
用python爬蟲來爬華科宿舍查電費
準備工作:
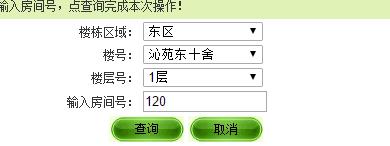
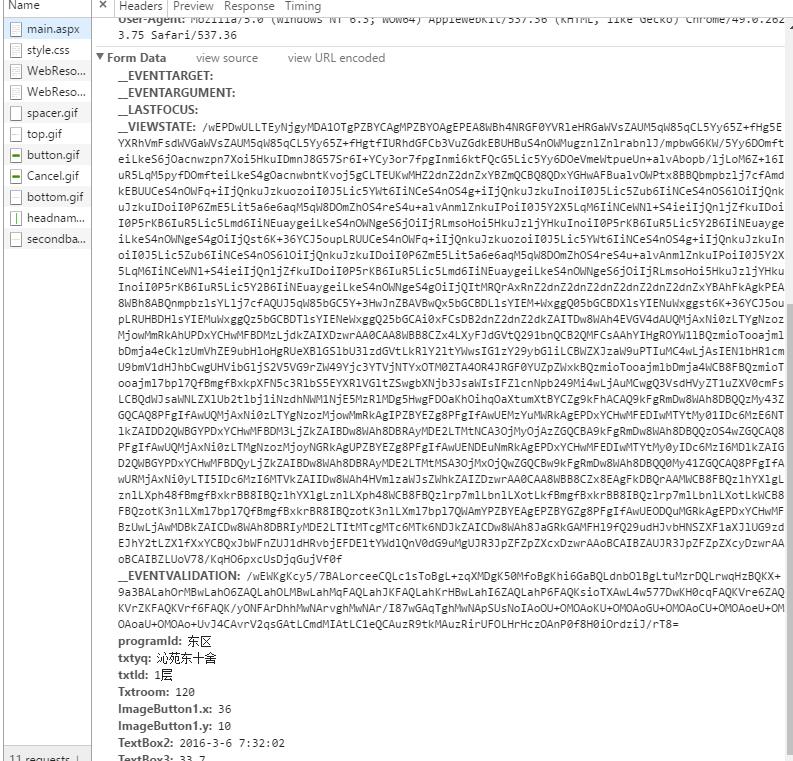
用(谷歌)瀏覽器訪問網址,右鍵開啟’檢查’,審查該網址的元素,檢視檢查框中的NetWork選項。通過嘗試人工進行電費查詢,來查詢Request請求的url和請求時所帶的資料,如下列圖:
從上面圖來看,我們知道請求時所帶的資料除了我們所選擇的樓層資訊外,還有其他兩個奇怪的資訊:
__EVENTVALIDATION 和 __VIEWSTATE。這給我們的爬蟲帶來一定的麻煩。學會使用python的urllib.request庫和BeautifulSoup庫
程式碼部分 :
import urllib.request from bs4 import BeautifulSoup import urllib.error #環境:phthon3.5.1 #請求的連結 url = "http://202.114.18.218/main.aspx" #請求的頭資訊 head = {} head['User-Agent'] = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36' #請求所帶的資料: data = {} data['programId']='東區' data['txtyq']='沁苑東十舍' data['txtld']='1層' data['Txtroom']='120' data['ImageButton1.x']='56' data['ImageButton1.y']='13' data['TextBox2']='2016-3-6 7:08:35' data['TextBox3']='8.7' data['__EVENTTARGET']='' data['__EVENTARGUMENT']='' data['__LASTFOCUS']='' data['__EVENTVALIDATION']='/wEWKgKcy5/7BALorceeCQLc1sToBgL+zqXMDgK50MfoBgKhi6GaBQLdnbOlBgLtuMzrDQLrwqHzBQKX+9a3BALahOrMBwLahO6ZAQLahOLMBwLahMqFAQLahJKFAQLahKrHBwLahI6ZAQLahP6FAQKsioTXAwL4w577DwKH0cqFAQKVre6ZAQKVrZKFAQKVrf6FAQK/yONFArDhhMwNArvghMwNAr/I87wGAqTghMwNApSUsNoIAoOU+OMOAoKU+OMOAoGU+OMOAoCU+OMOAoeU+OMOAoaU+OMOAo+UvJ4CAvrV2qsGAtLCmdMIAtLC1eQCAuzR9tkMAuzRirUFOLHrHczOAnP0f8H0iOrdziJ/rT8=' data['__VIEWSTATE']='/wEPDwULLTEyNjgyMDA1OTgPZBYCAgMPZBYOAgEPEA8WBh4NRGF0YVRleHRGaWVsZAUM5qW85qCL5Yy65Z+fHg5EYXRhVmFsdWVGaWVsZAUM5qW85qCL5Yy65Z+fHgtfIURhdGFCb3VuZGdkEBUHBuS4nOWMugznlZnlrabnlJ/mpbwG6KW/5Yy6DOmfteiLkeS6jOacnwzpn7Xoi5HkuIDmnJ8G57Sr6I+YCy3or7fpgInmi6ktFQcG5Lic5Yy6DOeVmeWtpueUn+alvAbopb/ljLoM6Z+16IuR5LqM5pyfDOmfteiLkeS4gOacnwbntKvoj5gCLTEUKwMHZ2dnZ2dnZxYBZmQCBQ8QDxYGHwAFBualvOWPtx8BBQbmpbzlj7cfAmdkEBUUCeS4nOWFq+iIjQnkuJzkuozoiI0J5Lic5YWt6IiNCeS4nOS4g+iIjQnkuJzkuInoiI0J5Lic5Zub6IiNCeS4nOS6lOiIjQnkuJzkuIDoiI0P6ZmE5Lit5a6e6aqM5qW8DOmZhOS4reS4u+alvAnmlZnkuIPoiI0J5Y2X5LqM6IiNCeWNl+S4ieiIjQnljZfkuIDoiI0P5rKB6IuR5Lic5Lmd6IiNEuaygeiLkeS4nOWNgeS6jOiIjRLmsoHoi5HkuJzljYHkuInoiI0P5rKB6IuR5Lic5Y2B6IiNEuaygeiLkeS4nOWNgeS4gOiIjQst6K+36YCJ5oupLRUUCeS4nOWFq+iIjQnkuJzkuozoiI0J5Lic5YWt6IiNCeS4nOS4g+iIjQnkuJzkuInoiI0J5Lic5Zub6IiNCeS4nOS6lOiIjQnkuJzkuIDoiI0P6ZmE5Lit5a6e6aqM5qW8DOmZhOS4reS4u+alvAnmlZnkuIPoiI0J5Y2X5LqM6IiNCeWNl+S4ieiIjQnljZfkuIDoiI0P5rKB6IuR5Lic5Lmd6IiNEuaygeiLkeS4nOWNgeS6jOiIjRLmsoHoi5HkuJzljYHkuInoiI0P5rKB6IuR5Lic5Y2B6IiNEuaygeiLkeS4nOWNgeS4gOiIjQItMRQrAxRnZ2dnZ2dnZ2dnZ2dnZ2dnZ2dnZxYBAhFkAgkPEA8WBh8ABQnmpbzlsYLlj7cfAQUJ5qW85bGC5Y+3HwJnZBAVBwQx5bGCBDLlsYIEM+WxggQ05bGCBDXlsYIENuWxggst6K+36YCJ5oupLRUHBDHlsYIEMuWxggQz5bGCBDTlsYIENeWxggQ25bGCAi0xFCsDB2dnZ2dnZ2dkZAITDw8WAh4EVGV4dAUQMjAxNi0zLTYgNzozMjowMmRkAhUPDxYCHwMFBDMzLjdkZAIXDzwrAA0CAA8WBB8CZx4LXyFJdGVtQ291bnQCB2QMFCsAAhYIHgROYW1lBQzmioTooajmlbDmja4eCklzUmVhZE9ubHloHgRUeXBlGSlbU3lzdGVtLkRlY2ltYWwsIG1zY29ybGliLCBWZXJzaW9uPTIuMC4wLjAsIEN1bHR1cmU9bmV1dHJhbCwgUHVibGljS2V5VG9rZW49Yjc3YTVjNTYxOTM0ZTA4OR4JRGF0YUZpZWxkBQzmioTooajmlbDmja4WCB8FBQzmioTooajml7bpl7QfBmgfBxkpXFN5c3RlbS5EYXRlVGltZSwgbXNjb3JsaWIsIFZlcnNpb249Mi4wLjAuMCwgQ3VsdHVyZT1uZXV0cmFsLCBQdWJsaWNLZXlUb2tlbj1iNzdhNWM1NjE5MzRlMDg5HwgFDOaKhOihqOaXtumXtBYCZg9kFhACAQ9kFgRmDw8WAh8DBQQzMy43ZGQCAQ8PFgIfAwUQMjAxNi0zLTYgNzozMjowMmRkAgIPZBYEZg8PFgIfAwUEMzYuMWRkAgEPDxYCHwMFEDIwMTYtMy01IDc6MzE6NTlkZAIDD2QWBGYPDxYCHwMFBDM3LjZkZAIBDw8WAh8DBRAyMDE2LTMtNCA3OjMyOjAzZGQCBA9kFgRmDw8WAh8DBQQzOS4wZGQCAQ8PFgIfAwUQMjAxNi0zLTMgNzozMjoyNGRkAgUPZBYEZg8PFgIfAwUENDEuNmRkAgEPDxYCHwMFEDIwMTYtMy0yIDc6MzI6MDlkZAIGD2QWBGYPDxYCHwMFBDQyLjZkZAIBDw8WAh8DBRAyMDE2LTMtMSA3OjMxOjQwZGQCBw9kFgRmDw8WAh8DBQQ0My41ZGQCAQ8PFgIfAwURMjAxNi0yLTI5IDc6MzI6MTVkZAIIDw8WAh4HVmlzaWJsZWhkZAIZDzwrAA0CAA8WBB8CZx8EAgFkDBQrAAMWCB8FBQzlhYXlgLznlLXph48fBmgfBxkrBB8IBQzlhYXlgLznlLXph48WCB8FBQzlrp7mlLbnlLXotLkfBmgfBxkrBB8IBQzlrp7mlLbnlLXotLkWCB8FBQzotK3nlLXml7bpl7QfBmgfBxkrBR8IBQzotK3nlLXml7bpl7QWAmYPZBYEAgEPZBYGZg8PFgIfAwUEODQuMGRkAgEPDxYCHwMFBzUwLjAwMDBkZAICDw8WAh8DBRIyMDE2LTItMTcgMTc6MTk6NDJkZAICDw8WAh8JaGRkGAMFHl9fQ29udHJvbHNSZXF1aXJlUG9zdEJhY2tLZXlfXxYCBQxJbWFnZUJ1dHRvbjEFDEltYWdlQnV0dG9uMgUJR3JpZFZpZXcxDzwrAAoBCAIBZAUJR3JpZFZpZXcyDzwrAAoBCAIBZLUoV78/KqHO6pxcUsDjqGujVf0f' #資料解析 data = urllib.parse.urlencode(data).encode('utf-8') #生成請求 req = urllib.request.Request(url,data,head) #獲取並解析請求得到的回覆 try: response = urllib.request.urlopen(req) except urllib.error.URLError as e: print(e.reason) else: #對回覆讀取並解碼 html = response.read().decode('utf-8') #print(html) #通過BeautifulSoup來解析html soup =BeautifulSoup(html,"html.parser") rest2 = soup.findAll('table',attrs={"rules" : "all"}) r = rest2[0].findAll('td') for e in r: print(e.string)
後續:
- 幾乎查詢每個不同的宿舍時,可能會對應到不同的
__EVENTVALIDATION 和 __VIEWSTATE,經個人的抽樣測驗,輸入條件正確的情況下,上面那對__EVENTVALIDATION 和 __VIEWSTATE對“沁苑東十舍”的宿舍查詢幾乎都是可以的。
專案地址:地址
相關推薦
用python爬蟲來爬華科宿舍查電費
準備工作: 用(谷歌)瀏覽器訪問網址,右鍵開啟’檢查’,審查該網址的元素,檢視檢查框中的NetWork選項。通過嘗試人工進行電費查詢,來查詢Request請求的url和請求時所帶的資料,如下列圖: 從上面圖來看,我們知道請求時所帶的資料除了我們所選擇的
用Python爬蟲爬取廣州大學教務系統的成績(內網訪問)
enc 用途 css選擇器 狀態 csv文件 表格 area 加密 重要 用Python爬蟲爬取廣州大學教務系統的成績(內網訪問) 在進行爬取前,首先要了解: 1、什麽是CSS選擇器? 每一條css樣式定義由兩部分組成,形式如下: [code] 選擇器{樣式} [/code
教你分分鐘學會用python爬蟲框架Scrapy爬取你想要的內容
python 爬蟲 Scrapy python爬蟲 教你分分鐘學會用python爬蟲框架Scrapy爬取心目中的女神 python爬蟲學習課程,下載地址:https://pan.baidu.com/s/1v6ik6YKhmqrqTCICmuceug 課程代碼原件:課程視頻:教你分分鐘學會用py
用Python爬蟲爬取豆瓣電影、讀書Top250並排序
更新:已更新豆瓣電影Top250的指令碼及網站 概述 經常用豆瓣讀書的童鞋應該知道,豆瓣Top250用的是綜合排序,除使用者評分之外還考慮了很多比如是否暢銷、點選量等等,這也就導致了一些近年來評分不高的暢銷書在這個排行榜上高高在上遠比一些經典名著排名還高,於是在這裡打算重新給To
用python爬蟲爬取和登陸github
一 利用API簡單爬取 利用GitHub提供的API爬取前十個star數量最多的Python庫 GitHub提供了很多專門為爬蟲準備的API介面,通過介面可以爬取到便捷,易處理的資訊。(這是GitHub官網的各種api介紹) 使用到的庫 import re
教你分分鐘學會用python爬蟲框架Scrapy爬取心目中的女神
Scrapy,Python開發的一個快速,高層次的螢幕抓取和web抓取框架,用於抓取web站點並從頁面中提取結構化的資料。Scrapy用途廣泛,可以用於資料探勘、監測和自動化測試。 Scrapy吸引人的地方在於它是一個框架,任何人都可以根據需求方便的修改。它也提供了多種型別爬蟲
用python爬蟲爬取網頁桌布圖片(彼岸桌面網唯美圖片)
今天想給我的電腦裡面多加點桌布,但是嫌棄一個個儲存太慢,於是想著寫個爬蟲直接批量爬取,因為爬蟲只是很久之前學過一些,很多基礎語句都不記得了,於是直接在網上找了個有基礎操作語句的爬蟲程式碼,在這上面進行修改以適應我的要求和爬取的網頁需求 注意:這次爬取的
用python爬蟲爬取去哪兒4500個熱門景點,看看國慶不能去哪兒
前言:本文建議有一定Python基礎和前端(html,js)基礎的盆友閱讀。 金秋九月,丹桂飄香,在這秋高氣爽,陽光燦爛的收穫季節裡,我們送走了一個個暑假餘額耗盡哭著走向校園的孩籽們,又即將迎來一年一度偉大祖國母親的生日趴體(無心上班,迫不及待想為祖國母親
記錄一個不同的流媒體網站實現方法,和用Python爬蟲爬它的坑
今天找到一片電影,想把它下載下來。 先開Networks工具分析一下: 初步分析發現,視訊載入時會拉取TS格式的檔案,推測這是一個m3u8的索引,記錄著幾百段TS檔案,這樣方便快進時載入。 但是實際分析m3u8檔案時,發現這並不是一個有效的索引檔案,應該只是載入一個形式,實際的h
python爬蟲:爬取網站視頻
爬蟲 python python爬取百思不得姐網站視頻:http://www.budejie.com/video/新建一個py文件,代碼如下:#!/usr/bin/python # -*- coding: UTF-8 -*- import urllib,re,requests import sys
Python爬蟲(三)爬淘寶MM圖片
name os.path app dir util mozilla user mac baseurl 直接上代碼: # python2 # -*- coding: utf-8 -*- import urllib2 import re import string impo
python爬蟲——對爬到的數據進行清洗的一些姿勢(5)
weibo 英雄 mina ret term creators 刪除 動畫 任務 做爬蟲,當然就要用數據。想拿數據進行分析,首先清洗數據。這個清洗數據包括清除無用數據列和維度,刪除相同數據,對數據進行勘誤之類的。 從各大不同新聞網站可以爬到重復新聞。。。這個可以有。
Python爬蟲之爬取煎蛋網妹子圖
創建目錄 req add 註意 not 相同 esp mpi python3 這篇文章通過簡單的Python爬蟲(未使用框架,僅供娛樂)獲取並下載煎蛋網妹子圖指定頁面或全部圖片,並將圖片下載到磁盤。 首先導入模塊:urllib.request、re、os import
[轉]用python爬蟲抓站的一些技巧總結 zz
內容 req xxxxx pic 個數 相關 choice 都是 observe 來源網站:http://www.pythonclub.org/python-network-application/observer-spider 學用python也有3個多月了,用得最
團隊-張文然-需求分析-python爬蟲分類爬取豆瓣電影信息
工具 新的 翻頁 需求 使用 html 頁面 應該 一個 首先要明白爬網頁實際上就是:找到包含我們需要的信息的網址(URL)列表通過 HTTP 協議把頁面下載回來從頁面的 HTML 中解析出需要的信息找到更多這個的 URL,回到 2 繼續其次還要明白:一個好的列表應該:包含
python爬蟲如何爬知乎的話題?
write targe connect 問題 brush img fetchone new text 因為要做觀點,觀點的屋子類似於知乎的話題,所以得想辦法把他給爬下來,搞了半天最終還是妥妥的搞定了,代碼是python寫的,不懂得麻煩自學哈!懂得直接看代碼,絕對可用 #c
最最簡單的python爬蟲教程--爬取百度百科案例
python爬蟲;人工智能from bs4 import BeautifulSoupfrom urllib.request import urlopenimport reimport randombase_url = "https://baike.baidu.com"#導入相關的包 his
Python爬蟲入門 | 爬取豆瓣電影信息
Python 編程語言 web開發這是一個適用於小白的Python爬蟲免費教學課程,只有7節,讓零基礎的你初步了解爬蟲,跟著課程內容能自己爬取資源。看著文章,打開電腦動手實踐,平均45分鐘就能學完一節,如果你願意,今天內你就可以邁入爬蟲的大門啦~好啦,正式開始我們的第二節課《爬取豆瓣電影信息》吧!啦啦哩啦啦,
Python 爬蟲 ajax爬取馬雲爸爸微博內容
item ber ODB ont 分享 cache cti book 生成 ajax爬取情況 有時候我們在用 Requests 抓取頁面的時候,得到的結果可能和在瀏覽器中看到的是不一樣的,在瀏覽器中可以看到正常顯示的頁面數據,但是使用 Requests 得到的結果並沒有,
我的第一個python爬蟲:爬取豆瓣top250前100部電影
爬取豆瓣top250前100部電影 1 # -*-coding=UTF-8 -*- 2 3 import requests 4 from bs4 import BeautifulSoup 5 6 headers = {'User-Agent':'Moz