
更好的理解分析深度卷積神經網路
深度卷積神經網路(CNNs)在特徵識別相關任務中取得的效果,遠比傳統方法好。因此,CNNs常用於影象識別、語音識別等。但是,因為CNNs結構龐大,一般都會包含幾十個神經層,每一層,又有數百至數千個神經元;同時,CNNs任意兩層之間神經元的相互影響錯綜複雜。這兩個主要的因素,導致CNNs難以理解、分析。為此,使用者很難從失敗或成功的例子中學習到如何設計一個好的卷積神經網路。因此,設計一個效果好的神經網路,往往需要依靠大量的嘗試。
這篇文章提出了一個可視分析系統,CNNVis,支援機器學習專家更好的理解、分析、設計深度卷積神經網路。
在介紹可視分析系統之前,我將簡要的介紹卷積神經網路。

圖1. 典型的卷積神經網路結構
上圖展示的是一個典型的卷積神經網路結構。這個網路包含兩個卷積層(convolution layer),兩個池化層(pooling layer)和一個全連線層(fully connected layer)。

圖2. 卷積操作示意圖
卷積層,採用各種卷積核對輸入圖片進行卷積處理,基本卷積過程如圖2所示。卷積操作具有平移不變性。因而,能夠支援神經元學習到魯棒性比較高的特徵。

圖3. 最大池化層。從特定區域中,選取最大值作為輸出值
池化層的操作,是一種降取樣操作。該操作是在一個小區域內,採取一個特定的值作為輸出值。比如圖3,在每個特定的小區域內,我們選取最大值作為輸出值。池化層的操作可以達到一定的空間不變性效果。
卷積神經網路中的激勵函式,根據一系列的輸入值,神經元之間連線的權值以及激勵規則,刺激神經元。
卷積神經網路中的損失函式,在訓練階段,用於評估網路輸出結果與實際值的差異。然後用損失函式的值更新每個神經元之間的權重值。卷積神經網路的訓練目的就是最小化損失函式值。

圖4. CNNVis的設計流程圖
CNNVis的設計流程圖如圖四所示,主要包含四個部分。
DAG轉換主要是將卷積神經網路轉換為有向非迴圈網路(directed acyclic graph);神經元群簇視覺化的目的在於,給使用者一個直觀的視覺化形式分析神經元群簇在整個網路中的作用;基於雙邊聚類的邊捆綁技術的目的是減少檢視的混亂;此外,系統還支援一系列的互動,比如支援使用者修改聚類結果等,以便使用者更好的分析探索整個卷積神經網路。

圖5. DAG轉換及聚類過程
DAG轉換環節,由於一個卷積神經網路往往會有很多層,每一層會有很多神經元。為了提供總覽圖,方便使用者建立對整個卷積神經網路的認識,他們首先對層進行了聚類。然後在每個層聚類中,對內部的神經元進行了聚類(如圖5所示)。

圖6. CNNVis中,矩陣表現形式
在神經元群簇視覺化部分,他們採用矩陣填充技術,將群簇內神經元的輸出影象填充成一個矩陣來表示該群簇特徵。同時,為了方便使用者分析每個神經元在不同類別上效能,他們採用矩陣形式來表示此類資訊。一個群簇用一個矩陣表示。在矩陣中,每一行表示一個神經元,每一列表示一個類別,顏色的深淺表示該神經元在該類別上的判別能力(如圖6所示)。為了更好的表現出該群簇的特點,他們對矩陣中的行進行了重排序,最大化鄰近的兩個行的相似性之和。

圖7. 基於雙邊聚類的邊捆綁技術示意圖
接著,為了減少檢視的混亂,線的交叉,他們提出了基於雙邊聚類的邊捆綁技術。此處的雙邊分別指兩層之間輸入的邊和輸出的邊。如圖7所示,雙邊聚類之後,對每個聚類結果分別進行邊捆綁操作。圖中,綠色表示邊的權值為正,紅色表示其權值為負。
接下來,我將通過一個樣例,展示CNNVis的實用性。在這個例子中,專家們首先設計了包含10個卷積層, 4個池化層和2個全連線層的卷積神經網路BaseCNN,該網路主要用於影象識別。在CNNVis中,專家們發現在比較低的層,神經元傾向於學習一些簡單的模式(圖8(A)),比如邊緣,顏色,條帶燈;在比較高的層,神經元能夠檢測到一些抽象的特徵(圖8(C)),比如整輛轎車等。

圖8. 用CNNVis分析BaseCNN
為了分析卷積神經網路的結構對最後結果的影響,他們設計了另外兩種卷積神經網路來分析網路的深度對結果的影響。表1展示了這三種網路的基本資訊。與BaseCNN相比,ShallowCNN少了三層卷積層和一層池化層;DeepCNN的卷積層和池化層數量是BaseCNN的兩倍。
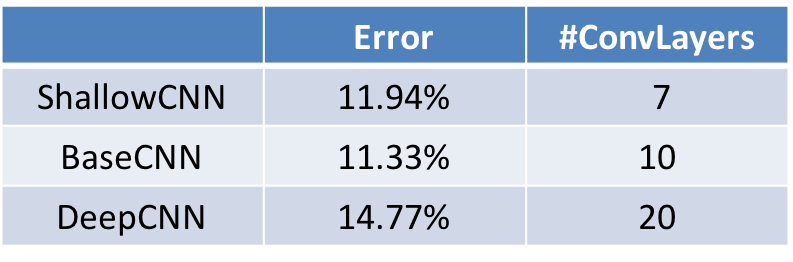
表1. 用於分析卷積神經網路的深度對結果的影響的三種神經網路

圖9. 用CNNVis分析ShallowCNN的高層神經元效能
從圖9,我們可以發現,ShallowCNN的高層神經層,依舊存在好多混亂的群簇(群簇內的影象屬於多種實體)。這表明它沒有足夠多的神經層來區分各種實體。

圖10. 用CNNVis分析DeepCNN的高層神經元效能
從圖10,我們可以發現,DeepCNN的高層神經層之間的邊都是綠色,表明其權重都是正值,這就說明,這內部存在冗餘現象。神經元之間的學習都是正值,基本沒有進行結果的糾正。
接下來,他們嘗試分析,每個神經層內神經元的數量對結果的影響。為此,他們設計了以下五種網路,如表2所示。
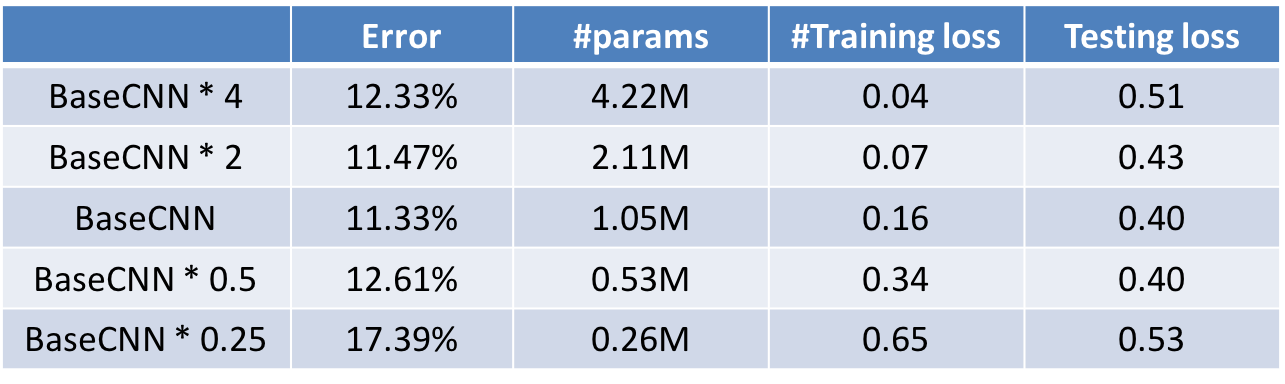
表2. 用於分析卷積神經網路的寬度對結果的影響。BaseCNN * w表示其每個神經層內神經元的個數是BaseCNN的w倍
觀察表2,我們可以發現,BaseCNN * 4的訓練錯誤率很低,但是測驗錯誤率卻比較高。這說明,這個網路出現了過擬合現象。圖11展示了其在CNNVis系統中的現象。我們可以發現,在圖11(a)的矩陣中,大部分行都非常的相似,這就說明,這些神經元在學習相同的特徵。這是一種冗餘現象。

圖11. (a)BaseCNN * 4 在CNNVis中的表現;(b)BaseCNN在CNNVis中的表現
此外,在表2中,我們可以發現BaseCNN * 0.25的訓練錯誤率和測試錯誤率都很高,這是一種欠擬合現象。圖12展示了其在CNNVis中的現象,我們可以發現,即使是高層的神經元簇,每個群簇內的結果都比較混亂。這說明,該網路沒有足夠的神經元學習影象中的特徵,進而區分不同類別的影象。

圖12. BaseCNN * 0.25的高層神經元在CNNVis中的表現
總的來說,該工作提出了一個可視分析系統來支援機器學習專家更好的理解,分析,設計深度卷積神經網路。很多機器學習演算法都有與卷積神經網路相似的特點,難以理解、分析,引數設定麻煩等。結合適合的可視分析技巧,個人覺得可以有效的將這些黑盒子透明化,方便相關的研究者更好的理解、分析、設計這些機器學習演算法。
相關推薦
更好的理解分析深度卷積神經網路
深度卷積神經網路(CNNs)在特徵識別相關任務中取得的效果,遠比傳統方法好。因此,CNNs常用於影象識別、語音識別等。但是,因為CNNs結構龐大,一般都會包含幾十個神經層,每一層,又有數百至數千個神經元;同時,CNNs任意兩層之間神經元的相互影響錯綜複雜。這兩個主要的因素,導致CNNs難以理解、分析。為此
基於深度卷積神經網路的單通道人聲與音樂的分離-論文翻譯
主體內容:作為當前的一大熱門,語音識別在得到快速應用的同時,也要更適應不同場景的需求,特別是對於智慧手機而言,由於元器件的微型化導致對於語音處理方面的器件不可能很大,因此單通道上的語音分離技術就顯得極為重要,而語音分離正是語音識別的前端部分。而傳統的技術由於資
tensorflow學習筆記(第一天)-深度卷積神經網路
一、在這裡首先需要了解一些概念性的東西,當然我是才接觸,還不太熟悉: 1.numpy NumPy系統是Python的一種開源的數值計算擴充套件。這種工具可用來儲存和處理大型矩陣,比Python自身的巢狀列表(nested l
深度卷積神經網路學習(一)
卷積神經網路的基礎模組為卷激流包括卷積(用於維數拓展)、非線性(洗屬性、飽和、側抑制)、池化(空間或特徵型別的聚合)和批量歸一化(優化操作,目的是為了加快訓練過程中的收斂速度,同事避免陷入區域性最優)等四種操作。下面簡單介紹這四種操作。 1、卷積:利用卷積核對輸入影象進行處
深度學習 --- 深度卷積神經網路詳解(AlexNet 網路詳解)
本篇將解釋另外一個卷積神經網路,該網路是Hinton率領的谷歌團隊(Alex Krizhevsky,Ilya Sutskever,Geoffrey E. Hinton)在2010年的ImageNet大賽獲得冠軍的一個神經網路,因此本節主要參考的論文也是這次大賽的論文即“Imag
基於動態場景去模糊的多尺度深度卷積神經網路
Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring- CVPR2017 主要貢獻 1、提出 多尺度學習CNN框架,實現由粗到細的方法提高了網路的收斂速度 之後多尺度
基於深度卷積神經網路(D-CNN)的影象去噪方法
基於深度卷積神經網路的影象去噪方法 摘要:影象去噪在影象處理中仍然是一個具有挑戰性的問題。作者提出了一種基於深度卷積神經網路(DCNN)的影象去噪方法。作者設計的不同於其他基於學習的方法:一個DCNN來實現噪聲影象。因此,通過從汙染影象中分離噪聲影
【Coursera】吳恩達 deeplearning.ai 04.卷積神經網路 第二週 深度卷積神經網路 課程筆記
深度卷積神經網路 2.1 為什麼要進行例項化 實際上,在計算機視覺任務中表現良好的神經網路框架,往往也適用於其他任務。 2.2 經典網路 LeNet-5 AlexNet VGG LeNet-5 主要針對灰度影象 隨著神經網路的加深
吳恩達《深度學習-卷積神經網路》2--深度卷積神經網路
1. Why look at case studies本節展示幾個神經網路的例項分析為什麼要講例項?近些年CNN的主要任務就是研究如何將基本構件(CONV、POOL、CF)組合起來形成有效的CNN,而學習瞭解前人的做法可以激發創造2. Classic Networks1)Le
基於FPGA的深度卷積神經網路的加速器設計
翻譯:卜居 【0. 摘要】 CNN已經廣泛用於影象識別,因為它能模仿生物視覺神經的行為獲得很高識別準確率。最近,基於深度學習演算法的現代應用高速增長進一步改善了研究和實現。特別地,多種基於FPGA平臺的深度CNN加速器被提出,具有高效能、可重配置、快速開發週期等優勢。
論文理解:基於卷積神經網路的人臉識別方法
本文是對陳耀丹、王連明的基於卷積神經網路的人臉識別方法的理解。 摘要:實現了一種基於卷積神經網路的人臉識別方法,該網路由兩個卷積層,兩個池化層、一個全連線層和一個softmax迴歸層組成,它能自動提取人臉特徵並進行分類,網路通過批量梯度下降法訓練特徵提取器和分
深度卷積神經網路影象風格變換 Deep Photo Style Transfer
深度卷積神經網路影象風格變換 Taylor Guo, 2017年4月23日 星期日 - 4月27日星期四 摘要 本文介紹了深度學習方法的影象風格轉換,處理各種各樣的影象內容,保持高保真的參考風格變換。我們的方法構建於最近繪畫風格變換基礎上,用神經網路的不同網路層從影
深度卷積神經網路在目標檢測中發展
近些年來,深度卷積神經網路(DCNN)在影象分類和識別上取得了很顯著的提高。回顧從2014到2016這兩年多的時間,先後湧現出了R-CNN,Fast R-CNN, Faster R-CNN, ION, HyperNet, SDP-CRC, YOLO,G-CNN, SSD等越來越快速和準確的目標檢測方法。 基
深度卷積神經網路的14種設計模式
機器之心編譯 參與:吳攀、武競、李澤南、蔣思源、李亞洲 這篇論文的作者是來自美國海軍研究實驗室的 Leslie N. Smith 和來自美國馬里蘭大學的 Nicholay Topin,他們在本論文中總結了深度卷積神經網路的 14 種設計模式;其中包括:1. 架構
深度卷積神經網路在目標檢測中的進展
近些年來,深度卷積神經網路(DCNN)在影象分類和識別上取得了很顯著的提高。回顧從2014到2016這兩年多的時間,先後湧現出了R-CNN,Fast R-CNN, Faster R-CNN, ION, HyperNet, SDP-CRC, YOLO,G-CN
優化基於FPGA的深度卷積神經網路的加速器設計
翻譯:卜居【0. 摘要】CNN已經廣泛用於影象識別,因為它能模仿生物視覺神經的行為獲得很高識別準確率。最近,基於深度學習演算法的現代應用高速增長進一步改善了研究和實現。特別地,多種基於FPGA平臺的深度CNN加速器被提出,具有高效能、可重配置、快速開發週期等優勢。儘管目前FP
基於深度卷積神經網路進行人臉識別的原理是什麼?
我這裡簡單講下OpenFace中實現人臉識別的pipeline,這個pipeline可以看做是使用深度卷積網路處理人臉問題的一個基本框架,很有學習價值,它的結構如下圖所示:1、Input Image -> Detect輸入:原始的可能含有人臉的影象。輸出:人臉位置的bounding box。這一步一般我
深度卷積神經網路學習筆記(一)
1.卷積操作實質: 輸入影象(input volume),在深度方向上由很多slice組成,對於其中一個slice,可以對應很多神經元,神經元的weight表現為卷積核的形式,即一個方形的濾波器(filter)(如3X3),這些神經元各自分別對應影象中的某一個區域性區域(local region
論文閱讀-為什麼深度卷積神經網路對小目標的變換泛化效果很差?
論文地址: Why do deep convolutional networks generalize so poorly to small image transformations? 1. 摘要 該論文發現,現代深度卷積神經網路在影象中的小目標發生平移後對其類別的判斷會產
深度學習框架--深度卷積神經網路CNNs的多GPU並行框架 及其在影象識別的應用
將深度卷積神經網路(Convolutional Neural Networks, 簡稱CNNs)用於影象識別在研究領域吸引著越來越多目光。由於卷積神經網路結構非常適合模型並行的訓練,因此以模型並行+資料並行的方式來加速Deep CNNs訓練,可預期取得較大收穫。Deep CNNs的單機多G