
caffe初步實踐---------使用訓練好的模型完成語義分割任務
caffe剛剛安裝配置結束,乘熱打鐵!
(一)環境準備
前面我有兩篇文章寫到caffe的搭建,第一篇cpu only ,第二篇是在伺服器上搭建的,其中第二篇因為硬體環境更佳我們的步驟稍顯複雜。其實,第二篇也僅僅是caffe的初步搭建完成,還沒有編譯python介面,那麼下面我們一起搞定吧!
首先請讀者再回過頭去看我的《Ubuntu16.04安裝配置Caffe》( http://www.cnblogs.com/xuanxufeng/p/6150593.html )
在這篇博文的結尾,我們再增加編譯Python介面,而這部分內容請參考我的博文《Ubuntu14.04搭建Caffe(僅cpu)》 http://www.cnblogs.com/xuanxufeng/p/6016945.html
(二)下載模型
專案檔案結構很清晰,如果想train自己的model,只需要修改一些檔案路徑設定即可,這裡我們應用已經train好的model來測試一下自己的圖片:
我們下載voc-fcn32s,voc-fcn16s以及voc-fcn8s的caffemodel(根據提供好的caffemodel-url),fcn-16s和fcn32s都是缺少deploy.prototxt的,我們根據train.prototxt稍加修改即可。注意,這裡的caffemode-url其實在各個模型的資料夾下面都已經提供給我們了,請讀者細心找一找,看看是不是每一個資料夾下面都有一個caffemode-url的檔案?開啟裡面會有模型的下載地址!
(三)修改infer.py檔案
- caffe path的加入,由於FCN程式碼和caffe程式碼是獨立的資料夾,因此,須將caffe的Python介面加入到path中去。這裡有兩種方案,一種是在所有程式碼中出現
import caffe之前,加入:
1 import sys 2 sys.path.append('caffe根目錄/python')
- 另一種一勞永逸的方法是:在終端或者bashrc中將介面加入到
PYTHONPATH中:
export PYTHONPATH=caffe根目錄/python:$PYTHONPATH
本次我們採用後者。
在解壓程式碼的根目錄下找到一個檔案:infer.py。略微修改infer.py,就可以測試我們自己的圖片了,請大家根據自己實際情況來進行修改。
im = Image.open('voc-fcn8s/test.jpeg') 這裡指的是測試圖片路徑!
net = caffe.Net('voc-fcn8s/deploy.prototxt', 'voc-fcn8s/fcn8s-heavy-pascal.caffemodel', caffe.TEST) ,這裡指的是voc-fcn8s檔案下的部署檔案和模型。注意,fcn下每一個模型其實都對應於一個資料夾,而每個資料夾下應當放著這個模型的caffemodel檔案和prototxt檔案!
plt.savefig('test.png') ,這裡指的是最終分割的結果應當放置在哪個路徑下,大家都知道,語義分割的結果應當是一張圖片!
修改完後的infer.py如下所示:
1 import numpy as np 2 from PIL import Image 3 import matplotlib.pyplot as plt 4 import caffe 5 6 # load image, switch to BGR, subtract mean, and make dims C x H x W for Caffe 7 im = Image.open('voc-fcn8s/test.jpeg') 8 in_ = np.array(im, dtype=np.float32) 9 in_ = in_[:,:,::-1] 10 in_ -= np.array((104.00698793,116.66876762,122.67891434)) 11 in_ = in_.transpose((2,0,1)) 12 13 # load net 14 net = caffe.Net('voc-fcn8s/deploy.prototxt', 'voc-fcn8s/fcn8s-heavy-pascal.caffemodel', caffe.TEST) 15 # shape for input (data blob is N x C x H x W), set data 16 net.blobs['data'].reshape(1, *in_.shape) 17 net.blobs['data'].data[...] = in_ 18 # run net and take argmax for prediction 19 net.forward() 20 out = net.blobs['score'].data[0].argmax(axis=0) 21 22 plt.imshow(out,cmap='gray'); 23 plt.axis('off') 24 plt.savefig('test.png') 25 #plt.show()
執行結束後會在軟體的根目錄下生成一個分割好的圖片test.png!
我們可以看一下原始圖片和最後生成的圖片的區別:


可能會遇到的問題:
(1)no display name and no $DISPLAY environment variable
其實,在Ubuntu虛擬終端裡執行python infer.py是沒有任何錯誤的,但是我是通過遠端訪問連線伺服器的方式執行程式的。所以在執行到最後的時候會報這個錯。不過不要害怕,
在stackoverflow中找到了終極解決辦法:
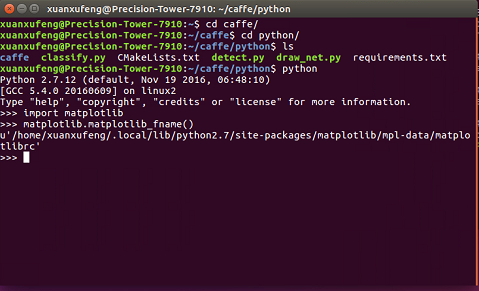
如圖中所示的步驟,找到matplotlibrc,將backend從tkAGG修改為AGG。
sudo gedit /home/xuanxufeng/.local/lib/python2.7/site-packages/matplotlib/mpl-data/matplotlibrc

再次在putty中執行就沒有任何問題了!
(2)在執行python infer.py時可能會提示缺少某一兩個模組。
這個不用擔心,都是小問題,百度很容易搜到,一兩個命令安裝就好了~
(四) 結束語
從開始讀論文到現在,也算是前進了一小步,可以看見的一小步。在往後,隨著實驗的一步步進行,我還會再更新模型的訓練以及訓練資料集的製作!請各位看官耐心等待!
相關推薦
caffe初步實踐---------使用訓練好的模型完成語義分割任務
caffe剛剛安裝配置結束,乘熱打鐵! (一)環境準備 前面我有兩篇文章寫到caffe的搭建,第一篇cpu only ,第二篇是在伺服器上搭建的,其中第二篇因為硬體環境更佳我們的步驟稍顯複雜。其實,第二篇也僅僅是caffe的初步搭建完成,還沒有編譯python介面,那麼下面我們一起搞定吧! 首先請讀者再回過頭
caffe初步實踐---------使用訓練好的模型完成語義分割任務(使用vocfcn32)
利用caffe框架對已經訓練好的模型進行語義分割時要先保證caffe已經安裝配置好,本文的caffe環境是建立在ubuntu 16.04的環境下的,以下是caffe安裝的參考連結: (一)環境準備 本人電腦是暗影精靈二代pro GTX1050 的顯示
Caffe:利用訓練好的模型進行分類
以大神訓練好的模型為基礎,利用自己的資料進行了finetune之後,下一步就可以真正使用模型來進行分類操作了。具體步驟如下: 1. 編輯分類網路的配置檔案deploy.prototxt deploy檔案是真正使用模型時候用的,其結構與train_v
【caffe學習筆記之7】caffe-matlab/python訓練LeNet模型並應用於mnist資料集(2)
【案例介紹】 LeNet網路模型是一個用來識別手寫數字的最經典的卷積神經網路,是Yann LeCun在1998年設計並提出的,是早期卷積神經網路中最有代表性的實驗系統之一,其論文是CNN領域第一篇經典之作。本篇部落格詳細介紹基於Matlab、Python訓練lenet手
caffe使用預訓練的模型進行finetune--caffe學習(1)
首先明確預訓練好的模型和自己的網路結構是有差異的,預訓練模型的引數如何跟自己的網路匹配的呢: –If we provide the weights argument to the caffe train command, the pretrained we
最簡單的基於FCN的語義分割任務
先上一個圖,這個圖展示的是在Weizmann horse 資料集上做的一個語義分割任務時最簡單的全卷積網路結構。其實寫這個部落格是想記錄一下自己前段時間研究FCN的內容,主要工作是在兩個資料集,一個是Weizmann horse 資料集,另一個是lfw資料集。同樣是使用的FCN網路(層數不同
使用訓練好的caffe模型分類圖片(python版)
英文官方文件:http://nbviewer.jupyter.org/github/BVLC/caffe/blob/master/examples/00-classification.ipynb 匯入python caffe包 import numpy as np im
caffe之利用mnist資料集訓練好的lenet_iter_10000.caffemodel模型測試一張自己的手寫體數字
1.安裝一些基本依賴項: $ sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler $ sudo
opencv-python(十三):DNN模組載入caffe訓練好的SSD模型
opencv越來越強大了,可以直接對訓練好的caffe、tensorflow等框架訓練好的模型進行載入,進而完成識別、檢測等任務。 opencv載入caffe訓練好的模型,採用readNetFromCaffe(arg1,arg2),第一個引數對應定義模型結構
caffe的python介面學習(6):用訓練好的模型(caffemodel)來分類新的圖片
#coding=utf-8import caffeimport numpy as nproot='/home/xxx/' #根目錄deploy=root + 'mnist/deploy.prototxt' #deploy檔案caffe_model=root + 'mnist/lenet_iter
將訓練好的caffe模型封裝成動態連結庫提供C++API
<<2018.12.11 照例先po出兩篇部落格 https://blog.csdn.net/maweifei/article/details/72811413 https://blog.csdn.net/jiongnima/article/details/70199480
使用訓練好的caffe模型識別圖片
這裡記錄如何用訓練好的caffe模型來對測試圖片進行識別。 下載訓練好的caffemodel 首先需要一個訓練好的caffemodel,這裡我選用的是caffe官方提供的caffemodel,該模型擁有較多標籤,經過大量的資料訓練得到的。 下載地址:http:/
深度學習Caffe實戰筆記(21)Windows平臺 Faster-RCNN 訓練好的模型測試資料
前一篇部落格介紹瞭如何利用Faster-RCNN訓練自己的資料集,訓練好會得到一個模型,這篇部落格介紹如何利用訓練好的模型進行測試資料。 1、訓練好的模型存放位置 訓練好的模型存放在faster_rcnn-master\output\faster_rcnn_
FCN語義分割初探——使用訓練好的模型進行分割
前言 由於課題的需要,最近開始研究FCN語義分割,這幾天將環境搭建好了立即測試了一下,這裡分享出來與大家進行分享。 1. 準備 1.1 執行環境 這裡使用到的環境是Ubuntu下PyCaffe,具體的環境搭建大家可以參考我的這篇部落格進行環境搭架
DL開源框架Caffe | 用訓練好的模型對資料進行預測
一句話理解Caffe: Caffe的萬丈高樓(Net)是按照我們設計的圖紙(prototxt),用很多磚塊(Blob)築成一層層(Layer)樓房,最後通過某些手段(Solver)進行簡裝修(Train)/精裝修(Finetune)實現的,另外每個樓層都可
caffe練習例項(3)——使用訓練好的模型
本例項是使用opencv編寫程式碼,使用修改後的mnist的deploy檔案並且呼叫訓練好的模型,輸入一張圖片,輸出分類結果。本工程的所有檔案我都上傳到了github上面,需要的可以下載。具體步驟如下: 改寫deploy檔案: 把資料層和(Data
利用caffe訓練好的模型測試自己的手寫字型圖片
轉載地址: http://blog.csdn.net/xunan003/article/details/73126425 一、前沿 寫這篇博文,是因為一開始在做《21天學習caffe》第6天6.4練習題1的時候看著自己搜尋的博文,在不理解其根本的情況下做的
測試一個訓練好的caffe模型
在學習caffe的過程中,訓練了出了模型出來,出了當時的準確率和loss值,並沒有看到給定輸入看到真正的輸出,這個時候需要測試一下訓練出來的模型,實際檢視一下效果,其中用到的配置檔案和網路模型在caffe的目錄下都有,自己測試自己的模型時需要修改為自己的*.prototxt和
用caffe自帶的訓練好的模型測試圖片的分類結果,實現啦啦啦
1、caffemodel檔案下載 可以直接在瀏覽器裡輸入地址下載,也可以執行指令碼檔案下載。下載地址為:http://dl.caffe.berkeleyvision.org/bvlc_reference_caffenet.caffemodel 檔名稱為:b
Caffe用訓練好的模型測試圖片
這是一個python指令碼,用訓練好的caffemodel來測試圖片,接下來直接上程式碼,裡面有詳細解釋,大部分你要修改的只是路徑,另外在這個指令碼的基礎上你可以根據自己的需要進行改動。 需要的東西:訓練好的caffemodel,deploy.prototxt