
第十八節、基於傳統影象處理的目標檢測與識別(HOG+SVM附程式碼)
其實在深度學習分類中我們已經介紹了目標檢測和目標識別的概念、為了照顧一些沒有學過深度學習的童鞋,這裡我重新說明一次:目標檢測是用來確定影象上某個區域是否有我們要識別的物件,目標識別是用來判斷圖片上這個物件是什麼。識別通常只處理已經檢測到物件的區域,例如,人們總是會使在已有的人臉影象的區域去識別人臉。
傳統的目標檢測方法與識別不同於深度學習方法,後者主要利用神經網路來實現分類和迴歸問題。在這裡我們主要介紹如何利用OpecnCV來實現傳統目標檢測和識別,在計算機視覺中有很多目標檢測和識別的技術,這裡我們主要介紹下面幾塊內容:
- 方向梯度直方圖HOG(Histogram of Oriented Gradient);
- 影象金字塔;
- 滑動視窗;
上面這三塊內容其實後面兩塊我們之前都已經介紹過,由於內容也比較多,這裡不會比較詳細詳細介紹,下面我們從HOG說起。
一 HOG
HOG特徵是一種在計算機視覺和影象處理中用來進行物體檢測的特徵描述子,是與SIFT、SURF、ORB屬於同一型別的描述符。HOG不是基於顏色值而是基於梯度來計算直方圖的,它通過計算和統計影象區域性區域的梯度方向直方圖來構建特徵。HOG特徵結合SVM分類器已經被廣泛應用到影象識別中,尤其在行人檢測中獲得了極大的成功。
1、主要思想
此方法的基本觀點是:區域性目標的外表和形狀可以被區域性梯度或邊緣方向的分佈很好的描述,即使我們不知道對應的梯度和邊緣的位置。(本質:梯度的統計資訊,梯度主要存在於邊緣的地方)
2、實施方法
首先將影象分成很多小的連通區域,我們把它叫做細胞單元,然後採集細胞單元中各畫素點的梯度和邊緣方向,然後在每個細胞單元中累加出一個一維的梯度方向直方圖。
為了對光照和陰影有更好的不變性,需要對直方圖進行對比度歸一化,這可以通過把這些直方圖在影象的更大的範圍內(我們把它叫做區間或者block)進行對比度歸一化。首先我們計算出各直方圖在這個區間中的密度,然後根據這個密度對區間中的各個細胞單元做歸一化。我們把歸一化的塊描述符叫作HOG描述子。
3、目標檢測
將檢測視窗中的所有塊的HOG描述子組合起來就形成了最終的特徵向量,然後使用SVM分類器進行行人檢測。下圖描述了特徵提取和目標檢測流程。檢測視窗劃分為重疊的塊,對這些塊計算HOG描述子,形成的特徵向量放到線性SVM中進行目標/非目標的二分類。檢測視窗在整個影象的所有位置和尺度上進行掃描,並對輸出的金字塔進行非極大值抑制來檢測目標。(檢測視窗的大小一般為$128\times{64}$)

二 演算法的具體實現
1、影象標準化(調節影象的對比度)
為了減少光照因素的影響,降低影象區域性的陰影和光照變化所造成的影響,我們首先採用Gamma校正法對輸入影象的顏色空間進行標準化(或者說是歸一化)。
所謂的Gamma校正可以理解為提高影象中偏暗或者偏亮部分的影象對比效果,能夠有效地降低影象區域性的陰影和光照變化。更詳細的內容可以點選這裡檢視影象處理之gamma校正。
Gamma校正公式為:
$$f(I)=I^\gamma$$
其中$I$為影象畫素值,$\gamma$為Gamma校正係數。$\gamma$係數設定影響著影象的調整效果,結合下圖,我們來看一下Gamma校正的作用:
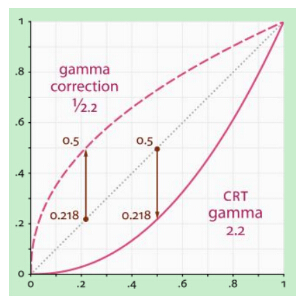
$\gamma<1$在低灰度值區域內,動態範圍變大,影象對比度增加強;在高灰度值區域,動態範圍變小,影象對比度降低,同時,影象的整體灰度值變大;
$\gamma>1$在低灰度值區域內,動態範圍變小,影象對比度降低;在高灰度值區域,動態範圍變大,影象對比度提高,同時,影象的整體灰度值變小;

左邊的影象為原圖,中間影象的$\gamma=\frac{1}{2.2}$,右圖$\gamma=2.2$。
作者在他的博士論文裡有提到,對於涉及大量的類內顏色變化,如貓,狗和馬等動物,沒標準化的RGB圖效果更好,而牛,羊的圖做gamma顏色校正後效果更好。是否用gamma校正得分析具體的訓練集情況。
2、影象平滑(具體視情況而定)
對於灰度影象,一般為了去除噪點,所以會先利用高斯函式進行平滑:高斯函式在不同的平滑尺度下對灰度影象進行平滑操作。Dalal等實驗表明moving from σ=0 to σ=2 reduces the recall rate from 89% to 80% at 10?4 FPPW,即不做高斯平滑人體檢測效果最佳,使得漏檢率縮小了約一倍。不做平滑操作,可能原因:HOG特徵是基於邊緣的,平滑會降低邊緣資訊的對比度,從而減少影象中的有用資訊。
3、邊緣方向計算
計算影象每個畫素點的梯度、包括方向和大小:
$$G_x(x,y)=I(x+1,y)-I(x-1,y)$$
$$G_y(x,y)=I(x,y+1)-I(x,y-1)$$
上式中$G_x(x,y)、G_y(x,y)$分別表示輸入影象在畫素點$(x,y)$處的水平方向梯度和垂直方向梯度,畫素點在$(x,y)$的梯度幅值和梯度方向分別為:
$$G(x,y)=\sqrt{G_x(x,y)^2+G_y(x,y)^2}$$
$$\alpha=arctan\frac{G_y(x,y)}{G_x(x,y)}$$
4、直方圖計算
將影象劃分成小的細胞單元(細胞單元可以是矩形的或者環形的),比如大小為$8\times{8}$,然後統計每一個細胞單元的梯度直方圖,即可以得到一個細胞單元的描述符,將幾個細胞單元組成一個block,例如$2\times{2}$個細胞單元組成一個block,將一個block內每個細胞單元的描述符串聯起來即可以得到一個block的HOG描述符。
在說到統計一個細胞單元的梯度直方圖時,我們一般考慮採用9個bin的直方圖來統計這$8\times{8}$個畫素的梯度資訊,即將cell的梯度方向0~180°(或0~360°,即考慮了正負)分成9個方向塊,如下圖所示:
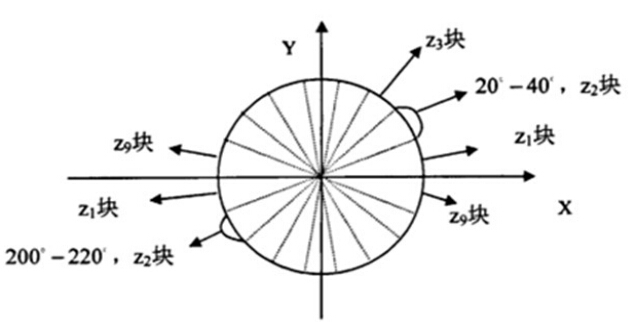
如果cell中某一個畫素的梯度方向是20~40°,直方圖第2個bin的計數就要加1,這樣對cell中的每一個畫素用梯度方向在直方圖中進行加權投影(權值大小等於梯度幅值),將其對映到對應的角度範圍塊內,就可以得到這個cell的梯度方向直方圖了,就是該cell對應的9維特徵向量。對於梯度方向位於相鄰bin的中心之間(如20°、40°等)需要進行方向和位置上的雙線性插值。
採用梯度幅值量級本身得到的檢測效果最佳,而使用二值的邊緣權值表示會嚴重降低效果。採用梯度幅值作為權重,可以使那些比較明顯的邊緣的方向資訊對特徵表達影響增大,這樣比較合理,因為HOG特徵主要就是依靠這些邊緣紋理。
根據Dalal等人的實驗,在行人目標檢測中,在無符號方向角度範圍並將其平均分成9份(bins)能取得最好的效果,當bin的數目繼續增大效果改變不明顯,故一般在人體目標檢測中使用bin數目為9範圍0~180°的度量方式。
5、對block歸一化
由於區域性光照的變化,以及前景背景對比度的變化,使得梯度強度的變化範圍非常大,這就需要對梯度做區域性對比度歸一化。歸一化能夠進一步對光照、陰影、邊緣進行壓縮,使得特徵向量對光照、陰影和邊緣變化具有魯棒性。
具體的做法:將細胞單元組成更大的空間塊(block),然後針對每個塊進行對比度歸一化。最終的描述子是檢測視窗內所有塊內的細胞單元的直方圖構成的向量。事實上,塊之間是有重疊的,也就是說,每個細胞單元的直方圖都會被多次用於最終的描述子的計算。塊之間的重疊看起來有冗餘,但可以顯著的提升效能 。
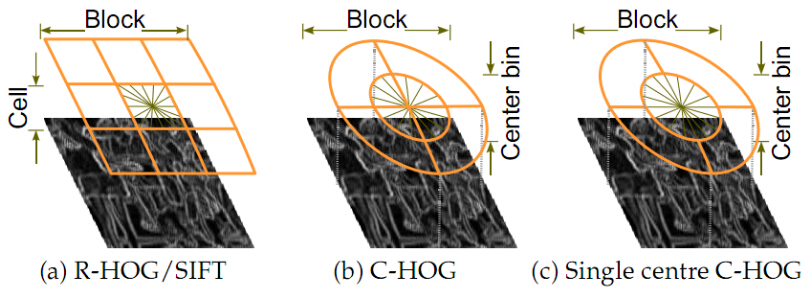
通常使用的HOG結構大致有三種:矩形HOG(簡稱為R-HOG),圓形HOG和中心環繞HOG。它們的單位都是Block(即塊)。Dalal的試驗證明矩形HOG和圓形HOG的檢測效果基本一致,而環繞形HOG效果相對差一些。
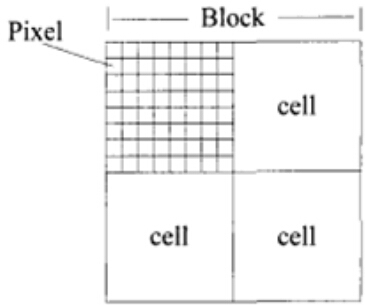
如上圖,一個塊由$2\times{2}$個cell組成,每一個cell包含$8\times{8}$個畫素點,每個cell提取9個直方圖通道,因此一個塊的特徵向量長度為$2\times{2}\times{9}$。
假設$v$是未經歸一化的特徵向量。 $\|v\|_k$是$v$的$k$範數,$k=1,2$,是一個很小的常數,對塊的特徵向量進行歸一化,一般有以下四種方法:
- $L_2-norm$:$v←\frac{v}{\sqrt{\|v\|_2^2+\xi^2}}$($\xi$是一個很小的數,主要是為了防止分母為0);
- $L_2-Hys$:先計算$L_2$範數,然後限制$v$的最大值為0.2,再進行歸一化;
- $L_1-norm$:$v←\frac{v}{|v\|_1+\xi}$;
- $L_1-sqrt$:$v←\sqrt{\frac{v}{\|v\|_1+\xi}}$;
在人體檢測系統中進行HOG計算時一般使用$L_2-norm$,Dalal的文章也驗證了對於人體檢測系統使用$L_2-norm$的時候效果最好。
6、樣本HOG特徵提
最後一步就是對一個樣本中所有的塊進行HOG特徵的手機,並將它們結合成最終的特徵向量送入分類器。
那麼一個樣本可以提取多少個特徵呢?之前我們已經說過HOG特徵的提取過程:
- 首先把樣本圖片分割為若干個畫素的單元,然後把梯度方向劃分為9個區間,在每個單元裡面對所有畫素的梯度方向在各個方向區間進行直方圖統計,得到一個9維的特徵向量;
- 每相鄰4個單元構成一個塊,把一個塊內的特徵向量串聯起來得到一個36維的特徵向量;
- 用塊對樣本影象進行掃描,掃描步長為一個單元的大小,最後將所有的塊的特徵串聯起來,就得到一個樣本的特徵向量;
例如:對於$128\times{64}$的輸入圖片(後面我所有提到的影象大小指的是$h\times{w}$),每個塊由$2\times{2}$個cell組成,每個cell由$8\times{8}$個畫素點組成,每個cell提取9個bin大小的直方圖,以1個cell大小為步長,那麼水平方向有7個掃描視窗,垂直方向有5個掃描視窗,也就是說,一共有$15*7*2*2*9=3780$個特徵。
7、行人檢測HOG+SVM
這裡我們介紹一下Dalal等人的訓練方法:
- 提取正負樣本的HOG特徵;
- 用正負樣本訓練一個初始的分類器,然後由分類器生產檢測器;
- 然後用初始分類器在負樣本原圖上進行行人檢測,檢測出來的矩形區域自然都是分類錯誤的負樣本,這就是所謂的難例(hard examples);
- 提取難例的HOG特徵並結合第一步中的特徵,重新訓練,生成最終的檢測器 ;
這種二次訓練的處理過程顯著提高了每個檢測器的表現,一般可以使得每個視窗的誤報率(FPPW False Positives Per Window)下降5%。
三 手動實現HOG特徵
雖然opencv已經實現了HOG演算法,但是手動實現的目的是為了加深我們對HOG的理解,本程式碼參考了部落格80行Python實現-HOG梯度特徵提取並做了一些調整:
程式碼主要包括以下步驟:
- 影象灰度化,歸一化處理;
- 首先計算影象每一個畫素點的梯度幅值和角度;
- 計算輸入影象的每個cell單元的梯度直方圖(注意,我們在實現梯度直方圖的時候,使用到的是雙線性插值,這和上面介紹的理論略微有區別),形成每個cell的descriptor,比如輸入影象為$128\times{64}$ 可以得到$16\times{8}$個cell,每個cell由9個bin組成;
- 將$2\times{2}$個cell組成一個block,一個block內所有cell的特徵串聯起來得到該block的HOG特徵descriptor,並進行歸一化處理,將影象內所有block的HOG特徵descriptor串聯起來得到該影象的HOG特徵descriptor,這就是最終分類的特徵向量;
# -*- coding: utf-8 -*- """ Created on Mon Sep 24 18:23:04 2018 @author: zy """ #程式碼來源GitHub:https://github.com/PENGZhaoqing/Hog-feature #https://blog.csdn.net/ppp8300885/article/details/71078555 #https://www.leiphone.com/news/201708/ZKsGd2JRKr766wEd.html import cv2 import numpy as np import math import matplotlib.pyplot as plt class Hog_descriptor(): ''' HOG描述符的實現 ''' def __init__(self, img, cell_size=8, bin_size=9): ''' 建構函式 預設引數,一個block由2x2個cell組成,步長為1個cell大小 args: img:輸入影象(更準確的說是檢測視窗),這裡要求為灰度影象 對於行人檢測影象大小一般為128x64 即是輸入影象上的一小塊裁切區域 cell_size:細胞單元的大小 如8,表示8x8個畫素 bin_size:直方圖的bin個數 ''' self.img = img ''' 採用Gamma校正法對輸入影象進行顏色空間的標準化(歸一化),目的是調節影象的對比度,降低影象區域性 的陰影和光照變化所造成的影響,同時可以抑制噪音。採用的gamma值為0.5。 f(I)=I^γ ''' self.img = np.sqrt(img*1.0 / float(np.max(img))) self.img = self.img * 255 #print('img',self.img.dtype) #float64 #引數初始化 self.cell_size = cell_size self.bin_size = bin_size self.angle_unit = 180 / self.bin_size #這裡採用180° assert type(self.bin_size) == int, "bin_size should be integer," assert type(self.cell_size) == int, "cell_size should be integer," assert 180 % self.bin_size == 0, "bin_size should be divisible by 180" def extract(self): ''' 計算影象的HOG描述符,以及HOG-image特徵圖 ''' height, width = self.img.shape ''' 1、計算影象每一個畫素點的梯度幅值和角度 ''' gradient_magnitude, gradient_angle = self.global_gradient() gradient_magnitude = abs(gradient_magnitude) ''' 2、計算輸入影象的每個cell單元的梯度直方圖,形成每個cell的descriptor 比如輸入影象為128x64 可以得到16x8個cell,每個cell由9個bin組成 ''' cell_gradient_vector = np.zeros((int(height / self.cell_size), int(width / self.cell_size), self.bin_size)) #遍歷每一行、每一列 for i in range(cell_gradient_vector.shape[0]): for j in range(cell_gradient_vector.shape[1]): #計算第[i][j]個cell的特徵向量 cell_magnitude = gradient_magnitude[i * self.cell_size:(i + 1) * self.cell_size, j * self.cell_size:(j + 1) * self.cell_size] cell_angle = gradient_angle[i * self.cell_size:(i + 1) * self.cell_size, j * self.cell_size:(j + 1) * self.cell_size] cell_gradient_vector[i][j] = self.cell_gradient(cell_magnitude, cell_angle) #將得到的每個cell的梯度方向直方圖繪出,得到特徵圖 hog_image = self.render_gradient(np.zeros([height, width]), cell_gradient_vector) ''' 3、將2x2個cell組成一個block,一個block內所有cell的特徵串聯起來得到該block的HOG特徵descriptor 將影象image內所有block的HOG特徵descriptor串聯起來得到該image(檢測目標)的HOG特徵descriptor, 這就是最終分類的特徵向量 ''' hog_vector = [] #預設步長為一個cell大小,一個block由2x2個cell組成,遍歷每一個block for i in range(cell_gradient_vector.shape[0] - 1): for j in range(cell_gradient_vector.shape[1] - 1): #提取第[i][j]個block的特徵向量 block_vector = [] block_vector.extend(cell_gradient_vector[i][j]) block_vector.extend(cell_gradient_vector[i][j + 1]) block_vector.extend(cell_gradient_vector[i + 1][j]) block_vector.extend(cell_gradient_vector[i + 1][j + 1]) '''塊內歸一化梯度直方圖,去除光照、陰影等變化,增加魯棒性''' #計算l2範數 mag = lambda vector: math.sqrt(sum(i ** 2 for i in vector)) magnitude = mag(block_vector) + 1e-5 #歸一化 if magnitude != 0: normalize = lambda block_vector, magnitude: [element / magnitude for element in block_vector] block_vector = normalize(block_vector, magnitude) hog_vector.append(block_vector) return np.asarray(hog_vector), hog_image def global_gradient(self): ''' 分別計算影象沿x軸和y軸的梯度 ''' gradient_values_x = cv2.Sobel(self.img, cv2.CV_64F, 1, 0, ksize=5) gradient_values_y = cv2.Sobel(self.img, cv2.CV_64F, 0, 1, ksize=5) #計算梯度幅值 這個計算的是0.5*gradient_values_x + 0.5*gradient_values_y #gradient_magnitude = cv2.addWeighted(gradient_values_x, 0.5, gradient_values_y, 0.5, 0) #計算梯度方向 #gradient_angle = cv2.phase(gradient_values_x, gradient_values_y, angleInDegrees=True) gradient_magnitude, gradient_angle = cv2.cartToPolar(gradient_values_x,gradient_values_y,angleInDegrees=True) #角度大於180°的,減去180度 gradient_angle[gradient_angle>180.0] -= 180 #print('gradient',gradient_magnitude.shape,gradient_angle.shape,np.min(gradient_angle),np.max(gradient_angle)) return gradient_magnitude, gradient_angle def cell_gradient(self, cell_magnitude, cell_angle): ''' 為每個細胞單元構建梯度方向直方圖 args: cell_magnitude:cell中每個畫素點的梯度幅值 cell_angle:cell中每個畫素點的梯度方向 return: 返回該cell對應的梯度直方圖,長度為bin_size ''' orientation_centers = [0] * self.bin_size #遍歷cell中的每一個畫素點 for i in range(cell_magnitude.shape[0]): for j in range(cell_magnitude.shape[1]): #梯度幅值 gradient_strength = cell_magnitude[i][j] #梯度方向 gradient_angle = cell_angle[i][j] #雙線性插值 min_angle, max_angle, weight = self.get_closest_bins(gradient_angle) orientation_centers[min_angle] += (gradient_strength * (1 - weight)) orientation_centers[max_angle] += (gradient_strength *weight) return orientation_centers def get_closest_bins(self, gradient_angle): ''' 計算梯度方向gradient_angle位於哪一個bin中,這裡採用的計算方式為雙線性插值 具體參考:https://www.leiphone.com/news/201708/ZKsGd2JRKr766wEd.html 例如:當我們把180°劃分為9個bin的時候,分別對應對應0,20,40,...160這些角度。 角度是10,副值是4,因為角度10介於0-20度的中間(正好一半),所以把幅值 一分為二地放到0和20兩個bin裡面去。 args: gradient_angle:角度 return: start,end,weight:起始bin索引,終止bin的索引,end索引對應bin所佔權重 ''' idx = int(gradient_angle / self.angle_unit) mod = gradient_angle % self.angle_unit return idx % self.bin_size, (idx + 1) % self.bin_size, mod / self.angle_unit def render_gradient(self, image, cell_gradient): ''' 將得到的每個cell的梯度方向直方圖繪出,得到特徵圖 args: image:畫布,和輸入影象一樣大 [h,w] cell_gradient:輸入影象的每個cell單元的梯度直方圖,形狀為[h/cell_size,w/cell_size,bin_size] return: image:特徵圖 ''' cell_width = self.cell_size / 2 max_mag = np.array(cell_gradient).max() #遍歷每一個cell for x in range(cell_gradient.shape[0]): for y in range(cell_gradient.shape[1]): #獲取第[i][j]個cell的梯度直方圖 cell_grad = cell_gradient[x][y] #歸一化 cell_grad /= max_mag angle = 0 angle_gap = self.angle_unit #遍歷每一個bin區間 for magnitude in cell_grad: #轉換為弧度 angle_radian = math.radians(angle) #計算起始座標和終點座標,長度為幅值(歸一化),幅值越大、繪製的線條越長、越亮 x1 = int(x * self.cell_size + cell_width + magnitude * cell_width * math.cos(angle_radian)) y1 = int(y * self.cell_size + cell_width + magnitude * cell_width * math.sin(angle_radian)) x2 = int(x * self.cell_size + cell_width - magnitude * cell_width * math.cos(angle_radian)) y2 = int(y * self.cell_size + cell_width - magnitude * cell_width * math.sin(angle_radian)) cv2.line(image, (y1, x1), (y2, x2), int(255 * math.sqrt(magnitude))) angle += angle_gap return image if __name__ == '__main__': #載入影象 img = cv2.imread('./image/person.jpg') width = 64 height = 128 img_copy = img[320:320+height,570:570+width][:,:,::-1] gray_copy = cv2.cvtColor(img_copy,cv2.COLOR_BGR2GRAY) #顯示原影象 plt.figure(figsize=(6.4,2.0*3.2)) plt.subplot(1,2,1) plt.imshow(img_copy) #HOG特徵提取 hog = Hog_descriptor(gray_copy, cell_size=8, bin_size=9) hog_vector, hog_image = hog.extract() print('hog_vector',hog_vector.shape) print('hog_image',hog_image.shape) #繪製特徵圖 plt.subplot(1,2,2) plt.imshow(hog_image, cmap=plt.cm.gray) plt.show()
程式執行結果為:
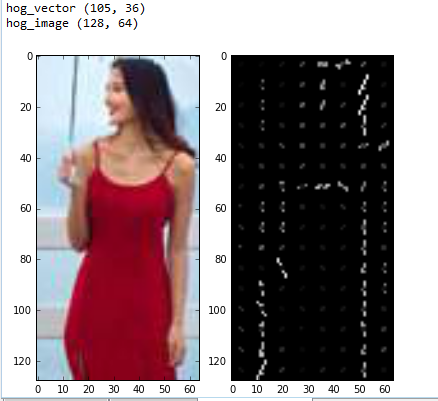
我們可以看到當輸入影象大小為$128\times{64}$時,得到的HOG特徵向量為$105\times{36}=3780$,這和我們計算的一樣,左邊的圖為需要提取HOG特徵的原圖,右圖為所提取得到的特徵圖,我們使用線段長度表示每一個cell中每一個bin的幅值大小(同時線段的亮度也與幅值大小成正比),線段傾斜角度表示cell中每一個bin的角度,從右圖上我們可以大致觀察到這個人的邊緣資訊以及梯度變化,因此利用該特徵可以很容易的識別出人的主要結構。
四 目標檢測中的問題
雖然我們已經介紹了HOG特徵的提取,但是在想把HOG特徵應用到目標檢測上,我們還需考慮兩個問題:
- 尺度:對於這個問題可以通過舉例說明:假如要檢測的目標(比如人)是較大影象中的一部分,要把要檢測的影象和訓練影象比較。如果在比較中找不到一組相同的梯度,則檢測就會失敗(即使兩張影象都有人)。
- 位置:在解決了尺度問題後,還有另一個問題:要檢測的目標可能位於影象上的任一個地方,所以需要掃描影象的每一個地方,以取保找到感興趣的區域,並且嘗試在這些區域檢測目標。即使待檢測的影象中的目標和訓練影象中的目標一樣大,也需要通過某種方式讓opencv定位該目標。
1、影象金字塔
影象金字塔有助於解決不同尺度下的目標檢測問題,影象金字塔使影象的多尺度表示,如下圖所示:

構建影象金字塔一般包含以下步驟(詳細內容可以參考尺度空間理論):
- 獲取影象;
- 使用任意尺度的引數來調整(縮小)影象的大小;
- 平滑影象(使用高斯模糊);
- 如果影象比最小尺度還大,從第一步開會重複這個過程;
在人臉檢測之Haar分類器這一節我們利用haar特徵和級聯分類器Adaboost檢測人臉時我們使用過一個函式detectMultiScale(),這個函式就涉及這些內容,級聯分類器物件嘗試在輸入影象的不同尺度下檢測物件,該函式有一個比較重要的引數scaleFactor(一般設定為1.3),表示一個比率:即在每層金字塔中所獲得的影象與上一層影象的比率,scaleFactor越小,金字塔的層數就越多,計算就越慢,計算量也會更大,但是計算結果相對更精確。
下面我們在對人進行檢測時候也會再次使用到這個函式。
2、滑動視窗
滑動視窗是用在計算機視覺的一種技術,它包括影象中要移動部分(滑動視窗)的檢查以及使用影象金字塔對各部分進行檢測。這是為了在多尺度下檢測物件。
滑動視窗通過掃描較大影象的較小區域來解決定位問題,進而在同一影象的不同尺度下重複掃描。
使用這種方法進行目標檢測會出現一個問題:區域重疊,針對區域重疊問題,我們可以利用非極大值抑制(詳細內容可以參考第二十七節,IOU和非極大值抑制),來消除重疊的視窗。
五 使用opencv檢測人
下面我們介紹使用OpenCV自帶的HOGDescriptor()函式對人進行檢測:
# -*- coding: utf-8 -*- """ Created on Mon Sep 24 16:43:37 2018 @author: zy """ ''' HOG檢測人 ''' import cv2 import numpy as np def is_inside(o,i): ''' 判斷矩形o是不是在i矩形中 args: o:矩形o (x,y,w,h) i:矩形i (x,y,w,h) ''' ox,oy,ow,oh = o ix,iy,iw,ih = i return ox > ix and oy > iy and ox+ow < ix+iw and oy+oh < iy+ih def draw_person(img,person): ''' 在img影象上繪製矩形框person args: img:影象img person:人所在的邊框位置 (x,y,w,h) ''' x,y,w,h = person cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,255),2) def detect_test(): ''' 檢測人 ''' img = cv2.imread('./image/person.jpg') rows,cols = img.shape[:2] sacle = 1.0 #print('img',img.shape) img = cv2.resize(img,dsize=(int(cols*sacle),int(rows*sacle))) #print('img',img.shape) #建立HOG描述符物件 #計算一個檢測視窗特徵向量維度:(64/8 - 1)*(128/8 - 1)*4*9 = 3780 ''' winSize = (64,128) blockSize = (16,16) blockStride = (8,8) cellSize = (8,8) nbins = 9 hog = cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nbins) ''' hog = cv2.HOGDescriptor() #hist = hog.compute(img[0:128,0:64]) 計算一個檢測視窗的維度 #print(hist.shape) detector = cv2.HOGDescriptor_getDefaultPeopleDetector() print('detector',type(detector),detector.shape) hog.setSVMDetector(detector) #多尺度檢測,found是一個數組,每一個元素都是對應一個矩形,即檢測到的目標框 found,w = hog.detectMultiScale(img) print('found',type(found),found.shape) #過濾一些矩形,如果矩形o在矩形i中,則過濾掉o found_filtered = [] for ri,r in enumerate(found): for qi,q in enumerate(found): #r在q內? if ri != qi and is_inside(r,q): break else: found_filtered.append(r) for person in found_filtered: draw_person(img,person) cv2.imshow('img',img) cv2.waitKey(0) cv2.destroyAllWindows() if __name__=='__main__': detect_test()
輸出如下:

其中有一點我們需要注意,opencv自帶的檢測器大小是3781維度的,這是因為在預設引數下,我們從$128\times{64}$的檢測視窗中提取的特徵向量為3780維度,而我們的檢測器採用的是支援向量機,最終的檢測方法是基於線性判別函式$wx+b=0$。在訓練檢測器時,當把特徵維度為3780的特徵送到SVM中訓練,得到的$w$維度也為3780,另外還有一個偏置$b$,因此檢測器的維度為3781。
detector = cv2.HOGDescriptor_getDefaultPeopleDetector() print('detector',type(detector),detector.shape)
另外我在囉嗦一下:在訓練的時候,我們的正負樣本影象預設大小都應該是$128\times{64}$的,然後提取樣本影象的HOG特徵,也就是3780維度的特徵向量,送入到SVM進行訓練,最終的目的就是得到這3781維度的檢測器。
在測試的時,檢測視窗(大小為$128\times{64}$)在整個影象的所有位置和尺度上進行掃描,然後提取提取每一個視窗的HOG特徵,送入檢測器進行判別,最後還需要對輸出的金字塔進行非極大值抑制。例如:這裡有張圖是$720\times{475}$的,我們選$200\times{100}$大小的patch,把這個patch從圖片裡面摳出來,然後再把大小調整成$128\times{64}$,計算HOG特徵,並送入檢測器判別是否包含目標。

但是當我們想檢測其他目標時,比如一輛車這時候高與寬的比可能就不是2:1了,這時候我們就需要修改HOG物件的配置引數:
#計算一個檢測視窗特徵向量維度:(64-8)/8*(128-8)/8*4*9 = 3780 winSize = (64,128) blockSize = (16,16) blockStride = (8,8) cellSize = (8,8) nbins = 9 hog = cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nbins)
上面的是預設引數,針對不同的目標檢測我們一般需要修改為適合自己目標大小的引數:
- winSize:檢查視窗大小,一般為blockStride的整數倍;
- blockSize:塊大小,一般為cellSize的整數倍;
- blockStride:塊步長,一般為cellSize的整數倍;
- cellSize:每一個細胞單元大小;
- nbins:每一個細胞單元提取的直方圖bin的個數;
計算公式:
沿$x$軸塊的個數$m = [(winSize_x - blockSize_x)/blockStride_x+1]$向下取整;
沿$y$軸塊的個數$n = [(winSize_y - blockSize_y)/blockStride_x+1]$向下取整;
一個block內的特徵向量維度為$c = (blockSize_x/cellSize_x) * (blockSize_y/cellSize_y)*nbins$;
那麼特徵向量維度 $t = m*n* c$
我們再來形象的說明檢測視窗的特徵向量維度是如何計算的,因為這個很重要:

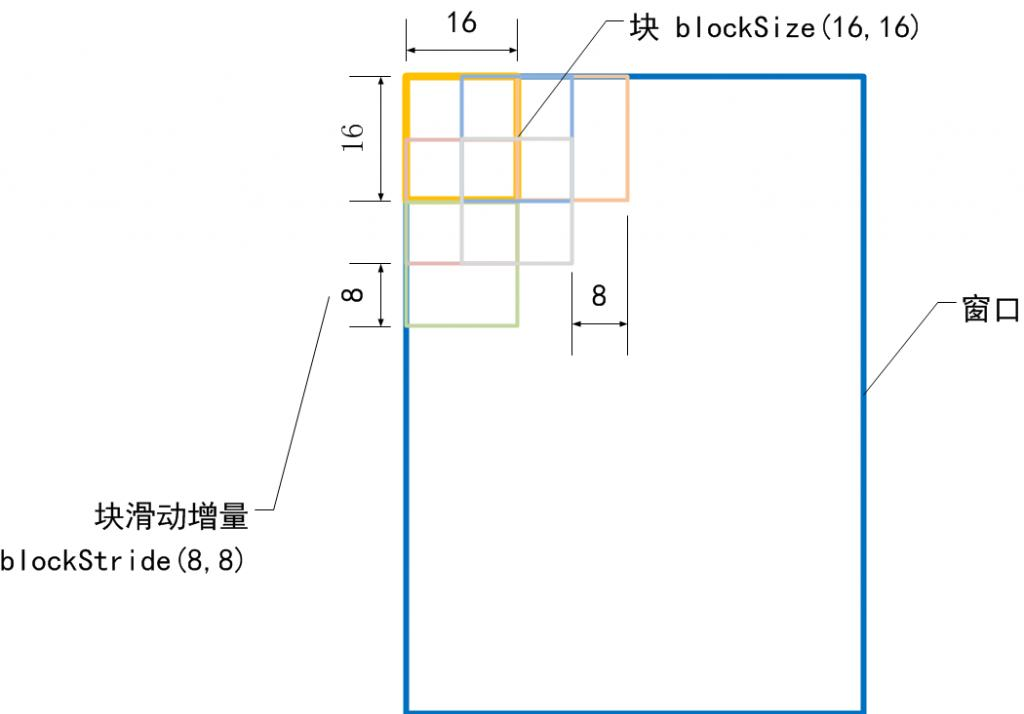
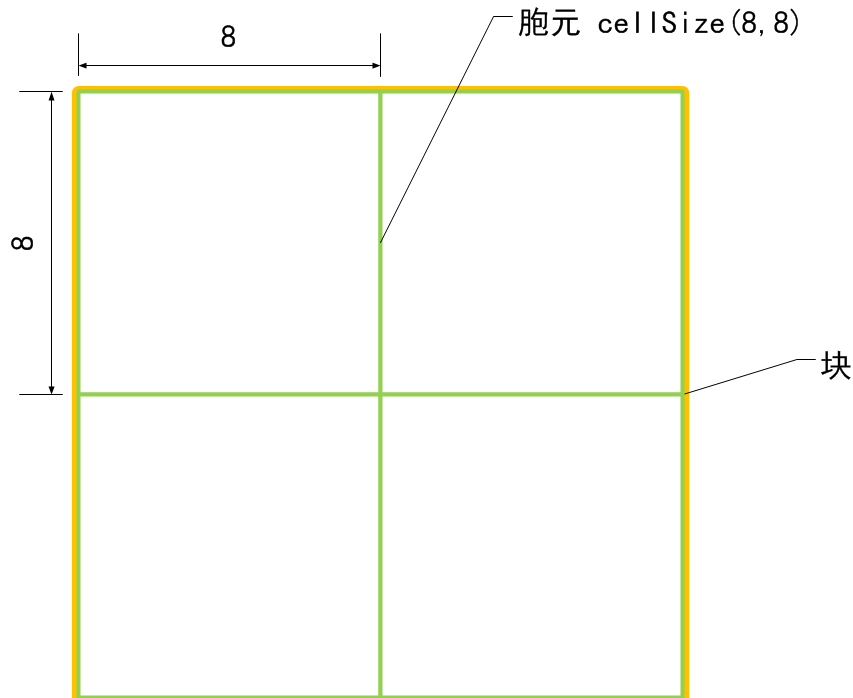
看明白了吧?如果再不明白,那你再看看上面的原理吧!!!!!
六 總結
HOG的優點:
- 核心思想是所檢測的區域性物體外形能夠被梯度或邊緣方向的分佈所描述,HOG能較好地捕捉區域性形狀資訊,對幾何和光學變化都有很好的不變性;
- HOG是在密集取樣的影象塊中求取的,在計算得到的HOG特徵向量中隱含了該塊與檢測視窗之間的空間位置關係。
HOG的缺陷:
- 很難處理遮擋問題,人體姿勢動作幅度過大或物體方向改變也不易檢測(這個問題後來在DPM中採用可變形部件模型的方法得到了改善);
- 跟SIFT相比,HOG沒有選取主方向,也沒有旋轉梯度方向直方圖,因而本身不具有旋轉不變性(較大的方向變化),其旋轉不變性是通過採用不同旋轉方向的訓練樣本來實現的;
- 跟SIFT相比,HOG本身不具有尺度不變性,其尺度不變性是通過縮放檢測視窗影象的大小來實現的;
- 此外,由於梯度的性質,HOG對噪點相當敏感,在實際應用中,在block和cell劃分之後,對於得到各個區域,有時候還會做一次高斯平滑去除噪點。
參考文章:
[10]OpenCV 3計算機視覺
相關推薦
第十八節、基於傳統影象處理的目標檢測與識別(HOG+SVM附程式碼)
其實在深度學習分類中我們已經介紹了目標檢測和目標識別的概念、為了照顧一些沒有學過深度學習的童鞋,這裡我重新說明一次:目標檢測是用來確定影象上某個區域是否有我們要識別的物件,目標識別是用來判斷圖片上這個物件是什麼。識別通常只處理已經檢測到物件的區域,例如,人們總是會使在已有的人臉影象的區域去識別人臉。 傳統的目
第十八節、基於傳統圖像處理的目標檢測與識別(HOG+SVM附代碼)
當我 陰影 .fig 來源 end 映射 形狀 itl eee 其實在深度學習分類中我們已經介紹了目標檢測和目標識別的概念、為了照顧一些沒有學過深度學習的童鞋,這裏我重新說明一次:目標檢測是用來確定圖像上某個區域是否有我們要識別的對象,目標識別是用來判斷圖片上這個對象是什麽
第十九節、基於傳統影象處理的目標檢測與識別(詞袋模型BOW+SVM附程式碼)
在上一節、我們已經介紹了使用HOG和SVM實現目標檢測和識別,這一節我們將介紹使用詞袋模型BOW和SVM實現目標檢測和識別。 一 詞袋介紹 詞袋模型(Bag-Of-Word)的概念最初不是針對計算機視覺的,但計算機視覺會使用該概念的升級。詞袋最早出現在神經語言程式學(NLP)和資訊檢索(IR)領域,該模型
影象處理——目標檢測與前背景分離
前提 運動目標的檢測是計算機影象處理與影象理解領域裡一個重要課題,在機器人導航、智慧監控、醫學影象分析、視訊影象編碼及傳輸等領域有著廣泛的應用。
基於MATLAB影象處理的中值濾波、均值濾波以及高斯濾波的實現與對比
基於MATLAB影象處理的中值濾波、均值濾波以及高斯濾波的實現與對比 作者:lee神 1.背景知識 中值濾波法是一種非線性平滑技術,它將每一畫素點的灰度值設定為該點某鄰域視窗內的所有畫素點灰度值的中值. 中值濾波是基於排序統計理論的一種能有效抑制噪聲的非線性訊號處
第十三節、用 Proxy 進行預處理
相信大家對鉤子函式會有一定的瞭解,這裡簡單解釋一下什麼是鉤子函式。當我們在操作一個物件或者方法時會有幾種動作,比如:在執行函式前初始化一些資料,在改變物件值後做一些善後處理。這些都算鉤子函式,Proxy 的存在就可以讓我們給函式加上這樣的鉤子函式,你也可以理解為
第十二、十三周作業【Linux微職位】
馬哥教育一、結合圖形描述LVS的工作原理;lvs-nat模型主要是修改目標IP地址為挑選出新的RS的IP地址。即請求進入負載均衡器時做DNAT,響應出負載均衡器時做SNAT。1.當用戶請求到達Director Server,此時請求的數據報文會先到達內核的PREROUTING鏈,此時報文的源IP是CIP,目標
構建之法第十一、十二章
交互 業界 用戶體驗 可用性 找到 方法 認同 我認 設計 用戶體驗有幾個層次:1 最基礎的是在交互環節,就是usablity,可用性,或者說易用性,大家說得最多的;要把可用性做好,不是太難,業界有成熟的方法,不需要太多天賦,兩個字:“用心”即可。 2 更高層次的乃情
第十七、十八周微職位:tomcat,MogileFS
十八周 第十七 微職位 1、描述Tomcat的架構;Tomcat組件,分為4類:頂層類組件:包括<Server>元素和<Service>元素,它們位於整個配置文件的頂層;連接器類組件:為<Connector>元素,代表介於客戶端與服務器端之間的通信接口,負責將客
第十八節,TensorFlow中使用批量歸一化
item con 用法 它的 線性 dev 樣本 需要 sca 在深度學習章節裏,已經介紹了批量歸一化的概念,詳情請點擊這裏:第九節,改善深層神經網絡:超參數調試、正則化以優化(下) 由於在深層網絡中,不同層的分布都不一樣,會導致訓練時出現飽和的問題。而批量歸一化就是為了緩
【php增刪改查實例】第十八節 - login.php編寫
ray str for -o arr ech gin and 用戶表 1.對用戶名和密碼進行非空判斷(後臺驗證) $username; $password; if(isset($_POST[‘username‘]) && $_POS
第十章、日常運維(上)
抓取 進入 fff 0.11 cpu rip 筆記 裏來 ifd 10.1 使用w查看系統負載 10.2 vmstat命令 10.3 top命令 10.4 sar命令 10.5 nload命令 10.6 監控io性能 10.7 free命令 10.8 ps命令 10.9 查
學習筆記第十八節:卡特蘭數
前話 本樓主是蒟蒻,居然最近才搞懂了卡特蘭數,在這裡總結一下,最基礎的總結。 正題 定義卡特蘭數為: 卡特蘭數的遞推式是:
網絡操作系統第十二、十三章習題
使用 地址 tro 如果 操作系統 asc 就是 e-mail 選中 第十二章習題 1.簡述FTP的連接模式。 答:FTP的連接模式有RORT和PASV兩種,其中RORT是主動模式,PASV是被動模式,這裏說的主動和被動都是相對與服務器而言的。如果是主動模式,數據端
Java學習第十七、十八、十九天總結
常用類及一些常用方法 常用類 系統相關的兩個類 1.System(代表了系統執行平臺) System.currentTimeMillis()是獲得系統當前時間的函式 返回的是系統當前時間和1970-01-01午夜時間的差值得毫秒值 System.nanoTim
Office辦公自動化 第三章、excl電子表格處理
1.第三章excl電子表格處理 一、辦公室表格處理軟體: 1.office Excel 2.wps excel 二、excel2010介面組成部分 1.單元格名稱 2.功能選項卡 3.標題欄 4.功能面板 5.編輯區 6.單元格 7.工作表導航按鈕 8.工作表標
機器學習學習筆記 第十六章 基於貝葉斯的新聞分類
利用貝葉斯分類器進行文字分類 考慮情況 1 對於文字分析,首先我們應該先利用停用詞語料庫對部分大量出現的停用詞進行遮蔽,可以百度直接搜停用詞進行下載 我們對於經常出現的詞,有可能是一個不太重要的詞,比
Java程式設計思想 第十二章:通過異常處理錯誤
發現錯誤的理想時機是在編譯階段,也就是程式在編碼過程中發現錯誤,然而一些業務邏輯錯誤,編譯器並不能一定會找到錯誤,餘下的問題需要在程式執行期間解決,這就需要發生錯誤的地方能夠準確的將錯誤資訊傳遞給某個接收者,以便接收者知道如何正確的處理這個錯誤資訊。 改進錯誤的機制在Java中尤為重要,
基於STM32影象處理的機器人自動充電解決方案---三
接上一篇基於STM32影象處理的機器人自動充電解決方案---二 第4章 自主導航與避障設計 4.1自主導航設計