
C++語言的表示式模板:表示式模板的入門性介紹
這段小小的程式引發了之後多年對所謂模板超程式設計的雪崩般的研究。本文將介紹從中得來 的一些程式設計技巧和技術。那麼,模板超程式設計的工作原理是什麼呢?
從本質上來看,無論是質數的計算,還是本文中所提及的其他技術,都是基於如下原理的 :模板的例項化是一個遞迴過程。當編譯器例項化一個模板時,它可能會發現在此之前另 外的模板需要首先例項化;在例項化這些模板的時候,又會發現有更多的模板需要例項化 。許多模板超程式設計的技巧就是基於這個原理,來實現遞迴式的計算的。
階乘——編譯時計算的第一個例子
作為第一個例子,我們來在編譯時對N的階乘進行計算。N的階乘(記作N!)定義為從1到N 所有整數的積。(譯註2),作為一個特例,0的階乘是1。通常對階乘的遞迴計算可以採用 函式遞迴的方法,如下是一個執行時計算的例子:int factorial(int n) { return (n == 0 ? 1 : n * factorial(n - 1)); }
這個函式反覆呼叫自身,直到引數n的值減少到0為止。使用的例子:
cout << factorial(4) << endl;遞迴式的函式呼叫是昂貴的,特別是在編譯器無法進行內聯(inline)優化的時候——這樣 函式呼叫的負擔馬上就凸顯出來。我們可以用編譯時計算來避免這一點。做法如下:用遞 歸式的模板例項化來代替遞迴式的函式呼叫。這樣,名為factorial的函式將由名為 factorial的類代替:
template <int n> struct factorial { enum { ret = factorial<n-1>::ret * n }; };
這個模板類既沒有資料也沒有成員函式,而僅僅是定義了有唯一enum值的匿名enum型別。 (之後便可以看到,factorial::ret起到了函式返回值的作用。)為了計算這個值,編譯 器必須反覆例項化以n-1為模板引數的新的模板類,這就是遞迴的第一推動力。
值得注意的是,factorial模板類的引數並不常見:它並不是一個型別的佔位符,而是一個 int型別的常量。常見的模板引數都和下面的例子類似:
template <typename T> class X {...};其中T是一個實際型別的佔位符。在編譯器遇到形如X<int>的程式碼時,T將被具體的型別( int)所取代。在我們的例子中,實際型別int成為了模板的引數,也就是說,在編譯時將 被具體的int型別的值所取代。呼叫此模板類的程式碼可以是這樣的:
cout << factorial<4>::ret <<endl;
編譯器將依次例項化factorial<4>,factorial<3>……我們注意到,這個遞迴是沒有終點的 。這樣可不行。所以,需要利用模板的特化來提供這樣一個終點。在我們的這個例子裡:
template <>
struct factorial<0>
{
enum { ret = 1 };
};
從上述程式碼片段中可以看到遞迴將止步於此。因為此時enum的值已經不再依賴例項化其他 模板類了。
倘若你不熟悉模板的特化,在這裡只需要記住對於特定的模板引數,可以提供一個特殊的 類模板即可。在我們的例子中我們提供了一個特殊的,引數為0的階乘模板類。在這裡編譯 器可以不再通過遞迴來計算需要的值。
那麼我們這麼計算階乘,好處是什麼呢?表示式factorial<4>::ret在編譯時將會被其具體 數值,也就是24所取代。執行時無需對此進行計算。在可執行檔案裡,是找不到計算的痕跡的。
開平方根——編譯時計算的又一個例子
讓我們試試另外一個編譯時計算的例子。這一次,我們試圖計算N的平方根的近似值——更準 確的說,我們希望能找到一個整數,使得它的平方是最小的比N的平方大的完全平方數。例 如:10的平方根大約是3.1622776601,所以哦我們希望能通過程式設計得到4這個比 3.1622776601大的最小的整數。如果採用執行時計算的方法的話,我們就需要呼叫C的標準 庫:ceil(sqrt(N))。但是如果需要用這個值來定義陣列的大小的話,那麼我們就倒了大黴 :int array[ceil(sqrt(N))];不能通過編譯,因為陣列的大小在編譯時必須是一個常數。(譯註3)因此,我們有理由在 編譯時進行計算。
回憶一下我們在第一個例子中所做的:我們利用了模板例項化是通過遞迴進行這一特性。 在這裡我們再次通過引發遞迴式的模板例項化來近似獲取相應的值。這裡我們定義一個有 一個給定型別int的模板引數N的類模板,並使用一個內部儲存的值來返回結果。如果我們 將這個類命名為Root,那麼它的一個用例如下:
int array[Root<10>::ret];
Root的程式碼如下:
template <size_t N, size_t Low = 1, size_t Upp = N> struct Root
{
static const size_t ret = Root<N, (down ? Low : mean + 1),
(down ? mean : Upp)>::ret;
static const size_t mean = (Low + Upp) / 2;
static const bool down = ((mean * mean) >= N);
};
在此我們不拘泥於細節,僅僅給出一些註解。(譯註4)模板類有三個引數,其中兩個有默 認值。在這三個引數中:
- 需要開方的數
- 預期平方根的上界和下界。預設值是1和N。平方根必然是介於1和N之間的某個數。
在這個例子中,返回值ret不是一個enum的值,而是一個靜態常數成員,用於引發遞迴例項 化。餘下的靜態資料成員mean和down僅僅作為輔助,以簡化遞迴例項化的編碼。
在什麼時候遞迴才能停止呢?遞迴的停止取決於一個特化的,不需要進一步進行模板例項 化的模板。如下是所需的偏特化的Root類:
template <size_t N, size_t Mid>
struct Root<N, Mid, Mid>
{
static const size_t ret = Mid;
};
這裡偏特化只有兩個模板引數。這是因為在遞迴結束的時候,上界和下界均已收斂到結果上了。
在我們的遞迴例子中,會產生如下例項化的模板:
Root<10, 1, 10>;
Root<10, 1, 5>;
Root<10, 4, 5>;
Root<10, 4, 4>;之後得到了4這個預期的結果。
從上述兩個例子可以看出,編譯時計算通常是通過遞迴例項化模板這一途徑進行的。遞迴 的函式為類模板所取代。函式的引數為已知型別的常數模板引數代替,而返回值則由類內 儲存的常數來表示。遞迴的終止通常由模板的特化來實現。有了上述的知識,Erwin Unruh 的質數計算程式將不再神祕,因為它無非是使用了與上述兩個例子相同的原理而已。
表示式模板
到此為止,我們已經能夠在編譯時進行數值計算(譯註5),然而這還不是本文的主題。下 面我們進行一項更巨集偉的計劃:在編譯時進行更加複雜的表示式計算。首先我們來實現一 個編譯時計算向量點乘的功能。點乘定義為兩個向量對應元素的積的和。例如:兩個三維 向量(1, 2, 3)和(4, 5, 6)的點乘等於1 * 4 + 2 * 5 + 3 * 6,也就是32。我們的目標是 使用表示式模板來計算任意維度向量的點乘,如下所示:int a[4] = {1, 100, 0, -1};
int b[4] = {2, 2, 2, 2};
cout << dot<4>(a, b) <<endl;點乘是表示式模板的一個最簡單的例子,不過在這裡使用的技術可以被擴充套件到高階矩陣的 數值計算上。對於矩陣來說,編譯時求值的技巧可以帶來比向量計算更加好的效能提升。
反覆用不同的引數代入相同函式求值的情況下,表示式模板可以起到有力的輔助作用。如 果使用這種技術,我們不再需要在執行時損失呼叫函式的時間,而是可以直接將函式在編 譯時嵌入到呼叫之中。例如在計算積分
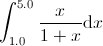
的時候。我們知道積分x / (1 + x)可以通過在積分割槽間中取n個等距離的點(這裡是 [1.0, 5.0])來近似計算。(譯註6)如果我們使用表示式模板來實現一個近似求解任意函 數積分的程式,那麼它的一個可能的樣子如下:
template <typename ExprT>
double integrate(ExprT e, double from, double to, size_t n)
{
double sum = 0;
double step = (to - from) / n;
for(double i = from + step / 2; i < to; i += step)
sum += e.eval(i);
return step * sum;
}
在這個例子裡,函式x / (1 + x)將被ExprT表示。我們在下文中可以看到這是如何實現的 。(譯註 7)
點乘(I)——表示式模板的第一個應用
為了方便讀者理解表示式模板的基本思想,我們在這裡採用經典設計模式來描述點乘和算 數表示式的實現。有關於設計模式方面的知識讀者可以參考Gamma等人編著的設計模式著作 (/GOF/)。向量的點乘可以看作是組合(composite)的一個特例。組合模式所表示的是部分——整體之間的關係:使用者可以忽略單個物件和組合物件之間的差 別。這裡的關鍵點在於葉結點和組合體。
- 葉結點定義組合體中個體物件的行為。
- 組合體定義葉結點集合的行為。
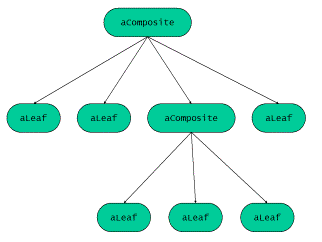
圖1:一個典型的組合體結構
著作GOF提出了一個採用虛基類實現的面向物件的組合體設計:定義葉結點和組合體共有的 操作,而葉結點和組合體均從一個基類派生出來。
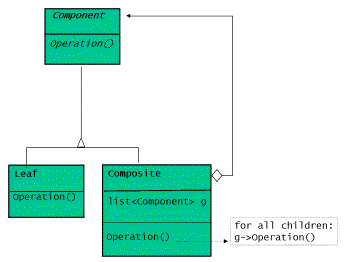
圖2:組合體設計模式的類圖
向量的點乘可以看作組合體設計模式的一個特例。點乘可以分成兩個部分:葉結點是一維 向量的積,而組合體是剩下N-1維向量的點乘。
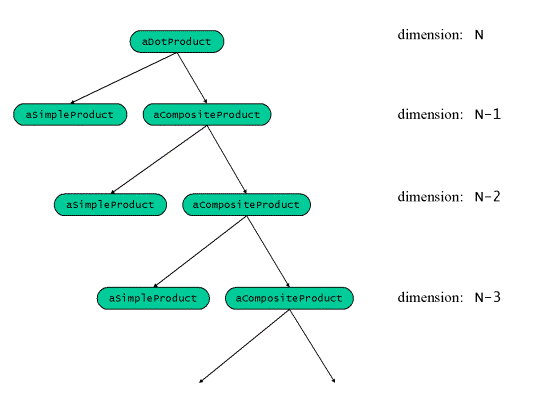
圖3:點乘的組合結構
顯而易見,這是組合體的某種簡併(degenerate)形式,每個組合體包含一個葉結點和一 個組合體。使用面向物件程式設計的技術,我們可以用一個基類和兩個派生類來表示點乘:
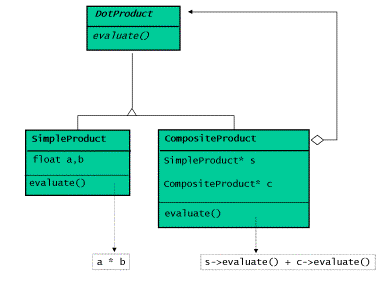
圖4:點乘的組合體的類圖
具體的編碼實現可以參考列表1-3的內容。列表4給出了一個方便使用的輔助函式,列表5是 一個具體的使用例子。
列表1:基類
template <typename T> class DotProduct
{
public:
virtual ~DotProduct () {}
virtual T eval() = 0;
};
列表2:組合體
template <typename T>
class CompositeDotProduct : public DotProduct<T>
{
public:
CompositeDotProduct (T* a, T* b, size_t dim) :
s(new SimpleDotProduct<T>(a, b)),
c((dim == 1) ? 0 : new CompositeDotProduct<T>(a + 1, b + 1, dim - 1))
{}
virtual ~CompositeDotProduct ()
{
delete c;
delete s;
}
virtual T eval()
{
return ( s->eval() + ((c) ? c->eval() : 0));
}
protected:
SimpleDotProduct<T>* s;
CompositeDotProduct<T>* c;
};
列表3:葉結點
template <typename T>
class SimpleDotProduct : public DotProduct<T>
{
public:
SimpleDotProduct (T* a, T* b) : v1(a), v2(b)
{}
virtual T eval()
{
return (*v1)*(*v2);
}
private:
T* v1;
T* v2;
};
列表4:輔助函式
template <typename T>
T dot(T* a, T* b, size_t dim)
{
return (dim == 1) ?
SimpleDotProduct<T>(a, b).eval() :
CompositeDotProduct<T>(a, b, dim).eval();
}
列表5:具體使用
int a[4] = {1, 100, 0, -1};
int b[4] = {2, 2, 2, 2};
cout << dot(a, b, 4);當然,這不是計算點乘的最有效途徑。我們可以通過在派生類中消去葉結點和組合體來簡化實現。這樣,不在建構函式裡傳遞且儲存需要計算的向量,以便之後的計算,而是直接將向量傳遞給求值函式。將建構函式和求值函式由
SimpleDotProduct<T>::SimpleDotProduct (T* a, T* b) : v1(a), v2(b)
{}
virtual T SimpleDotProduct<T>::eval()
{
return (*v1)*(*v2);
}
修改為一個帶引數的求值函式:
T SimpleDotProduct::eval(T* a, T* b, size_t dim)
{
return (*a)*(*b);
}
簡化的實現可以參考列表6中的程式碼:基類可以保持不變,但是輔助函式需要進行修改。
列表6:簡化的面向物件點乘程式碼
template <typename T>
class CompositeDotProduct : public DotProduct <T>
{
public:
virtual T eval(T* a, T* b, size_t dim)
{
return SimpleDotProduct<T>().eval(a,b,dim) + ((dim==1) ?
0 : CompositeDotProduct<T>().eval(a+1,b+1,dim-1));
} };
template <typename T>
class SimpleDotProduct : public DotProduct <T>
{
public:
virtual T eval(T* a, T* b, size_t dim)
{
return (*a)*(*b);
}
};
圖5表明了簡化模型對應的類圖
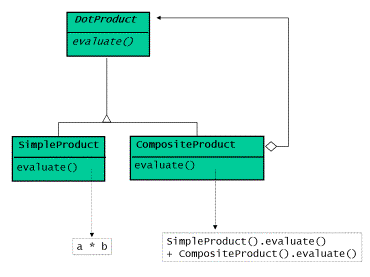
圖5:簡化的點乘模型的類圖
點乘(II)——編譯時計算
現在讓我們將面向物件的實現轉化成為編譯時計算的實現。葉結點和組合體對應的兩個類 共用了一個用來表示它們的共同操作的基類——這是面向物件程式設計的常用技巧:共同點用相 同的基類來表示。在模板程式設計中,共同點則是用命名的一致性來表現的。在面向物件程式設計 中的虛擬函式將不再為虛,而變為一個普通的,有著特定名稱的函式。兩個派生類不再是從 一個基類中派生的兩個類,而是變為獨立的,有著相同名稱和相通記號成員函式的兩個類 。也就是說,我們不再需要基類了。現在我們來通過在模板的引數中儲存結構資訊的方式來實現組合體。我們需要儲存的結構 資訊是這個向量的維度。回憶一下之前我們計算階乘和平方根的程式碼:函式實現中函式的 引數變為了編譯時處理的模板引數。我們在這裡也採用相同的手法,原來在面向物件實現 中傳遞給求值函式的向量的維度,在這裡變為編譯時確定的模板引數。因此在組合體中, 這個維度資料將變為模板中的一個常量引數。
葉結點則需要通過組合體類在一維情況下的模板特化類來實現。正如以往一樣,我們將運 行時的遞迴轉變為編譯時的遞迴:將對求值虛擬函式的遞迴呼叫轉變為模板類在遞迴例項化 的過程中對一個靜態的求值函式的遞迴呼叫。如下是編譯時計算點乘程式碼的類圖:
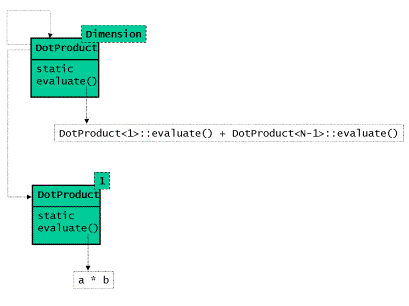
圖6:編譯時計算點乘的類圖
具體實現程式碼在列表7中供參考。使用的例子可以參見列表8。
列表7:編譯時點乘的實現
template <size_t N, typename T>
class DotProduct
{
public:
static T eval(T* a, T* b)
{
return DotProduct<1,T>::eval(a,b) + DotProduct<N-1,T>::eval(a+1,b+1);
}
};
template <typename T>
class DotProduct<1,T>
{
public:
static T eval(T* a, T* b)
{
return (*a)*(*b);
}
};
列表8:列表7中程式碼的使用例子
template <size_t N, typename T>
inline T dot(T* a, T* b)
{
return DotProduct<N,T>::eval(a, b);
}
int a[4] = {1, 100, 0, -1};
int b[4] = {2, 2, 2, 2};
cout << dot<4>(a,b);
注意到在執行時計算中,點乘函式的呼叫方法是dot(a, b, 4),而編譯時計算中,點乘函 數的呼叫方法是dot<4>(a, b):
- dot(a, b, 4)等價於CompositeDotProduct<int>().eval(a, b, 4),遞迴式的引發如下函式在執行時的呼叫:
SimpleDotProduct<int>().eval(a, b, 1);
CompositeDotProduct<int>().eval(a + 1, b + 1, 3);
SimpleDotProduct<int>().eval(a + 1, b + 1, 1);
CompositeDotProduct<int>().eval(a + 2, b + 2, 2);
SimpleDotProduct<int>().eval(a + 2, b + 2, 1);
CompositeDotProduct<int>().eval(a + 3, b + 3, 1);
SimpleDotProduct<int>().eval(a + 3, b + 3, 1);
總共進行7次虛擬函式的呼叫。
- dot<4>(a, b)通過計算DotProduct<4, int>::eval(a, b),從而遞迴式的引發下列模板依次例項化展開:
DotProduct<4, size_t>::eval(a, b);
DotProduct<1, size_t>::eval(a, b) + DotProduct<3, size_t>::eval(a + 1, b + 1);
(*a) * (*b) + DotProduct<1, size_t>::eval(a + 1, b + 1) + DotProduct<2, size_t>::eval(a + 2, b + 2);
(*a) * (*b) + (*a + 1) * (*b + 1) + DotProduct<1, size_t>::eval(a + 2, b + 2) + DotProduct<1, size_t>::eval(a + 3, b + 3);
(*a) * (*b) + (*a + 1) * (*b + 1) + (*a + 2) * (*b + 2) + (*a + 3) * (*b + 3)在可執行檔案中,只會有(*a) * (*b) + (*a + 1) * (*b + 1) + (*a + 2) * (*b + 2) + (*a + 3) * (*b + 3)對應的程式碼;具體的展開過程是在編譯時完成的。
很明顯,模板程式設計提升了執行時的計算效能,但是代價是延長了編譯的時間。遞迴的模板 例項化展開所造成的編譯時間延長是以數量級形式進行的。而面向物件的程式碼雖然編譯時 間短,卻花費了更多的執行時間。
編譯時計算的另一個侷限性在於,向量的維度必須在編譯時就已知,因為這個值需要通過 模板引數來傳遞。實際上這反而不是太大的問題,因為通常這個值在編碼的時候的確是已 知的,例如,我們如果要計算空間中的向量,那麼向量的維度顯然是3。
點乘的程式碼未必能給讀者留下深刻印象,因為事實上我們只需要手工展開乘法,就能帶來 和模板程式設計帶來的相同的效能提升。然而這裡所提及的技術並不僅僅侷限於點乘,而是可 以擴充套件到高階矩陣的算術計算上去。這樣的編碼將大大簡化程式設計的複雜性。如果定義a為 10x20的矩陣,b為20x10的矩陣,而c為10x10的矩陣(譯註8),那麼使用a * b + c來表達 計算將顯得非常簡潔明瞭。程式設計師顯然寧願讓編譯器自動的,同時也是可靠的處理這個問 題,而不願意手工展開如此高階的矩陣。
算術表示式——表示式模板的另一個應用
讓我們通過一個更加現實的組合體來進一步研究這種程式設計技術。算術表示式是由一元和二 元的算術運算子,以及變數和常量這些元素組成的。GOF這本書中採用直譯器( Interpreter)模式來應對這種情況。直譯器模式採用一個抽象語法樹來描述算術表示式語言,同時用一個直譯器來處理這個語 法樹。這是組合體的一個特例。組合體中“部分-整體”的關係與直譯器中子表示式和表示式 之間的關係相互照應。
- 葉結點是一個終點表示式(terminal expression)。
- 組合體是一個非終點表示式(nonterminal expression)。
- 通過解釋表示式樹和其中包含的表示式來進行求值。
形如(a + 1) * c或者log(abs(x - N))的算術表示式將由語法樹來實現。共有兩種終點表 達式:常數(literial)與數值變數(variable)。常數對應的是已知的數值,而數值變 量則可能在每次求值時取不同的值。非終點表示式則由一元或者二元運算子組成,每個非 終點表示式可能包含一到兩個終點表示式。表示式中可能有各種不同語義的運算子,比如+ ,-,*,/,++,--,exp,log,sqrt等等。
我們通過(x + 2) * 3這個具體例項來分析。組合體的結構,也就是語法樹的結構,如下圖所示:
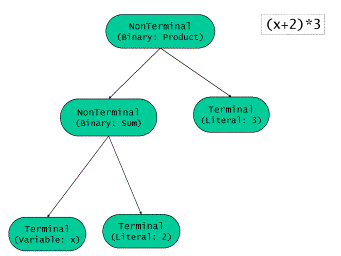
圖7:算術表示式的語法樹的例子
在GOG中,直譯器的經典的面向物件設計如下類圖所示:
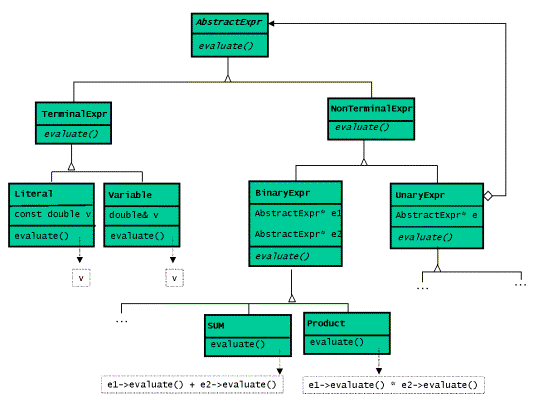
圖8:面向物件方式實現的算術表示式的直譯器的類圖
與之相關的程式碼實現可以參見列表9.UnaryExpr的基類與BinaryExpr的類相似,所有的一元 和二元運算均和類Sum相似。
列表9:面向物件方式下的算術表示式的直譯器
class AbstractExpr
{
public:
virtual double eval() const = 0; };
class TerminalExpr : public AbstractExpr
{ };
class NonTerminalExpr : public AbstractExpr
{ };
class Literal : public TerminalExpr
{
public:
Literal(double v) : _val(v)
{}
double eval() const
{
return _val;
}
private:
const double _val;
};
class Variable : public TerminalExpr
{
public:
Variable(double& v) : _val(v)
{}
double eval() const
{
return _val;
}
private:
double& _val;
};
class BinaryExpr : public NonTerminalExpr
{
protected:
BinaryExpr(const AbstractExpr* e1, const AbstractExpr* e2) : _expr1(e1),_expr2(e2)
{}
virtual ~BinaryExpr ()
{
delete const_cast<AbstractExpr*>(_expr1);
delete const_cast<AbstractExpr*>(_expr2);
}
const AbstractExpr* _expr1;
const AbstractExpr* _expr2;
};
class Sum : public BinaryExpr
{
public:
Sum(const AbstractExpr* e1, const AbstractExpr* e2) : BinExpr(e1,e2)
{}
double eval() const
{
return _expr1->eval() + _expr2->eval();
}
};
//...
列表10中則表明瞭解釋器是如何解析算術表示式(x + 2) * 3的:
列表10:使用直譯器來處理算術表示式
void someFunction(double x)
{
Product expr(new Sum(new Variable(x), new Literal(2)), new Literal(3));
cout << expr.eval() <<endl;
}
在這裡,首先創造了一個表示式物件,用以表示(x + 2) * 3。之後該物件對自身進行求值 。自然而然的,我們覺得這是一個極其低效的計算方法。現在我們將它轉化為表示式模板 。
正如之前點乘的例子中所示,我們首先要消除所有的虛基類。因為模板類中沒有繼承,取 而代之的是相同的成員名稱。因此,我們不再使用基類,而將所有的終點表示式和非終點 表示式都用單獨的類來表示,它們共有一個相同的名為eval的函式。
下一步,我們將通過類模板UnaryExpr和BinaryExpr來生成所有的形如Sum和Product的非終 點表示式。這裡結構資訊將全部儲存在類模板的引數中。這些類模板將其子表示式的型別 作為其型別模板。另外,我們將具體的運算子操作抽象為類模板中一個型別,通過仿函式 物件傳遞。
實現,與面向物件實現沒有很大的差別。
同樣的,執行時遞迴將由編譯時遞迴所代替:我們將虛的求值函式的遞迴呼叫改為表示式 模板的遞迴例項化。
圖9是基於模板實現表示式求值問題的類圖:
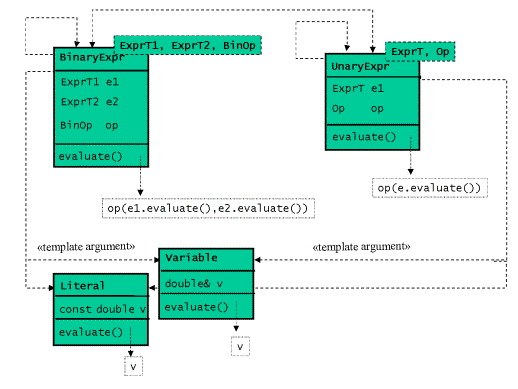
圖9:基於模板實現的表示式求值直譯器的類圖
原始碼請參考列表11:
列表11:基於模板的算術表示式直譯器
class Literal
{
public:
Literal(const double v) : _val(v)
{}
double eval() const
{
return _val;
}
private:
const double _val;
};
class Variable
{
public:
Variable(double& v) : _val(v)
{}
double eval() const
{
return _val;
}
private:
double& _val;
};
template <typename ExprT1, typename ExprT2, typename BinOp>
class BinaryExpr
{
public:
BinaryExpr(ExprT1 e1, ExprT2 e2,BinOp op=BinOp()) :
_expr1(e1),_expr2(e2),_op(op)
{}
double eval() const
{
return _op(_expr1.eval(),_expr2.eval());
}
private:
ExprT1 _expr1;
ExprT2 _expr2;
BinOp _op;
};
//...
UnaryExpr的類模板與BinaryExpr的類模板相似。對於實際操作,我們可以使用已經編寫好 的STL的仿函式類plus,minus,等等,或者我們也可以自行編寫。一個用來表示和的二元 表示式的型別是BinaryExpr<ExprT1, ExprT2, std::plus<double>>。(譯註9)這樣的類 型使用起來較為複雜,因此我們寫一個產生函式,方便以後的使用。
我們將用產生函式來簡化表示式物件的生成。列表12給出了產生函式的兩個例子:產生函式
產生函式是在模板程式設計中廣泛使用的一種技巧。在STL中有大量的產生函式,例如 make_pair()。產生函式的優勢在於,可以利用編譯器對函式模板引數的自動推導來簡化 程式設計,而對類模板,編譯器是無法進行自動推導的。
每次我們從一個類模板中建立一個物件的時候,我們需要給出完整的類模板引數的例項化資訊。在很多情況下,這些資訊非常複雜,難於理解。例如包含pair的pair: pair<pair<string, complex<double>>, pair<string, complex<double>>>。產生函式可以簡化這個問題:它將生成給定型別的物件,而無需我們寫出冗長的型別宣告資訊。
更準確的說,產生函式是一類函式模板。這種函式模板與它生成的物件對應的模板類有著相同的模板引數。以pair為例,pair類模板有兩個型別引數T1和T2,表示它所包含的兩個 元素的型別,而make_pair()產生函式同樣包含這兩個型別引數:template <typename T1, typename T2> class pair { public: pair(T1 t1, T2 t2); // ... }; template <typename T1, typename T2> pair<T1,T2> make_pair(t1 t1, T2 t2) { return pair<T1,T2>(t1, t2); }
產生函式與建構函式非常相似:我們傳遞給產生函式的引數和我們傳遞給建構函式的 引數是一樣的。因為編譯器能夠自動推導函式模板中模板引數所表示的型別,我們可以借 此省去這個宣告,而把這一繁重的工作交給編譯器來進行。因此,我們不用通過pair< pair<string,complex<double>>, pair<string,complex<double>>>( pair<string,complex<double> >("origin", complex<double>(0,0)), pair<string,complex<double> >("saddle", aCalculation()))
來宣告一個複雜的pair,而通過產生函式進行:make_pair(make_pair("origin", complex<double>(0,0)), make_pair("saddle", aCalculation()))
列表12:表示式物件的產生函式
template <typename ExprT1, typename ExprT2>
BinaryExpr<ExprT1,ExprT2,plus<double>> makeSum(ExprT1 e1, ExprT2 e2)
{
return BinaryExpr<ExprT1,ExprT2,plus<double> >(e1,e2);
}
template <typename ExprT1, typename ExprT2>
BinaryExpr <ExprT1,ExprT2,multiplies<double>> makeProd(ExprT1 e1, ExprT2 e2)
{
return BinaryExpr<ExprT1,ExprT2,multiplies<double> >(e1,e2);
}
列表13給出了基於模板實現的直譯器解析(x + 2) * 3的方式:
列表13:使用基於模板元的直譯器求解算術表示式
void someFunction (double x)
{
BinaryExpr< BinaryExpr < Variable, Literal, plus<double> >, multiplies<double>>
expr = makeProd (makeSum (Variable(x), Literal(2)), Literal(3));
cout << expr.eval() << endl;
}
首先生成了一個代表(x + 2) * 3的表示式物件,然後這個物件對自身進行求值。表示式對 象的結構本身即是語法樹的結構。
我們其實完全不必給出如此冗長的型別資訊,而是可以直接使用產生函式來自動生成,如 下所示:
cout << makeProd(makeSum(Variable(x),Literal(2)),Literal(3)).eval() << endl;
通過模板來實現直譯器這個設計模式的優越性是什麼呢?倘若所有的產生函式,建構函式 和求值函式都能被編譯器內聯的話(這應該是可以辦到的,因為這些函式本身都很簡單) ,表示式makeProd(makeSum(Variable(x),Literal(2)),Literal(3)).eval()最終將被編 譯器轉化為(x + 2) * 3進行編譯。
回過頭來看列表10中的程式碼
Product expr(new Sum(new Variable(x),new Literal(2)), new Literal(3)).eval()僅僅這一小段中就包含了大量的堆上的記憶體申請和物件構造,同時也引入了不少對虛擬函式 eval()的呼叫。這些虛擬函式呼叫很難被內聯,因為編譯器一般不會內聯通過指標呼叫的函 數。(譯註10)
可見,基於模板的實現將比面向物件的實現效率高上許多。
表示式模板的進一步應用
為了使用上的方便,我們進一步的修改表示式模板。首先要考慮的是增加可讀性。我們希 望的是如下的語句makeProd(makeSum(Variable(x), Literal(2)), Literal(3)).eval() 可以更像是它所表示的表示式(x + 2) * 3。只要稍稍修改程式碼,並且使用運算子過載,我 們就可以把它變為eval((v + 2) * 3.0)。
首先我們要將產生函式修改為過載的運算子。也就是說,將makeSum改為operator+,將 makeProd改為operator*,等等。這樣產生的效果就是將
makeProd(makeSum(Variable(x), Literal(2)), Literal(3))轉化為
((Variable(x) + Literal(2)) * Literal(3))這已經是一大進步了。但是距離我們所希望的直接寫(x + 2) * 3還有一定差距。因此我們 需要設法消除Variable和Literal的建構函式的直接呼叫。
為了解決這個問題我們首先考察形如x + 2的表示式的意義。我們將產生函式從makeSum改 為operator+。這個函式的具體程式碼參見列表14:
列表14:operator+過載形式下的產生函式
template <typename ExprT1, typename ExprT2>
BinaryExpr<ExprT1, ExprT2, plus<double>> operator+(ExprT1 e1, ExprT2 e2)
{
return BinaryExpr<ExprT1, ExprT2, plus<double>>(e1,e2);
}
我們希望x + 2可以和之前的makeSum(x, 2),如今的operator+(x, 2)相對應。x + 2應當 創造一個代表求和的二元表示式物件,而這個物件的建構函式將以double型別的變數x以及 整形常量2作為構造引數。更準確的說,這將生成一個BinaryExpr<double, int,
plus<double>>(x, 2)的匿名物件。然而我們所期望的型別並非如此:需要的是BinaryExpr <Variable, Literal, plus<double>>型別的物件。可是,自動模板引數型別推導並不知道x是一個變數,而2是一個常量。編譯器只能檢查傳遞給函式的引數型別,從而從x中推匯出double型別,從2中推匯出int型別。
看起來我們需要稍稍給編譯器一些更多的資訊,從而得到我們所需要的結果。如果我們給函式傳遞的不是double型別的x,而是一個Variable型別的引數,那麼編譯器應該能夠自動產生BinaryExpr<Variable, int, plus<double>>,這將更接近我們的目標。(我們將很快解決int到Literal的轉換問題)因此,使用者不得不對程式碼做一些小小的改動:他們需要用Variable類來包裝他們的變數。如列表15所示:
列表15:使用基於模板的直譯器來進行算術表示式計算
void someFunction (double x)
{
Variable v = x;
cout << ((v + 2) * 3).eval() << endl;
}通過使用Variable物件v來代替一個數值型別的引數,我們可以將v + 2轉化為一個等價於BinaryExpr<Variable, int, plus<double>>(v, 2)的匿名物件。這樣的BinaryExpr物件有兩個資料成員,一個是Variable,一個是int。求值函式BinaryExpr<Variable, int, plus<double>>::eval()將計算並且返回兩個資料成員的和。問題是,int型別的資料無法自行轉化為可以自動求值的物件,我們必須將常數2轉化為Literal型別,才能進行自動求值。如何做到這種自動轉化呢?我們需要使用traits。
Traits *TRAITS*
在模板程式設計中,traits是另一種常用的技術。traits類是一種只與另外一種型別配合,儲存這種型別的具體資訊的影子類(shadow class)。
C++ STL中有多個traits的例子,字元traits就是其中之一。讀者大約知道標準庫中的string類其實是一個類模板,這個類模板的引數是具體的字元型別。這就使得string可以處理普通的字元和寬字元。實際上,string類的實際名稱是basic_string。basic_string可以通過例項化來接受任何型別的字元,而不僅僅是上述提及的兩種。倘若有人需要儲存以Jchar定義的日文字元,那麼他就可以用basic_string模板實現:basic_string<Jchar>。
讀者可以自己設想如何設計這樣的string類模板。有一些必須的資訊並不能由字元的型別本身所提供。例如,如何計算字串的長度?這可以通過數一下字串裡的所有字元個數來實現。這樣就需要知道字串的結束記號是什麼。但是如何知道這一點呢?雖然我們知道對於一般的字元,'\0'是結束符;寬字元wchar_t有它自己定義的結束符,但是對於Jchar呢?很明顯,結束符這個資訊與字元的型別直接相關,但是卻不包括在型別本身所能提供的資訊之中。這時traits就派上了用場:它們可以提供這些額外的,卻是必須的資訊。
traits型別是一種可以被具體的一組型別例項化或者特化的影子(shadow)類模板,在例項化或者特化的時候,它們包含了額外的資訊。C++標準庫中字元的traits,即是char_traits類模板,就包含了一個靜態的字元常量,用以表示這種字元對應的字串結束符的值。
我們使用traits技術來解決常數到Literal型別的轉換問題。對於每一種表示式的型別,我們定義表示式的traits用以儲存它們在各種運算子物件中的儲存方式。所有的常數型別都應該以Literal型別的物件儲存;所有的Variable物件都應該以本身的型別儲存在Variables之中;而所有的非終端表示式都應該按照本身型別儲存。列表16給出了traits的編碼:
列表16:表示式traits
template <typename ExprT>
struct exprTraits
{
typedef ExprT expr_type;
};
template <>
struct exprTraits<double>
{
typedef Literal expr_type;
};
template <>
struct exprTraits<int>
{
typedef Literal expr_type;
};
//...
表示式traits類定義了一個巢狀型別expr_type,代表表示式物件的具體型別。未特化的traits模板類將所有常用的表示式型別儲存為其本身。但是對於C++語言內建的數值型別,例如short,int,long,float,double等則進行了特化,它們在表示式中對應的型別均為Literal。
在BinaryExpr和UnaryExpr類中,我們將使用表示式traits來確認存有子表示式的資料成員的型別。
列表17:使用表示式traits
template <typename ExprT1, typename ExprT2, typename BinOp>
class BinaryExpr
{
public:
BinaryExpr(ExprT1 e1, ExprT2 e2,BinOp op=BinOp()) :
_expr1(e1), _expr2(e2), _op(op)
{}
double eval() const
{
return _op(_expr1.eval(),_expr2.eval());
}
private:
exprTraits<ExprT1>::expr_type _expr1;
exprTraits<ExprT2>::expr_type _expr2;
BinOp _op;
};
通過使用表示式traits,BinaryExpr<Variable, int, plus<double>>可以將它的兩個運算元的型別分別儲存為Variable和Literal。這正是吾等草民所期望的。
現在我們已經可以使用((v + 2) * 3).eval()來進行求值了。在這裡v是一個Variable型別,其中封裝了一個double型別的物件x。這樣,實際上的求值就是(x + 2) * 3了。我們可以為可讀性著想,稍稍再做進一步的改進。人們通常覺得呼叫表示式的一個成員函式進行求值看上去很古怪。不過我們可以設計一個輔助函式,將((v + 2) * 3).eval()變為eval((v + 2) * 3)。這兩段程式碼雖然事實上是等價的,但是卻更符合諸君的閱讀習慣。列表18給出了這個輔助函式:
列表18:eval()輔助函式
template <class ExprT> double eval(ExprT e)
{
return e.eval();
}圖10給出了表示式((v + 2) * 3).eval()在v作為Variable封裝了一個double型別的x的情況下,在編譯過程中是如何逐步的展開為(x + 2) * 3的。
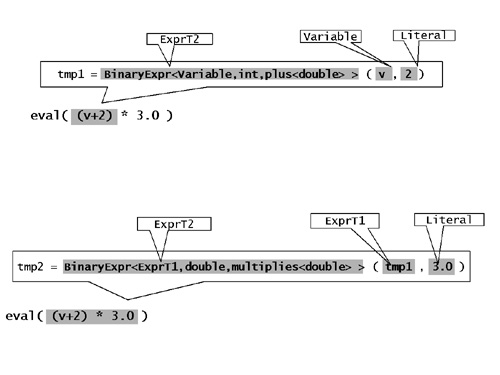
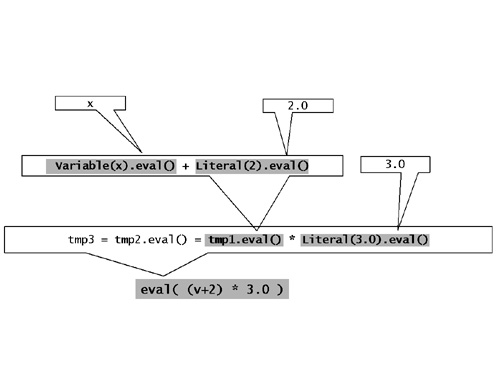
圖10:編譯時對錶達式物件(v + 2) * 3的計算
表示式物件的反覆計算
讀者可能仍然在考慮表示式物件的優勢在何處。每個表示式物件代表了一個算術表示式的分解,從而形成了一個語法樹,而這個語法樹又能夠自動求值。簡而言之,我們創造了一個機械式的表示式求值途徑——雖然這個途徑C++語言本身就支援。那麼這麼做到底有何好處呢?下面我們來考察這一點。迄今為止,我們所用到的語法樹都是靜態的。每個語法樹在構造之後,只被呼叫一次。然而我們可以通過給定一個語法樹,並傳入不同的引數值,來動態的使用這個模型。如上文所述,我們希望能夠用如下的近似函式:
template <class ExprT>
double integrate (ExprT e,double from,double to,size_t n)
{
double sum = 0;
double step = (to - from) / n;
for (double i = from + step / 2; i < to; i += step)
sum += e.eval(i);
return step * sum;
}
計算類似下面的積分式:
為此我們可以用下面的例子給出的方式來呼叫這個函式:
Identity<double> x;
cout << integrate(x / (1.0 + x), 1.0, 5.0, 10) << endl;這裡我們需要的是一個被反覆呼叫的表示式物件,然而我們現有的程式碼尚不支援這樣的操作。不過一些小小的修改即可滿足我們的要求。只要讓我們的eval函式接受一個值作為引數即可。非終端的表示式將把引數傳遞給它們的子表示式。Literal類只需要形式上的接受這個引數即可,它們的值不受這個引數所影響。Variable將不再返回Variable的值,而是它所接受到的這個引數的值。出於這個目的,我們把Variable改名為Identity。列表19給出了修改過的類。
列表19:可重複計算的表示式模板
class Literal
{
public:
Literal(double v) : _val(v)
{}
double eval(double) const
{
return _val;
}
private:
const double _val;
};
template<class T> class Identity
{
public:
T eval(T d) const
{
return d;
}
};
template <class ExprT1,class ExprT2, class BinOp> class BinExpr
{
public:
double eval(double d) const
{
return _op(_expr1.eval(d),_expr2.eval(d));
}
};
//...
如果編寫sqrt(),sqr(),exp(),log()等等數值函式的非終點表示式程式碼,我們甚至可以計算高斯分佈:
列表20:計算高斯分佈
double sigma = 2.0;
double mean = 5.0;
const double Pi = 3.141593;
cout << integrate(
1.0 / (sqrt(2 * Pi) * sigma) * exp(sqr(x - mean) / (-2 * sigma * sigma)),
2.0, 10.0, 100) << endl;
我們可以通過呼叫C標準庫裡的相應函式來實現這些非終點表示式,只要增加相應的一元或者二元運算子的產生函式即可。列表21給出了一些例子:
列表21:數值函式的非終點表示式表示
template <typename ExprT>
UnaryExpr<ExprT, double(*)(double)> sqrt(const ExprT& e)
{
return UnaryExpr<ExprT, double(*)(double)>(e, ::std::sqrt);
}
template <typename ExprT>
UnaryExpr<ExprT, double(*)(double)> exp(const ExprT& e)
{
return UnaryExpr<ExprT,double(*)(double)>(e,::std::exp);
}
// ...
通過這些修改,我們得到了一個有力的高效能數值表示式計算庫。利用本文所述的技術,不難為這個庫增添邏輯計算的功能。如果將求值函式eval()改為括號算符的過載operator()(),我們可以很容易的將表示式物件轉換為仿函式物件,這樣就可以應用在STL的演算法庫中。下面是一個將邏輯表示式應用於計算連結串列中符合條件的元素個數的例子:
list<int> l;
Identity<int> x;
count_if(l.begin(), l.end(), x >= 10 && x <= 100);一旦編寫好相應的表示式模板,就可以如上述例子所示一般,令程式碼兼具高度可讀性和高效的執行時表現。建立這樣的表示式模板庫則相當複雜,需要使用本文尚未提及的許多模板程式設計技巧。但是無論如何,本文中涉及的程式設計原理已經覆蓋了所有的模板庫。
參考文獻
已經有很多成熟的表示式模板庫供讀者下載。下文中僅僅提及了一部分。不過這些模板庫程式並不一定具有較好的可讀性或者代表性。如果讀者希望獲取更多資料,作者推薦讀者訪問下面的資料(參見/JUL/和/OON/)。|
/GOF/ |
Design Patterns: Elements of Reusable Object-Oriented Software |
|
/VAN/ |
C++ Templates – The Complete Guide |
|
/DUR/ |
Design Patterns for Generic Programming in C++ |
|
/VEL/ |
T. Veldhuizen, "Expression Templates," C++ Report,Vol. 7 No. 5 June 1995, pp. 26-31 |
|
/JÜL/ |
Research Centre Jülich |
|
/OON/ |
The Object-Oriented Numerics Page |
|
/BLI/ |
The Blitz Project |
|
/PET/ |
PETE (Portable Expression Template Engine) |
|
/POO/ |
POOMA (Parallel Object-Oriented Methods and Applications) |
|
/MET/ |
MET (Matrix Expression Templates) |
|
/MTL/ |
MTL (Matrix Template Library) |
|
/FAC/ |
FACT! (Functional Additions to C++ through Templates andClasses) |
|
/FCP/ |
FC++ (Functional Programming in C++) |
|
/BLL/ |
BLL (The Boost Lambda Library) |
|
/PHO/ |
Phoenix (A parser used by
Spirit) |
作者感謝在C++ UsersJ 閱讀了我們文章的Gary Powell。他的郵件中提及了我們之前沒有注意到的FACT!,FC++,Boost Lambda Library,以及Phoenix程式庫。
譯註:
譯註1:參見《The Design and Evolution of C++》。
譯註2:階乘在數學上可以用Gamma函式定義。
譯註3:C99是允許變長陣列的,但是即便是最新的C++11標準也不支援變長陣列。
譯註4:這其實是使用二分法搜尋平方根。作為一個優化,預設的Upp可以定為N的一半甚至 更少。
譯註5:編譯時數值計算是有相當侷限性的,例如浮點數的計算就無法執行,這是因為浮點 數計算是和機器/編譯器實現直接相關的。
譯註6:參見Riemann積分定義。
譯註7:C++11的Lambda語法可能大大減少此類技巧的使用。
譯註8:原文中a,b,c均為20x10的矩陣,明顯有誤,這裡更改為一個合理的值。
譯註9:原文中>和>之間有一個多餘的空格,這是C++03標準的要求。在C++11中這個空格可 以去掉。
譯註10:虛擬函式是通過查詢虛表進行的呼叫的,因此編譯時很難確認具體哪個函式會被調 用,然而現在也有編譯器可以在一定程度上預測呼叫的具體函式,參見g++的引數 -fdevirtualize。
相關推薦
C++語言的表示式模板:表示式模板的入門性介紹
時至今日,我仍然能清晰的記起我的同事Erwin Unruh在一次C++標準委員會會議時展 示的得意之作。這是一段並不能通過編譯的程式碼,但是它卻給出了質數數列。(參見:UNR )編譯它的過程中產生的錯誤資訊中依次包含了每一個給定範圍內的質數。當然,不能夠 通過編譯的程式是毫無意義的,然而這段程式碼是有意這樣的
C語言程式設計入門之--第五章C語言基本運算和表示式-part1
導讀:程式要完成高階功能,首先要能夠做到基本的加減乘除。本章從程式中變數的概念開始,結合之前學的輸出函式和新介紹的輸入函式製作簡單人機互動程式,然後講解最基礎的加減法運算,自制簡單計算器程式練手。 5.1 變數 5.1.1 變數宣告定義與賦值表示式 上一章講了資料型別,資料型別要和變數結合在一起
C語言程式設計入門之--第五章C語言基本運算和表示式-part2
5.1.4 再來一個C庫函式getchar吸收回車鍵 回車鍵也是一個字元,在使用scanf的時候,輸入完畢要按下回車鍵,這時候回車鍵也會被輸入到stdin流中,會搞亂我們的程式。 注意:stdin是輸入流,stdout是輸出流,這兩個流就是在記憶體中流進流出的資料,根據流向不同命名也不同。 比如以
C語言程式設計入門之--第五章C語言基本運算和表示式-part3
5.3 挑幾個運算子來講 常用的運算子除了加減乘除(+-*/)外,還有如下: 注意:以下運算子之間用逗號隔開,C語言中也有逗號運算子,這裡不講逗號運算子。 1. 賦值運算子 =,+=,*= 2. 一元運算子 +
C語言程式設計-1199-計算表示式
Problem Description 計算下列表達式值: Input 輸入x和n的值,其中x為非負實數,n為正整數。 Output 輸出f(x,n),保留2位小數。 Sample Input 3 2 Sample Output 2.00 看到題目是一臉懵逼的,看了下別人的程式碼,原文
《我的第①本c語言程式設計書:C語言從入門到精通》掃描版.pdf
書籍簡介: 《C語言從入門到精通》以零基礎講解為宗旨,用例項引導讀者深入學習,採取“基礎知識→核心技術→趣味題解→專案實戰”的講解模式,深入淺出地講解C語言的各項技術及實戰技能。《C語言從入門到精通》第1篇【基礎知識】主要講解步入C的世界、常量與變數、資料型別、運算子和表示式、程式控制結構
資料結構之---C語言實現棧的表示式求值(表示式樹)
利用棧實現表示式樹這裡我一共有兩種思路: part one: 首先判斷輸入表示式的每個字元,如果遇到運算子,不壓棧, 接著彈出兩個棧頂的元素,進行元素,接著把結果壓棧。 程式碼: //棧實現表示式 //思路:此程式的思路是,讀取輸入的字串,然後判斷每個字元, //當遇到
Linux C/C++ 模板:類模板成員特化
一、程式碼 不需要完全特化整個類,只特化相關函式即可。 #include <iostream> #include <cstring> #include <vector> #include <algorithm>
C語言實現計算器 ---- 字尾表示式
對於平時我們書寫的算術表示式是 12 * ( 3 + 4 ) - 6 + 8 / 2 這種習慣的寫法是中綴表示式 但是計算機一般執行方式是字尾表示式,從左向右依次執行 12 3 4 + * 6 - 8 2 / + 這就是字尾表示式
c語言模擬實現棧的模板化
對於寫過表示式解析的同學一定不會陌生,我們需要兩個棧,一個是符號棧(char),一個是運算元棧(int). 經典的資料結構書中的棧,型別是定死了的。所以能夠實現一個棧,自己指定型別,想必編寫接下來程式碼的心情要愉快的多。本實現過程採用巨集定義,這樣然介面看來
C++11 條款1:理解模板型別推導
前言 c++98有單獨一套型別推導規則:適用於函式模板。c++11修改了這套規則並且增加了兩個,一個是auto,一個是decltype。c++14擴充套件了auto和decltype使用的場景。隨著型別推導在應用程式中的使用逐步增加,你可以從那些明顯或冗餘的型別拼寫中
C語言實現整數四則運算表示式的計算
一、問題重述 【問題描述】 從標準輸入中讀入一個整數算術運算表示式,如5 - 1 * 2 * 3 + 12 / 2 / 2 = 。計算表示式結果,並輸出。 要求: 1、表示式運算子只有+、-、*、/,表示式末尾的’=’字元表示表示式輸入結束,表示式中可能會出現空格; 2、
T4模板:T4模板之基礎篇
教程 添加 介紹 9.png 輸出 com 明顯 gin ecif 一、回顧 上一篇文章 ——T4模板之菜菜鳥篇,我們囫圇吞棗的創建了與“T4模板”有關的文件。在創建各個文件的這一個過程中,我們對於T4模板有了那麽丁點的認識。現在就帶著之前的那些問題,正式的邁入對“T4模板
嵌入式C語言難點一:數組
數組 位置 scanf 列表 輸出結果 clu sort 難點 can 1.數組的定義 由若幹相同類型並且有順序關系的數組組成,數組中的每個變量就叫做這個數組的元素。 表達式:<儲存類型> <數據類型> <數組名> [<常量
C語言復習:內存模型2
com 一個 函數調用模型 ++ white hit 運行 技術分享 空間 函數調用模型 基本原理 實際上就是不斷的從一個內存跳到另一個內存。 函數調用變量傳遞分析 一個主程序有n函數組成,c++編譯器會建立有幾個堆區?有幾個棧區? 答:一個程序只有一個堆區
C語言復習:文件操作
end 文件 don 表示 creat 比較 部分 name conf 文件操作專題 C語言文件讀寫概念 文件分類 按文件的邏輯結構: 記錄文件:由具有一定結構的記錄組成(定長和不定長) 流式文件:由一個個字符(字節)數據順序組成 按存儲介質: 普通文件:存儲介質文件
C語言加密練習:第一個字母變成第26個字母,第i個字母變成第(26-i+1)個字母。非字母字符不變。要求編程序將密碼譯回原文,並輸出密碼和原文。
c語言 http () spa mage strlen str png for 1 int Afan(char a); 2 3 int main() 4 5 { 6 7 char arr[40] = {"aABX"}; 8 9 scanf("%s
三十二、python學習之Flask框架(四)模板:jinja2模板、過濾器、模板複用(繼承、巨集、包含)、瞭解CSRF跨站請求攻擊
一、jinja2模板引擎的簡介: 1.模板: 1.1檢視函式的兩個作用: 處理業務邏輯; 返回響應內容; 1.3 什麼是模板: 模板其實是一個包含響應文字的檔案,不是特指的html檔案,其中用佔位符(變數)表示動態部分,告訴模板引擎其具體的
C語言函式庫:動態連結庫與靜態連結庫
首先,函式庫就是一些事先寫好的函式的集合,是別人分享的,我們可以拿來使用的。經過一些校準和整理,就形成一份標準化的函式庫。例如glibc 函式庫有兩種提供形式:動態連結庫與靜態連結庫 早起函式庫裡的函式都是直接共享的,就是所謂的開源社群。後來函式庫商業化,就出現了靜態連結庫與動態連結庫。
Mr.J--C語言學習Errors:LNK2019
每日日常敲程式碼,日常看bug,錯誤提示: 這個錯誤提示第一次見到,心裡表示很難受於是乎google一下: 可以在Linker Tools Error LNK2019中找到該主題的最新版本。 函式'functi