
【R語言 爬蟲】用R爬蟲,爬取杭州安居客九堡租房資訊
在當今網際網路時代,資料要會挖,得先學會爬!爬的過程是痛苦的,因為在計算機程式開發領域,網路爬蟲的開發是一個很專業的方向,技術門檻比較高,它所要求的綜合知識很多,相信很多同學都望而卻步了。別急,說話說到後面往往都有但是滴。
但是該領域的幾個非常方便的工具已經被整合到R的一些第三方包中了,所以我們完全可以基於R用一種很容易實現的方式來實現網際網路資料的抓取,讓我們可以直接去挖掘網際網路這座金礦。
有了XML包,RCurl包,尤其是最近新出的rvest包(聽說簡直就是神器,是不是吹的呢),媽媽再也不用擔心我的資料了。
今天下午學了一下RCurl包,很抱歉沒有太多中文文件,看英語學來的,英語真的很重要,誰讓程式設計軟體都是由老外開發的呢,爬取了杭州安居客九堡租房資訊,瞎操練的,實踐出真知,慢慢懂了。。。
坑爹的地方真多,不同情況不同處理方法,還有有的網站URL本身就是加密的,如淘寶的https,還有些網頁需要登入之後才能檢視,有的網頁甚至你點它的下一頁,url居然還一樣,原始碼不變的,真是百思不得姐了。為什麼沒有大神寫一本書,我給它起叫做,《那些年,爬蟲我們遇到過的坑》。
data:2015-11-7
author:laidefa
library(XML)
library(RCurl)
loginURL<-"http://hz.zu.anjuke.com/fangyuan/jiubao/"
cookieFile<-"E://cookies.txt"
loginCurl<-getCurlHandle(followlocation=TRUE,verbose=TRUE,ssl.verifyhost=FALSE,
ssl.verifypeer=FALSE,cookiejar=cookieFile,cookiefile=cookieFile)
#獲取第一頁的url 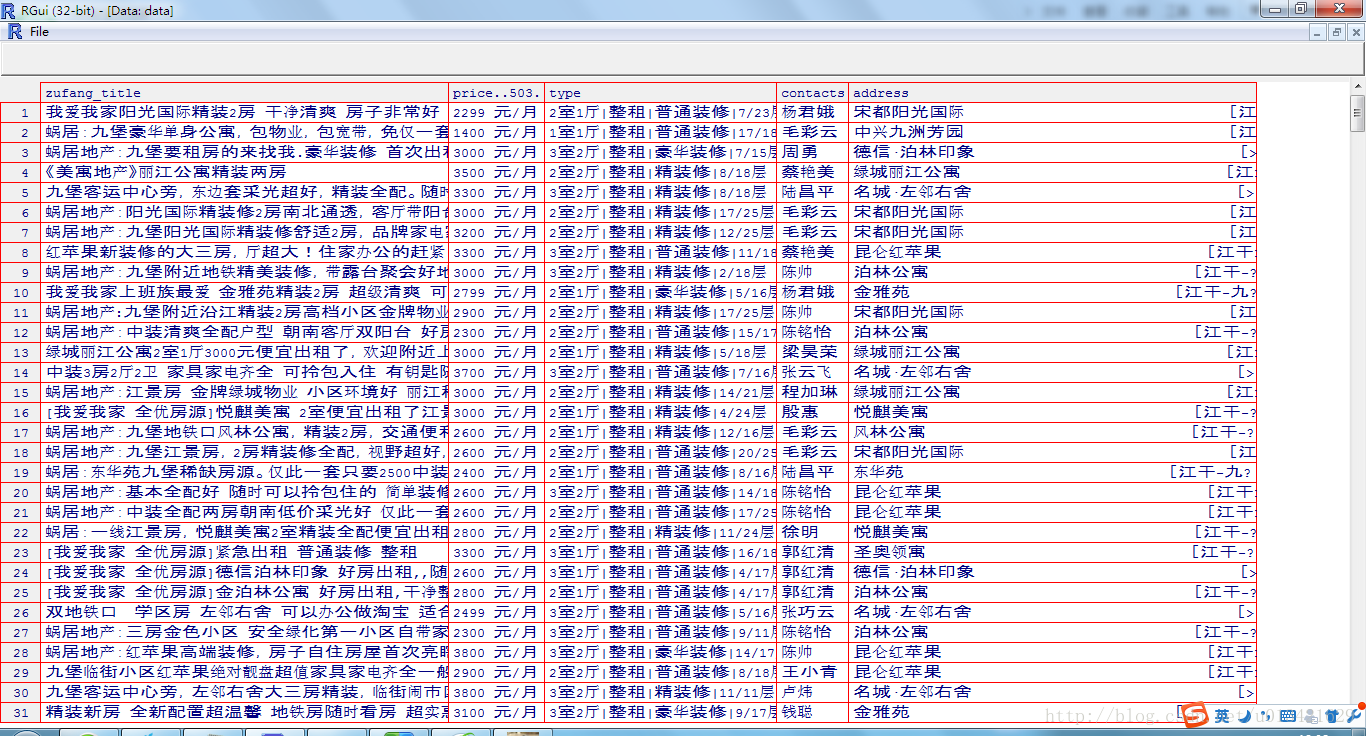
相關推薦
【R語言 爬蟲】用R爬蟲,爬取杭州安居客九堡租房資訊
在當今網際網路時代,資料要會挖,得先學會爬!爬的過程是痛苦的,因為在計算機程式開發領域,網路爬蟲的開發是一個很專業的方向,技術門檻比較高,它所要求的綜合知識很多,相信很多同學都望而卻步了。別急,說話說到
【爬蟲】002 python3 +beautifulsoup4 +requests 爬取靜態頁面
bgcolor img err 預覽 政府 bold 技術 貴的 頁面元素 實驗環境: win7 python3.5 bs4 0.0.1 requests 2.19 實驗日期:2018-08-07 爬取網站:http://www.xhsd.cn/ 現在的網站大多有復雜
【Python3爬蟲】使用Fidder實現APP爬取
telerik tail 實現 鏈接 端口號 dpi () vco 軟件 之前爬取都是網頁上的數據,今天要來說一下怎麽借助Fidder來爬取手機APP上的數據。 一、環境配置 1、Fidder的安裝和配置 沒有安裝Fidder軟件的可以進入這個網址下載,然後就是傻瓜式的
【Python爬蟲】Scrapy框架運用1—爬取豆瓣電影top250的電影資訊(1)
一、Step step1: 建立工程專案 1.1建立Scrapy工程專案 E:\>scrapy startproject 工程專案 1.2使用Dos指令檢視工程資料夾結構 E:\>tree /f step2: 建立spid
【C語言練習題】編寫一個程式,它從標準輸入讀取C原始碼,並驗證所有花括號都正確成對出現
《C和指標》課後練習題 問:編寫一個程式,它從標準輸入讀取C原始碼,並驗證所有花括號都正確成對出現。 程式碼 思路:在while迴圈條件中讀取我輸入的字元,只有當輸入緩衝區沒有資料或者我這裡產生回車符'\n'時,才會判斷條件不成立。c
【C語言練習題】編寫一個函式,它從一個字串中提取一個子字串
《C與指標》 習題 4.14 編寫一個函式,它從一個字串中提取一個子字串。函式原型如下: int substr(char dst[], char src[],int start, int l
爬蟲系列(2)-----python爬取CSDN博客首頁所有文章
成功 -name 保存 eas attr eve lan url att 對於Python初學者來說,爬蟲技能是應該是最好入門,也是最能夠有讓自己有成就感的,今天在整理代碼時,整理了一下之前自己學習爬蟲的一些代碼,今天上第2個簡單的例子,python爬取CSDN博客首頁所有
爬蟲,爬取鏈家網北京二手房資訊
# 鏈家網二手房資訊爬取 import re import time import requests import pandas as pd from bs4 import BeautifulSoup url = 'http://bj.lianjia.com/ershouf
python搭建簡單爬蟲框架,爬取獵聘網的招聘職位資訊
該專案將主要有五個部分負責完成爬取任務,分別是:URL管理器,HTML下載器,HTML解析器,資料儲存器,爬蟲排程器。 具體程式碼如下: URL管理器: import hashlib import pickle import time class UrlManag
初識Scrapy框架+爬蟲實戰(7)-爬取鏈家網100頁租房資訊
Scrapy簡介 Scrapy,Python開發的一個快速、高層次的螢幕抓取和web抓取框架,用於抓取web站點並從頁面中提取結構化的資料。Scrapy用途廣泛,可以用於資料探勘、監測和自動化測試。Scrapy吸引人的地方在於它是一個框架,任何人都可以根
爬蟲(進階),爬取網頁資訊並寫入json檔案
import requests # python HTTP客戶端庫,編寫爬蟲和測試伺服器響應資料會用到的類庫 import re import json from bs4 import BeautifulSoup import copy print('正在爬取網頁連結……'
【Python3爬蟲】用Python實現發送天氣預報郵件
int 字符串 開發者工具 height window 1.0 需要 targe 沒有 此次的目標是爬取指定城市的天氣預報信息,然後再用Python發送郵件到指定的郵箱。 一、爬取天氣預報 1、首先是爬取天氣預報的信息,用的網站是中國天氣網,網址是http://www.
【Python3爬蟲】用Python實現傳送天氣預報郵件
此次的目標是爬取指定城市的天氣預報資訊,然後再用Python傳送郵件到指定的郵箱。 一、爬取天氣預報 1、首先是爬取天氣預報的資訊,用的網站是中國天氣網,網址是http://www.weather.com.cn/static/html/weather.shtml,任意選擇一個城市(比如武漢
【機器學習演算法】基於R語言的多元線性迴歸分析
多元線性迴歸的適用條件: (1)自變數對應變數的變化具有顯著影響 (2)自變數與應變數間的線性相關必須是真實的,而非形式上的 (3)自變數之間需有一定的互斥性 (4)應具有完整的統計資料 訓練資料:csv格式,含有19維特徵 資料下載地址:http://pan.baidu
【資料分析 R語言實戰】學習筆記 第六章 引數估計與R實現(上)
6.1點估計及R實現 6.1.1矩估計 R中的解方程函式: 函式及所在包:功能 uniroot()@stats:求解一元(非線性)方程 multiroot()@rootSolve:給定n個(非線性)方程,求解n個根 uniroot.all()@rootSolve:
【R語言 函式】R語言聚合函式總結
> rm(list=ls()) > > > # 聚合函式學習 > data(iris) > ##tapply 分組求和 > (aa<-tapply(i
【R語言入門】R語言中的變數與基本資料型別
## 說明 在前一篇中,我們介紹了 `R` 語言和 `R Studio` 的安裝,並簡單的介紹了一個示例,接下來讓我們由淺入深的學習 `R` 語言的相關知識。 本篇將主要介紹 `R` 語言的基本操作、變數和幾種基本資料型別,好對 `R` 語言的使用方法有一個基本的概念。通過本篇的學習,你將瞭解到: 1.
【C語言程序】讓用戶輸入一句話,輸出這句話中每個單詞含有多少個字母
get mage 一句話 printf png es2017 urn bsp can #include <stdio.h>#define N 100 //宏定義,用N表示100 int main(int argc, char *argv[]) { int i
解決ubuntu 用anaconda 安裝R 語言後,無法安裝R語言package的問題
info={ 系統:ubuntu 17.10 } 錯誤提示 * installing *source* package ‘quadprog’ ... ** 成功將‘quadprog’程式包解包並MD5和檢查 ** libs /home/longsent/anaconda3/bin/
快樂程式設計大本營【java語言訓練班】 6課:用java的物件和類程式設計
快樂程式設計大本營【java語言訓練班】 6課:用java的物件和類程式設計 第1節. 什麼是物件和類 第2節. 物件的屬性和方法 第3節. 類的繼承 第4節. 使用舉例:建立類,定義方法,定義屬性 第5節. 使用舉例:建立物件,屬性賦值與使用,方法呼叫; 第6節. 使用舉例:類繼承及物件使用 地址如下