
Hbase與傳統資料庫的區別
其實說白了,這些就是事先沒有認清楚網際網路應用什麼才是最重要的。從系統架構的角度來說,網際網路應用更加看重系統性能以及伸縮性,而傳統企業級應用都是比較看重資料完整性和資料安全性。那麼我們就來說說網際網路應用伸縮性這事兒.對於伸縮性這事兒,哥們兒我也寫了幾篇博文,想看的兄弟可以參考我以前的博文,對於web server,app server的伸縮性,我在這裡先不說了,因為這部分的伸縮性相對來說比較容易一點,我主要來回顧一些一個慢慢變大的網際網路應用如何應對資料庫這一層的伸縮。
首先剛開始,人不多,壓力也不大,搞一臺資料庫伺服器就搞定了,此時所有的東東都塞進一個Server裡,包括web server,app server,db server,但是隨著人越來越多,系統壓力越來越多,這個時候可能你把web server,app server和db server分離了,好歹這樣可以應付一陣子,但是隨著使用者量的不斷增加,你會發現,資料庫這哥們不行了,速度老慢了,有時候還會宕掉,所以這個時候,你得給資料庫這哥們找幾個伴,這個時候Master-Salve就出現了,這個時候有一個Master Server專門負責接收寫操作,另外的幾個Salve Server專門進行讀取,這樣Master這哥們終於不抱怨了,總算讀寫分離了,壓力總算輕點了,這個時候其實主要是對讀取操作進行了水平擴張,通過增加多個Salve來克服查詢時CPU瓶頸。一般這樣下來,你的系統可以應付一定的壓力,但是隨著使用者數量的增多,壓力的不斷增加,你會發現Master server這哥們的寫壓力還是變的太大,沒辦法,這個時候怎麼辦呢?你就得切分啊,俗話說“只有切分了,才會有伸縮性嘛”,所以啊,這個時候只能分庫了,這也是我們常說的資料庫“垂直切分”,比如將一些不關聯的資料存放到不同的庫中,分開部署,這樣終於可以帶走一部分的讀取和寫入壓力了,Master又可以輕鬆一點了,但是隨著資料的不斷增多,你的資料庫表中的資料又變的非常的大,這樣查詢效率非常低,這個時候就需要進行“水平分割槽”了,比如通過將User表中的資料按照10W來劃分,這樣每張表不會超過10W了。
綜上所述,一般一個流行的web站點都會經歷一個從單臺DB,到主從複製,到垂直分割槽再到水平分割槽的痛苦的過程。其實資料庫切分這事兒,看起來原理貌似很簡單,如果真正做起來,我想凡是sharding過資料庫的哥們兒都深受其苦啊。對於資料庫伸縮的文章,哥們兒可以看看後面的參考資料介紹。
好了,從上面的那一堆廢話中,我們也發現數據庫儲存水平擴張scale out是多麼痛苦的一件事情,不過幸好技術在進步,業界的其它弟兄也在努力,09年這一年出現了非常多的NoSQL資料庫,更準確的應該說是No relation資料庫,這些資料庫多數都會對非結構化的資料提供透明的水平擴張能力,大大減輕了哥們兒設計時候的壓力。下面我就拿Hbase這分散式列儲存系統來說說。
一 Hbase是個啥東東?
在說Hase是個啥傢伙之前,首先我們來看看兩個概念,面向行儲存和麵向列儲存。面向行儲存,我相信大夥兒應該都清楚,我們熟悉的RDBMS就是此種類型的,面向行儲存的資料庫主要適合於事務性要求嚴格場合,或者說面向行儲存的儲存系統適合OLTP,但是根據CAP理論,傳統的RDBMS,為了實現強一致性,通過嚴格的ACID事務來進行同步,這就造成了系統的可用性和伸縮性方面大大折扣,而目前的很多NoSQL產品,包括Hbase,它們都是一種最終一致性的系統,它們為了高的可用性犧牲了一部分的一致性。好像,我上面說了面向列儲存,那麼到底什麼是面向列儲存呢?Hbase,Casandra,Bigtable都屬於面向列儲存的分散式儲存系統。看到這裡,如果您不明白Hbase是個啥東東,不要緊,我再總結一下下:
Hbase是一個面向列儲存的分散式儲存系統,它的優點在於可以實現高效能的併發讀寫操作,同時Hbase還會對資料進行透明的切分,這樣就使得儲存本身具有了水平伸縮性。
二 Hbase資料模型
HBase,Cassandra的資料模型非常類似,他們的思想都是來源於Google的Bigtable,因此這三者的資料模型非常類似,唯一不同的就是Cassandra具有Super cloumn family的概念,而Hbase目前我沒發現。好了,廢話少說,我們來看看Hbase的資料模型到底是個啥東東。
在Hbase裡面有以下兩個主要的概念,Row key,Column Family,我們首先來看看Column family,Column family中文又名“列族”,Column family是在系統啟動之前預先定義好的,每一個Column Family都可以根據“限定符”有多個column.下面我們來舉個例子就會非常的清晰了。
假如系統中有一個User表,如果按照傳統的RDBMS的話,User表中的列是固定的,比如schema 定義了name,age,sex等屬性,User的屬性是不能動態增加的。但是如果採用列儲存系統,比如Hbase,那麼我們可以定義User表,然後定義info 列族,User的資料可以分為:info:name = zhangsan,info:age=30,info:sex=male等,如果後來你又想增加另外的屬性,這樣很方便只需要info:newProperty就可以了。
也許前面的這個例子還不夠清晰,我們再舉個例子來解釋一下,熟悉SNS的朋友,應該都知道有好友Feed,一般設計Feed,我們都是按照“某人在某時做了標題為某某的事情”,但是同時一般我們也會預留一下關鍵字,比如有時候feed也許需要url,feed需要image屬性等,這樣來說,feed本身的屬性是不確定的,因此如果採用傳統的關係資料庫將非常麻煩,況且關係資料庫會造成一些為null的單元浪費,而列儲存就不會出現這個問題,在Hbase裡,如果每一個column 單元沒有值,那麼是佔用空間的。下面我們通過兩張圖來形象的表示這種關係:
上圖是傳統的RDBMS設計的Feed表,我們可以看出feed有多少列是固定的,不能增加,並且為null的列浪費了空間。但是我們再看看下圖,下圖為Hbase,Cassandra,Bigtable的資料模型圖,從下圖可以看出,Feed表的列可以動態的增加,並且為空的列是不儲存的,這就大大節約了空間,關鍵是Feed這東西隨著系統的執行,各種各樣的Feed會出現,我們事先沒辦法預測有多少種Feed,那麼我們也就沒有辦法確定Feed表有多少列,因此Hbase,Cassandra,Bigtable的基於列儲存的資料模型就非常適合此場景。說到這裡,採用Hbase的這種方式,還有一個非常重要的好處就是Feed會自動切分,當Feed表中的資料超過某一個閥值以後,Hbase會自動為我們切分資料,這樣的話,查詢就具有了伸縮性,而再加上Hbase的弱事務性的特性,對Hbase的寫入操作也將變得非常快。
上面說了Column family,那麼我之前說的Row key是啥東東,其實你可以理解row key為RDBMS中的某一個行的主鍵,但是因為Hbase不支援條件查詢以及Order by等查詢,因此Row key的設計就要根據你係統的查詢需求來設計了額。我還拿剛才那個Feed的列子來說,我們一般是查詢某個人最新的一些Feed,因此我們Feed的Row key可以有以下三個部分構成<userId><timestamp><feedId>,這樣以來當我們要查詢某個人的最進的Feed就可以指定Start Rowkey為<userId><0><0>,End Rowkey為<userId><Long.MAX_VALUE><Long.MAX_VALUE>來查詢了,同時因為Hbase中的記錄是按照rowkey來排序的,這樣就使得查詢變得非常快。
三 Hbase的優缺點
1 列的可以動態增加,並且列為空就不儲存資料,節省儲存空間.
2 Hbase自動切分資料,使得資料儲存自動具有水平scalability.
3 Hbase可以提供高併發讀寫操作的支援
Hbase的缺點:
1 不能支援條件查詢,只支援按照Row key來查詢.
2 暫時不能支援Master server的故障切換,當Master宕機後,整個儲存系統就會掛掉.
四.補充
1.資料型別,Hbase只有簡單的字元型別,所有的型別都是交由使用者自己處理,它只儲存字串。而關係資料庫有豐富的型別和儲存方式。
2.資料操作:HBase只有很簡單的插入、查詢、刪除、清空等操作,表和表之間是分離的,沒有複雜的表和表之間的關係,而傳統資料庫通常有各式各樣的函式和連線操作。
3.儲存模式:HBase是基於列儲存的,每個列族都由幾個檔案儲存,不同的列族的檔案時分離的。而傳統的關係型資料庫是基於表格結構和行模式儲存的
4.資料維護,HBase的更新操作不應該叫更新,它實際上是插入了新的資料,而傳統資料庫是替換修改
5.可伸縮性,Hbase這類分散式資料庫就是為了這個目的而開發出來的,所以它能夠輕鬆增加或減少硬體的數量,並且對錯誤的相容性比較高。而傳統資料庫通常需要增加中間層才能實現類似的功能
下面是用詳細實際操作截圖比較區別
|
1.nosql資料庫能否刪除列 2.nosql資料庫如何刪除一條記錄 3.nosql資料庫列族和lieder區別是什麼? 4.nosql操作與傳統資料庫的操作區別在什麼地方? 對於大多數做技術的人員,都知道我們傳統資料庫是什麼樣子的,那麼如下圖所示,我們操作的物件是行。 也就是增刪改查,都是以為物件。 1.傳統資料庫增加刪除介紹  圖1 圖1下面我們以mysql為例: 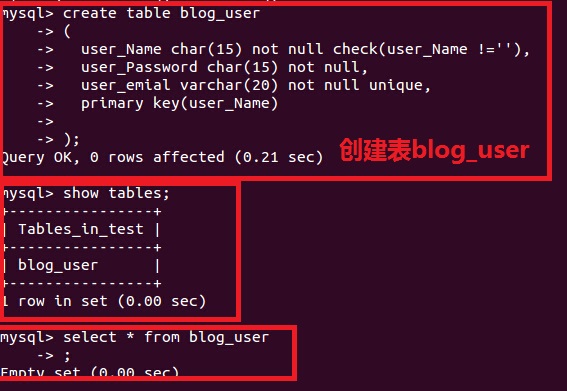 插入資料 mysql>INSERT INTO blog_user (`user_Name`,`user_Password`,`user_emial`)VALUES ('aboutyun','aboutyun', '[email protected]');  刪除資料:
 2.Nosql資料庫增加刪除介紹 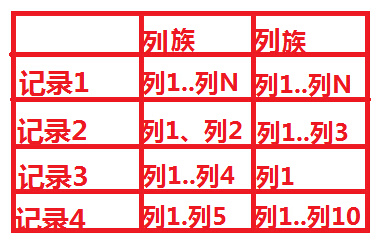 圖2 以hbase為例: 建立表:
 插入資料 這裡是關鍵點,也是很多人不容易理解的地方
 上面我們看到了 1所示是什麼,我們在傳統資料塊裡面根本沒有,這是nosql所特有的,是一個rowkey,是系統自帶的,也是nosql中一條記錄的唯一標識。但是這個唯一標識,有跟我們的傳統資料庫是有所差別的。如圖1所示,“記錄1”便是rowkey. 2所示是我們插入的列user_Name,這也是最難以理解的地方,列竟然可以插入。並且其’value‘為3即'aboutyun' 我們插入了列,下面我們來檢視一下效果:  下面來解釋一下上面的含義: 我們會看到 1為rowkey,插入資料‘, 2為列族下面列的名字user_Name 3我們並沒有在設計的新增這個列族,所以這個是系統自帶的,這個是記錄的操作時間,以時間戳的形式放到hbase裡面。 4是我們插入的user_Name的值 下面我們在插入password:
 再次查詢結果:
 到這裡,我們看到兩行記錄,傳統資料塊認為這是兩行資料,對於nosql,這是一條記錄。 刪除列資料 刪除資料分為刪除列和刪除記錄 1.刪除列 這裡面的刪除,沒有刪除 delete 'blog_user','www.aboutyun.com','userInfo:user_Password'  從上面我們看出列被刪除了 2.刪除記錄:
這是刪除之前顯示結果,這裡已經是  刪除後結果 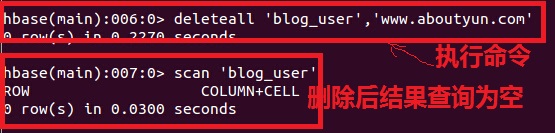 總結 對於傳統資料庫,增加列對於一個專案來講,改變是非常大的。但是對於nosql,插入列和刪除列,跟傳統資料庫裡面的增加記錄和刪除記錄類似 |
相關推薦
Hbase和Hive的區別,Hbase與傳統資料庫的區別
HBase 於 Hive 的區別,我們簡單的梳理一下 Hive 和 HBase 的應用場景: Hive 適合用來對一段時間內的資料進行分析查詢,例如,用來計算趨勢或者網站的日誌。Hive 不應該用來進行實時的查詢(Hive 的設計目的,也不是支援實時的查詢)。因為它需要很長時間才可以返回結果;H
Hbase與傳統資料庫的區別
在說HBase之前,我想再嘮叨幾句。做網際網路應用的哥們兒應該都清楚,網際網路應用這東西,你沒辦法預測你的系統什麼時候會被多少人訪問,你面臨的使用者到底有多少,說不定今天你的使用者還少,明天系統使用者就變多了,結果您的系統應付不過來了了,不幹了,這豈不是咱哥幾個的悲哀,說時
Hbase資料庫與傳統資料庫的比較
HBase的知識點 Mycat備份機制 HMASTER動態感知HregionServer的狀態。 基於行的行式資料庫 行式讀取方式 基於列的列式資料庫 傳統資料庫的
大資料研發(2Hbase)2.1:hbase和傳統資料庫的區別
1.hbase①hbase是一個面向列儲存的分散式儲存系統,可以實現高效能的併發讀寫操作,對資料進行透明的切分。②hbase有兩個主要概念,row key(行健),column family(列簇)。每個列簇包含多個列。row key 是hbase中記錄的唯一標識。③hbas
Hbase與傳統關系型數據庫對比
不同的 存儲方式 start 分開部署 好的 技術分享 兼容 看到了 是我 在說HBase之前,我想再嘮叨幾句。做互聯網應用的哥們兒應該都清楚,互聯網應用這東西,你沒辦法預測你的系統什麽時候會被多少人訪問,你面臨的用戶到底有多少,說不定今天你的用戶還少,明天系統用戶就變多了
Hive簡介、什麼是Hive、為什麼使用Hive、Hive的特點、Hive架構圖、Hive基本組成、Hive與Hadoop的關係、Hive與傳統資料庫對比、Hive資料儲存
1.1 Hive簡介 1.1.1 什麼是Hive Hive是基於Hadoop的一個數據倉庫工具,可以將結構化的資料檔案對映為一張資料庫表,並提供類SQL查詢功能。 1.1.2 為什麼使用Hive Ø 直接使用hadoop所面
HBase-與Hive的區別、與Sqoop的整合
1、HBase 與 Hive 的對比 Hive: 1)、資料倉庫 Hive 的本質其實就相當於將 HDFS 中已經儲存的檔案在 Mysql 中做了一個雙射關係,以方 便使用 HQL 去管理查詢。 2)、用於資料分析、清洗 Hive 適用於離線的資料分析和清洗,延遲較高。 3)
Hive與傳統資料庫對比
中沒有定義專門的資料格式,資料格式可以由使用者指定,使用者定義資料格式需要指定三個屬性:列分隔符(通常為空格、”\t”、”\x001″)、行分隔符(”\n”)以及讀取檔案資料的方法(Hive中預設有三個檔案格式TextFile,SequenceFile以及 RCFile)。由於在載入資料的過程中,不需要從使用
ES與傳統資料庫的比較
ES(ElasticSearch)是一款分散式全文檢索框架,底層基於基於Lucene實現。ES與傳統資料的區別主要有: 1.結構名稱不同 一個ES叢集可以包含多個索引(資料庫),每個索引又包含了很多型別(表),型別中包含了很多文件(行),每個文件使用 JSON 格式儲存資
小程式UI與傳統HTML5區別
開發語言不同。 小程式自己開發了一套WXML標籤語言和WXSS樣式語言,並非直接使用標準的HTML5+css3。 元件封裝不同。 小程式獨立出來了很多原生APP的元件,在HTML5需要模擬才能實現的功能,小程式裡可以直接呼叫元件。小程式開發者工具 微信小程式的開發工具,基於MINA框架(現已取消該名稱)
HBase資料庫與關係型資料庫的區別(取材於官方文件)
HBase 資料被建模為多維對映,其中值(表單元)通過 4 個鍵索引: value = Map(TableName, RowKey, ColumnKey, Timestamp) 其中: TableName 是一個字串。 是表名。 RowKey 和 ColumnKey 是
Hbase和Hive以及傳統資料庫的區別
Hbase和Hive HBase 是一種類似於資料庫的儲存層,也就是說 HBase 適用於結構化的儲存。並且 HBase 是一種列式的分散式資料庫。 HBase 底層依舊依賴 HDFS 來作為其物理儲存,這點類似於 Hive。 1.實時性:Hive 適合用來對一段時間內
html5新增標簽與傳統html的區別
部分 canvas 側邊欄 運用 html5 元素 base frameset tail 一、文檔聲明以及編碼聲明的改變 html5之前的版本聲明: 文檔類型- <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transit
什麽是響應式網站建設?與傳統網站制作相比有什麽區別和不同?
16px 訪問 問題 接下來 網址 點贊 例如 沒有 正常 傳統網站建設可以說是互聯網剛剛興起時的產物,已經是過去式的代名詞,如今如果還有企業選擇這一類傳統建站服務的話,只能說企業領導們對互聯網這一塊不大關註,或沒有互聯網思維意識,甚至說沒有危機感,有網站和沒有網站關系不大
git 團隊合作的使用方法以及與傳統SVN的區別:
我們先來聊一聊git和svn的區別把: 首先git是一個分散式的(distribute)也就是團隊之間的成員不僅能夠共享程式碼 從管理git上pull或者是push程式碼,並且他對成員的程式碼提交過程記錄特別的好; 當然SVN也有這些功能,但是為什麼說git要更好一些呢:問題就出在分散式
一對一直播原始碼平臺開發搭建與傳統直播平臺開發有什麼區別
今早在拜訪客戶的時候,QQ上有位大哥加我好友諮詢手機直播軟體開發相關問題。我說好的呀!然後給大哥發了案例體驗下,對方回覆我“你給我的案例怎麼跟我看到的不一樣呢?”當時我是一臉的懵呀~~最後問清楚之後,才知道大哥是要問下一對一直播平臺怎麼開發。當時,我就在想要不給大家聊下我對一對一直播和傳統直播平臺之
NIO與傳統IO的區別,很好的比喻
傳統的socket IO中,需要為每個連線建立一個執行緒,當併發的連線數量非常巨大時,執行緒所佔用的棧記憶體和CPU執行緒切換的開銷將非常巨大。使用NIO,不再需要為每個執行緒建立單獨的執行緒,可以用一個含有限數量執行緒的執行緒池,甚至一個執行緒來為任意數量的連線服務。由於執行緒數量小於連線數量,所以每個執行
Hive與關係型資料庫的區別
Hive與關係型資料庫的區別 (1)Hive和關係型資料庫儲存檔案的系統不同, Hive使用的是HDFS(Hadoop的分散式檔案系統),關係型資料則是伺服器本地的檔案系統。 (2)Hive使用的計算模型是MapReduce,而關係型資料庫則是自己設計的計算
看電子煙與傳統香菸有何區別
電子煙是一種模仿捲菸的電子產品,有著與捲菸一樣的外觀、煙霧、味道和感覺。它是通過霧化等手段,將尼古丁等變成蒸汽後,讓使用者吸食的一種產品。與傳統的香菸相比,電子煙又有哪些不同呢? 電子煙和傳統香菸的區別 電子煙是一種非燃燒的香菸替代品。其主要原理是通過電池給控制板及霧化器提供電源,將煙油霧化
資料庫中char與varchar型別區別
1.CHAR的長度是固定的,而VARCHAR2的長度是可以變化的, 比如,儲存字串“abc",對於CHAR (10),表示你儲存的字元將佔10個位元組(包括7個空字元),而同樣的VARCHAR2 (10)則只佔用3個位元組的長度,10只是最大值,當你儲存的字元小於10時,按實際長度儲存。 2