
Coursera-Getting and Cleaning Data-Week3-dplyr+tidyr+lubridate的組合拳
Coursera-Getting and Cleaning Data-Week3
Wednesday, February 04, 2015
好久不寫筆記了,年底略忙。。
Getting and Cleaning Data第三週其實沒什麼好說的,一個quiz,一個project,加一個swirl。
基本上swirl已經把第三週的內容都概括進去了。就是dplyr, tidyr以及lubridate包的學習和使用。其中dplyr專注於選擇/篩選,tidyr關注於資料重塑型,二lubridate是我目前接觸過的最好用的R中處理時間的包。
這三個包都是Hadley Wickam開發的,秉承了這系列包簡潔,實用,好理解的特點。dplyr包尤其像sql語句,select, group_by什麼的,有sql基礎的人理解起來不會很難。
該系列swirl安裝程式碼如下:
library(swirl)
install_from_swirl("Getting and Cleaning Data")關於dplyr,swirl本身已經寫得很詳盡了。不過開發者有自己的一個總結。我最開始是在一個人的微博裡看到這張圖的。然後追本索源發現,它原載於Rstudio官網Cheatsheets網頁。裡面還有markdown/Shiny包的快捷應用影象,值得初學者列印一整張下來好好學習。

dplyr+tidyr
總結一下dplyr+tidyr的應用,就是:
1)篩選/選擇資料: select, filter。其中select選擇列,filter新增篩選條件(類似於SQL中的where).select裡有如select(iris,contains/ends_with/everthing
2)整合資料,類似於reshape2:gather(從寬變窄),spread(從窄變寬),可以快速改變資料結構。
3)資料排序/命名:arrange(行排序),rename(重新命名列)
4)新增刪除變數,多表查詢:mutate(列,類似於cbind),transmute(幾列並行),join, left_join等。
同時,因為他們系出同門,我們可以用%>%來簡化程式碼,避免重複輸入。
lubridate
關於lubridate包,常用的為:
1)指定格式的資料輸出,如ymd("20110604")和mdy("06-04-2011")
2)常見資料的處理,如second(arrive),wday(arrive),並可新增時區(tz)
3)計算區間,如interval(arrive,leave,tz="Pacific/Auckland"),
需要注意的是,這個包的使用涉及了R時區的概念。如果你是中文系統,發現你的monday, sunday被系統自動替換成週一,週日等中文字元的話,請看時區設定Sys.setlocale。 我是windows系統,所以改成英文的話是Sys.setlocale("LC_TIME","English")。這個在接下來的畫圖課裡有一定的用處。
基本上過了一遍swirl後,quiz不是大問題。
Project
關於project,中英文一起看吧,題目寫得有點簡略了,但是重點是探索的過程。
我們那個超級好人超級NICE的TA David Hood在討論區裡曾發過一張圖給看不懂題目的人解釋一下資料結構。因為TA都在討論區發過了,所以我覺得可以共享一下。
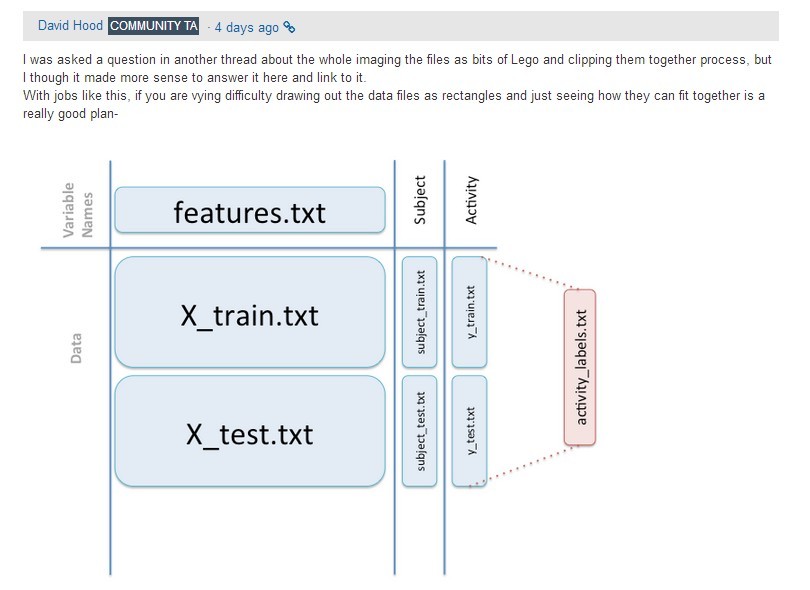
這裡需要注意,老師滿強調tidy data的概念。不管是寬的資料還是短的資料,只要符合tidy data規則,都算tidy data。各位有興趣可以回去啃啃Hadley的那個PDF。
之前跟Q群的人討論這個project時,看到有四種處理該project某一問的方法。包括簡潔的group_by+summarize_each,或者繞一個圈的gather+group_by+summarize+spread組合,還有用reshape2的melt+dcsat組合,以及R programming裡面著重介紹的迴圈+apply/lapply組合。有興趣的可以自行嘗試~~
在資料分析裡,資料處理是一個苦差事。有人說一個數據挖掘專案,可能資料處理會佔用60-70%甚至更多的時間,建模什麼的,一旦資料處理好了,就很快,因為常用且經過時間驗證的可靠模型也就那麼幾種。同時這個資料處理,也是瞭解業務的一個重要途徑。所以這門課還是不可或缺的。我的部落格
相關推薦
Coursera-Getting and Cleaning Data-Week3-dplyr+tidyr+lubridate的組合拳
Coursera-Getting and Cleaning Data-Week3 Wednesday, February 04, 2015 好久不寫筆記了,年底略忙。。 Getting and Cleaning Data第三週其實沒什麼好說的,一個quiz,一個project,加一個swirl。
Coursera-Getting and Cleaning Data-Week2-課程筆記
按照Quiz知識點來的筆記 1.API 視訊裡介紹了用httr包讀取twitter資料,在httr Demo頁有其讀取twitter, facebook, google,github等的demo程式碼。 在使用httr包前,都要到相應網站去註冊API,獲得訪問許可權,httr裡訪問資料的方式基本都是
Coursera-Getting and Cleaning Data-week4-R語言中的正則表示式以及文字處理
補上第四周筆記,以及本次課程總結。 第四周課程主要針對text進行處理。裡面包括 1.變數名的處理 2.正則表示式 3.日期處理(參見swirl lubridate包練習) 首先,變數名的處理,奉行兩個原則,1)統一大小寫tolower/toupper;2)去掉在匯入資料時,因為特殊字元導致的合併變
Coursera-Getting and Cleaning Data-week1-課程筆記
課程概述 Getting and Cleaning Data是Coursera資料科學專項的第三門課,有中文翻譯。但是由於中文區討論沒有英文區熱鬧,以及資料積累,強烈建議各位同時選報中文專案和英文專案,可以互相匹配學習。 Week1的課程概括下來,主要介紹了getting and cleaning d
Cleaning and Preparing Data in Python
Cleaning and Preparing Data in PythonThat boring part of every data scientist’s workData Science sounds like something cool and awesome. It’s pictured as s
Cleaning and Prepping Data with Python for Data Science
Check Your Data … QuicklyThe first thing you want to do when you get a new dataset, is to quickly to verify the contents with the .head() method.import pan
Good Bye 2015 F - New Year and Cleaning
first sca 線性復雜 def int 復雜 main 線段 include F - New Year and Cleaning 這題簡直是喪心病狂折磨王。。 思路:容易想到這樣一個轉換,把整個矩形一起移動,矩形移出去的時候相當於一行或者一列。 為了優化找到下一
Coursera機器學習基石筆記week3
Types of Learning Learning with Different Output Space Y 機器學習按照輸出空間劃分的話,包括二元分類、多元分類、迴歸、結構化學習等不同的型別。其中二元分類和迴歸是最基礎、最核心的兩個型別。 Learning with D
Swing State: Consistent Updates for Stateful and Programmable Data Planes
Swing State: Consistent Updates for Stateful and Programmable Data Planes 年份:2017 來源:ACM 本篇論文解決的問題 Before 原來的狀態遷移是三角形路由的方式: NF1->Controller->NF
[2] Getting Started With Data Reflections
Getting Started With Data Reflections Why Data Reflections? 分析中通常涉及較大資料集和資源密集型的操作,資料分析和資料科學家需要較高效的互動式查詢來完成他們的分析工作,其中分析任務多是迭代關聯性的,每一
coursera——Image and Video Processing
最近一直在刷coursera上的Image and Video Processing(https://www.coursera.org/learn/image-processing/home/welcome),收穫還可以,主要是掌握了影象的一些去噪、修復、邊緣分割思想,最重要的啟發主要還
論文解讀:DeLiGAN: Generative Adversarial Networks for Diverse and Limited Data
前言:DeLiGAN是計算機視覺頂會CVPR2017發表的一篇論文,本文將結合Python原始碼學習DeLiGAN中的核心內容。DeLiGAN最大的貢獻就是將生成對抗網路(GANs)的輸入潛空間編碼為混合模型(高斯混合模型),從而使得生成對抗網路(GANs)在數量有限但具有多樣性的訓練資料上表現出較
Coursera : Image and Video Processing學習筆記
之前軟體杯做OCR識別,圖片預處理比較的難搞的情況就是,那種在光照不均勻的環境(或者閃光燈)下導致影象呈現由光照中心由亮變暗的亮度不均勻影象的處理辦法,使用基於滑動視窗的區域性二值化
Dataset creation and cleaning: Web Scraping using Python
In my last article, I discussed about generating a dataset using the Application Programming Interface (API) and Python libraries. APIs allow us to draw ve
Positive and Negative Data Engineering
Today, Prefect is the codification of the patterns we observe in modern data engineering. We’ve worked very hard to build a system that can automatically e
Flask 101: Adding, Editing and Displaying Data
Last time we learned how to add a search form to our music database application. Of course, we still haven’t added any data to our database, so the search
Presentation Matters, or How I Learned to Stop Worrying and Love Data Communication
Here at NEMAC, I make up the entirety of our design department. I’m art director, branding intern, web design specialist, print guru, and logo designer, al
How AI and Big Data will Shape the Future of Cybersecurity
As we are moving rapidly towards the technology innovation, we are also getting dependent on technology on a daily basis. With the increase in dependency,