
AdaBoost原理詳解
寫一點自己理解的AdaBoost,然後再貼上面試過程中被問到的相關問題。按照以下目錄展開。
當然,也可以去我的部落格上看
- Boosting提升演算法
- AdaBoost
- 原理理解
- 例項
- 演算法流程
- 公式推導
- 面經
Boosting提升演算法
AdaBoost是典型的Boosting演算法,屬於Boosting家族的一員。在說AdaBoost之前,先說說Boosting提升演算法。Boosting演算法是將“弱學習演算法“提升為“強學習演算法”的過程,主要思想是“三個臭皮匠頂個諸葛亮”。一般來說,找到弱學習演算法要相對容易一些,然後通過反覆學習得到一系列弱分類器,組合這些弱分類器得到一個強分類器。Boosting演算法要涉及到兩個部分,加法模型和前向分步演算法。加法模型就是說強分類器由一系列弱分類器線性相加而成。一般組合形式如下:
$$F_M(x;P)=\sum_{m=1}^nβ_mh(x;a_m)$$
其中,$h(x;a_m)$ 就是一個個的弱分類器,$a_m$是弱分類器學習到的最優引數,$β_m$就是弱學習在強分類器中所佔比重,$P$是所有$a_m$和$β_m$的組合。這些弱分類器線性相加組成強分類器。
前向分步就是說在訓練過程中,下一輪迭代產生的分類器是在上一輪的基礎上訓練得來的。也就是可以寫成這樣的形式:
$$F_m (x)=F_{m-1}(x)+ β_mh_m (x;a_m)$$
由於採用的損失函式不同,Boosting演算法也因此有了不同的型別,AdaBoost就是損失函式為指數損失的Boosting演算法。
AdaBoost
原理理解
基於Boosting的理解,對於AdaBoost,我們要搞清楚兩點:
- 每一次迭代的弱學習$h(x;a_m)$有何不一樣,如何學習?
- 弱分類器權值$β_m$如何確定?
對於第一個問題,AdaBoost改變了訓練資料的權值,也就是樣本的概率分佈,其思想是將關注點放在被錯誤分類的樣本上,減小上一輪被正確分類的樣本權值,提高那些被錯誤分類的樣本權值。然後,再根據所採用的一些基本機器學習演算法進行學習,比如邏輯迴歸。
對於第二個問題,AdaBoost採用加權多數表決的方法,加大分類誤差率小的弱分類器的權重,減小分類誤差率大的弱分類器的權重。這個很好理解,正確率高分得好的弱分類器在強分類器中當然應該有較大的發言權。
例項
為了加深理解,我們來舉一個例子。
有如下的訓練樣本,我們需要構建強分類器對其進行分類。x是特徵,y是標籤。
| 序號 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
令權值分佈$D_1=(w_{1,1},w_{1,2},…,w_{1,10} )$
並假設一開始的權值分佈是均勻分佈:$w_{1,i}=0.1,i=1,2,…,10$
現在開始訓練第一個弱分類器。我們發現閾值取2.5時分類誤差率最低,得到弱分類器為:
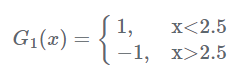
當然,也可以用別的弱分類器,只要誤差率最低即可。這裡為了方便,用了分段函式。得到了分類誤差率$e_1=0.3$。
第二步計算$(G_1 (x)$在強分類器中的係數$α_1=\frac{1}{2} log\frac{ 1-e_1}{e_1}=0.4236$,這個公式先放在這裡,下面再做推導。
第三步更新樣本的權值分佈,用於下一輪迭代訓練。由公式:
$$w_{2,i}=\frac{w_{1,i}}{z_1}exp(-α_1 y_i G_1 (x_i )),i=1,2,…,10$$
得到新的權值分佈,從各0.1變成了:
$$D_2=(0.0715,0.0715,0.0715,0.0715,0.0715,0.0715,0.1666,0.1666,0.1666,0.0715)$$
可以看出,被分類正確的樣本權值減小了,被錯誤分類的樣本權值提高了。
第四步得到第一輪迭代的強分類器:
$$sign(F_1 (x))=sign(0.4236G_1 (x))$$
以此類推,經過第二輪……第N輪,迭代多次直至得到最終的強分類器。迭代範圍可以自己定義,比如限定收斂閾值,分類誤差率小於某一個值就停止迭代,比如限定迭代次數,迭代1000次停止。這裡資料簡單,在第3輪迭代時,得到強分類器:
$$sign(F_3 (x))=sign(0.4236G_1 (x)+0.6496G_2 (x)+0.7514G_3 (x))$$
的分類誤差率為0,結束迭代。
$F(x)=sign(F_3 (x))$就是最終的強分類器。
演算法流程
總結一下,得到AdaBoost的演算法流程:
- 輸入:訓練資料集$T=\{(x_1,y_1),(x_2,y_2),(x_N,y_N)\}$,其中,$x_i∈X⊆R^n$,$y_i∈Y={-1,1}$,迭代次數$M$
- 1. 初始化訓練樣本的權值分佈:$D_1=(w_{1,1},w_{1,2},…,w_{1,i}),w_{1,i}=\frac{1}{N},i=1,2,…,N$。
- 2. 對於$m=1,2,…,M$
- (a) 使用具有權值分佈$D_m$的訓練資料集進行學習,得到弱分類器$G_m (x)$
- (b) 計算$G_m(x)$在訓練資料集上的分類誤差率:
$$e_m=\sum_{i=1}^Nw_{m,i} I(G_m (x_i )≠y_i )$$
- (c) 計算$G_m (x)$在強分類器中所佔的權重:
$$α_m=\frac{1}{2}log \frac{1-e_m}{e_m} $$
- (d) 更新訓練資料集的權值分佈(這裡,$z_m$是歸一化因子,為了使樣本的概率分佈和為1):
$$w_{m+1,i}=\frac{w_{m,i}}{z_m}exp(-α_m y_i G_m (x_i )),i=1,2,…,10$$
$$z_m=\sum_{i=1}^Nw_{m,i}exp(-α_m y_i G_m (x_i ))$$
- 3. 得到最終分類器:
$$F(x)=sign(\sum_{i=1}^Nα_m G_m (x))$$
公式推導
現在我們來搞清楚上述公式是怎麼來的。
假設已經經過$m-1$輪迭代,得到$F_{m-1} (x)$,根據前向分步,我們可以得到:
$$F_m (x)=F_{m-1} (x)+α_m G_m (x)$$
我們已經知道AdaBoost是採用指數損失,由此可以得到損失函式:
$$Loss=\sum_{i=1}^Nexp(-y_i F_m (x_i ))=\sum_{i=1}^Nexp(-y_i (F_{m-1} (x_i )+α_m G_m (x_i )))$$
這時候,$F_{m-1}(x)$是已知的,可以作為常量移到前面去:
$$Loss=\sum_{i=1}^N\widetilde{w_{m,i}} exp(-y_i α_m G_m (x_i ))$$
其中,$\widetilde{w_{m,i}}=exp(-y_i (F_{m-1} (x)))$ ,敲黑板!這個就是每輪迭代的樣本權重!依賴於前一輪的迭代重分配。
是不是覺得還不夠像?那就再化簡一下:
$$\widetilde{w_{m,i}}=exp(-y_i (F_{m-1} (x_i )+α_{m-1} G_{m-1} (x_i )))=\widetilde{w_{m-1,i}} exp(-y_i α_{m-1} G_{m-1} (x_i ))$$
現在夠像了吧?ok,我們繼續化簡Loss:
$$Loss=\sum_{y_i=G_m(x_i)}\widetilde{w_{m,i}} exp(-α_m)+\sum_{y_i≠G_m(x_i)}\widetilde{w_{m,i}} exp(α_m)$$
$$=\sum_{i=1}^N\widetilde{w_{m,i}}(\frac{\sum_{y_i=G_m(x_i)}\widetilde{w_{m,i}}}{\sum_{i=1}^N\widetilde{w_{m,i}}}exp(-α_m)+\frac{\sum_{y_i≠G_m(x_i)}\widetilde{w_{m,i}}}{\sum_{i=1}^N\widetilde{w_{m,i}}}exp(α_m))$$
公式變形之後,炒雞激動!$\frac{\sum_{y_i≠G_m(x_i)}\widetilde{w_{m,i}}}{\sum_{i=1}^N\widetilde{w_{m,i}}}$這個不就是分類誤差率$e_m$嗎???!重寫一下,
$$Loss=\sum_{i=1}^N\widetilde{w_{m,i}}exp(-α_m)+e_m exp(α_m))$$
Ok,這樣我們就得到了化簡之後的損失函式。接下來就是求導了。
對$α_m$求偏導,令$\frac{∂Loss}{∂α_m }=0$得到:
$$α_m=\frac{1}{2}log\frac{1-e_m}{e_m} $$
真漂亮!
另外,AdaBoost的程式碼實戰與詳解請戳程式碼實戰之AdaBoost
面經
今年8月開始找工作,參加大廠面試問到的相關問題有如下幾點:
- 手推AdaBoost
- 與GBDT比較
- AdaBoost幾種基本機器學習演算法哪個抗噪能力最強,哪個對重取樣不敏感?
相關推薦
【機器學習】AdaBoost 原理詳解 數學推導
AdaBoost 自適應 增強 Boosting系列代表演算法,對同一訓練集訓練出不同的(弱)分類器,然後集合這些弱分類器構成一個更優效能的(強)分類器
AdaBoost原理詳解
寫一點自己理解的AdaBoost,然後再貼上面試過程中被問到的相關問題。按照以下目錄展開。 當然,也可以去我的部落格上看 Boosting提升演算法 AdaBoost 原理理解 例項 演算法流程 公式推導 面經 Boosting提升演算法 AdaBoost是典型的Boosting演算法,屬於Boo
Adaboost演算法原理詳解
Adaboost介紹 Adaboost,是英文Adaptive Boosting(自適應增強)的縮寫,它的自適應在於:前一個基本分類器分錯的樣本會得到加強,加權後的全體樣本再次被用來訓練下一個基本分類器,同時,在每一輪中加入一個新的弱分類器,直到達到某個預定的足
磁盤陣列 RAID 技術原理詳解
十分 單獨 很好 不同的 raid1 miss 和數 會同 帶寬 RAID一頁通整理所有RAID技術、原理並配合相應RAID圖解,給所有存儲新人提供一個迅速學習、理解RAID技術的網上資源庫,本文將持續更新,歡迎大家補充及投稿。中國存儲網一如既往為廣大存儲界朋友提供免費、精
解決ajax跨域的方法原理詳解之Cors方法
詳細 不同 htm 渲染 jsonp del 需要 methods href 1、神馬是跨域(Cross Domain) 對於端口和協議的不同,只能通過後臺來解決。 一句話:同一個ip、同一個網絡協議、同一個端口,三者都滿足就是同一個域,否則就是 跨域問題了。而為
Nginx+Php-fpm運行原理詳解
pop 圖片 ron 什麽 地址 pan webserver family tid 一、代理與反向代理 現實生活中的例子 1、正向代理:訪問google.com 如上圖,因為google被墻,我們需要vpnFQ才能訪問google.com。 vpn對於“我們”來說,是可
虛擬化技術基礎原理詳解
虛擬化技術基礎原理詳解DISK : IO調度模式 CFQ deadline anticipatory NOOP/sys/block/<device>/queue/schedulerMemory: MMU TLB vm.swappiness={0..100},使用交換分區的
常用 JavaScript 小技巧及原理詳解
this lin slice pen global 轉化 script lis fun 善於利用JS中的小知識的利用,可以很簡潔的編寫代碼 1. 使用!!模擬Boolean()函數 原理:邏輯非操作一個數據對象時,會先將數據對象轉換為布爾值,然後取反,兩個!!重復取反,就實
Storm概念、原理詳解及其應用(一)BaseStorm
when 結構 tails 並發數 vm 虛擬機 cif 異步 優勢 name 本文借鑒官文,添加了一些解釋和看法,其中有些理解,寫的比較粗糙,有問題的地方希望大家指出。寫這篇文章,是想把一些官文和資料中基礎、重點拿出來,能總結出便於大家理解的話語。與大多數“wordc
主成分分析(PCA)原理詳解(轉載)
增加 信息 什麽 之前 repl 神奇 cto gmail 協方差 一、PCA簡介 1. 相關背景 上完陳恩紅老師的《機器學習與知識發現》和季海波老師的《矩陣代數》兩門課之後,頗有體會。最近在做主成分分析和奇異值分解方面的項目,所以記錄一下心得體會。
lvs和keeplived的工作原理詳解
lvs+keeplived的工作原理一、lvs的工作原理 使用集群的技術和liunx的操作系統實現一個高性能、高可用的服務器。可伸縮性、可靠性、很好的管理性。 特點:可伸縮網絡服務的幾種結構,它們都需要一個前端的負載調度器(或者多個進行主從備份)。我們先分析實現虛擬網絡服務的主要技術,指出IP負載均衡技術
js中幾種實用的跨域方法原理詳解
自身 標簽 cdc 返回 屬性和方法 插入 實用 封裝 判斷 這裏說的js跨域是指通過js在不同的域之間進行數據傳輸或通信,比如用ajax向一個不同的域請求數據,或者通過js獲取頁面中不同域的框架中(iframe)的數據。只要協議、域名、端口有任何一個不同, 都被當作是不同
http原理詳解
tor keep 接受 地址 lru structure 格式 dns 請求方式 1. HTTP簡介 HTTP協議(HyperText Transfer Protocol,超文本傳輸協議)是用於從WWW服務器傳輸超文本到本地瀏覽器的傳送協議。它可以使瀏覽器
HTTP2.0 原理詳解
不依賴 href 漸進 pre new 進制 四個步驟 回來 stream 影響一個網絡請求的因素主要有兩個,帶寬和延遲。今天的網絡基礎建設已經使得帶寬得到極大的提升,大部分時候都是延遲在影響響應速度。連接無法復用連接無法復用會導致每次請求都經歷三次握手和慢啟動。三次握手在
css-浮動與清除浮動的原理詳解(清除浮動的原理你知道嗎)
alt col ges mage all strong splay height http float元素A的特點: 脫離文檔流 靠向left或right float元素會和塊盒子重疊 準確來說,是塊盒子和A重疊,但塊盒子內容會浮動在A周圍 不會和inline元素重
VMware VDS原理詳解--20170922
vmware vds原理詳解--20170922本文純屬個人理解,如有錯誤請留言指正。上圖為vSpere中一個簡單的結構拓撲圖,借用這個拓撲圖來解釋一下為什麽VDS能夠邏輯上跨越ESXi。首先說明一下整個架構1. 在底層用三臺ESXi表示一個底層的網絡,另外用Storage代表存儲,在最左邊ESXi中的最左邊
歸並排序原理詳解!
elf 可能 動態空間 文件合並 you col 相同 治法 lte 無論在空間的利用上還是原理的簡介,使用空間換取時間的代價是必須的! 申請一定量的動態空間,double也是有可能!實際會有許多的問題。 時間復雜度,計算方法如下!因為每次比較都為( k*n/2 )+l*n
DPM(Deformable Part Model)原理詳解(匯總)
特征向量 成就 算法思想 filter people tell 梯度 錨點 精度 寫在前面: DPM(Deformable Part Model),正如其名稱所述,可變形的組件模型,是一種基於組件的檢測算法,其所見即其意。該模型由大神Felzenszwalb在2008年提
交換機的原理詳解
交換機的原理詳解實驗名稱:交換機 MAC 表形成 實驗需求: 1、確保 PC-1 與 PC-3 可以互相Ping通; 2、查看交換機的 MAC 地址表 ; 實驗步驟: 1、互聯交換機與 PC-1/2/3 ; 分別對應交換機的 Fas0/1/2/3口 2、配置PC-1/2/3的I
ping命令知識 Ping命令工作原理詳解
pla bsp 知識 網吧 撥號 lock tcp 問題 mage 在網絡應用中,ping網速與IP地址等都是非常常用的命令,但大家知道ping命令的工作原理嗎?要知道這其中的奧秘,我們有必要來看看Ping命令的工作過程到底是怎麽樣的。下面介紹下ping命令的詳細知識。