
Tensorflow中權值和feature map的視覺化
前言
Tensorflow中可以使用tensorboard這個強大的工具對計算圖、loss、網路引數等進行視覺化。本文並不涉及對tensorboard使用的介紹,而是旨在說明如何通過程式碼對網路權值和feature map做更靈活的處理、顯示和儲存。本文的相關程式碼主要參考了github上的一個小專案,但是對其進行了改進。原專案地址為(https://github.com/grishasergei/conviz)。
本文將從以下兩個方面進行介紹:
- 卷積知識補充
- 網路權值和feature map的視覺化
1. 卷積知識補充
為了後面方便講解程式碼,這裡先對卷積的部分知識進行一下簡介。關於卷積核如何在影象的一個通道上進行滑動計算,網上有諸多資料,相信對卷積神經網路有一定了解的讀者都應該比較清楚,本文就不再贅述。這裡主要介紹一組卷積核如何在一幅影象上計算得到一組feature map。
以從原始影象經過第一個卷積層得到第一組feature map為例(從得到的feature map到再之後的feature map也是同理),假設第一組feature map共有64個,那麼可以把這組feature map也看作一幅影象,只不過它的通道數是64, 而一般意義上的影象是RGB3個通道。為了得到這第一組feature map,我們需要64個卷積核,每個卷積核是一個k x k x 3的矩陣,其中k是卷積核的大小(假設是正方形卷積核),3就對應著輸入影象的通道數。下面我以一個簡單粗糙的圖示來展示一下影象經過一個卷積核的卷積得到一個feature map的過程。

如圖所示,其實可以看做卷積核的每一通道(不太準確,將就一下)和影象的每一通道對應進行卷積操作,然後再逐位置相加,便得到了一個feature map。
那麼用一組(64個)卷積核去卷積一幅影象,得到64個feature map就如下圖所示,也就是每個卷積核得到一個feature map,64個卷積核就得到64個feature map。
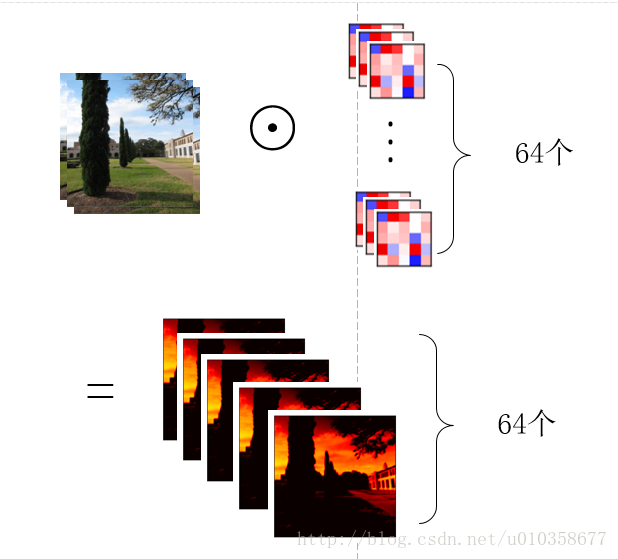
另外,也可以稍微換一個角度看待這個問題,那就是先讓圖片的某一通道分別與64個卷積核的對應通道做卷積,得到64個feature map的中間結果,之後3個通道對應的中間結果再相加,得到最終的feature map,如下圖所示:
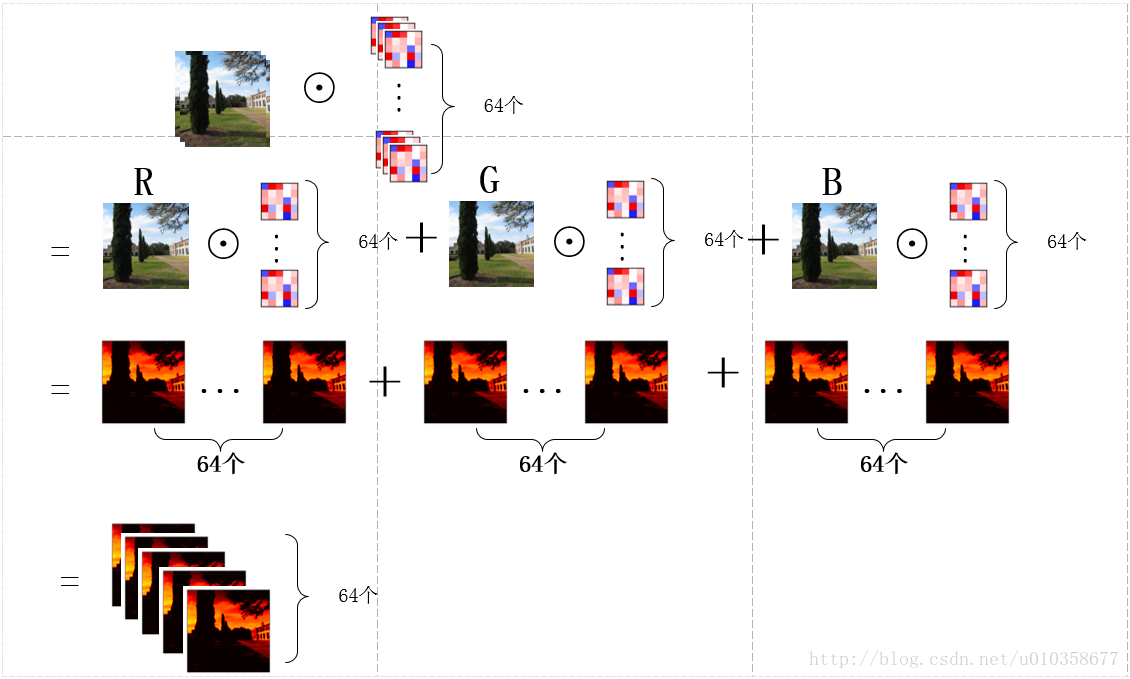
可以看到這其實就是第一幅圖擴充套件到多卷積核的情形,圖畫得較為粗糙,有些中間結果和最終結果直接用了一樣的子圖,理解時請稍微注意一下。下面程式碼中對卷積核進行展示的時候使用的就是這種方式,即對應著輸入影象逐通道的去顯示卷積核的對應通道,而不是每次顯示一個卷積核的所有通道,可能解釋的有點繞,需要注意一下。通過下面這個小圖也許更好理解。
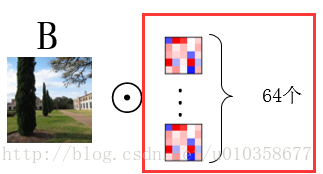
圖中用紅框圈出的部分即是我們一次展示出的權重引數。
2. 網路權值和feature map的視覺化
(1) 網路權重引數視覺化
首先介紹一下Tensorflow中卷積核的形狀,如下程式碼所示:
weights = tf.Variable(tf.random_normal([filter_size, filter_size, channels, filter_num]))前兩維是卷積核的高和寬,第3維是上一層feature map的通道數,在第一節(卷積知識補充)中,我提到了上一層的feature map有多少個(也就是通道數是多少),那麼對應著一個卷積核也要有這麼多通道。第4維是當前卷積層的卷積核數量,也是當前層輸出的feature map的通道數。
以下是我更改之後的網路權重引數(卷積核)的視覺化程式碼:
from __future__ import print_function
#import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import os
import visualize_utils
def plot_conv_weights(weights, plot_dir, name, channels_all=True, filters_all=True, channels=[0], filters=[0]):
"""
Plots convolutional filters
:param weights: numpy array of rank 4
:param name: string, name of convolutional layer
:param channels_all: boolean, optional
:return: nothing, plots are saved on the disk
"""
w_min = np.min(weights)
w_max = np.max(weights)
# make a list of channels if all are plotted
if channels_all:
channels = range(weights.shape[2])
# get number of convolutional filters
if filters_all:
num_filters = weights.shape[3]
filters = range(weights.shape[3])
else:
num_filters = len(filters)
# get number of grid rows and columns
grid_r, grid_c = visualize_utils.get_grid_dim(num_filters)
# create figure and axes
fig, axes = plt.subplots(min([grid_r, grid_c]),
max([grid_r, grid_c]))
# iterate channels
for channel_ID in channels:
# iterate filters inside every channel
if num_filters == 1:
img = weights[:, :, channel_ID, filters[0]]
axes.imshow(img, vmin=w_min, vmax=w_max, interpolation='nearest', cmap='seismic')
# remove any labels from the axes
axes.set_xticks([])
axes.set_yticks([])
else:
for l, ax in enumerate(axes.flat):
# get a single filter
img = weights[:, :, channel_ID, filters[l]]
# put it on the grid
ax.imshow(img, vmin=w_min, vmax=w_max, interpolation='nearest', cmap='seismic')
# remove any labels from the axes
ax.set_xticks([])
ax.set_yticks([])
# save figure
plt.savefig(os.path.join(plot_dir, '{}-{}.png'.format(name, channel_ID)), bbox_inches='tight')原專案的程式碼是對某一層的權重引數或feature map在一個網格中進行全部展示,如果引數或feature map太多,那麼展示出來的結果中每個圖都很小,很難看出有用的東西來,如下圖所示:

所以我對程式碼做了些修改,使得其能顯示任意指定的filter或feature map。
程式碼中,
w_min = np.min(weights)
w_max = np.max(weights)這兩句是為了後續顯示影象用的,具體可檢視matplotlib.pyplot的imshow()函式進行了解。
接下來是判斷是否顯示全部的channel(通道數)或全部filter。如果是,那就和原始碼一致了。若不是,則畫出函式引數channels和filters指定的filter來。
再往下的兩句程式碼是畫圖用的,我們可能會在一個圖中顯示多個子圖,以下這句是為了計算出大圖分為幾行幾列比較合適(一個大圖會盡量分解為方形的陣列,比如如果有64個子圖,那麼就分成8 x 8的陣列),程式碼細節可在原專案中的utils中找到。
grid_r, grid_c = visualize_utils.get_grid_dim(num_filters)實際畫圖時,如果想要一個圖一個圖的去畫,需要單獨處理一下。如果還是想在一個大圖中顯示多個子圖,就按原始碼的方式去做,只不過這裡可以顯示我們自己指定的那些filter,而不是不加篩選地全部輸出。主要拿到資料的是以下這句程式碼:
img = weights[:, :, channel_ID, filters[l]]剩下的都是是畫圖相關的函數了,本文就不再對畫圖做更多介紹了。
使用這段程式碼視覺化並儲存filter時,先載入模型,然後拿到我們想要視覺化的那部分引數,之後直接呼叫函式就可以了,如下所示:
with tf.Session(graph=tf.get_default_graph()) as sess:
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
sess.run(init_op)
saver.restore(sess, model_path)
with tf.variable_scope('inference', reuse=True):
conv_weights = tf.get_variable('conv3_1_w').eval()
visualize.plot_conv_weights(conv_weights, dir_prefix, 'conv3_1')這裡並沒有對filter進行額外的指定,在feature map的視覺化中,我會給出相關例子。
(2) feature map視覺化
其實feature map的視覺化與filter非常相似,只有細微的不同。還是先把完整程式碼貼上。
def plot_conv_output(conv_img, plot_dir, name, filters_all=True, filters=[0]):
w_min = np.min(conv_img)
w_max = np.max(conv_img)
# get number of convolutional filters
if filters_all:
num_filters = conv_img.shape[3]
filters = range(conv_img.shape[3])
else:
num_filters = len(filters)
# get number of grid rows and columns
grid_r, grid_c = visualize_utils.get_grid_dim(num_filters)
# create figure and axes
fig, axes = plt.subplots(min([grid_r, grid_c]),
max([grid_r, grid_c]))
# iterate filters
if num_filters == 1:
img = conv_img[0, :, :, filters[0]]
axes.imshow(img, vmin=w_min, vmax=w_max, interpolation='bicubic', cmap=cm.hot)
# remove any labels from the axes
axes.set_xticks([])
axes.set_yticks([])
else:
for l, ax in enumerate(axes.flat):
# get a single image
img = conv_img[0, :, :, filters[l]]
# put it on the grid
ax.imshow(img, vmin=w_min, vmax=w_max, interpolation='bicubic', cmap=cm.hot)
# remove any labels from the axes
ax.set_xticks([])
ax.set_yticks([])
# save figure
plt.savefig(os.path.join(plot_dir, '{}.png'.format(name)), bbox_inches='tight')程式碼中和filter視覺化相同的部分就不再贅述了,這裡只講feature map視覺化獨特的方面,其實就在於以下這句程式碼,也就是要視覺化的資料的獲得:
img = conv_img[0, :, :, filters[0]]神經網路一般都是一個batch一個batch的輸入資料,其輸入的形狀為
image = tf.placeholder(tf.float32, shape = [None, IMAGE_SIZE, IMAGE_SIZE, 3], name = "input_image")第一維是一個batch中圖片的數量,為了靈活可以設定為None,Tensorflow會根據實際輸入的資料進行計算。二三維是圖片的高和寬,第4維是圖片通道數,一般為3。
如果我們想要輸入一幅圖片,然後看看它的啟用值(feature map),那麼也要按照以上維度以一個batch的形式進行輸入,也就是[1, IMAGE_SIZE, IMAGE_SIZE, 3]。所以拿feature map資料時,第一維度肯定是取0(就對應著batch中的當前圖片),二三維取全部,第4維度再取我們想要檢視的feature map的某一通道。
如果想要視覺化feature map,那麼構建網路時還要動點手腳,定義計算圖時,每得到一組啟用值都要將其加到Tensorflow的collection中,如下:
tf.add_to_collection('activations', current)而實際進行feature map視覺化時,就要先輸入一幅圖片,然後執行網路拿到相應資料,最後把資料傳參給視覺化函式。以下這個例子展示的是如何將每個指定卷積層的feature map的每個通道進行單獨的視覺化與儲存,使用的是VGG16網路:
visualize_layers = ['conv1_1', 'conv1_2', 'conv2_1', 'conv2_2', 'conv3_1', 'conv3_2', 'conv3_3', 'conv4_1', 'conv4_2', 'conv4_3', 'conv5_1', 'conv5_2', 'conv5_3']
with tf.Session(graph=tf.get_default_graph()) as sess:
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
sess.run(init_op)
saver.restore(sess, model_path)
image_path = root_path + 'images/train_images/sunny_0058.jpg'
img = misc.imread(image_path)
img = img - meanvalue
img = np.float32(img)
img = np.expand_dims(img, axis=0)
conv_out = sess.run(tf.get_collection('activations'), feed_dict={x: img, keep_prob: 1.0})
for i, layer in enumerate(visualize_layers):
visualize_utils.create_dir(dir_prefix + layer)
for j in range(conv_out[i].shape[3]):
visualize.plot_conv_output(conv_out[i], dir_prefix + layer, str(j), filters_all=False, filters=[j])
sess.close()其中,conv_out包含了所有加入到collection中的feature map,這些feature map在conv_out中是按卷積層劃分的。
最終得到的結果如下圖所示:

第一個資料夾下的全部結果:

相關推薦
Tensorflow中權值和feature map的視覺化
前言 Tensorflow中可以使用tensorboard這個強大的工具對計算圖、loss、網路引數等進行視覺化。本文並不涉及對tensorboard使用的介紹,而是旨在說明如何通過程式碼對網路權值和feature map做更靈活的處理、顯示和儲存。本文的相關
CNN中feature map視覺化
卷積特徵的視覺化,有助於我們更好地理解深度網路。卷積網路在學習過程中保持了影象的空間結構,也就是說最後一層的啟用值(feature map)總和原始影象具有空間上的對應關係,具體對應的位置以及大小,可以用感受野來度量。利用這點性質可以做很多事情: 1 前向計算。我們直接視覺化網路每層的 feature ma
根據後序中序輸出樹並且求解路徑權值和最小的葉子結點
題目描述: 給一顆點帶權(權值均為正整數並且小於10000)的二叉樹的中序和後序遍歷,找一個葉子是的它到根的路徑上的權和最小。如果有多解,輸出葉子權最小的那個。輸入樣例兩行, 第一行為中序遍歷,第二行為後序遍歷,輸出葉子結點。樣例輸入:3 2 1 4 5 7 6 3 1 2
TensorFlow與caffe中卷積層feature map大小計算
剛剛接觸Tensorflow,由於是做影象處理,因此接觸比較多的還是卷及神經網路,其中會涉及到在經過卷積層或者pooling層之後,影象Feature map的大小計算,之前一直以為是與caffe相同的,後來查閱了資料發現並不相同,將計算公式貼在這裡,以便查閱: caffe中: TF中:
下拉框只顯示最初下拉框中的值和json返回array的交集
sel .text json down emp tno append length drop 首先我們可以遍歷dropdown var array = new Array(); $("#select option").each(function(j){ array[j]=
[翻譯] Tensorflow中name scope和variable scope的區別是什麽
iter res .cn push init const images ges variables 翻譯自:https://stackoverflow.com/questions/35919020/whats-the-difference-of-name-scope-an
神經網絡中權值初始化的方法
網絡 mac tro 推導 6.4 linear diff ati soft from:http://blog.csdn.net/u013989576/article/details/76215989 權值初始化的方法主要有:常量初始化(constant)、高斯分布初始化(
JavaScript中原始值和引用值傳遞
scrip int 性能 直接 一模一樣 post 完全 引用類型 是把 a 聲明變量時不同的內存分配: 1)原始值:存儲在棧(stack)中的簡單數據段,也就是說,它們的值直接存儲在變量訪問的位置。 這是因為這些原始類型占據的空間是固定的,所以可將他們存儲在較小的內存區
如何理解IEEE 754標準對Java中float值和double值的規定
rac tro zh-cn 分享圖片 編號 如何 ins font 指數 在Java語言中,我們可以使用float和double這兩種基本數據類型來表示特定的數據。 這兩種數據類型,本質上是浮點數(floating-point number),浮點是一種對於實數的近似值數值
tensorflow中的佇列和執行緒
一、佇列 tensorflow中主要有FIFOQueue和RandomShuffleQueue兩種佇列,下面就詳細介紹這兩種佇列的使用方法和應用場景。 1、FIFOQueue FIFOQueue是先進先出佇列,主要是針對一些序列樣本。如:在使用迴圈神經網路的時候,需要處理語音、文字、
tensorflow中tf.random_normal和tf.truncated_normal的區別
tensorflow中tf.random_normal和tf.truncated_normal的區別 原創 2017年06月24日 15:31:01 9322 1、tf.truncated_normal使用方法 tf
tensorflow中的shapre和reshape的問題
TensorFlow用張量這種資料結構來表示所有的資料.你可以把一個張量想象成一個n維的陣列或列表.一個張量有一個靜態型別和動態型別的維數.
程序通訊中鍵值和識別符號的關係
在建立一個訊息佇列(其他ipc相同)時,需要先通過檔案路徑名和專案ID獲取一個鍵值,然後通過此鍵值由核心生成識別符號,在以後可通過此識別符號來使用此訊息佇列。 為什麼要有鍵值和識別符號兩個值呢? 描述符是對於使用者操作而言的,讓使
tensorflow中的Session()和run()
創建 需要 ons 參與 鍵值對 連接 edt 分布 const Session()方法 tensorflow的內核使用更加高效的C++作為後臺,以支撐它的密集計算。tensorflow把前臺(即python程序)與後臺程序之間的連接稱為"會話(Session)" Sess
tensorflow中的tensor和session
Tensot(張量) 張量:tensorflow內部的計算都基於張量,使用tf.tensor類的示例表示張量 # 張量 #引入tensorflow模組 import tensorflow as tf
TensorFlow中的name_scope和variable_scope
1、tf.Variable() 和 tf.get_variable() (1)tf.Variable()會自動檢測命名衝突並自行處理。 import tensorflow as tf sess = tf.Session() var1 = tf.Variable(
矩陣從左上角到右下角的最優路徑使得經過路徑上的權值和最大(最小)
描述: 有一張藏寶圖,而藏寶圖描述的所在區域(只有一個左上角入口和一個右下角出口)被分為m*n的小區域,並且每一個小區域內都藏有一定數量N(0<=N<=9)的寶貝,但要求只能從當前位置向右邊或者下邊尋找寶貝。如果你非常幸運,得到了這張藏寶圖
MySQL中毫秒值和日期的指定格式的相互轉換及其時間函式
DAYOFWEEK(date) 返回日期date的星期索引(1=星期天,2=星期一, ……7=星期六)。這些索引值對應於ODBC標準。 mysql> select DAYOFWEEK('1998-02-03'); -> 3 WEEKDAY(date) 返回date的星期索引(0
理解卷積神經網路CNN中的特徵圖 feature map
一直以來,感覺 feature map 挺晦澀難懂的,今天把初步的一些理解記錄下來。參考了斯坦福大學的機器學習公開課和七月演算法中的機器學習課。 CNN一個牛逼的地方就在於通過感受野和權值共享減少了神經網路需要訓練的引數的個數。總之,卷積網路的
利用caffe中自帶的工具來視覺化loss 和accuracy
以前只是一股腦的訓練,卻很少注意到這些,今天仔細研究了下,發現caffe自帶技能包.方法如下:1訓練,和以前略有不同的是,./XX.sh|& tee xx.log,保證在caffe-master目錄下生成日誌檔案,或者去根目錄下的temp中尋找也可以.2在caff