
【Python爬蟲】Scrapy框架運用1—爬取豆瓣電影top250的電影資訊(1)
阿新 • • 發佈:2019-01-22
一、Step
step1: 建立工程專案
1.1建立Scrapy工程專案
E:\>scrapy startproject 工程專案
1.2使用Dos指令檢視工程資料夾結構
E:\>tree /f
step2: 建立spider爬蟲程式模板
E:\>cd 工程專案資料夾名稱
E:\dbmovie>scrapy genspider 爬蟲指令碼名稱 訪問網站的域名
step3: 測試網站連線
E:\>dbmovie>scrapy shell 網站url地址
出現403反爬蟲

step4: 將rotate_useragent.py拷貝到工程專案中
備註:設定user-agent使用者代理資訊,隨機輪循;通過rotate_useragent.py我們可以快速得到一個user-agent的列表,並實現自動隨機選取
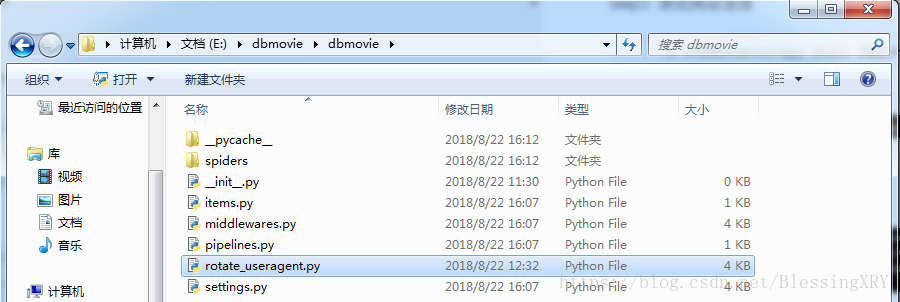
step5: 設定settings.py框架配置檔案,將rotate-useragent.py配置到框架中,此時框架在傳送請求時,會隨機得到user-agent列表中的一個代理資訊
DOWNLOADER_MIDDLEWARES = {
'dbmovie.middlewares.DbmovieDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None,
'dbmovie.rotate_useragent.RotateUserAgentMiddleware' 
此時:重新進行step3,測試連線
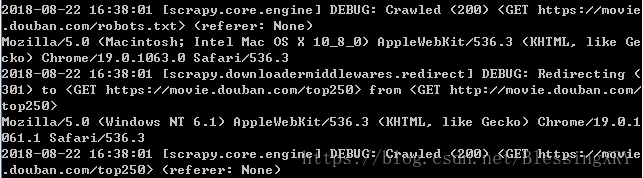
200,連線成功