
windows 利用R定時抓取貓眼專業版電影票房
1、在mysql建立資料庫,表
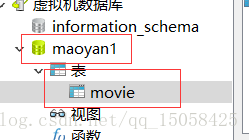
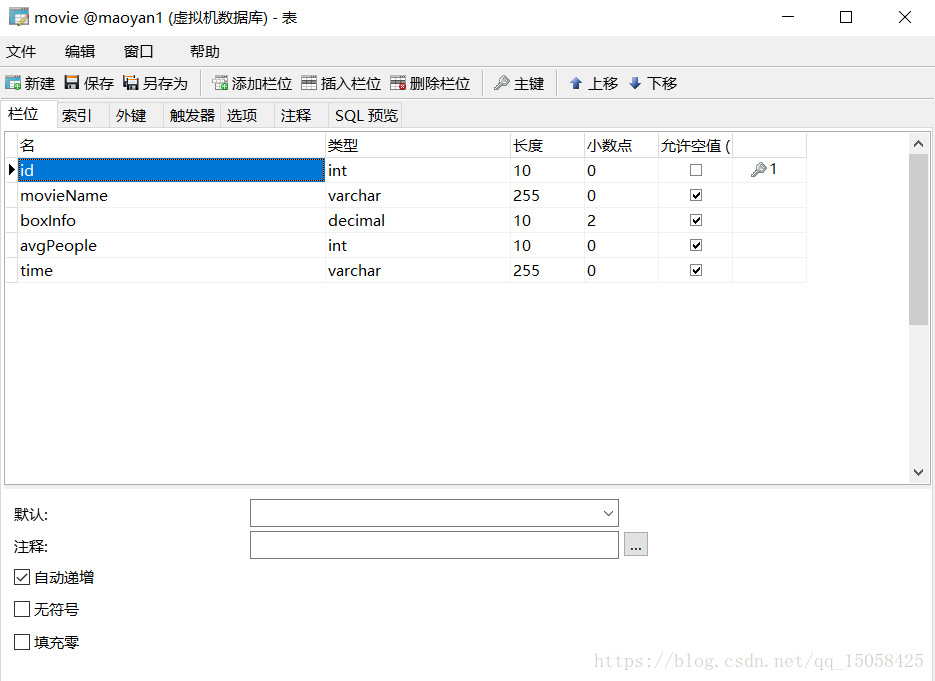
2、網址
貓眼專業版:http://piaofang.maoyan.com/dashboard
電影票房資料鏈接:https://box.maoyan.com/promovie/api/box/second.json
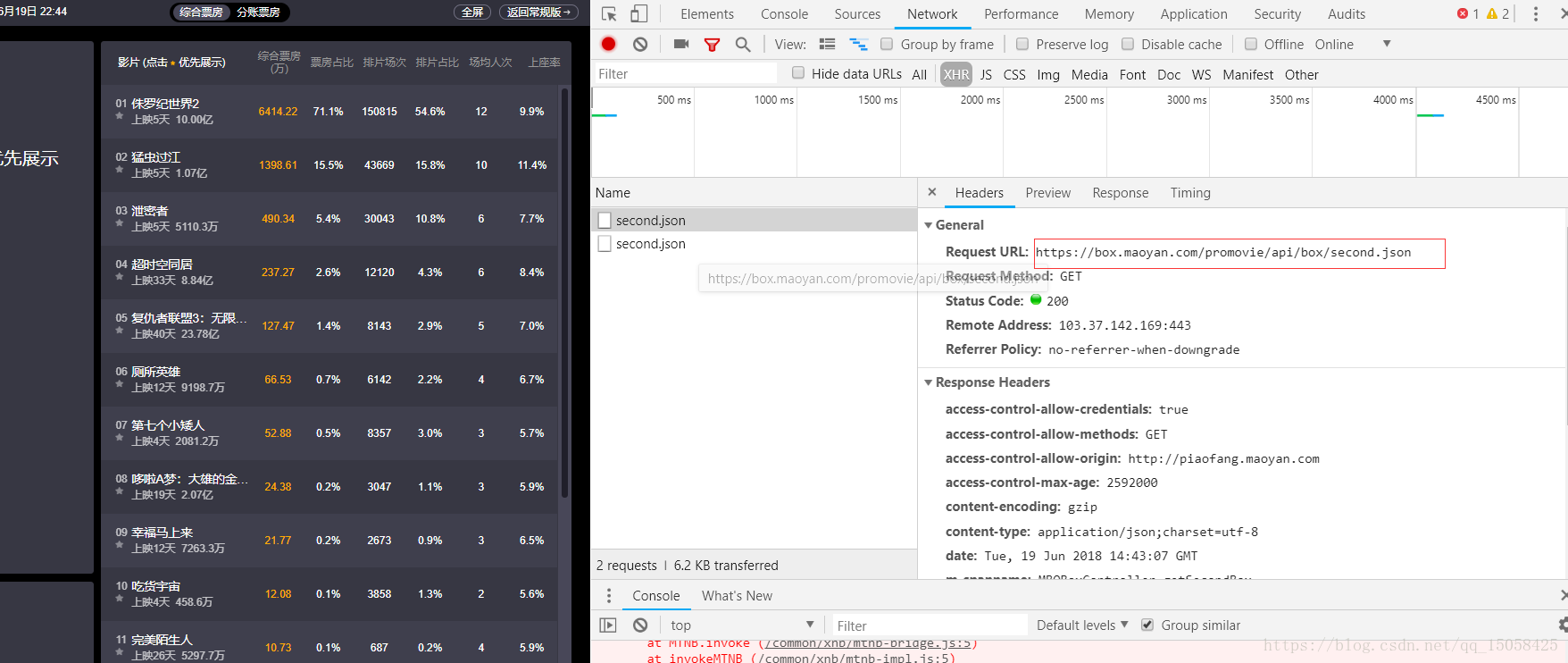
3、指令碼
library(xml2)
library(rvest)
movieData<-read_html('https://box.maoyan.com/promovie/api/box/second.json')
content<-movieData %>% html_nodes('p') %>% html_text()
library(RMySQL)
library(DBI)
library('jsonlite')
result<-fromJSON(content)
movieName<-result$data$list$movieName
boxInfo<-result$data$list$boxInfo
avgPeople<-result$data$list$avgShowView
insertData<-data.frame(movieName,boxInfo,avgPeople)
newData<-transform(insertData,time=result$data$'updateInfo')
conn <- dbConnect(MySQL(), dbname = "maoyan1", username="root", password="root", host="192.168.193.128", port=3306)
dbWriteTable(conn, "movie",newData,append=T,row.names=F)
4、可以將該文字複製,替換上一遍部落格中的test.R指令碼,重新建立定時任務,即可(當時我以為將test.R中的程式碼複製貼上就行了,結果發現之前定時執行test.R指令碼的定時任務不執行了,所以重新建立了定時任務就可以了)
上一篇部落格地址:https://blog.csdn.net/qq_15058425/article/details/80739067
這樣就可以定時爬取資料,將資料儲存到資料庫中,不過windows的時間間隔最小是5分鐘,不知道是不是還可以設定更小,暫時沒有找到設定方法,如果還想設定更小的間隔時間抓取資料,我考慮將R安裝在Linux上,利用crontab
相關推薦
windows 利用R定時抓取貓眼專業版電影票房
1、在mysql建立資料庫,表2、網址貓眼專業版:http://piaofang.maoyan.com/dashboard電影票房資料鏈接:https://box.maoyan.com/promovie/api/box/second.json3、指令碼library(xml2
python爬取貓眼專業版-實時票房
python 爬蟲&#!/usr/bin/env python #coding:utf-8 import requests def jsonresponse(url): response = requests.get(url) return response.json() #定義
python爬蟲實戰--爬取貓眼專業版-實時票房
小白級別的爬蟲入門 最近閒來無事,發現了貓眼專業版-實時票房,可以看到在貓眼上映電影的票房資料,便驗證自己之前學的python爬蟲,爬取資料,做成.svg檔案。 爬蟲開始之前 我們先來看看貓眼專業版-實時票房這個網頁,看看我們要爬取的資料,分析網頁的結構和檢視原始碼。
利用request和re抓取貓眼電影排行
offset requests url oar 復習 .com one text mozilla import requests import re import time def get_one_page(url): headers = { &#
利用 pyspider 框架抓取貓途鷹酒店信息
tasks 啟動 font oca star 一鍵 resp att blank 利用框架 pyspider 能實現快速抓取網頁信息,而且代碼簡潔,抓取速度也不錯。 環境:macOS;Python 版本:Python3。 1.首先,安裝 pyspider 框架,
python requests抓取貓眼電影
def res b- int nic status () tle proc 1. 網址:http://maoyan.com/board/4? 2. 代碼: 1 import json 2 from multiprocessing import Po
利用Python批量抓取京東評論數據
() 開始 book for return SQ 數據返回 python js對象 京東圖書評論有非常豐富的信息,這裏面就包含了購買日期、書名、作者、好評、中評、差評等等。以購買日期為例,使用Python + Mysql的搭配進行實現,程序不大,才100行。相關的解釋我都在
用pyquery 初步改寫崔慶才的 抓取貓眼電影排行(正在更新)特意置頂,提醒自己更新
items parse rac info sco ber windows time ont 目前正在學Python爬蟲,正在讀崔慶才的《Python3網絡爬蟲開發實戰》,之前學習正則表達式,但是由於太難,最後放棄了(學渣的眼淚。。。。),在這本書上的抓取貓眼電影排行上,
《一出好戲》講述人性,使用Python抓取貓眼近10萬條評論並分析,一起揭秘“這出好戲”到底如何?
generate pro hand stk 同時 readlines 看電影 就是 msh 黃渤首次導演的電影《一出好戲》自8月10日在全國上映,至今已有10天,其主演陣容強大,相信許多觀眾也都是沖著明星們去的。目前《一出好戲》在貓眼上已經獲得近60萬個評價,評分為8.2
00_抓取貓眼電影排行TOP100
前言: 學習python3爬蟲大概有一週的時間,熟悉了爬蟲的一些基本原理和基本庫的使用,本次就準備利用requests庫和正則表示式來抓取貓眼電影排行TOP100的相關內容。 1、本次目標: 需要爬去出貓眼電影排行TOP100的電影相關資訊,包括:名稱、圖片、演員、時間、評分,排名。提取站點的URL為h
【Python3 爬蟲學習筆記】基本庫的使用 13 —— 抓取貓眼電影排行
四、抓取貓眼電影排行 4.1 抓取分析 需要抓取的目標站點為http://maoyan.com/board/4 ,開啟之後便可以檢視到榜單資訊,如下圖所示: 排名第一的電影是霸王別姬,頁面中顯示的有效資訊有影片名稱、主演、上映時間、上映地區、評分、圖片等資訊。 將網頁滾動到最下方,
反爬蟲-python3.6抓取貓眼電影資訊
思路分解: 1.頁面資訊 url:http://maoyan.com/cinema/24311?poi=164257570 檢視資訊發現價格存在亂碼現象: 重新整理頁面找到亂碼的URL,下載woff格式檔案:方法:複製URL:右鍵單擊轉
Python爬蟲之requests+正則表示式抓取貓眼電影top100以及瓜子二手網二手車資訊(四)
{'index': '1', 'image': 'http://p1.meituan.net/movie/[email protected]_220h_1e_1c', 'title': '霸王別姬', 'actor': '張國榮,張豐毅,鞏俐', 'time': '1993-01-01', 'sc
Python-爬蟲-基本庫(requests)使用-抓取貓眼電影Too100榜
spa spi fire tools not agen ext get pytho 1 #抓取貓眼電影,https://maoyan.com/board/4 榜單電影列表 2 import requests 3 import re 4 from requests
python3實現抓取貓眼top100電影資訊
前言:最近正在學習python爬蟲,瞭解一些基礎知識後,還是要實踐動手熟悉。下面文章例子有空再加備註。。import requests import re import json import time from requests.exceptions import Requ
Python爬蟲之三:抓取貓眼電影TOP100
今天我要利用request庫和正則表示式抓取貓眼電影Top100榜單。 執行平臺: Windows Python版本: Python3.6 IDE: Sublime Text 其他工具: Chrome瀏覽器 1. 抓取單頁內容 瀏
【3月24日】Requests+正則表示式抓取貓眼電影Top100
本次實驗爬蟲任務工具較為簡單,主要是熟悉正則表示式的匹配: pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>
利用Fiddler 可以抓取HTTPS
以前很看好wireshark,可是對HTTPS的支援不夠好 裡面有個FLASH是如何配置HTTPS的 開發網際網路應用的過程中,常常會設立或利用網路介面。為了除錯對網路介面的使用,往往需要檢視流入和流出網路介面的網路流量或資料包。“抓包工具”就是一類用於記錄通過網路介面
PowerShell定時抓取螢幕影象
昨天的博文寫了定時記錄作業系統行為,其實說白了就是抓取了擊鍵的記錄和對應視窗的標題欄,而很多應用程式標題欄又包含當時記錄的檔案路徑和檔名,用這種方式可以大致記錄操作了哪些程式,打開了哪些檔案,以及敲擊了哪些按鍵。事實上這樣記錄作業系統的行為顯得相對單薄一點,因為記錄的內容不太形象,對於新手來說太過於
Python爬蟲之抓取貓眼電影TOP100
執行平臺:windowsPython版本:Python 3.7.0IDE:Sublime Text瀏覽器:Chrome瀏覽器思路: 1.檢視網頁原始碼 2.抓取單頁內容 3.正則表示式提取資訊