
golang sql連線池的實現解析
golang的”database/sql”是操作資料庫時常用的包,這個包定義了一些sql操作的介面,具體的實現還需要不同資料庫的實現,mysql比較優秀的一個驅動是:github.com/go-sql-driver/mysql,在介面、驅動的設計上”database/sql”的實現非常優秀,對於類似設計有很多值得我們借鑑的地方,比如beego框架cache的實現模式就是借鑑了這個包的實現;”database/sql”除了定義介面外還有一個重要的功能:連線池,我們在實現其他網路通訊時也可以借鑑其實現。
連線池的作用這裡就不再多說了,我們先從一個簡單的示例看下”database/sql”怎麼用:
package main
import 用法很簡單,首先Open開啟一個數據庫,然後呼叫Query、Exec執行資料庫操作,github.com/go-sql-driver/mysql具體實現了database/sql/driver的介面,所以最終具體的資料庫操作都是呼叫github.com/go-sql-driver/mysql實現的方法,同一個資料庫只需要呼叫一次Open即可,下面根據具體的操作分析下”database/sql”都幹了哪些事。
1.驅動註冊
import _ "github.com/go-sql-driver/mysql"
init()方法,mysql驅動正是通過這種方式註冊到”database/sql”中的://github.com/go-sql-driver/mysql/driver.go
func init() {
sql.Register("mysql", &MySQLDriver{})
}
type MySQLDriver struct{}
func (d MySQLDriver) Open(dsn string) (driver.Conn, error) {
...
}init()通過Register()方法將mysql驅動新增到sql.drivers(型別:make(map[string]driver.Driver))中,MySQLDriver實現了driver.Driver介面:
//database/sql/sql.go
func Register(name string, driver driver.Driver) {
driversMu.Lock()
defer driversMu.Unlock()
if driver == nil {
panic("sql: Register driver is nil")
}
if _, dup := drivers[name]; dup {
panic("sql: Register called twice for driver " + name)
}
drivers[name] = driver
}
//database/sql/driver/driver.go
type Driver interface {
// Open returns a new connection to the database.
// The name is a string in a driver-specific format.
//
// Open may return a cached connection (one previously
// closed), but doing so is unnecessary; the sql package
// maintains a pool of idle connections for efficient re-use.
//
// The returned connection is only used by one goroutine at a
// time.
Open(name string) (Conn, error)
}假如我們同時用到多種資料庫,就可以通過呼叫sql.Register將不同資料庫的實現註冊到sql.drivers中去,用的時候再根據註冊的name將對應的driver取出。
2.連線池實現
先看下連線池整體處理流程:
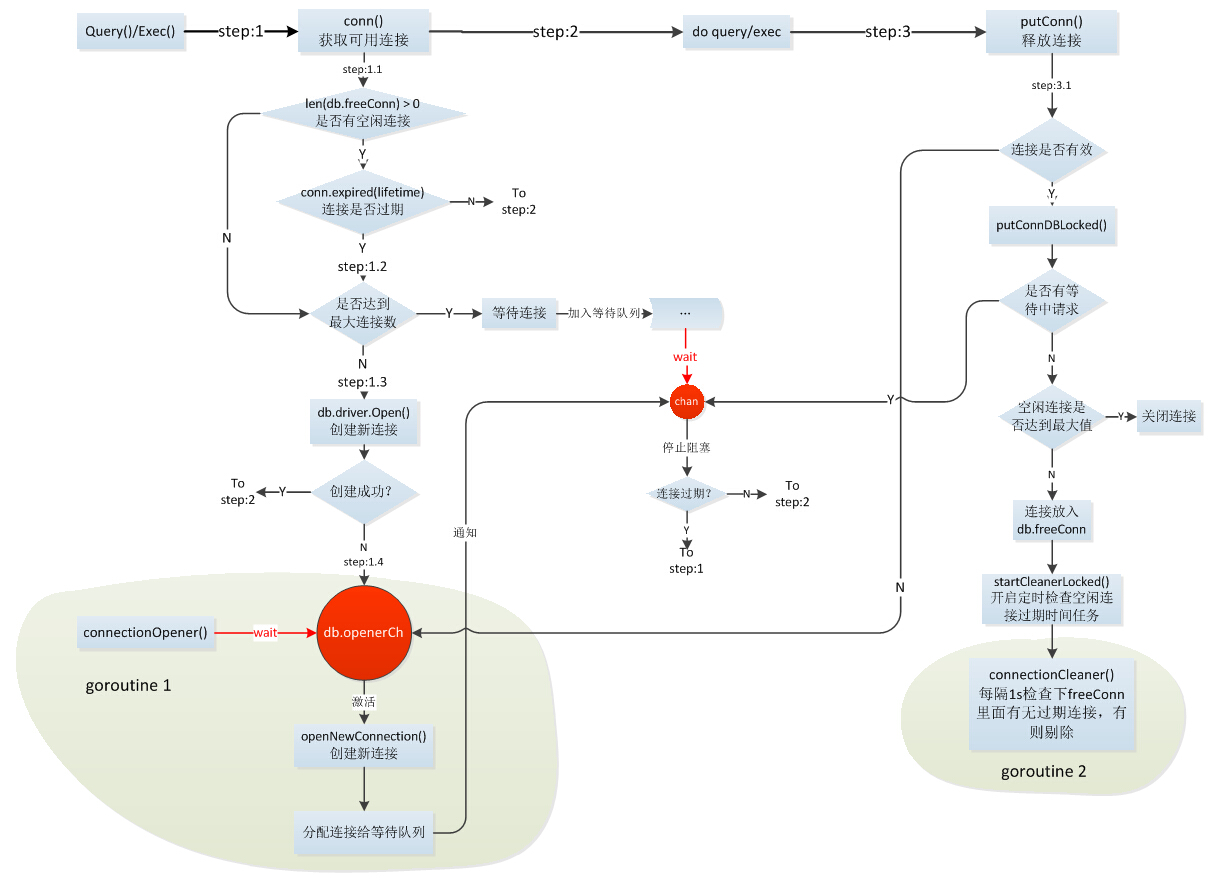
2.1 初始化DB
db, err := sql.Open("mysql", "username:[email protected](host)/db_name?charset=utf8&allowOldPasswords=1")sql.Open()是取出對應的db,這時mysql還沒有建立連線,只是初始化了一個sql.DB結構,這是非常重要的一個結構,所有相關的資料都儲存在此結構中;Open同時啟動了一個connectionOpener協程,後面再具體分析其作用。
type DB struct {
driver driver.Driver //資料庫實現驅動
dsn string //資料庫連線、配置引數資訊,比如username、host、password等
numClosed uint64
mu sync.Mutex //鎖,操作DB各成員時用到
freeConn []*driverConn //空閒連線
connRequests []chan connRequest //阻塞請求佇列,等連線數達到最大限制時,後續請求將插入此佇列等待可用連線
numOpen int //已建立連線或等待建立連線數
openerCh chan struct{} //用於connectionOpener
closed bool
dep map[finalCloser]depSet
lastPut map[*driverConn]string // stacktrace of last conn's put; debug only
maxIdle int //最大空閒連線數
maxOpen int //資料庫最大連線數
maxLifetime time.Duration //連線最長存活期,超過這個時間連線將不再被複用
cleanerCh chan struct{}
}maxIdle(預設值2)、maxOpen(預設值0,無限制)、maxLifetime(預設值0,永不過期)可以分別通過SetMaxIdleConns、SetMaxOpenConns、SetConnMaxLifetime設定。
2.2 獲取連線
上面說了Open時是沒有建立資料庫連線的,只有等用的時候才會實際建立連線,獲取可用連線的操作有兩種策略:cachedOrNewConn(有可用空閒連線則優先使用,沒有則建立)、alwaysNewConn(不管有沒有空閒連線都重新建立),下面以一個query的例子看下具體的操作:
rows, err := db.Query("select * from test")database/sql/sql.go:
func (db *DB) Query(query string, args ...interface{}) (*Rows, error) {
var rows *Rows
var err error
//maxBadConnRetries = 2
for i := 0; i < maxBadConnRetries; i++ {
rows, err = db.query(query, args, cachedOrNewConn)
if err != driver.ErrBadConn {
break
}
}
if err == driver.ErrBadConn {
return db.query(query, args, alwaysNewConn)
}
return rows, err
}
func (db *DB) query(query string, args []interface{}, strategy connReuseStrategy) (*Rows, error) {
ci, err := db.conn(strategy)
if err != nil {
return nil, err
}
//到這已經獲取到了可用連線,下面進行具體的資料庫操作
return db.queryConn(ci, ci.releaseConn, query, args)
}資料庫連線由db.query()獲取:
func (db *DB) conn(strategy connReuseStrategy) (*driverConn, error) {
db.mu.Lock()
if db.closed {
db.mu.Unlock()
return nil, errDBClosed
}
lifetime := db.maxLifetime
//從freeConn取一個空閒連線
numFree := len(db.freeConn)
if strategy == cachedOrNewConn && numFree > 0 {
conn := db.freeConn[0]
copy(db.freeConn, db.freeConn[1:])
db.freeConn = db.freeConn[:numFree-1]
conn.inUse = true
db.mu.Unlock()
if conn.expired(lifetime) {
conn.Close()
return nil, driver.ErrBadConn
}
return conn, nil
}
//如果沒有空閒連線,而且當前建立的連線數已經達到最大限制則將請求加入connRequests佇列,
//並阻塞在這裡,直到其它協程將佔用的連線釋放或connectionOpenner建立
if db.maxOpen > 0 && db.numOpen >= db.maxOpen {
// Make the connRequest channel. It's buffered so that the
// connectionOpener doesn't block while waiting for the req to be read.
req := make(chan connRequest, 1)
db.connRequests = append(db.connRequests, req)
db.mu.Unlock()
ret, ok := <-req //阻塞
if !ok {
return nil, errDBClosed
}
if ret.err == nil && ret.conn.expired(lifetime) { //連線過期了
ret.conn.Close()
return nil, driver.ErrBadConn
}
return ret.conn, ret.err
}
db.numOpen++ //上面說了numOpen是已經建立或即將建立連線數,這裡還沒有建立連線,只是樂觀的認為後面會成功,失敗的時候再將此值減1
db.mu.Unlock()
ci, err := db.driver.Open(db.dsn) //呼叫driver的Open方法建立連線
if err != nil { //建立連線失敗
db.mu.Lock()
db.numOpen-- // correct for earlier optimism
db.maybeOpenNewConnections() //通知connectionOpener協程嘗試重新建立連線,否則在db.connRequests中等待的請求將一直阻塞,知道下次有連線建立
db.mu.Unlock()
return nil, err
}
db.mu.Lock()
dc := &driverConn{
db: db,
createdAt: nowFunc(),
ci: ci,
}
db.addDepLocked(dc, dc)
dc.inUse = true
db.mu.Unlock()
return dc, nil
}總結一下上面獲取連線的過程:
* step1:首先檢查下freeConn裡是否有空閒連線,如果有且未超時則直接複用,返回連線,如果沒有或連線已經過期則進入下一步;
* step2:檢查當前已經建立及準備建立的連線數是否已經達到最大值,如果達到最大值也就意味著無法再建立新的連線了,當前請求需要在這等著連線釋放,這時當前協程將建立一個channel:chan connRequest,並將其插入db.connRequests佇列,然後阻塞在接收chan connRequest上,等到有連線可用時這裡將拿到釋放的連線,檢查可用後返回;如果還未達到最大值則進入下一步;
* step3:建立一個連線,首先將numOpen加1,然後再建立連線,如果等到建立完連線再把numOpen加1會導致多個協程同時建立連線時一部分會浪費,所以提前將numOpen佔住,建立失敗再將其減掉;如果建立連線成功則返回連線,失敗則進入下一步
* step4:建立連線失敗時有一個善後操作,當然並不僅僅是將最初佔用的numOpen數減掉,更重要的一個操作是通知connectionOpener協程根據db.connRequests等待的長度建立連線,這個操作的原因是:
numOpen在連線成功建立前就加了1,這時候如果numOpen已經達到最大值再有獲取conn的請求將阻塞在step2,這些請求會等著先前進來的請求釋放連線,假設先前進來的這些請求建立連線全部失敗,那麼如果它們直接返回了那些等待的請求將一直阻塞在那,因為不可能有連線釋放(極限值,如果部分建立成功則會有部分釋放),直到新請求進來重新成功建立連線,顯然這樣是有問題的,所以maybeOpenNewConnections將通知connectionOpener根據db.connRequests長度及可建立的最大連線數重新建立連線,然後將新建立的連線發給阻塞的請求。
注意:如果maxOpen=0將不會有請求阻塞等待連線,所有請求只要從freeConn中取不到連線就會新建立。
另外Query、Exec有個重試機制,首先優先使用空閒連線,如果2次取到的連線都無效則嘗試新建立連線。
獲取到可用連線後將呼叫具體資料庫的driver處理sql。
2.3 釋放連線
資料庫連線在被使用完成後需要歸還給連線池以供其它請求複用,釋放連線的操作是:putConn():
func (db *DB) putConn(dc *driverConn, err error) {
...
//如果連線已經無效,則不再放入連線池
if err == driver.ErrBadConn {
db.maybeOpenNewConnections()
dc.Close() //這裡最終將numOpen數減掉
return
}
...
//正常歸還
added := db.putConnDBLocked(dc, nil)
...
}
func (db *DB) putConnDBLocked(dc *driverConn, err error) bool {
if db.maxOpen > 0 && db.numOpen > db.maxOpen {
return false
}
//有等待連線的請求則將連線發給它們,否則放入freeConn
if c := len(db.connRequests); c > 0 {
req := db.connRequests[0]
// This copy is O(n) but in practice faster than a linked list.
// TODO: consider compacting it down less often and
// moving the base instead?
copy(db.connRequests, db.connRequests[1:])
db.connRequests = db.connRequests[:c-1]
if err == nil {
dc.inUse = true
}
req <- connRequest{
conn: dc,
err: err,
}
return true
} else if err == nil && !db.closed && db.maxIdleConnsLocked() > len(db.freeConn) {
db.freeConn = append(db.freeConn, dc)
db.startCleanerLocked()
return true
}
return false
}釋放的過程:
* step1:首先檢查下當前歸還的連線在使用過程中是否發現已經無效,如果無效則不再放入連線池,然後檢查下等待連線的請求數新建連線,類似獲取連線時的異常處理,如果連線有效則進入下一步;
* step2:檢查下當前是否有等待連線阻塞的請求,有的話將當前連線發給最早的那個請求,沒有的話則再判斷空閒連線數是否達到上限,沒有則放入freeConn空閒連線池,達到上限則將連線關閉釋放。
* step3:(只執行一次)啟動connectionCleaner協程定時檢查feeConn中是否有過期連線,有則剔除。
有個地方需要注意的是,Query、Exec操作用法有些差異:
- a.
Exec(update、insert、delete等無結果集返回的操作)呼叫完後會自動釋放連線; - b.
Query(返回sql.Rows)則不會釋放連線,呼叫完後仍然佔有連線,它將連線的所屬權轉移給了sql.Rows,所以需要手動呼叫close歸還連線,即使不用Rows也得呼叫rows.Close(),否則可能導致後續使用出錯,如下的用法是錯誤的:
//錯誤
db.SetMaxOpenConns(1)
db.Query("select * from test")
row,err := db.Query("select * from test") //此操作將一直阻塞
//正確
db.SetMaxOpenConns(1)
r,_ := db.Query("select * from test")
r.Close() //將連線的所屬權歸還,釋放連線
row,err := db.Query("select * from test")
//other op
row.Close()相關推薦
golang sql連線池的實現解析 golang sql連線池的實現解析
golang sql連線池的實現解析 golang的”database/sql”是操作資料庫時常用的包,這個包定義了一些sql操作的介面,具體的實現還需要不同資料庫的實現,mysql比較優秀的一個驅動是:github.com/go-sql-dri
golang sql連線池的實現解析
golang的”database/sql”是操作資料庫時常用的包,這個包定義了一些sql操作的介面,具體的實現還需要不同資料庫的實現,mysql比較優秀的一個驅動是:github.com/go-sql-driver/mysql,在介面、驅動的設計上”database/sql”的實現非常優秀,對於類似設計有很多
呼叫SQL連線池 重複開啟connection.Open()連結超時異常的處理
最近遇到一個很奇葩的問題,就是反覆重新整理頁面通過SQL去查詢資料的時候,按了10多遍了後系統會GG,直接卡住奔潰,一直在找問題,最後是SQL讀取資料後資源無釋放,連線無關閉的原因。 DBHelper.cs程式碼: using System; using System.Collectio
【Java】Spring和Tomcat自帶的連線池實現資料庫操作
@[toc] 前言 前面我們已經用Spring和傳統的Jdbc實現資料庫操作、Spring和JdbcTemplate實現資料庫操作。但是這些都是基於直連的資料來源進行的,現在我們將介紹基於連線池的資料來源進行資料庫操作。前面幾個步驟都相同。 建立資料庫 首先建立我們的資料庫(這裡我使用的是Mysql)
jdbc連線池實現
2、連線池實現 下面給出連線池類和連線池管理類的主要屬性及所要實現的基本介面: public class DBConnectionPool implements TimerListener{ private int checkedOut;//已被分配出去的連線數 private ArrayLis
golang redis連線池使用方法
package main import ( "fmt" "github.com/garyburd/redigo/redis" ) var pool *redis.Pool func init() { pool = &redis.Pool{ MaxIdle
servlet+jsp+mysql+資料庫連線池實現註冊登陸驗證碼功能
首先專案的結構及所用到的jar包如圖: 主要用到jdbc和jstl的jar包,大家可自行去相應網站下載 一、資料庫和資料表的建立 1.建庫語句: create database test; 2.建表語句: CREATE TABLE `t_users` (
pymysql的連線池實現
在使用pymysql作為MySQL驅動時,在多執行緒模型下,如果我們沒有為每個執行緒建立一個單獨的連線的話,就會遇到下列錯誤 pymysql.err.InternalError: Packet sequence number wrong - got 0 e
自定義資料庫連線池實現方式 MySQL
應用程式直接獲取資料庫連線缺點 使用者每次請求都會建立一次資料庫連線,並且資料庫建立連線會消耗相對大的資源和時間。 如果針對於個別的工具或者是大量的程式碼測試甚至系統執行,對資料庫操作次數頻繁,極大的佔用資料庫資源,有可能會發生宕機或者記憶體溢位的現象。 而在大多的專案中,常常用到阿里巴
[C++]MYSQL 資料庫操作封裝及連線池實現
Database類為單例類、執行緒安全、實現了連線池,並且封裝所需要的操作。 本程式碼在Ubuntu下測試可用,使用Mysql connector c++連線資料庫,並啟用C++11特性。 基本操作如下: //資料庫配置 DbSetting set
JDBC資料庫連線池實現原理(手動實現)
一、普通的資料庫連線 如下圖所示,個使用者獲取資料庫資料都要單獨建立一個jdbc連線,當用戶獲取資料完成後再將連線釋放,可見對cpu的資源消耗很大。 二
自定義資料庫連線池實現方式 MySQL
應用程式直接獲取資料庫連線缺點 使用者每次請求都會建立一次資料庫連線,並且資料庫建立連線會消耗相對大的資源和時間。 如果針對於個別的工具或者是大量的程式碼測試甚至系統執行,對資料庫操作次數頻繁,極大的佔用資料庫資源,有可能會發生宕機或者記憶體溢位的現象。 而在大多的專案中
c3p0,dbcp和druid連線池效能解析
阿里出品,淘寶和支付寶專用資料庫連線池,但它不僅僅是一個數據庫連線池,它還包含一個ProxyDriver,一系列內建的JDBC元件庫,一個 SQL Parser。支援所有JDBC相容的資料庫,包括Oracle、MySql、Derby、Postgresql、SQL Server、H2等等。Druid針對Or
ftp連線池實現
public class FTPClientPool implements ObjectPool<FTPClient> { private static Logger logger = LoggerFactory.getLogger(FTPClient.class); private s
【轉】C# Sql連線池
使用連線池 連線到資料庫伺服器通常由幾個需要軟長時間的步驟組成。必須建立物理通道(例如套接字或命名管道),必須與伺服器進行初次連線,必須分析連線字串資訊,必須由伺服器對連線進行身份驗證,等等。 實際上,大部份的應用程式都是使用一個或幾個不同的連線配置。當應用程式的資料量和訪問
PHP連線池實現的一種想法
雖然現在名義上是PHP開發,不過做這資料分析的事,平時工作大部分用的是JAVA。C語言出身,學的語言比較多,JAVA還算熟悉,不過之前一直都沒用連線池。第一次遇到連線池是在學校的時候女朋友用連線池出現問題了,找我,我看了下覺得沒必要,直接就刪了。那時候用的是第三方擴充套件,
spring feign http客戶端連線池配置以及spring zuul http客戶端連線池配置解析
背景 一般在生產專案中, Feign會使用HTTP連線池而不是預設的Java原生HTTP單路由單長連線;而是使用連線池。Zuul直接使用Ribbon的Http連線池;Feign和閘道器Zuul的RPC呼叫,實際上都是HTTP請求。HTTP請求,如果不配置好HT
連線池實現連線Mysql資料庫
之前操作資料庫都是直接使用命令操作(因為做的都是小東西,併發量不會很大),但是如果做實際應用的東西就必須考慮使用連線池實現對資料庫的操作,因為資料庫的連線和釋放都會耗費很大的資源,連線池的原理就是連線
資料庫連線池原理詳解與自定義連線池實現
實現原理資料庫連線池在初始化時將建立一定數量的資料庫連線放到連線池中,這些資料庫連線的數量是由最小資料庫連線數制約。無論這些資料庫連線是否被使用,連線池都將一直保證至少擁有這麼多的連線數量。連線池的最大資料庫連線數量限定了這個連線池能佔有的最大連線數,當應用程式向連線池請求的連
fastdfs分散式檔案系統之TrackerServer連線池實現
非常感謝 http://blog.csdn.net/Mr_Smile2014/article/details/52441824 公司使用fastdfs檔案系統來儲存檔案和圖片,為了避免每個系統都直接通過客戶端直接訪問fastdfs檔案系統,所以我們做了一個