妙的差別。例如使用者的行為序列為“ABCDE”,每個字母代表對一個物品(或關鍵詞)的行為,標準的word2vec演算法可能會構造出下面這些樣本:AC→B, BD→C, CE→D… 但是我們希望的形式其實是這樣的:AB→C, BC→D,CD→E…因此,需要對word2vec生成樣本的邏輯進行修改,使其只包含我們需要的單方向的樣本,方可在最終模型中得到我們真正期望的結果。
下面是按照該方法生成的一些預測例子:
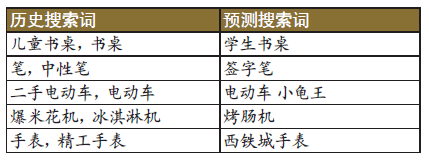
可以看出,預測搜尋詞都與歷史搜尋詞有著緊密的關係,是對歷史搜尋詞的延伸(例如學生書桌和烤腸機的例子)或者細化(例如小龜王和西鐵城手錶的例子),具有比較好的預測屬性,是非常好的推薦策略來源。沿著這樣的思路,我們還可以對word2vec作進一步修改,得到對時序關係更為敏感的模型,以及嘗試使用RNN、LSTM等純時序模型來得到更好的預測結果,但由於篇幅所限,在此不做展開。
行業應用現狀
文字主題模型在被提出之後,由於其良好的概率性質,以及對文字資料有意義的聚類抽象能力,在網際網路的各個行業中都取得了廣泛的應用。搜尋巨頭Google在其系統的各個方面都在廣泛使用文字主題模型,併為此開發了大規模文字主題系統Rephil。例如在為使用者搜尋產生廣告的過程中,就使用了文字主題來計算網頁內容和廣告之間的匹配度,是其廣告產品成功的重要因素之一。此外,在匹配使用者搜尋詞和網頁間關係的時候,文字主題也可用來提高匹配召回率和準確性。Yahoo!也在其搜尋排序模型中大量使用了LDA主題特徵,還為此開源了著名的Yahoo!LDA工具。
在國內,文字主題最著名的系統當屬騰訊開發的Peacock系統,該系統可以捕捉百萬級別的文字主題,在騰訊的廣告分類、網頁分類、精準廣告定向、QQ群分類等重要業務上均起著重要的作用。該系統使用的HDP(Hierarchical Dirichlet Process)模型是LDA模型的一個擴充套件,可智慧選擇資料中主題的數量,還具有捕捉長尾主題的能力。除了騰訊以外,文字主題模型在各公司的推薦、搜尋等業務中也已經在廣泛使用,使用方法根據各自業務有所不同。
以word2vec為代表的神經網路模型近年來的使用也比較廣泛,典型的應用如詞的聚類、近義詞的發現、quer y的擴充套件、推薦興趣的擴充套件等。Facebook開發了一種word2vec的替代方案FastText,該方案在傳統詞向量的基礎上,考慮子詞(subword)的概念,取得了比word2vec更好的效果 。
總結和展望
我們從簡單的文字關鍵詞出發,沿著結構化、降維、聚類、概率、時序的思路,結合推薦系統中候選集召回、相關性計算、排序模型特徵等具體應用,介紹了推薦系統中一些常用的自然語言處理技術和具體應用方法。自然語言處理技術藉著深度學習的東風,近年來取得了長足的進步,而其與推薦系統的緊密關係,也意味著推薦系統在這方面仍然有著巨大的提升空間,讓我們拭目以待。
7月22-23日,本年度中國人工智慧技術會議最強音——2017 中國人工智慧大會(CCAI 2017)即將在杭州國際會議中心拉開序幕。彙集超過40位學術帶頭人、8場權威專家主題報告、4場開放式專題研討會、超過2000位人工智慧專業人士將參與本次會議,歡迎掃描下方二維碼或直接登入【大會官網】購票。
