
Encoder-Decoder模型和Attention模型
1.Encoder-Decoder模型及RNN的實現
所謂encoder-decoder模型,又叫做編碼-解碼模型。這是一種應用於seq2seq問題的模型。
那麼seq2seq又是什麼呢?簡單的說,就是根據一個輸入序列x,來生成另一個輸出序列y。seq2seq有很多的應用,例如翻譯,文件摘取,問答系統等等。在翻譯中,輸入序列是待翻譯的文字,輸出序列是翻譯後的文字;在問答系統中,輸入序列是提出的問題,而輸出序列是答案。
為了解決seq2seq問題,有人提出了encoder-decoder模型,也就是編碼-解碼模型。所謂編碼,就是將輸入序列轉化成一個固定長度的向量;解碼,就是將之前生成的固定向量再轉化成輸出序列。
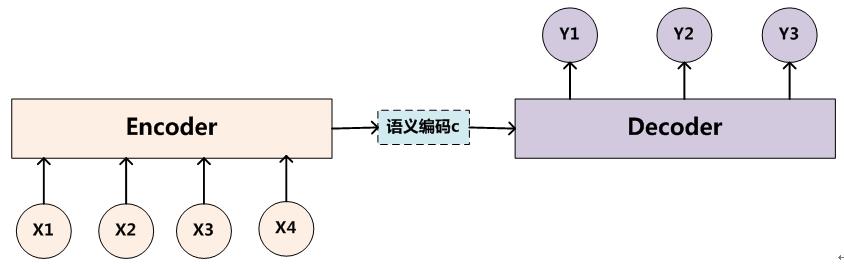
當然了,這個只是大概的思想,具體實現的時候,編碼器和解碼器都不是固定的,可選的有CNN/RNN/BiRNN/GRU/LSTM等等,你可以自由組合。比如說,你在編碼時使用BiRNN,解碼時使用RNN,或者在編碼時使用RNN,解碼時使用LSTM等等。
這邊為了方便闡述,選取了編碼和解碼都是RNN的組合。在RNN中,當前時間的隱藏狀態是由上一時間的狀態和當前時間輸入決定的,也就是
ht=f(ht−1,xt)◂=▸ht=f(◂,▸◂◽.▸ht−1,xt)
獲得了各個時間段的隱藏層以後,再將隱藏層的資訊彙總,生成最後的語義向量
C=q(h1,h2,h3,…,hTx)◂=▸C=q(◂,▸h1,h2,h3,…,◂◽.▸hTx)
一種簡單的方法是將最後的隱藏層作為語義向量C,即
C=q(h1,h2,h3,…,hTx)=hTx◂=⋯▸C=q(◂,▸h1,h2,h3,…,◂◽.▸hTx)=◂◽.▸hTx
解碼階段可以看做編碼的逆過程。這個階段,我們要根據給定的語義向量C和之前已經生成的輸出序列y1,y2,…yt−1◂,▸y1,y2,…◂◽.▸yt−1來預測下一個輸出的單詞ytyt,即
yt=argmaxP(yt)=∏t=1Tp(yt|{y1,…,yt−1},C)◂=⋯▸yt=◂+▸argmaxP(yt)=◂∏▸∏t=1Tp(◂,▸yt|{◂,▸y1,…,◂◽.▸yt−1},C)
也可以寫作
yt=g({y1,…,yt−1},C)◂=▸yt=g({◂,▸y1,…,◂◽.▸yt−1},C)
而在RNN中,上式又可以簡化成
yt=g(yt−1,st,C)◂=▸yt=g(◂,▸◂◽.▸yt−1,st,C)
其中ss是輸出RNN中的隱藏層,C代表之前提過的語義向量,yt−1◂◽.▸yt−1表示上個時間段的輸出,反過來作為這個時間段的輸入。而g則可以是一個非線性的多層的神經網路,產生詞典中各個詞語屬於ytyt的概率。
encoder-decoder模型雖然非常經典,但是侷限性也非常大。最大的侷限性就在於編碼和解碼之間的唯一聯絡就是一個固定長度的語義向量C。也就是說,編碼器要將整個序列的資訊壓縮排一個固定長度的向量中去。但是這樣做有兩個弊端,一是語義向量無法完全表示整個序列的資訊,還有就是先輸入的內容攜帶的資訊會被後輸入的資訊稀釋掉,或者說,被覆蓋了。輸入序列越長,這個現象就越嚴重。這就使得在解碼的時候一開始就沒有獲得輸入序列足夠的資訊, 那麼解碼的準確度自然也就要打個折扣了
2.Attention模型
為了解決這個問題,作者提出了Attention模型,或者說注意力模型。簡單的說,這種模型在產生輸出的時候,還會產生一個“注意力範圍”表示接下來輸出的時候要重點關注輸入序列中的哪些部分,然後根據關注的區域來產生下一個輸出,如此往復。模型的大概示意圖如下所示
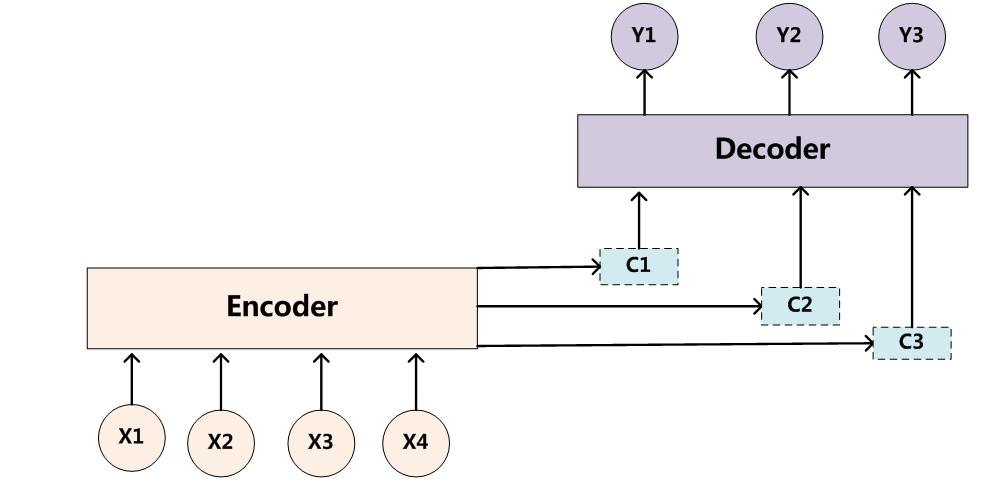
相比於之前的encoder-decoder模型,attention模型最大的區別就在於它不在要求編碼器將所有輸入資訊都編碼進一個固定長度的向量之中。相反,此時編碼器需要將輸入編碼成一個向量的序列,而在解碼的時候,每一步都會選擇性的從向量序列中挑選一個子集進行進一步處理。這樣,在產生每一個輸出的時候,都能夠做到充分利用輸入序列攜帶的資訊。而且這種方法在翻譯任務中取得了非常不錯的成果。
在這篇文章中,作者提出了一個用於翻譯任務的結構。解碼部分使用了attention模型,而在編碼部分,則使用了BiRNN(bidirectional RNN,雙向RNN)
2.1 解碼
我們先來看看解碼。解碼部分使用了attention模型。類似的,我們可以將之前定義的條件概率寫作
p(yi|y1,…,yi−1,X)=g(yi−1,si,ci)◂=▸p(◂,▸yi|y1,…,◂◽.▸yi−1,X)=g(◂,▸◂◽.▸yi−1,si,ci)
上式sisi表示解碼器i時刻的隱藏狀態。計算公式是
si=f(si−1,yi−1,ci)◂=▸si=f(◂,▸◂◽.▸si−1,◂◽.▸yi−1,ci)
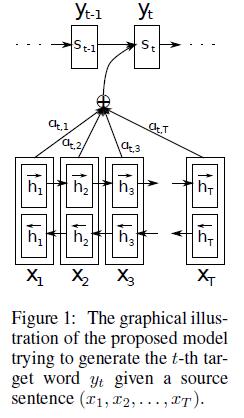
注意這裡的條件概率與每個目標輸出yiyi相對應的內容向量cici有關。而在傳統的方式中,只有一個內容向量C。那麼這裡的內容向量cici又該怎麼算呢?其實cici是由編碼時的隱藏向量序列(h1,…,hTx)(◂,▸h1,…,◂◽.▸hTx)按權重相加得到的。
ci=∑j=1Txαijhjci=◂∑▸∑j=1Tx◂◽.▸αijhj
由於編碼使用了雙向RNN,因此可以認為hihi中包含了輸入序列中第i個詞以及前後一些詞的資訊。將隱藏向量序列按權重相加,表示在生成第j個輸出的時候的注意力分配是不同的。αij◂◽.▸αij的值越高,表示第i個輸出在第j個輸入上分配的注意力越多,在生成第i個輸出的時候受第j個輸入的影響也就越大。那麼現在我們又有新問題了,αij◂◽.▸αij又是怎麼得到的呢?這個其實是由第i-1個輸出隱藏狀態si−1◂◽.▸si−1和輸入中各個隱藏狀態共同決定的。也即是
αij=exp(eij)∑Txk=1exp(eik)eij=a(si−1,hj)◂=⋯▸◂◽.▸αij=◂⋅▸exp(◂◽.▸eij)◂∑▸∑k=1Tx◂⋅▸exp(◂◽.▸eik)◂◽.▸eij=a(◂,▸◂◽.▸si−1,hj)
也就是說,si−1◂◽.▸si−1先跟每個hh分別計算得到一個數值,然後使用softmax得到i時刻的輸出在TxTx個輸入隱藏狀態中的注意力分配向量。這個分配向量也就是計算cici的權重。我們現在再把公式按照執行順序彙總一下:
eij=a(si−1,hj)αij=exp(eij)∑Txk=1exp(eik)ci=∑j=1Txαijhjsi=f(si−1,yi−1,ci)yi=g(yi−1,si,ci)◂=▸◂◽.▸eij=a(◂,▸◂◽.▸si−1,hj)◂◽.▸αij=◂⋅▸exp(◂◽.▸eij)◂∑▸∑k=1Tx◂⋅▸exp(◂◽.▸eik)ci=◂∑▸∑j=1Tx◂◽.▸αijhj◂=▸si=f(◂,▸◂◽.▸si−1,◂◽.▸yi−1,ci)◂=▸yi=g(◂,▸◂◽.▸yi−1,si,ci)
上面這些公式就是解碼器在第i個時間段內要做的事情。作者還給了一個示意圖:
2.2 編碼
相比於上面解碼的創新,這邊的編碼就比較普通了,只是傳統的單向的RNN中,資料是按順序輸入的,因此第j個隱藏狀態h→j◂◽.▸h→j只能攜帶第j個單詞本身以及之前的一些資訊;而如果逆序輸入,則h←j◂◽.▸h←j包含第j個單詞及之後的一些資訊。如果把這兩個結合起來,hj=[h→j,h←j]◂=▸hj=[◂◽.▸h→j,◂◽.▸h←j]就包含了第j個輸入和前後的資訊。
3.實驗結果
為了檢驗效能,作者分別使用傳統模型和attention模型在英語-法語的翻譯資料集上進行了測驗。
傳統模型的編碼器和解碼器各有1000個隱藏單元。編碼器中還有一個多層神經網路用於實現從隱藏狀態到單詞的對映。在優化方面,使用了SGD(minibatch stochastic gradient descent)以及Adadelta,前者負責取樣,後者負責優化下降方向。
得到的結果如下: 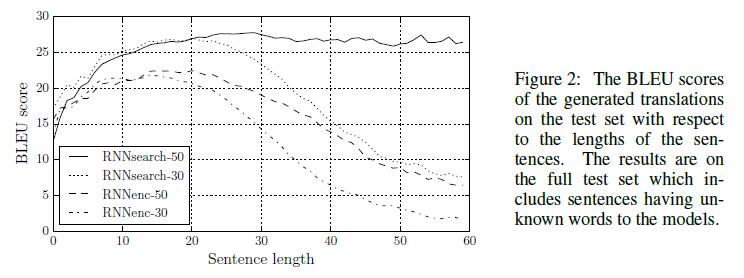
圖中RNNenc表示傳統的結構,而RNNsearch表示attention模型。後面的數字表示序列的長度。可以看到,不論序列長度,attention模型的效能均優於傳統的編碼-解碼模型。而RNNsearch-50甚至在長文字上的效能也非常的優異
除了準確度之外,還有一個很值得關注的東西:注意力矩陣。之前已經提過,每個輸出都有一個長為TxTx的注意力向量,那麼將這些向量合起來看,就是一個矩陣。對其進行視覺化,得到如下結果
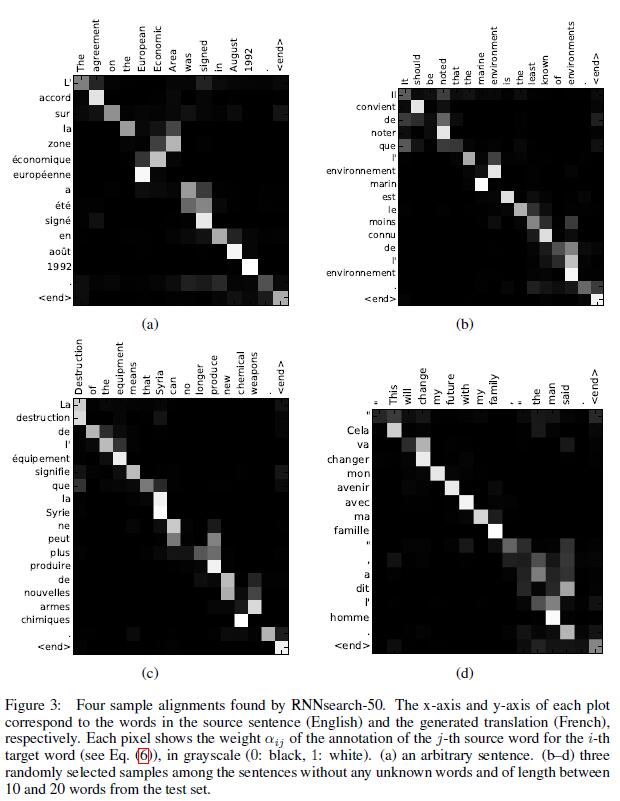
其中x軸表示待翻譯的句子中的單詞(英語),y軸表示翻譯以後的句子中的單詞(法語)。可以看到儘管從英語到法語的過程中,有些單詞的順序發生了變化,但是attention模型仍然很好的找到了合適的位置。換句話說,就是兩種語言下的單詞“對齊”了。因此,也有人把注意力模型叫做對齊(alignment)模型。而且像比於用語言學實現的硬對齊,這種基於概率的軟對齊更加優雅,因為能夠更全面的考慮到上下文的語境。
相關推薦
深度學習筆記(六):Encoder-Decoder模型和Attention模型
這兩天在看attention模型,看了下知乎上的幾個回答,很多人都推薦了一篇文章Neural Machine Translation by Jointly Learning to Align and Translate 我看了下,感覺非常的不錯,裡面還大
Encoder-Decoder模型和Attention模型
1.Encoder-Decoder模型及RNN的實現 所謂encoder-decoder模型,又叫做編碼-解碼模型。這是一種應用於seq2seq問題的模型。 那麼seq2seq又是什麼呢?簡單的說,就是根據一個輸入序列x,來生成另一個輸出序列y。seq2seq有很多的應用
深度學習---深度學習筆記(七):Encoder-Decoder模型和Attention模型
這兩天在看attention模型,看了下知乎上的幾個回答,很多人都推薦了一篇文章Neural Machine Translation by Jointly Learning to Align and Translate 我看了下,感覺非常的不錯,裡面還大概闡述了encoder
判別模型和生成模型
使用 sin cow ria regress gauss 生成 == 給定 【摘要】 - 生成模型:無窮樣本==》概率密度模型 = 產生模型==》預測 - 判別模型:有限樣本==》判別函數 = 預測模型==》預測 【簡介】 簡單的說,假設o是觀察值,
生成模型和判別模型
特征 數據 學習方法 最大 mem 針對 表示 不能 問題 1、定義: 生成模型(或稱產生式模型)和判別模型(或稱判別式模型)的本質區別在於模型中觀測序列x和狀態序列y的決定關系。前者假設y決定x,後者假設x決定y。 2、生成模型特點 2.1、生成模型以“狀態序列y按照一定
對星型模型和雪花模型的簡單理解
alt 存在 body 所有 維度 info 多層 分享 post 星形模型 雪花模型 星型模型是所有維度表都是連接在一個事實表上面,雪花模型是將維度表拆分地更加詳細,是多層次的。 在星型模型的維度表裏面,一張維度表儲存了眾多存在冗余的信息,為什麽冗余,在哪裏冗余,我
Actor模型和CSP模型的區別
Akka/Erlang的actor模型與Go語言的協程Goroutine與通道Channel代表的CSP(Communicating Sequential Processes)模型有什麼區別呢? 首先這兩者都是併發模型的解決方案,我們看看Actor和Channel這兩個方案的不同:
【IM】關於引數模型和核模型的理解
學習模型按照引數與維度還是樣本相關,可分為引數模型(引數與維度相關)和核模型(引數與樣本相關)。 對於核模型的核方法或核函式說明有如下博文,參考《圖解機器學習》理解如下兩頁。 https://blog.csdn.net/fjssharpsword/article/details/8166
MVC模型和MTV模型
MVC模型 MVC 設計模型是一種使用 Model View Controller( 模型-檢視-控制器)設計建立 Web 應用程式的模式。 Model(模型):是應用程式中用於處理應用程式資料邏輯的部分。 通常模型物件負責在資料庫中存取資料。 View(檢視):是
機器學習之---生成模型和判別模型
監督學習方法可分為兩大類,即生成方法與判別方法,它們所學到的模型稱為生成模型與判別模型。 判別模型:判別模型是學得一個分類面(即學得一個模型),該分類面可用來區分不同的資料分別屬於哪一類; 生成模型:生成模型是學得各個類別各自的特徵(即可看成學得多個模型),可用這些
判別模型和生成模型——機器學習
轉載自:https://www.cnblogs.com/zeze/p/7047630.html 判別式模型(discriminative model) 產生式模型(generative model)
bs模型和cs模型
bs模式 客戶端通過瀏覽器,瀏覽web伺服器上的網頁,這樣的模型叫bs模型,b指客戶端browser,s指服務端server。在客戶端和瀏覽器端之間走的報文是http協議(即超文字傳輸協議) cs模型 客戶端(client)發報文,伺服器(
【機器學習】生成模型和判別模型
定義: 生成方法由資料學習聯合概率分佈P(x, y),然後求出條件概率分佈P(y|x)作為預測的模型。 包括樸素貝葉斯,貝葉斯網路,高斯混合模型,隱馬爾科夫模型等。 判別方法由資料直接學習決策函式
資料庫設計---PowerDesigner(物理模型和概念模型)
上一篇介紹了個工具建資料庫:PowerDesigner V16.5 安裝教程以及漢化(資料庫建模)?,現在我就說一下怎麼用這個建資料庫吧。 1、首先新建模型--選擇概念模型(CDM) 2、新建實體(學生和卡),設定相應的屬性
CNN模型和RNN模型在分類問題中的應用(Tensorflow實現)
在這篇文章中,我們將實現一個卷積神經網路和一個迴圈神經網路語句分類模型。 本文提到的模型(rnn和cnn)在一系列文字分類任務(如情緒分析)中實現了良好的分類效能,並且由於模型簡單,方便實現,成為了競賽和實戰中常用的baseline。 cnn-text-classifica
tensorflow儲存模型和恢復模型
儲存模型 w1 = tf.placeholder("float", name="w1") w2 = tf.placeholder("float", name="w2") b1= tf.Variable(2.0,name="bias") feed_dict ={w1:4,w2:8} w3 =
Tensorflow載入預訓練模型和儲存模型
使用tensorflow過程中,訓練結束後我們需要用到模型檔案。有時候,我們可能也需要用到別人訓練好的模型,並在這個基礎上再次訓練。這時候我們需要掌握如何操作這些模型資料。看完本文,相信你一定會有收穫! 1 Tensorflow模型檔案 我們在checkpo
揭祕阿里小蜜:基於檢索模型和生成模型相結合的聊天引擎
面向 open domain 的聊天機器人無論在學術界還是工業界都是個有挑戰的課題,目前有兩種典型的方法:一是基於檢索的模型,二是基於 Seq2Seq 的生成式模型。前者回復答案可控但無法處理長尾問題,後者則難以保證一致性和合理性。 本期推薦的論文筆記來自 Pa
CSS學習—盒模型和佈局模型
最近做的小專案需要搭建一個小網站,因此從 慕課網 上學習HTML+CSS的基礎知識,將接觸到的知識點用這個部落格總結出來。 一、盒模型 1.元素分類 在CSS中,html中的標籤元素大體被分為三種不同的型別:塊狀元素、內聯元素(又叫行內元素)和內聯塊狀元素
Python機器學習筆記:深入理解Keras中序貫模型和函式模型
先從sklearn說起吧,如果學習了sklearn的話,那麼學習Keras相對來說比較容易。為什麼這樣說呢? 我們首先比較一下sklearn的機器學習大致使用流程和Keras的大致使用流程: sklearn的機器學習使用流程: 1 2 3 4