
Scrapy-Splash的介紹、安裝以及例項
scrapy-splash的介紹
在前面的部落格中,我們已經見識到了Scrapy的強大之處。但是,Scrapy也有其不足之處,即Scrapy沒有JS engine, 因此它無法爬取JavaScript生成的動態網頁,只能爬取靜態網頁,而在現代的網路世界中,大部分網頁都會採用JavaScript來豐富網頁的功能。所以,這無疑Scrapy的遺憾之處。
那麼,我們還能愉快地使用Scrapy來爬取動態網頁嗎?有沒有什麼補充的辦法呢?答案依然是yes!答案就是,使用scrapy-splash模組!
scrapy-splash模組主要使用了Splash. 所謂的Splash, 就是一個Javascript渲染服務。它是一個實現了HTTP API的輕量級瀏覽器,Splash是用Python實現的,同時使用Twisted和QT。Twisted(QT)用來讓服務具有非同步處理能力,以發揮webkit的併發能力。Splash的特點如下:
- 並行處理多個網頁
- 得到HTML結果以及(或者)渲染成圖片
- 關掉載入圖片或使用 Adblock Plus規則使得渲染速度更快
- 使用JavaScript處理網頁內容
- 使用Lua指令碼
- 能在Splash-Jupyter Notebooks中開發Splash Lua scripts
- 能夠獲得具體的HAR格式的渲染資訊
scrapy-splash的安裝
由於Splash的上述特點,使得Splash和Scrapy兩者的相容性較好,抓取效率較高。
聽了上面的介紹,有沒有對scrapy-splash很心動呢?下面就介紹如何安裝scrapy-splash,步驟如下:
1. 安裝scrapy-splash模組
pip3 install scrapy-splash2. scrapy-splash使用的是Splash HTTP API, 所以需要一個splash instance,一般採用docker執行splash,所以需要安裝docker。不同系統的安裝命令會不同,如筆者的CentOS7系統的安裝方式為:
sudo yum install docker安裝完docker後,可以輸入命令‘docker -v’來驗證docker是否安裝成功。
3. 開啟docker服務,拉取splash映象(pull the image):
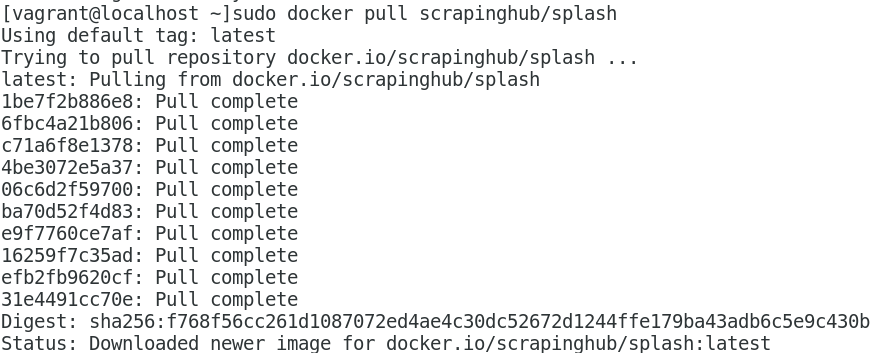
sudo service docker start sudo dock pull scrapinghub/splash
執行結果如下:
4. 開啟容器(start the container):
sudo docker run -p 8050:8050 scrapinghub/splash此時Splash以執行在本地伺服器的埠8050(http).在瀏覽器中輸入'localhost:8050', 頁面如下:

在這個網頁中我們能夠執行Lua scripts,這對我們在scrapy-splash中使用Lua scripts是非常有幫助的。以上就是我們安裝scrapy-splash的全部。
scrapy-splash的例項
在安裝完scrapy-splash之後,不趁機介紹一個例項,實在是說不過去的,我們將在此介紹一個簡單的例項,那就是利用百度查詢手機號碼資訊。比如,我們在百度輸入框中輸入手機號碼‘159********’,然後查詢,得到如下資訊:
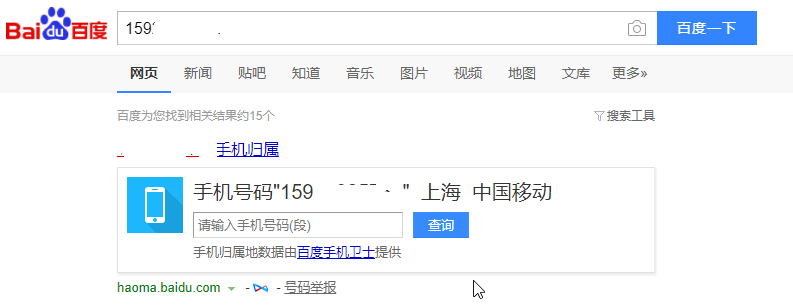
我們將利用scrapy-splash模擬以上操作並獲取手機號碼資訊。
1. 建立scrapy專案phone
2. 配置settings.py檔案,配置的內容如下:
ROBOTSTXT_OBEY = False
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810
}
SPLASH_URL = 'http://localhost:8050'
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'3. 建立爬蟲檔案phoneSpider.py, 程式碼如下:
# -*- coding: utf-8 -*-
from scrapy import Spider, Request
from scrapy_splash import SplashRequest
# splash lua script
script = """
function main(splash, args)
assert(splash:go(args.url))
assert(splash:wait(args.wait))
js = string.format("document.querySelector('#kw').value=%s;document.querySelector('#su').click()", args.phone)
splash:evaljs(js)
assert(splash:wait(args.wait))
return splash:html()
end
"""
class phoneSpider(Spider):
name = 'phone'
allowed_domains = ['www.baidu.com']
url = 'https://www.baidu.com'
# start request
def start_requests(self):
yield SplashRequest(self.url, callback=self.parse, endpoint='execute', args={'lua_source': script, 'phone':'159*******', 'wait': 5})
# parse the html content
def parse(self, response):
info = response.css('div.op_mobilephone_r.c-gap-bottom-small').xpath('span/text()').extract()
print('='*40)
print(''.join(info))
print('='*40)4. 執行爬蟲,scrapy crawl phone, 結果如下:

相關推薦
Scrapy-Splash的介紹、安裝以及例項
scrapy-splash的介紹 在前面的部落格中,我們已經見識到了Scrapy的強大之處。但是,Scrapy也有其不足之處,即Scrapy沒有JS engine, 因此它無法爬取JavaScript生成的動態網頁,只能爬取靜態網頁,而在現代的網路世界中,大部分網頁都會採用JavaScript來豐富網頁的
Scrapy-Splash的介紹、安裝以及實例
ext call sse requests 多個 efs ebooks pypi pri scrapy-splash的介紹 ??在前面的博客中,我們已經見識到了Scrapy的強大之處。但是,Scrapy也有其不足之處,即Scrapy沒有JS engine, 因此它無法爬取J
nosql快取技術之memcached介紹、安裝以及使用總結
1.1 Memcached介紹 1.1.1 Memcached是什麼 Memcached是一個開源的、支援高效能、高併發以及分散式的內純快取服務軟體,從名稱上前三個字元的單詞Mem就是記憶體的意思,而後面的五個單詞Cache就是快取的意思,最後字元d,是da
Tomcat介紹、安裝配置以及簡單的實現Tomcat負載均衡
Tomcat介紹、安裝配置以及簡單的實現Tomcat負載均衡 ------------------------------------------------------------------------
Randoop介紹、安裝及環境變量配置
you 套件 文件路徑 令行 sts dt.jar 開發 通知 一個 大體來說,開發人員開發源程序,測試人員找bug,中間人產品經理。 黑盒測試:(不看代碼) 白盒測試: 1、基於覆蓋:語句、分支(if、for、真假)、方法 結構:順序、分支(T or F,
libevent源碼分析-介紹、安裝、使用
ont write net clas pretty string his har oot Libevent介紹 安裝 樣例 Libevent介紹 在include\event2\event.h中有關於Libevent的介紹,這裏簡單翻譯
Tomcat介紹 、安裝jdk、 安裝Tomcat
temp star path rap tar.gz 查看 ora 1.7 穩定性 Tomcat介紹以及流行的java容器 Tomcat是Apache軟件基金會(Apache Soft
Tomcat介紹、安裝JDK、安裝Tomcat
jdk software java程序 pre runtime soft web nor 二進制包 Tomcat介紹 Tomcat是Apache軟件基金會(Apache Software Foundation)的Jakarta項目中的一個核心項目,由Apache、Sun和
pythoon介紹、安裝環境、基礎知識、練習題
基礎 行程 分享 生產 image 雲計算 bool 字符串 習題 pyrhoon介紹:創始人為吉多·範羅蘇姆(Guido van Rossum)(龜叔) Python崇尚優美、清晰、簡單,是一個優秀並廣泛使用的語言
linux監控平臺介紹、zabbix監控介紹、安裝zabbix
web .so dmi zabbix日誌 展現 com 狀態 中文顯示 代理 linux監控平臺介紹 常見開源監控軟件 cacti、nagios、zabbix、smokeping、open-falcon 等等。 nagios和zabbix流行度很高。 cacti
第一篇:Tomcat介紹、安裝、配置
分享圖片 訪問網站 esp ext .tar.gz resp less a20 關閉防火墻 一、Tomcat介紹 Tomcat是Apache軟件基金會(Apache Software Foundation)的Jakarta項目中的一個核心項目,有Apache 、Sun和其
Mysql數據庫介紹、安裝和配置文件
username 存取 空閑 交互式 遠程登錄 現在 centos7 delet 取數 Mysql數據庫介紹、安裝和配置文件 MySQL數據庫介紹 mysql是開源關系型數據庫,遵循GPL協議。 mysql的特點是性能卓越且服務穩定,開源,無版本限制,成本低
MySQL開發——【介紹、安裝】
dbms tab 數據結構 個數 關系模型 集合 base 存儲 模型 什麽是數據庫? 數據庫(Database)是按照數據結構來組織、存儲和管理數據的倉庫, 每個數據庫都有一個或多個不同的API用於創建,訪問,管理,搜索和復制所保存的數據。 數據庫的分類?
57.Tomcat介紹、安裝jdk、安裝Tomcat
Tomcat介紹 安裝jdk 安裝Tomcat 一、Tomcat介紹 Tomcat是Apache軟件基金會(Apache Software Foundation)的Jakarta項目中的一個核心項目,由Apache、Sun和其他一些公司及個人共同開發而成。 java程序寫的網站用tomcat+j
Linux系統Vi/Vim編輯器的簡單介紹、安裝/卸載、常用命令
菜鳥 3.3 移動 左移 str file 所在 最後一行 簡單 Linux系統Vi/Vim編輯器的簡單介紹、安裝/卸載、常用命令 1、介紹 vi(Visual Interface)編輯器是Linux和Unix上最基本的文本編輯器,工作在字符模式下。由於不需要圖形界面,
六十四、Linux監控平臺介紹、zabbix監控介紹、安裝zabbix、忘記Admin密碼如何做
LInux監控平臺介紹 zabbix監控介紹 安裝zabbix 忘記Admin密碼如何做 六十四、Linux監控平臺介紹、zabbix監控介紹、安裝zabbix、忘記Admin密碼如何做一、Linux監控平臺介紹 cacti、nagios、zabbix、smokeping、open-falco
Tomcat介紹、安裝jdk和tomcat
TP htm etc 解析 code pre kit uil devel Tomcat介紹 Tomcat是Apache軟件基金會(Apache Software Foundation)的Jakarta項目中的一個核心項目,由Apache、Sun和其他一些公司及個人共同開發而
nosql介紹、memrcached介紹 、安裝memcached、查看memcachedq狀態
XML 什麽 mongodb reads ats 分享圖片 默認值 nec threads NoSQL 什麽是NoSQL非關系型數據庫就是NoSQL,關系型數據庫代表MySQL 對於關系型數據庫來說,是需要把數據存儲到庫、表、行、字段裏,查詢的時候根據條件一行一行地去匹配,
Linux監控平臺介、zabbix監控介紹、安裝zabbix、忘記Admin密碼如何做
character mysql lease where 壓縮包 zabbix監控 輸入 bpa smokeping 常見開源監控軟件 ?cacti、nagios、zabbix、smokeping、open-falcon等等?cacti、smokeping偏向於基礎監控,成圖
Ansible介紹、安裝、遠程執行命令、拷貝文件或者目錄、遠程執行腳本
github 軟件 ip地址 密碼 ssh doc ech 圖形 ofo Ansible介紹 不需要安裝客戶端,通過sshd去通信基於模塊工作,模塊可以由任何語言開發不僅支持命令行使用模塊,也支持編寫yaml格式的playbook,易於編寫和閱讀安裝十分簡單,centos上