
caffe練習例項(3)——使用訓練好的模型
本例項是使用opencv編寫程式碼,使用修改後的mnist的deploy檔案並且呼叫訓練好的模型,輸入一張圖片,輸出分類結果。本工程的所有檔案我都上傳到了github上面,需要的可以下載。具體步驟如下:
改寫deploy檔案:
- 把資料層和(Data Layer)和連線資料層的layers去掉(即top:data的層)如下:
- 去掉輸出層和連線輸出層的Layers(即bottom:label)
- 重新建立輸入,新增如下程式碼:


input: "data"
input_shape {
dim: 1 # batchsize,每次forward的時候輸入的圖片個數
dim: 3 - 重新建立輸出,程式碼如下:
layer {
name: "prob"
type: "Softmax"
bottom: "ip2"
top: "prob"
}
使用模型
- opencv原始碼:
#include "opencv2/dnn.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/highgui.hpp"
using namespace cv;
using - 編譯命令:
g++ -o test_mnist test_mnist.cpp -lopencv_dnn -lopencv_highgui -lopencv_imgcodecs -lopencv_imgproc -lstdc++ -lopencv_core 執行效果:
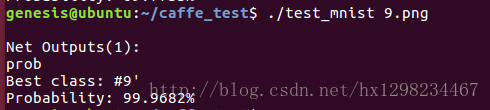
題外話
這裡給在自學caffe的同學一個建議,相比於自學,我覺得有個老師帶領你去學更加有動力,效率會更高。所以我學caffe和opencv都是在練數成金上報課程學習的,建議有需要的可以去報一下,然後報名的時候輸入我的優惠碼,可以有一定的優惠哦!!!
我的優惠碼:JE46
這是caffe課程連結: 深度學習框架Caffe學習與應用
這是opencv課程連結: 開源計算機視覺庫OpenCV從入門到應用
相關推薦
caffe練習例項(3)——使用訓練好的模型
本例項是使用opencv編寫程式碼,使用修改後的mnist的deploy檔案並且呼叫訓練好的模型,輸入一張圖片,輸出分類結果。本工程的所有檔案我都上傳到了github上面,需要的可以下載。具體步驟如下: 改寫deploy檔案: 把資料層和(Data
caffe練習例項(1)——訓練mnist資料集
1.簡介 這是一個非常簡單的例項,主要是為了這個簡單的例項瞭解caffe的工作流程。 2.操作流程 1.獲取資料 在caffe-master/data/mnist資料夾中只有一
caffe練習例項(4)——caffe實現caltech101資料集影象分類
1.準備資料集 caltech101(101類影象資料庫)資料集 資料集地址: http://www.vision.caltech.edu/Image_Datasets/Caltech101/Calt
python學習例項(3)
#=================================== #3.4 關於Python的函式呼叫 #=================================== #+++++++++++++++++++++++++++++++++++ #3.4.2
fork函式_例項(3)呼叫兩次以避免僵死程序
--------參考文獻 W.Richard Stevens, Stephen A.Rago.UNIX環境高階程式設計[M].北京:人民郵電出版社,2014.6:189-190. 一、 相關概念 1.1 僵死程序 一個已經終止,但是其父程序尚未對其進行善後處理
深度學習之caffe環境搭建(3)
ubuntu 系統下的Caffe環境搭建 作者:hjimce 對於caffe的系統一般使用linux系統,當然也有windows版本的caffe,不過如果你一開始使用了windows下面的caffe,後面學習的過程中,會經常遇到各種錯誤,網上下載的一些原始碼、模型也往往不
caffe隨記(七)---訓練和測試自己的圖片
前面也介紹了tools工具,今天來試著自己跑一下影象分類的例項 1、下載資料 我沒有用imagenet的資料,因為太大了不想下,而且反正也只是當作例程跑一下而已,所以我用的是另一位博主分享的網盤上的資料,共有500張圖片,分為大巴車、恐龍、大象、鮮花和馬五個類,每個類1
利用tensorflow訓練自己的圖片資料(3)——建立網路模型
一. 說明 在上一部落格——利用tensorflow訓練自己的圖片資料(2)中,我們已經獲得了神經網路的訓練輸入資料:image_batch,label_batch。接下就是建立神經網路模型,筆者的網路模型結構如下: 輸入資料:(batch_size,IMG_W,IMG_H
深度學習Caffe實戰筆記(3)用AlexNet跑自己的資料
上一篇部落格介紹瞭如何在caffe框架平臺下,用LeNet網路訓練車牌識別資料,今天介紹用AlexNet跑自己的資料,同樣基於windows平臺下,會比基於Ubuntu平臺下麻煩一些,特別是後面的Siamese網路,說起Siamese網路真是一把辛酸一把淚啊,先
myeclipse實現Servlet例項(3) 通過繼承HttpServlet介面實現
(1) 在軟體公司 90%都是通過該方法開發. //在HttpServlet 中,設計者對post 提交和 get提交分別處理 //回憶 <form action="提交給?" method="post|get"/>,預設是get (2)小結 get 提交
特徵提取使用已有的卷積基(VGG16)訓練微型模型
程式碼是《Python深度學習》上的,自己敲一遍看看,我自己的聯想拯救者跑起來都比較慢,GPU will be better! # -*- coding: utf-8 -*- """ Created on Tue Oct 30 22:04:30 2018 @author: Lxiao217 "
Spark學習筆記(3)—— Spark計算模型 RDD
1 彈性分散式資料集RDD 1.1 什麼是 RDD RDD(Resilient Distributed Dataset)叫做分散式資料集,是Spark中最基本的資料抽象,它代表一個不可變、可分割槽、裡面的元素可平行計算的集合。RDD具有資料流模型的特點:自動容錯
併發程式設計-(3)Java記憶體模型和volatile
目錄 1、記憶體模型概念 2、多執行緒的特性 1.1、原子性 1.2、可見性 1.3、有序性 2、Java記憶體模型 2.1、JMM和JVM 2.2、Java記憶體模型(JMM) 2.2.1、案例 2
scikit-leran學習筆記(3)---神經網路模型(有監督的)
1.Multi-layer Perceptron 多層感知機 MLP是一個監督學習演算法,圖1是帶一個隱藏層的MLP模型 左邊層是輸入層,由神經元集合{xi|x1,x2,…,xm},代表輸入特徵,隱藏層的每個神經元將前一層的的值通過線性加權求
PCL庫學習(3)----基於平面模型的點雲分割(地面點雲分割)(Plane Model Segmentation)
執行環境: VS2013,PCL1.8.0 程式碼參考: 最近做的專案需要對採集到的點雲場景進行去除地面的操作。在參考了CSDN博主:有夢想的田園犬對於PCL官方几種例程中的點雲分割方法的實驗後,考慮到系統的實時性要求,選擇基於平面模型的地面點雲去噪方
深度學習Caffe實戰筆記(21)Windows平臺 Faster-RCNN 訓練好的模型測試資料
前一篇部落格介紹瞭如何利用Faster-RCNN訓練自己的資料集,訓練好會得到一個模型,這篇部落格介紹如何利用訓練好的模型進行測試資料。 1、訓練好的模型存放位置 訓練好的模型存放在faster_rcnn-master\output\faster_rcnn_
深度學習與人臉識別系列(3)__利用caffe訓練深度學習模型
name: "VGG_FACE_16_layers" layer { top: "data_1" top: "label_1" name: "data_1" type: "Data" data_param { source: "/media/gk/9ec75485-26b1-471
算法導論22.3深度優先搜索 練習總結 (轉載)
由於 .net -c art 單個 hit 包含 strong 進行 22.3-1 畫一個 3*3 的網格,行和列的擡頭分別標記為白色、灰色和黑色,對於每個表單元 (i, j),請指出對有向圖進行深度優先搜索的過程中,是否可能存在一條邊,鏈接一個顏色為 i 的結點和一個顏色
dp練習(3)
output size rip names sample 有一個 象棋 ret 圖片 設有一個n*m的棋盤(2≤n≤50,2≤m≤50),如下圖,在棋盤上有一個中國象棋馬。 規定: 1)馬只能走日字 2)馬只能向右跳 問給定起點x1,y1和終點x2,y2,求出馬從x1,
小練習(3)
radi img com 1.5 放大 bubuko css padding 小練習 <!DOCTYPE html> <html> <head> <meta charset="UTF-8">