
Linux->Windows主機目錄和檔名中文亂碼恢復
目錄
Linux->Windows主機目錄和檔名中文亂碼恢復
標籤: 字元編碼 Python
宣告
本文主要記述作者如何通過Python指令碼恢復跨平臺傳輸導致的目錄和檔名中文亂碼。作者對Python程式設計和字元編碼瞭解不多,紕漏難免,歡迎指正。同時,本文兼做學習筆記,存在囉嗦之處,敬請諒解。
本文同時也釋出於作業部落,閱讀體驗可能更好。
一. 亂碼問題
一年前,作者將Windows XP系統主機下建立的一批檔案(以多級目錄組織),通過Samba手工拷貝至Linux系統主機,能正常顯示目錄和檔名中包含的中文字元。然後,通過filezilla連線Linux主機,將上述檔案下載至行動硬碟,這個過程中也未出現亂碼。但將行動硬碟連線到Windows 7系統主機上時,卻發現目錄和檔名中包含的中文字元出現亂碼。
例如,檔名"GNU Readline庫函式的應用示例"和"守護程序接收終端輸入的一種變通性方法"分別顯示為"GNU Readlineåºå½æ°çåºç¨ç¤ºä¾"和"å®æ¤è¿ç¨æ¥æ¶ç»ç«¯è¾å ¥çä¸ç§åéæ§æ¹æ³"。
但除目錄和檔名出現中文亂碼外,檔案內容並無亂碼。
作者當時並不熟悉字元編碼知識,於是請教《通俗易懂地解決中文亂碼問題(1) --- 跨平臺亂碼》一文的作者Roly-Poly。Roly-Poly非常熱心地轉換了上述兩個檔名,並給出效果圖:

以及相應的Java轉換方法:
String str = new String(new String(messyName.getBytes("ISO-8859-1"), "GBK").getBytes("GBK"), "UTF-8");其中,messyName對應出現亂碼的字串。getBytes(charset)將Unicode編碼儲存的字串按照charset編碼,並以位元組陣列表示;new String(bytes[], charset)則將位元組陣列按照charset編碼進行組合識別,最後轉換為Unicode儲存。因此,上述程式碼表示先將當前編碼從 ISO-8859-1轉為GBK,然後再從GBK轉為UTF-8。
當然,Roly-Poly的轉換仍有缺憾,畢竟還存在未能正確解析的亂碼。"幸運"的是,當時出於謹慎,作者分別通過dir /S path
tree /F path(Windows)和ls -lRS --time-style=long-iso(Linux)建立了三份檔案列表。這樣,在Roly-Poly轉碼的基礎上再做些校驗,有望替換為完全正確的檔名。
然而,一方面因為作者對Java語言和字元編碼比較陌生(主要是懶),另一方面因為解析檔案列表並更名的工作量預期較大,作者一直未付諸實踐。直到最近,才開始從頭著手處理亂碼問題。這一過程學到不少知識,也走過不少彎路。教訓就是:凡事要一鼓作氣!
二. 除錯環境
作者使用Python 2.7自帶的IDLE進行編碼除錯。除非特別說明,本文所有程式碼均為Python語言。
參考Python字元編碼詳解一文,獲取當前環境的預設編碼:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys, locale
def SysCoding():
fmt = '{0}:{1}'
#當前系統所使用的預設字元編碼
print fmt.format('DefaultEncoding ', sys.getdefaultencoding())
#轉換Unicode檔名至系統檔名時所用的編碼('None'表示使用系統預設編碼)
print fmt.format('FileSystemEncoding ', sys.getfilesystemencoding())
#預設的區域設定並返回元祖(語言, 編碼)
print fmt.format('DefaultLocale ', locale.getdefaultlocale())
#使用者首選的文字資料編碼(猜測結果)
print fmt.format('PreferredEncoding ', locale.getpreferredencoding())
if __name__ == '__main__':
SysCoding()作者的Windows XP系統主機上,區域和語言選項->區域選項->標準和格式及高階->非Unicode程式的語言均設定為"中文(中國)";Windows 7系統主機上,區域和語言->格式及管理->非Unicode程式的語言均設定為"中文(簡體,中國)"。兩臺主機的SysCoding()輸出相同,均顯示如下:
DefaultEncoding :ascii
FileSystemEncoding :mbcs
DefaultLocale :('zh_CN', 'cp936')
PreferredEncoding :cp936三. 目錄和檔名亂碼恢復
3.1 可選方案
3.1.1 通過合適的編解碼轉換
可使用chardet模組detect()函式檢測給定字元的編碼。該函式返回檢測到的編碼'encoding'及其可信度'confidence'。
安裝方法為:命令提示符下執行C:\Python27\Scripts>easy_install.exe chardet後,自動下載egg檔案包。若未安裝成功(import提示"ImportError: No module named chardet"),可到C:\Python27\Lib\site-packages目錄解壓egg檔案包,將其中的chardet目錄(所有檔案)拷貝到site-packages下面即可。
安裝成功後,按照以下方法檢測字元編碼:
#coding: gbk
import chardet
print chardet.detect('abc') #{'confidence': 1.0, 'encoding': 'ascii'}
print chardet.detect('喊') #{'confidence': 0.73, 'encoding': 'windows-1252'}
print chardet.detect('漢') #{'confidence': 0.99, 'encoding': 'TIS-620'} ##Thailand
print chardet.detect('漢中華人民共和國') #{'confidence': 0.99, 'encoding': 'GB2312'}
print '漢中華人民共和國', repr('漢中華人民共和國')
#漢中華人民共和國 '\xba\xba\xd6\xd0\xbb\xaa\xc8\xcb\xc3\xf1\xb9\xb2\xba\xcd\xb9\xfa'可見,當字元"樣本"過少時,chardet檢測結果並不準確(如'漢'被識別為泰文)。在Shell中執行上述檢測時,結果與之相同。
作為對比,宣告為coding: utf-8時,檢測結果又是另一番"景象":
import chardet
print chardet.detect('abc') #{'confidence': 1.0, 'encoding': 'ascii'}
print chardet.detect('æCUnitè¿è¡') #{'confidence': 0.99, 'encoding': 'utf-8'}
print chardet.detect('喊') #{'confidence': 0.73, 'encoding': 'windows-1252'}
print chardet.detect('漢') #{'confidence': 0.73, 'encoding': 'windows-1252'}
print chardet.detect('漢中華人民共和國') #{'confidence': 0.99, 'encoding': 'utf-8'}
print '漢中華人民共和國', repr('漢中華人民共和國')
#奼変腑鍗庝漢姘戝叡鍜屽浗 '\xe6\xb1\x89\xe4\xb8\xad\xe5\x8d\x8e\xe4\xba\xba\xe6\xb0\x91\xe5\x85\xb1\xe5\x92\x8c\xe5\x9b\xbd'可見,'å£è¯å¥æ_æ°æµ'被檢測為UTF-8編碼。這是因為UTF-8是ASCII的超集。當字串序列中所有字元均為ASCII符號(前128個字元)時,chardet認為該串為ASCII編碼;當字串序列中也含有所有擴充套件ASCII符號時,chardet很可能認為該串為UTF-8編碼。此外,print根據本地作業系統預設字元編碼(GBK),將'漢中華人民共和國'列印為奼変腑鍗庝漢姘戝叡鍜屽浗。
3.1.2 根據檔案列表資訊匹配
通過正則表示式提取檔案列表中的目錄大小、檔案數目、檔名及其大小、建立時間等資訊,再遍歷行動硬碟亂碼目錄,進行匹配和更名。為保險起見,應維護一份對映檔案,儲存檔案路徑、原名和新名,以便恢復或校正。
為減少匹配和更名次數,只操作名稱包含字母數字以外字元的目錄和檔案。此外,還可對檔案列表排序,如dir path /S /O:S(按大小升序排列)。
3.1.3 機器學習
因為word、網頁等檔案開啟後通常可以看到標題,作者得以整理若干檔案亂碼名與正常名的對映資料。這樣,藉助機器學習(如基於例項的演算法),最終有望消除所有亂碼。
顯然,這一方案難度太高,並不現實。
3.2 逐步實踐
3.2.1 獲取單級目錄及其檔案資訊
首先,建立名稱正常的多級目錄供除錯用。之所以不用原始亂碼目錄除錯,是因為一旦測試失敗很可能會破壞"樣本"。
然後,通過以下程式碼獲取單級目錄的大小、檔案數目、檔名及大小、建立時間等資訊:
import time
from os.path import join, getsize, getmtime, getctime
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
#os.getcwd()返回當前工作目錄
def FilesInfo():
for root, dirs, files in os.walk(CURRENT_DIR):
for file in files:
path = join(root, file)
ctime = time.ctime(getctime(path)) #建立時間
print 'Name:%-12s Size:%-7s Ctime:%s' %(file, getsize(path), ctime)
print root, "consumes",
print sum(getsize(join(root, file)) for file in files),
print "bytes in", len(files), "non-directory files!"注意,當本模組由其他模組import並執行時,os.getcwd()返回的並非本模組目錄。
執行FilesInfo()後,輸出結果如下:
Name:Coding.py Size:7936 Ctime:Mon Feb 29 09:41:15 2016
Name:d_res.bmp Size:522534 Ctime:Mon Feb 29 09:41:15 2016
Name:error3.bmp Size:70782 Ctime:Mon Feb 29 09:41:15 2016
Name:Open.bmp Size:354746 Ctime:Mon Feb 29 09:41:15 2016
Name:Thumbs.db Size:19968 Ctime:Mon Feb 29 09:41:47 2016
Name:typec.bmp Size:199022 Ctime:Mon Feb 29 09:41:15 2016
Name:WalkDir.py Size:4894 Ctime:Mon Feb 29 09:41:15 2016
Name:復Coding.py Size:6564 Ctime:Mon Feb 29 15:41:37 2016
E:\PyTest\stuff consumes 1186446 bytes in 8 non-directory files!3.2.2 從檔案列表中提取目錄和檔案資訊
在命令提示符下dir \F出調試目錄的結構。擷取部分如下:
C:\Program Files\IDM Computer Solutions\UEStudio>e:
E:\PyTest 的目錄
2016-02-24 11:53 <DIR> .
2016-02-24 11:53 <DIR> ..
2016-02-23 17:22 1,434 backup_ver2.py然後,通過ParseFileList()函式解析出"E:\PyTest"之類的路徑:
import codecs, re
def ParseFileList():
#Windows記事本預設的字元編碼為"ANSI"(實際是GBK)
file = codecs.open(r'E:\PyTest\filelist.txt', encoding='gbk')
for line in file:
#下句等效於m = re.match(u' (.+) 的目錄\s*$', line)
m = re.compile(u""" # Python預設字元編碼為Ansi, 需加u轉為Unicode
(.+) 的目錄 # 將' 的目錄'前的部分作為分組(Group)
\s*$ # 行尾""", re.X).match(line)
if m != None:
print m.groups()[0]注意,此處並未使用內建的open()方法開啟檔案。因為該方法得到的line為str型別,需要使用正確的編碼格式進行decode(),否則將無法匹配到"的目錄"。而codecs.open()方法開啟檔案時讀取的就是Unicode型別,不容易出現編碼問題。
當然,若將原始碼檔案中的字元編碼宣告改為#coding=gbk,並去掉pattern字串字首u,則使用內建的open()方法仍可匹配到"的目錄"。
目錄大小、檔案數目、檔名及其大小等,均可通過合適的正則表示式提取。然而,作者很快意識到,根據檔案列表遍歷和更名的方案實現起來過於複雜。於是,放棄正則匹配的嘗試。
3.2.3 遍歷目錄並更名
雖然檔案列表正則匹配的方案不可行,但遍歷和更名卻是所有方案所必需的。
Python中有三種遍歷目錄的方法,即os.listdir()、os.walk()和os.path.walk()。這三者中,作者首選os.walk()方法,遍歷程式碼如下:
import os
def ValidateDir(dirPath):
#判斷路徑是否為Unicode。若否,將其轉換為Unicode編碼
if isinstance(dirPath, unicode) == False:
#下句等效於dirPath = dirPath.decode('utf8')
dirPath = unicode(dirPath, 'utf8')
#判斷路徑是否存在(不區分大小寫)
if os.path.exists(dirPath) == False:
print dirPath + ' is non-existent!'
return ''
#判斷路徑是否為目錄(不區分大小寫)
if os.path.isdir(dirPath) == False:
print dirPath + ' is not a directory!'
return ''
return dirPath
def WalkDirReport(dirPath, fileNum):
print '##############' + str(fileNum) + ' files processed##############'
def WalkDir(dirPath):
dirPath = ValidateDir(dirPath)
if not dirPath:
return
#遍歷路徑下的檔案及子目錄
fileNum = 0
for root, dirs, files in os.walk(dirPath):
for file in files:
#處理檔案
#ChangeNames(root, file)
#RestoreNames(root, file)
fileNum += 1
while(fileNum % 100) == 0:
prompt = '$' + str(fileNum) + ' files processed, ' \
+ '''pause for checking. Type 'c' to continue: '''
if raw_input(prompt) == 'c':
break
WalkDirReport(dirPath, fileNum)其中,ValidateDir()用於校驗路徑合法性,同時還將非Unicode路徑轉為Unicode路徑(該步驟也可由使用者自行完成)。
os.listdir()方法遍歷目錄則較為"笨拙",對比如下:
def WalkDir_unsafe(dirPath):
dirPath = ValidateDir(dirPath)
if not dirPath:
return
#遍歷路徑下的檔案及子目錄
fileNum = 0
nameList = os.listdir(dirPath)
for name in nameList:
path = os.path.join(dirPath, name)
#型別為目錄,遞迴(存在棧溢位風險)
if os.path.isdir(path) == True:
fileNum += WalkDir_unsafe(path)
continue
#處理檔案
'''此時name等效於os.path.basename(path),即檔名;
dirPath等效於os.path.dirname(path),即目錄名;
path等效於os.path.abspath(os.path.basename(path)),即絕對路徑'''
fileNum += 1
return fileNum因為採用遞迴處理,所以該方法存在棧溢位風險(不過作者尚未遇到這種情況)。使用時,需按照如下方式呼叫:
WalkDirReport(r'E:\Pytest\測試', WalkDir_unsafe(r'E:\Pytest\測試'))注意,雖然os.walk()本身仍由os.listdir()遞迴實現,但卻是生成器(generator)寫法,相比普通遞迴更節省記憶體資源。
遍歷目錄除錯通過後,就可著手實現目錄和檔案更名。為簡單起見,更名規則為"尾部添0",即"E:\a\b.txt"會轉換為"E:\a0\b.txt0"。同時提供恢復函式,以便反覆除錯。程式碼如下:
def ChangeNames(dir, file):
#將'E:\a\b.txt'轉換為'E:\a0\b.txt0',以此類推
filePath = os.path.join(dir, file)
newdir = dir.split('\\')
newdir[1:] = map(lambda x: x+'0', newdir[1:]) #碟符不變
newdir = '\\'.join(newdir)
ufilePath = os.path.join(newdir, file) + '0'
print filePath + ' => ' + ufilePath
os.renames(filePath, ufilePath)
def RestoreNames(dir, file):
#將'E:\a0\b.txt0'恢復為'E:\a\b.txt',以此類推
filePath = os.path.join(dir, file)
newdir = dir.split('\\')
newdir[1:] = map(lambda x: x[:-1], newdir[1:])
newdir = '\\'.join(newdir)
ufilePath = os.path.join(newdir, file)[:-1]
print filePath + ' => ' + ufilePath
os.renames(filePath, ufilePath)可見,"添0"和恢復的方法比較"笨拙"。但作為Python新手,作者暫時只能如此。結合遍歷程式碼,ChangeNames()和RestoreNames()可有效地更名和恢復。
注意os.renames()方法,該方法可對巢狀目錄及其檔案更名,可能會建立臨時目錄以存放新命名的子目錄和檔案。因此,若以WalkDir(r'E:\bPytest')方式呼叫且bPytest目錄下存在空的子目錄,則更名後該子目錄保持原名原位置(仍在E:\bPytest目錄下),而其他子目錄及檔案被更名且"轉移"到E:\bPytest0目錄下——同時出現bPytest和bPytest0兩個目錄!
3.2.4 消除單個檔名亂碼
遍歷和更名除錯成功後,接下來便是重中之重——亂碼檔名恢復。
瀏覽各種網路資料後,作者終於在Stackoverflow網站上一則問答Getting correct utf8 Chinese characters from messed-up iso-8859-1 in Python and MySQL裡找到一線曙光。回答者通過u'最'.encode('cp1252').decode('utf8')成功地將最轉換為"最"——這與作者遇到的亂碼何其相似!
在嘗試cp1252、cp1254...等眾多Windows編碼後,作者終於找到正確的編碼格式,即latin_1,別名iso-8859-1, iso8859-1, 8859, cp819, latin, latin1, L1。測試程式碼如下:
print u'项ç®ä¸éæCUnitè¿è¡å¼åæµè¯'.encode('latin_1').decode('utf8')
print u'ãNBCå¤é´æ°é»(2011-2å£)'.encode('latin_1').decode('utf8')
print 'æ°æµªå客'.decode('utf8').encode('latin_1').decode('utf8')其中,u'string'等效於'string'.decode('utf8')。執行結果為:
專案中整合CUnit進行開發測試
《NBC夜間新聞(2011-2季)
新浪部落格經人工檢驗,完全符合期望!
此時再回想Roly-Poly提供的Java轉碼語句:
String str = new String(new String(messyName.getBytes("ISO-8859-1"), "GBK").getBytes("GBK"), "UTF-8");因為字串在Java記憶體中以Unicode編碼儲存,且getBytes()和new String()分別對應Python裡的encode()和decode(),所以等效的Python轉碼語句如下:
str = u'messyName'.encode('latin_1').decode('gbk').encode('gbk').decode('utf8')從字元編碼規則可知,經過GBK編解碼"中轉"後,很可能出現data loss。以第一章的兩個檔名為例,其Python轉碼如下:
s1 = u'GNU Readlineåºå½æ°çåºç¨ç¤ºä¾'.encode('latin_1').decode('gbk').encode('gbk','replace').decode('utf8')
s2 = u'å®æ¤è¿ç¨æ¥æ¶ç»ç«¯è¾å
¥çä¸ç§åéæ§æ¹æ³'.encode('latin_1').decode('gbk','replace').encode('gbk','replace').decode('utf8','replace')
s3 = u'å®æ¤è¿ç¨æ¥æ¶ç»ç«¯è¾å
¥çä¸ç§åéæ§æ¹æ³'.encode('latin_1').decode('utf8')
print s1 #GNU Readline庫函式的應用示例
print s2 #守護程序接收終�?輸入的一種變通�?方法
print s3 #守護程序接收終端輸入的一種變通性方法其中,'replace'引數以適當的字元替換編解碼過程中無法識別的字元,否則將產生UnicodeDecodeError和UnicodeEncodeError異常。可見,就本文問題而言,並不需要GBK編解碼"中轉"。
3.2.5 消除單級目錄下檔名亂碼
檔名字串亂碼恢復成功後,接下來將對檔案更名。該步驟需要在掛接行動硬碟的Windows 7主機上進行,因為在Windows XP主機上檔名亂碼無法以期望的方式顯示和解析。例如:
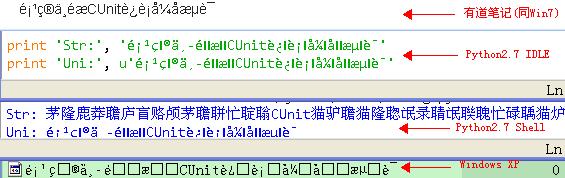
最後那個以亂碼字串為名建立的檔案,無法開啟(UEStudio提示"含有一個無效的路徑",記事本提示"無效的視窗控制代碼"),os.rename()也會報錯。
在Windows 7主機上,作者從行動硬碟拷貝一個單級亂碼目錄至磁碟作除錯用。然後,編寫程式碼恢復該目錄下的所有亂碼檔名:
from nt import chdir
def RecodeName(dirPath):
nameList = os.listdir(dirPath)
for fileName in nameList:
try:
ufileName = fileName.encode('latin_1').decode('utf8')
except UnicodeEncodeError as e:
print '[e]' + fileName + '(Possibly needn\'t xcode!)'
continue
print (fileName + ' => ' + ufileName)
#rename之前要先用chdir()函式進入到目標檔案所在的路徑
chdir(dirPath)
os.rename(fileName, ufileName)因為存在某些檔案已被手工更名的可能性,encode('latin_1')時會丟擲UnicodeEncodeError異常,所以需要跳過這些檔案。
執行結果如下:
8.26å京990å°ç»éªï¼å¸æ对以åç人æå¸®å© - è±è¯æä¸èè¯(TOEIC) - 大家论å -.url => 8.26南京990小經驗,希望對以後的人有幫助 - 英語託業考試(TOEIC) - 大家論壇 -.url
~2011.5.29~æä¸905ææ³~æ谢大家ç½è®ºå~å¸æè½ç»å¤§å®¶å¸¦æ¥å¸®å© - è±è¯æä¸èè¯(TOEIC) - 大家论å -.url => ~2011.5.29~託業905感想~感謝大家網論壇~希望能給大家帶來幫助 - 英語託業考試(TOEIC) - 大家論壇 -.url
ä¸å½é
æç½.url => 中國雅思網.url
å¦ä½æé«è±è¯å¬å_æé«è±è¯å¬åçæ¹æ³_å¬å课å .url => 如何提高英語聽力_提高英語聽力的方法_聽力課堂.url
>>> 經驗證,指定目錄下所有亂碼檔名均正確恢復。
3.2.6 消除巢狀目錄名及其檔名亂碼
單級目錄下檔名亂碼消除後,作者換用os.renames()方法消除巢狀目錄名及其檔名。程式碼如下:
def RecodeNames(dir, file):
filePath = os.path.join(dir, file)
try:
filePathNew = filePath.encode('latin_1').decode('utf8')
except UnicodeEncodeError as e:
'''os.renames()會建立臨時目錄以存放新命名的子目錄和檔案,故此處異常
表明最底層檔案已解碼成功(可能是手工處理),但其目錄路徑仍未解碼。
因此,需構造已解碼全路徑,以便renames將上述檔案拷貝至新目錄。
'''
print '[e]' + filePath + '(Possibly needn\'t xcode!)'
filePathNew = os.path.join(dir.encode('latin_1').decode('utf8'), file)
print (filePath + ' => ' + filePathNew)
os.renames(filePath, filePathNew)以WalkDir(r'F:\Pytest\Study')執行,結果如下:
F:\Pytest\Study\John_æ°æµªå客.url => F:\Pytest\Study\John_新浪部落格.url
[e]F:\Pytest\Study\ABR\~2011.5.29~託業905感想~感謝大家網論壇~希望能給大家帶來幫助 - 英語託業考試(TOEIC) - 大家論壇 -.url(Possibly needn't xcode!)
F:\Pytest\Study\ABR\~2011.5.29~託業905感想~感謝大家網論壇~希望能給大家帶來幫助 - 英語託業考試(TOEIC) - 大家論壇 -.url => F:\Pytest\Study\ABR\~2011.5.29~託業905感想~感謝大家網論壇~希望能給大家帶來幫助 - 英語託業考試(TOEIC) - 大家論壇 -.url
F:\Pytest\Study\å¾
读\ãNBCå¤é´æ°é»(2011-2å£)ã(NBC Nightly News)([m4v]è±è¯å¬åä¸è½½ -å¦ä¹ èµæåº.url => F:\Pytest\Study\待讀\《NBC夜間新聞(2011-2季)》(NBC Nightly News)([m4v]英語聽力下載 -學習資料庫.url
##############3 files processed##############可見,根目錄和子目錄及所有下屬檔案均正確更名。
讀者可能已經注意到,上述根目錄路徑名均為英文字元。假如該路徑包含已解碼的中文目錄名(可能是手工處理)呢?例如將Study目錄名改為外語學習。顯然,encode('latin_1')時會觸發UnicodeEncodeError異常。因此,編解碼時需要跳過這些中文目錄名:
def RecodeNames(dir, file):
filePath = os.path.join(dir, file)
#對路徑解碼
paths = filePath.split('\\')
for i in range(len(paths)):
try:
paths[i] = paths[i].encode('latin_1').decode('utf8')
except UnicodeEncodeError as e:
#路徑可能出現已解碼的中文(可能是手工處理),不再重複解碼
continue
filePathNew = '\\'.join(paths)
print (filePath + ' => ' + filePathNew)
os.renames(filePath, filePathNew)什麼?假如目錄名包含部分亂碼部分中文字元?拜託,這種情況不可能出現。
3.2.7 恢復原始亂碼目錄和檔名
激動人心的時刻來到了!本節將正式處理行動硬碟中的原始亂碼目錄和檔名。基於以上除錯結果,最終的亂碼恢復程式碼如下:
failedNamesList = []
def RecordFailedNames(name):
failedNamesList.append(name)
import ctypes
def RecodeNames(dir, file):
filePath = os.path.join(dir, file)
#對路徑解碼
paths = filePath.split('\\')
for i in range(len(paths)):
try:
paths[i] = paths[i].encode('latin_1').decode('utf8')
except UnicodeEncodeError as e:
#路徑可能出現已解碼的中文(可能是手工處理),不再重複解碼
continue
filePathNew = '\\'.join(paths)
print (filePath + ' => ' + filePathNew)
try:
os.renames(filePath, filePathNew)
except WindowsError as e:
print "[e]WindowsError({0}): {1}".format(e.winerror, ctypes.FormatError(e.winerror))
RecordFailedNames(filePath)
def WalkDirReport(dirPath, fileNum):
print '##############' + str(fileNum) + ' files processed##############'
print 'Failed files(%d):' %(len(failedNamesList))
for i in range(len(failedNamesList)):
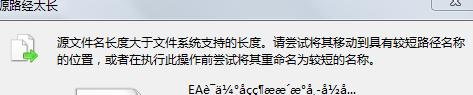
print ' ' + failedNamesList[i]某些亂碼檔名過長(多為.mht檔案),os.renames()時會觸發WindowsError[3]異常,如:

事實上,在資源管理器裡開啟這些檔案時,會提示"源路徑過長":
上述程式碼可有效地恢復原始亂碼目錄和檔名。當時的執行截圖如下:
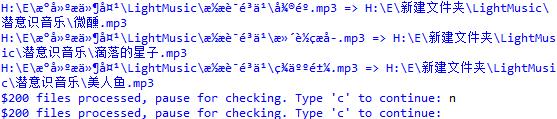
以及

經初步檢驗,更名成功。此時可通過tree命令生成生成目錄樹,與原先儲存的檔案列表對比。遺憾的是,兩者樹狀列表順序不同,無法直接對比。當然,如果夠閒,也可以程式設計比照。
四. 後記
本文所述的亂碼恢復實踐其實是種"摸著石頭過河(trial and error)"的過程。如果當初先研究字元編碼,而不是左右開弓,應該會避免不少彎路。當然論及價效比,孰優孰劣,亦未可知。
最後,關於Python字元編碼基礎知識,作者將在後續文章中加以說明,同時澄清本文一些謬誤之處。臉皮薄,就不說"敬請期待"了~~
相關推薦
Linux->Windows主機目錄和檔名中文亂碼恢復
目錄 Linux->Windows主機目錄和檔名中文亂碼恢復 標籤: 字元編碼 Python 宣告 本文主要記述作者如何通過Python指令碼恢復跨平臺傳輸導致的目錄和檔名中文亂碼。作者對Python程式設計和字元編碼瞭解不多,紕漏難免,歡迎指正。同時,本文兼做學習筆記,存在囉嗦之處,敬請諒解。 本
在linux下顯示中文目錄和檔名
選擇一個一勞永逸的方法,就是修改/etc/下的fstab檔案,我的fstab內容如下: /dev/hda9 / ext2 defaults 1 1 /dev/hda8 /boot ext2 defaults 1 2 none /dev/pts devpts gid=5,mode=620 0
java上傳檔案到linux上 防止檔名中文亂碼
在windows系統下 預設編碼是GBK/GB2312的編碼格式,linux上預設為utf-8的編碼格式。 當我們在windows上上傳檔案的時候,JVM會根據本身的作業系統所預設的編碼格式 編譯成unicode位元組陣列,進行儲存。 然後解析的時候也會根據本身的作業系統預
解決部署在Linux下的java程式上傳檔案,檔名中文亂碼
找了一圈資料,把centos的字符集、tomcat中server.xml中的“URIEncoding”都更改為UTF-8之後還是不成功。最終在tomcat/bin/catalina.sh檔案中增加了“export LANG=zh_CN.UTF-8”,成功解決了問題。
windows下,PHP建立目錄名、檔名中文亂碼問題
問題 在windows下,PHP呼叫mkdir()、file_put_contents()、fopen()函式建立帶有中文的目
關於windows下程序開發的中文亂碼問題小結
latin1 nco ansi 多人 保存文件 很大的 問題: 什麽 提示 筆者遇到的問題背景: windows 下使用notepad++6.7 ,ftp連接遠程ubuntu主機,在本地創建遠程主機文件,編輯後上傳出現中文亂碼。 筆者最開始不明白問題出在哪,因為設置了在
request和response中文亂碼問題後臺處理辦法
init resp character etc 構造方法 字符 字節數組 http pre request接收參數的中文亂碼的處理: GET: 方法一:使用String的構造方法: new String(request.getParameter("傳過來的name
Linux文件目錄和權限
inf ble hierarchy source gif ane 擴展 就是 tor Linux文件目錄和權限 前言: Linux一般將文件可存取的身份分為三個類別,分別是 owner/group/others,根據權限劃分,每個目錄都可以擁有相對身份的-rwx[可讀可寫可
Redmine 甘特圖導出 PDF 和 PNG 中文亂碼問題
foo har redmine apt-get phi arp 啟動 字體 config Redmine使用了RMagick來處理圖片,fpdf處理PDF,並在調用時設定了字體PDF中文字體redmine 中關於PDF字體設置的代碼 case pdf_en
git status 顯示中文和解決中文亂碼
col cte bash lse ons 註意 gui 字符集 dmi 目錄 git status 顯示中文和解決中文亂碼 解決git status不能顯示中文 解決git bash 終端顯示中文亂碼 通過修改配置文件來解決中文亂碼 git status 顯示中文和解
GET和POST中文亂碼的解決方法
如果表單中含有中文,採用GET或者POST提交請求時,getParameter()方法接收到的引數值亂碼。 1、亂碼產生的原因 請求引數通過瀏覽器傳送給Tomcat伺服器,瀏覽器傳送編碼,但是tomcat預設採用ISO-8859-1編碼進行處理,因此利用getParamenter()取出是亂碼。 2、PO
解決windows 掛載 nfs 驅動器中 中文亂碼問題
亂碼問題,是由於 mount.nfs 命令不支援 utf-8字符集。所以是系統軟體支援的問題。在網路上找了很多方案都沒能解決。 網上主要有三種方案(1)換解決方案,使用smb 共享,這等於不是解決方法。(2)使用第三方nfs 客戶端,但是Windows 10 預設不允許testsigning 測試模式。所以
解決Java POI 匯出Excel時檔名中文亂碼,相容瀏覽器
String agent = request.getHeader("USER-AGENT").toLowerCase(); response.setContentType("application/vnd.ms-excel");&
Asp.Net匯出檔名中文亂碼
Asp.Net匯出word為例,Excel等其他檔案也一樣 protected void Page_Load(object sender, EventArgs e) {string html = “網頁html程式碼”; string fileName = "故事.doc"
windows10下面部署nginx(解決檔名中文亂碼問題)
由於開發需要,我們總是需要先在windows環境下面部署專案進行測試,通過之後才會移植到linux系統進行測試部署。 本篇文章會介紹一下windows終端下面部署nginx WEB服務的一些步驟流程,僅供參考! 一、nginx for windows原始碼包下載: http://
IDEA開發Struts2和Tomcat中文亂碼解決方案
idea struts2中文亂碼。idea tomcat中文亂碼。 1.很可能是寫有中文的Java檔案編碼和前端不一樣導致。 統一為UTF-8編碼: jsp檔案 <%@ page contentType="text/html;charset=UTF-8" pag
Linux設定主機名和配置主機名跟IP地址對映
(1)為當前使用者配置臨時管理員身份 命令: sudo vi/etc/sysconfig/network 然輸入hadoop的密碼 被警告hadoop不在sudoers這個檔案中,解決辦法就是切換到root許可權,修改這個檔案,把hadoop加入到檔案中去 然後找
PHP問題 - 上傳檔名中文亂碼
iconv()按要求的字元編碼轉換字串 string iconv ( string $in_charset , string $out_charset , string $str ) in_charset 輸入的字符集。 out_charset
atom和sublime中文亂碼問題
一開始因為atom的炫酷外掛active power mode 而選擇atom編輯器,作為一個小白上來就用外掛真是自找苦吃,各種百度各種查,終於發現不用手動下載外掛檔案放到atom檔案目錄下,而是直接
python 獲取當前目錄下的檔案目錄和檔名 python 獲取當前目錄下的檔案目錄和檔名
python 獲取當前目錄下的檔案目錄和檔名 os模組下有兩個函式: os.walk() os.listdir() 1 # -*- coding: utf-8 -*- 2