
實現布隆過濾器
結合了點陣圖和Hash表兩者的優點,點陣圖的優點是節省空間,但是隻能處理整型值一類的問題,無法處理字串一類的問題,而Hash表卻恰巧解決了點陣圖無法解決的問題,然而Hash太浪費空間。針對這個問題,布隆提出了一種基於二進位制向量和一系列隨機函式的資料結構-布隆過濾器。它的空間利用率和時間效率是很多演算法無法企及的,但是它也有一些缺點,就是會有一定的誤判率並且不支援刪除操作。
實現程式碼:
#include"comm.h"
#include"BitMap.h"
//布隆過濾器
template <class T, class HashFun1 = __HashFunc1<T>,
class comm.h
#include<string>
template<class K>
class HashFunDef
{
public:
size_t operator()(const K& key)
{
return key;
}
};
template<>
class HashFunDef<string>
{
public:
size_t operator()(const string& key)
{
return BKDRHash(key.c_str());
}
};
static size_t BKDRHash(const char * str)
{
unsigned int seed = 131; // 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
size_t SDBMHash(const char* str)
{
register size_t hash = 0;
while (size_t ch = (size_t)*str++)
{
hash = 65599 * hash + ch;
//hash = (size_t)ch+(hash<<6)+ (hash<<16)-hash;
}
return hash;
}
size_t RSHash(const char *str)
{
register size_t hash = 0;
size_t magic = 63689;
while (size_t ch = (size_t)*str++)
{
hash = hash * magic + ch;
magic *= 378551;
}
return hash;
}
size_t APHash(const char* str)
{
register size_t hash = 0;
size_t ch;
for (long i = 0; ch = (size_t)*str++; i++)
{
if (0 == (i & 1))
{
hash ^= ((hash << 7) ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
size_t JSHash(const char* str)
{
if (!*str)
return 0;
register size_t hash = 1315423911;
while (size_t ch = (size_t)*str++)
{
hash ^= ((hash << 5) + ch + (hash >> 2));
}
return hash;
}
template<class K>
struct __HashFunc1
{
size_t operator()(const K& key)
{
return BKDRHash(key.c_str());
}
};
template<class K>
struct __HashFunc2
{
size_t operator()(const K& key)
{
return SDBMHash(key.c_str());
}
};
template<class K>
struct __HashFunc3
{
size_t operator()(const K& key)
{
return RSHash(key.c_str());
}
};
template<class K>
struct __HashFunc4
{
size_t operator()(const K& key)
{
return APHash(key.c_str());
}
};
template<class K>
struct __HashFunc5
{
size_t operator()(const K& key)
{
return JSHash(key.c_str());
}
};
BitMap.h
#include<iostream>
using namespace std;
#include<vector>
class Bitmap
{
public:
Bitmap()
{}
Bitmap(size_t size)
{
_table.resize((size >> 5) + 1);
}
void set(size_t data)
{
//將資料所在位元組的位元位置1
size_t byte = data >> 5;
size_t bit = data % 32;
_table[byte] |= 1 << bit;
}
void ReSet(size_t data)
{
//將資料所在位元組的位元位置0
size_t byte = data >> 5;
size_t bit = data % 32;
_table[byte] &= ~(1 << bit);
}
//所查data是否存在
bool test(size_t data)
{
size_t byte = data >> 5;
size_t bit = data % 32;
//1<<bit將其餘位置0,除bit位
if ((1 << bit)&_table[byte])
return true;
return false;
}
private:
vector<int> _table;
};
相關推薦
基於redis 實現布隆過濾器
簡介 Redis中有一個數據結構叫做Bitmap(下方有官網詳解),它提供一個最大長度為512MB(2^32)的位陣列。我們可以把它提供給布隆過濾器做位陣列。 根據《數學之美》中給出的資料,在使用8個雜湊函式的情況下,512MB大小的位陣列在誤報率萬分之五的情況下可以對約兩億的url去重
實現布隆過濾器
結合了點陣圖和Hash表兩者的優點,點陣圖的優點是節省空間,但是隻能處理整型值一類的問題,無法處理字串一類的問題,而Hash表卻恰巧解決了點陣圖無法解決的問題,然而Hash太浪費空間。針對這個問題,布隆提出了一種基於二進位制向量和一系列隨機函式的資料結構-布隆過
javascript實現布隆過濾器(改進)
雜湊函式 /** * MurmurHash * * 參考 http://murmurhash.googlepages.com/ * * data:待雜湊的值 * offset: * seed:種子集 * */ functio
Python實現布隆過濾器
#_*_coding:utf_8_ import BitVector import os import sys class SimpleHash(): def __init__(self, capability, seed): s
布隆過濾器go實現
1 布隆過濾器原理 布隆過濾器一般用來判斷一個數據是否在一個很大的資料集合裡面。當然可以用陣列,集合,樹等資料結構和各種查詢法都可以做同樣的事情,但是布隆過濾器有更好的時間效率和空間效率。比特幣實現SPV節點時使用了布隆過濾器來查詢交易。布隆過濾器可以判斷一個數在不在集合裡,但存在一定的誤判率。
[原創]大資料:布隆過濾器C#版簡單實現。
public class BloomFilter { public BitArray _BloomArray; public Int64 BloomArryLength { get; } public Int64 DataArray
布隆過濾器,原理+案例+程式碼實現
概述 什麼是布隆過濾器 布隆過濾器(Bloom Filter)是1970年由布隆提出的,它實際上是由一個很長的二進位制向量和一系列隨意對映函式組成。 它是一種基於
url去重 --布隆過濾器 bloom filter原理及python實現
array art bits bras pos for tar ack setup https://blog.csdn.net/a1368783069/article/details/52137417 # -*- encoding: utf-8 -*- """This
布隆過濾器(Bloom Filter)的簡單實現
最近在部署Scrapy專案時,瞭解到Scrapy_Redis的去重機制並不太友好。查詢之後發現了一個更好的去重方式——布隆過濾器。 使用布隆過濾器的原因: 關於布隆過濾器的詳細原理及介紹,推薦一個部落格:https://www.cnblogs.com/haippy/archive/2012/
java實現去重布隆過濾器(BloomFilter)
最近用到在list中找出重複的元素,實現結果給大家分享一下,自己也當做一個筆記。 在網上找的布隆過濾器(BloomFilter)類的實現: public class BloomFilter { private static final int DEFAULT_SIZE =
JAVA實現較完善的布隆過濾器
布隆過濾器是可以用於判斷一個元素是不是在一個集合裡,並且相比於其它的資料結構,布隆過濾器在空間和時間方面都有巨大的優勢。布隆過濾器儲存空間和插入/查詢時間都是常數。但是它也是擁有一定的缺點:布隆過濾器是有一定的誤識別率以及刪除困難的。本文中給出的布隆過濾器的實現,基本滿足了
布隆過濾器Bloom Filter演算法的Java實現(用於去重)
在日常生活中,包括在設計計算機軟體時,我們經常要判斷一個元素是否在一個 集合中。比如在字處理軟體中,需要檢查一個英語單詞是否拼寫正確(也就是要判斷它是否在已知的字典中);在 FBI,一個嫌疑人的名字是否已經在嫌疑名單上;在網路爬蟲裡,一個網址是否被訪問過等等。最直接的方法就
布隆過濾器總結(三)Java程式碼實現
/** * 專案名:SpiderCrawler * 檔名:BloomFilterTest.java * 作者:zhouyh * 時間:2014-8-29 下午02:54:56 * 描述:TODO(用一句話描述該檔案做什麼) */ package c
【布隆過濾器】實現一個簡單的布隆過濾器
原理 布隆過濾器(Bloom Filter)是1970年由布隆提出的。它實際上是一個很長的二進位制向量和一系列隨機對映函式。布隆過濾器可以用於檢索一個元素是否在一個集合中。它的優點是空間效率和查詢時間都遠遠超過一般的演算法,缺點是有一定的誤識別率和刪除困難。
day25之布隆過濾器的實現和優缺點以及擴充套件
布隆過濾器(Bloom Filter)是1970年由布隆提出的。它實際上是一個很長的二進位制向量和一系列隨機對映函式。布隆過濾器可以用於檢索一個元素是否在一個集合中。它的優點是空間效率和查詢時間都遠遠超過一般的演算法,缺點是有一定的誤識別率和刪除困難。 程式碼
BloomFilter布隆過濾器的java實現
網上有很多的原理解釋說明,此處不再對bloom filter做過多的說明,直接上程式碼(注:程式碼參考了網上其他部落格的實現,比如布隆過濾器(Bloom Filter)Java實現) /** * 專案名:SpiderCrawler * 檔名:BloomFil
BloomFilter(布隆過濾器)的C#實現
BloomFilterTest的程式碼如下: static void Main() { BloomFilter<string> bf = new BloomFilter<string>(20, 3);
Bloom Filter(布隆過濾器)學習實現(C++實現)
非常感謝評論裡指出了我程式碼裡的小問題。以下程式碼修改了一下,主要是在第二次 HasH 的時候有小問題。 Bloom filter簡介 Bloom filter 是由 Howard Bloom 在 1970 年提出的二進位制向量資料結構,它具有很好的空
布隆過濾器(Bloom Filters)的原理及程式碼實現(Python + Java)
本文介紹了布隆過濾器的概念及變體,這種描述非常適合程式碼模擬實現。重點在於標準布隆過濾器和計算布隆過濾器,其他的大都在此基礎上優化。文末附上了標準布隆過濾器和計算布隆過濾器的程式碼實現(Java版和Python版) 本文內容皆來自 《Foundations of Computers Systems Rese
冷飯新炒:理解布隆過濾器演算法的實現原理
## 前提 這是《冷飯新炒》系列的第六篇文章。 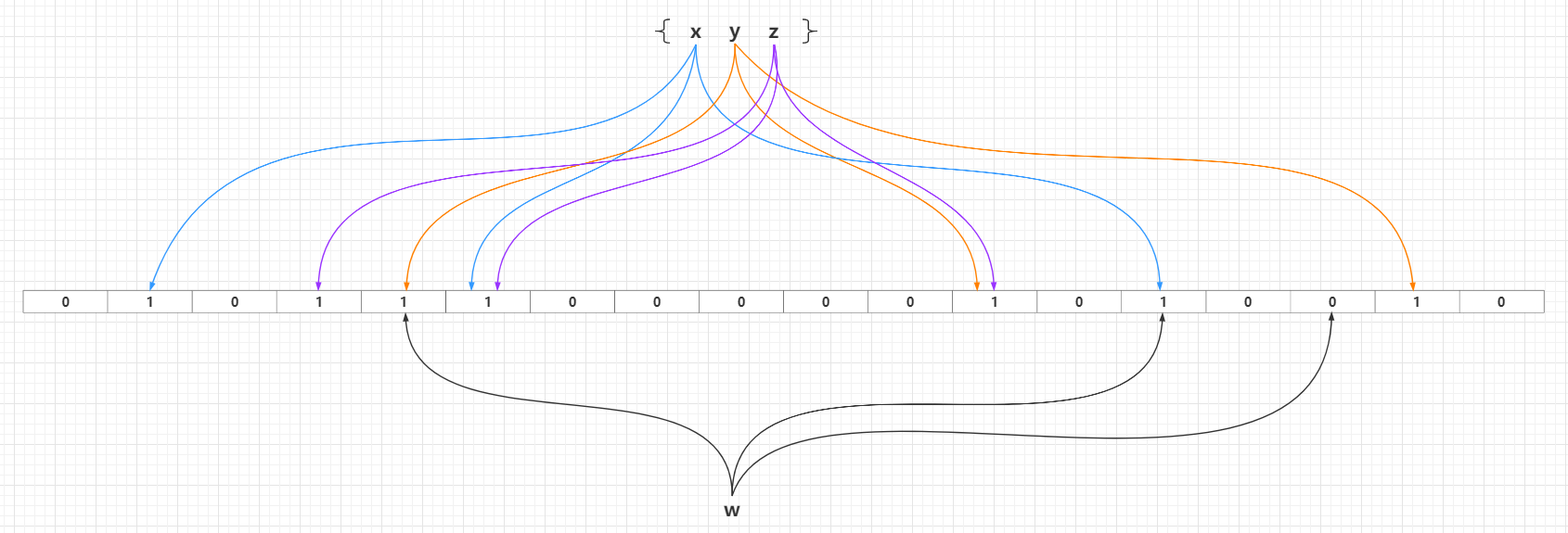 本文會翻炒一個用途比較廣的演算法 - **布隆過濾器演算法**。 ## 布