
冷飯新炒:理解布隆過濾器演算法的實現原理
阿新 • • 發佈:2021-03-06
## 前提
這是《冷飯新炒》系列的第六篇文章。
本文會翻炒一個用途比較廣的演算法 - **布隆過濾器演算法**。
## 布隆過濾器的一些概念
主要包括:
- 簡介
- 演算法
- 引數
- 優勢和劣勢
### 布隆過濾器簡介
布隆過濾器是**一種空間高效概率性的資料結構**(百科中原文是`a space-efficient probabilistic data structure`),該資料結構於`1970`年由`Burton Howard Bloom`提出,**作用是測試一個元素是否某個集合的一個成員**。布隆過濾器是可能出現`false positive`(這個是專有名詞"假陽性",可以理解為誤判的情況,下文如果用到這個名詞會保留英文單詞使用)匹配的,換言之,布隆過濾器在使用的時候有可能返回結果"可能存在於集合中"或者"必定不存在於集合中"。
### 布隆過濾器演算法描述
在場景複雜的網路爬蟲中,爬取到的網頁`URL`依賴有可能成環,例如在`URL-1`頁面中展示了`URL-2`,然後又在`URL-2`中的頁面展示了`URL-1`,這個時候需要一種方案記錄和判斷歷史訪問過的`URL`。這個時候可能會想到下面的方案:
- 方案一:使用資料庫儲存已經訪問過的`URL`,例如`MySQL`表中基於`URL`建立唯一索引或者使用`Redis`的`SET`資料型別
- 方案二:使用`HashSet`(其實這裡不侷限於`HashSet`,連結串列、樹和散列表等資料結構都能滿足)儲存已經訪問過的`URL`
- 方案三:基於方案一和方案二進行優化,儲存`URL`的摘要,使用摘要演算法如`MD5`、`SHA-n`演算法針對`URL`字串生成摘要
- 方案四:使用`Hash`函式處理對應的`URL`生成一個雜湊碼,再把雜湊碼通過一個對映函式對映到一個固定容量的`BitSet`中的某一個位元
對於方案一、方案二和方案三,在歷史訪問`URL`資料量極大的情況下,會消耗巨大的儲存空間(磁碟或者記憶體),對於方案四,如果`URL`有`100`億個,那麼要把衝突機率降低到`1%`,那麼`BitSet`的容量需要設定為`10000`億。
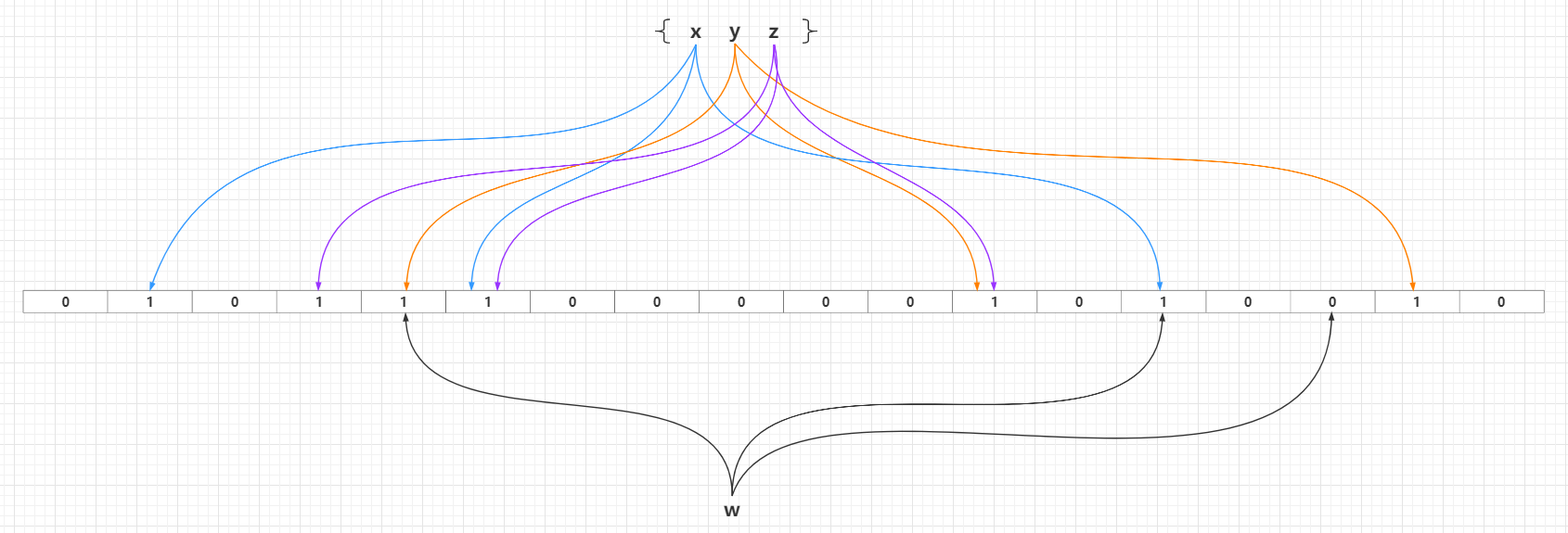
所以上面的四種方案都有明顯的不足之處,而布隆過濾器演算法的基本思路跟方案四差不多,最大的不同點就是方案四中只提到使用了一個雜湊函式,而布隆過濾器中使用了`k`(`k >= 1`)個相互獨立的高效低衝突的雜湊函式。
一個初始化的布隆過濾器是一個所有位元都設定為`0`的長度為`m`的位元陣列,也就是認知中的`Bit Array`、`Bit Set`或者`Redis`中的`Bit Map`概念。然後需要引入`k`個不同的雜湊函式,某個新增元素通過這`k`個雜湊函式處理之後,對映到位元陣列`m`個位元中的`k`個,並且把這些命中對映的`k`個位元位設定為`1`,產生一個均勻的隨機分佈。通常情況下,`k`的一個較小的常數,取決於所需的誤判率,而布隆過濾器容量`m`與雜湊函式個數`k`和需要新增元素數量呈正相關。

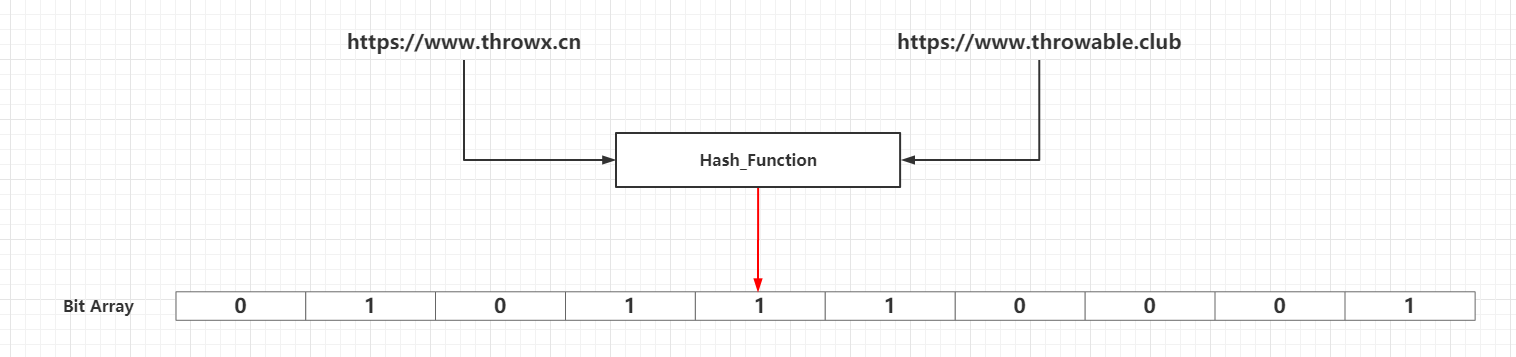
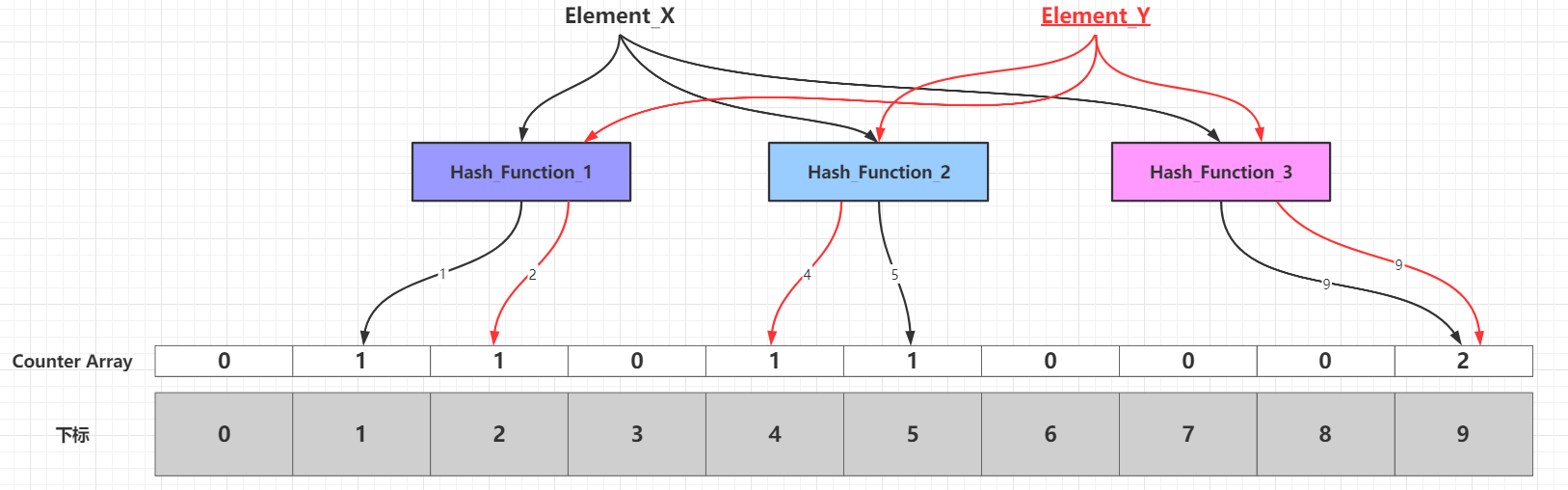
當需要新增的所有元素都新增到布隆過濾器之後,那麼位元陣列中的很多位元都被設定為`1`。這個時候如果需要判斷一個元素是否存在於布隆過濾器中,只需要通過`k`個雜湊函式處理得到位元陣列的`k`個下標,然後判斷位元陣列對應的下標所在位元是否為`1`。如果這`k`個下標所在位元中**至少存在一個`0`,那麼這個需要判斷的元素必定不在布隆過濾器代表的集合中**;如果這`k`個下標所在位元全部都為`1`,那麼那麼這個需要判斷的元素**可能存在於**布隆過濾器代表的集合中或者剛好是一個`False Positive`,至於誤差率分析見下文的**布隆過濾器的相關引數**一節。`False Positive`出現的情況可以見下圖:

當新增到布隆過濾器的元素數量比較大,並且布隆過濾器的容量設定不合理(過小),容易出現多個元素通過`k`個雜湊函式,對映到相同的`k`個位(如上圖的下標`1`、`3`、`9`所在的位),這個時候就無法準確判斷這`k`個位由具體那個元素對映而來。其實可以極端一點思考:假設布隆過濾器容量為`24`,雜湊函式只有一個,那麼新增最多`25`個不同元素,必定有兩個不同的元素的對映結果落在同一個位。
### 布隆過濾器的相關引數
在演算法描述一節已經提到過,布隆過濾器主要有下面的引數:
- 初始化位元陣列容量`m`
- 雜湊函式個數`k`
- 誤判率`ε`(數學符號`Epsilon`,代表`False Positive Rate`)
- 需要新增到布隆過濾器的元素數量`n`
考慮到篇幅原因,這裡不做這幾個值的關係推導,直接整理出結果和關係式。
- 誤判率`ε`的估算值為:`[1 - e^(-kn/m)]^k`
- 最優雜湊函式數量`k`的推算值:對於給定的`m`和`n`,當`k = m/n * ln2`的時候,誤判率`ε`最低
- 推算初始化位元容量`m`的值,當`k = m/n * ln2`的時候,`m >= n * log2(e) * log2(1/ε)`
這裡貼一個參考資料中`m/n`、`k`和`False Positive Rate`之間的關係圖:
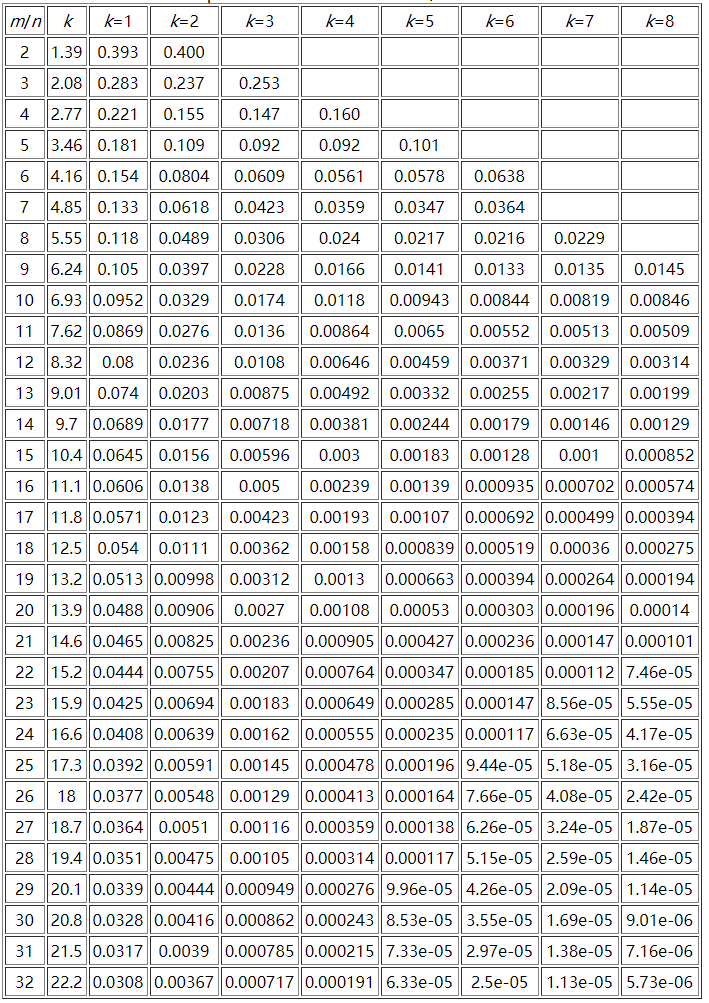
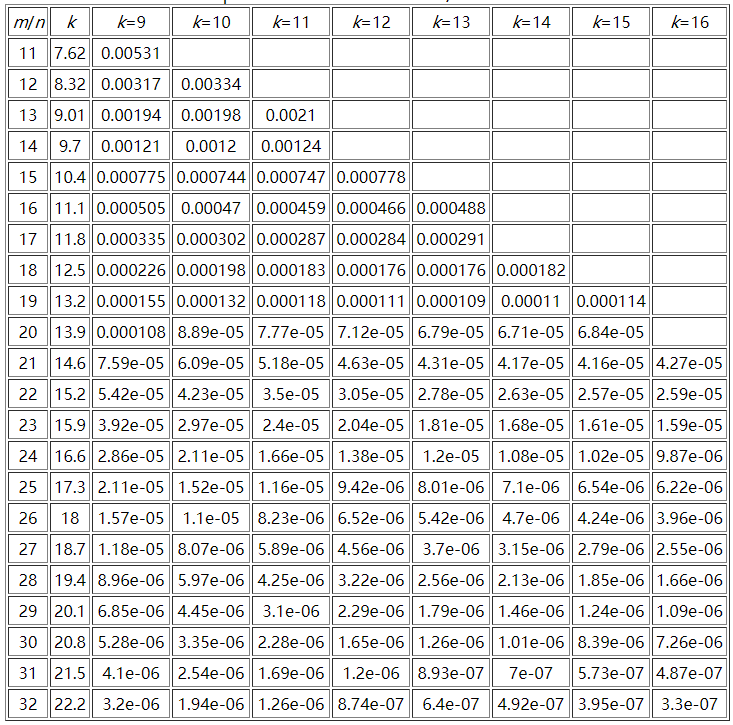

這裡可以推算一下表格中最大引數所需要的空間極限,假設`n`為`10`億,`m/n = 32`,那麼`m`為`320`億,而`k`為`24`,此時的誤判率為`2.17e-07(0.000000217)`,需要空間`3814.69727m`。一般規律是:
- 當`k`固定的時候,`m/n`越大,誤判率越小
- 當`m/n`固定的時候,`k`越大,誤判率越大
通常情況下,`k`需要固定,而`n`是無法確定準確值,最好要評估增長趨勢預先計算一個比較大的`m`值去降低誤判率,當然也要權衡`m`值過大導致空間消耗過大的問題。
既然引數的關係式都已經有推導結果,可以基於關係式寫一個引數生成器:
```java
import java.math.BigDecimal;
import java.math.RoundingMode;
public class BloomFilterParamGenerator {
public BigDecimal falsePositiveRate(int m, int n, int k) {
double temp = Math.pow(1 - Math.exp(Math.floorDiv(-k * n, m)), k);
return BigDecimal.valueOf(temp).setScale(10, RoundingMode.FLOOR);
}
public BigDecimal kForMinFalsePositiveRate(int m, int n) {
BigDecimal k = BigDecimal.valueOf(Math.floorDiv(m, n) * Math.log(2));
return k.setScale(10, RoundingMode.FLOOR);
}
public BigDecimal bestM(int n, double falsePositiveRate) {
double temp = log2(Math.exp(1) + Math.floor(1 / falsePositiveRate));
return BigDecimal.valueOf(n).multiply(BigDecimal.valueOf(temp)).setScale(10, RoundingMode.FLOOR);
}
public double log2(double x) {
return Math.log(x) / Math.log(2);
}
public static void main(String[] args) {
BloomFilterParamGenerator generator = new BloomFilterParamGenerator();
System.out.println(generator.falsePositiveRate(2, 1, 2)); // 0.3995764008
System.out.println(generator.kForMinFalsePositiveRate(32, 1)); // 22.1807097779
System.out.println(generator.bestM(1, 0.3995764009)); // 2.2382615950
}
}
```
這裡的計算沒有考慮嚴格的進位和截斷,所以和實際的結果可能有偏差,只提供一個參考的例子。
### 布隆過濾器的優勢和劣勢
布隆過濾器的優勢:
- 布隆過濾器相對於其他資料結構在時空上有巨大優勢,佔用記憶體少,查詢和插入元素的時間複雜度都是`O(k)`
- 可以準確判斷元素不存在於布隆過濾器中的場景
- 雜湊函式可以獨立設計
- 布隆過濾器不需要儲存元素本身,適用於某些資料敏感和資料嚴格保密的場景
布隆過濾器的劣勢:
- 不能準確判斷元素必定存在於布隆過濾器中的場景,存在誤判率,在`k`和`m`固定的情況下,新增的元素越多,誤判率越高
- 沒有儲存全量的元素,對於一些準確查詢或者準確統計的場景不適用
- 原生的布隆過濾器無法安全地刪除元素
> 這裡留一個很簡單的問題給讀者:為什麼原生的布隆過濾器無法安全地刪除元素?(可以翻看之前的False Positive介紹)
## 布隆過濾器演算法實現
著名的`Java`工具類庫`Guava`中自帶了一個`beta`版本的布隆過濾器實現,這裡參考其中的原始碼實現思路和上文中的演算法描述進行一次布隆過濾器的實現。先考慮設計雜湊函式,簡單一點的方式就是參考`JavaBean`的`hashCode()`方法的設計:
```java
// 下面的方法來源於java.util.Arrays#hashCode
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
```
上面方法的`31`可以作為一個輸入的`seed`,每個雜湊函式設計一個獨立的`seed`,並且這個`seed`值選用素數基於字串中的每個`char`進行迭加就能實現計算出來的結果是相對獨立的:
```java
import java.util.Objects;
public class HashFunction {
/**
* 布隆過濾器容量
*/
private final int m;
/**
* 種子
*/
private final int seed;
public HashFunction(int m, int seed) {
this.m = m;
this.seed = seed;
}
public int hash(String element) {
if (Objects.isNull(element)) {
return 0;
}
int result = 1;
int len = element.length();
for (int i = 0; i < len; i++) {
result = seed * result + element.charAt(i);
}
// 這裡確保計算出來的結果不會超過m
return (m - 1) & result;
}
}
```
接著實現布隆過濾器:
```java
public class BloomFilter {
private static final int[] K_SEED_ARRAY = {5, 7, 11, 13, 31, 37, 61, 67};
private static final int MAX_K = K_SEED_ARRAY.length;
private final int m;
private final int k;
private final BitSet bitSet;
private final HashFunction[] hashFunctions;
public BloomFilter(int m, int k) {
this.k = k;
if (k <= 0 && k > MAX_K) {
throw new IllegalArgumentException("k = " + k);
}
this.m = m;
this.bitSet = new BitSet(m);
hashFunctions = new HashFunction[k];
for (int i = 0; i < k; i++) {
hashFunctions[i] = new HashFunction(m, K_SEED_ARRAY[i]);
}
}
public void addElement(String element) {
for (HashFunction hashFunction : hashFunctions) {
bitSet.set(hashFunction.hash(element), true);
}
}
public boolean contains(String element) {
if (Objects.isNull(element)) {
return false;
}
boolean result = true;
for (HashFunction hashFunction : hashFunctions) {
result = result && bitSet.get(hashFunction.hash(element));
}
return result;
}
public int m() {
return m;
}
public int k() {
return k;
}
public static void main(String[] args) {
BloomFilter bf = new BloomFilter(24, 3);
bf.addElement("throwable");
bf.addElement("throwx");
System.out.println(bf.contains("throwable")); // true
}
}
```
這裡的雜湊演算法和有限的`k`值不足以應對複雜的場景,僅僅為了說明如何實現布隆過濾器,總的來說,原生布隆過濾器演算法是比較簡單的。對於一些複雜的生產場景,可以使用一些現成的類庫如`Guava`中的布隆過濾器`API`、`Redis`中的布隆過濾器外掛或者`Redisson`(`Redis`高階客戶端)中的布隆過濾器`API`。
## 布隆過濾器應用
主要包括:
- `Guava`中的`API`
- `Redisson`中的`API`
- 使用場景
### 使用Guava中的布隆過濾器API
引入`Guava`的依賴:
```xml
com.google.guava 30.1-jre
```
使用布隆過濾器:
```java
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.StandardCharsets;
public class GuavaBloomFilter {
@SuppressWarnings("UnstableApiUsage")
public static void main(String[] args) {
BloomFilter bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.US_ASCII), 10000, 0.0444D);
bloomFilter.put("throwable");
bloomFilter.put("throwx");
System.out.println(bloomFilter.mightContain("throwable"));
System.out.println(bloomFilter.mightContain("throwx"));
}
}
```
構造`BloomFilter`的最多引數的靜態工廠方法是`BloomFilter create(Funnel funnel, long expectedInsertions, double fpp, BloomFilter.Strategy strategy)`,引數如下:
- `funnel`:主要是把任意型別的資料轉化成`HashCode`,是一個頂層介面,有大量內建實現,見`Funnels`
- `expectedInsertions`:期望插入的元素個數
- `fpp`:猜測是`False Positive Percent`,誤判率,小數而非百分數,預設值`0.03`
- `strategy`:對映策略,目前只有`MURMUR128_MITZ_32`和`MURMUR128_MITZ_64`(預設策略)
引數可以參照上面的表格或者引數生成器的指導,基於實際場景進行定製。
### 使用Redisson中的布隆過濾器API
高階`Redis`客戶端`Redisson`已經基於`Redis`的`bitmap`資料結構做了封裝,遮蔽了複雜的實現邏輯,可以開箱即用。引入`Redisson`的依賴:
```xml
org.redisson 3.15.1
```
使用`Redisson`中的布隆過濾器`API`:
```java
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379");
RedissonClient redissonClient = Redisson.create(config);
RBloomFilter bloomFilter = redissonClient.getBloomFilter("ipBlockList");
// 第一個引數expectedInsertions代表期望插入的元素個數,第二個引數falseProbability代表期望的誤判率,小數表示
bloomFilter.tryInit(100000L, 0.03D);
bloomFilter.add("127.0.0.1");
bloomFilter.add("192.168.1.1");
System.out.println(bloomFilter.contains("192.168.1.1")); // true
System.out.println(bloomFilter.contains("192.168.1.2")); // false
}
}
```
`Redisson`提供的布隆過濾器介面`RBloomFilter`很簡單:

常用的方法有`tryInit()`(初始化)、`add()`(新增元素)和`contains()`(判斷元素是否存在)。相對於`Guava`的記憶體態的布隆過濾器實現,`Redisson`提供了基於`Redis`實現的**分散式布隆過濾器**,可以滿足分散式叢集中布隆過濾器的使用。
### 布隆過濾器使用場景
其實布隆過濾器的使用場景可以用百科中的一張示意圖來描述:

基於上圖具體化的一些場景列舉如下:
- 網站爬蟲應用中進行`URL`去重(不存在於布隆過濾器中的`URL`必定是未爬取過的`URL`)
- 防火牆應用中`IP`黑名單判斷(不侷限於`IP`黑名單,通用的黑名單判斷場景基本都可以使用布隆過濾器,不存在於布隆過濾器中的`IP`必定是白名單)
- 用於規避快取穿透(不存在於布隆過濾器中的`KEY`必定不存在於後置的快取中)
## 布隆過濾器變體
布隆過濾器的變體十分多,主要是為了解決布隆過濾器演算法中的一些缺陷或者劣勢。常見的變體如下:
|變體名稱|變體描述|
|:-:|:-:|
|`Counting Bloom Filter`|把原生布隆過濾器每個位替換成一個小的計數器(`Counter`),所謂計數器其實就是一個小的整數|
|`Compressed Bloom Filter`|對位陣列進行壓縮|
|`Hierarchical Bloom Filters`|分層,由多層布隆過濾器組成|
|`Spectral Bloom Filters`|`CBF`的擴充套件,提供查詢集合元素的出現頻率功能|
|`Bloomier Filters`|儲存函式值,不僅僅是做位對映|
|`Time-Decaying Bloom Filters`|計數器陣列替換位向量,優化每個計數器儲存其值所需的最小空間|
|`Space Code Bloom Filter`|-|
|`Filter Banks`|-|
|`Scalable Bloom filters`|-|
|`Split Bloom Filters`|-|
|`Retouched Bloom filters`|-|
|`Generalized Bloom Filters`|-|
|`Distance-sensitive Bloom filters`|-|
|`Data Popularity Conscious Bloom Filters`|-|
|`Memory-optimized Bloom Filter`|-|
|`Weighted Bloom filter`|-|
|`Secure Bloom filters`|-|
這裡挑選`Counting Bloom Filter`(簡稱`CBF`)變體稍微展開一下。原生布隆過濾器的基礎資料結構是位向量,`CBF`擴充套件原生布隆過濾器的基礎資料結構,底層陣列的每個元素使用`4`位大小的計數器儲存新增元素到陣列某個下標時候對映成功的頻次,在插入新元素的時候,通過`k`個雜湊函式對映到`k`個具體計數器,這些命中的計數器值增加`1`;刪除元素的時候,通過`k`個雜湊函式對映到`k`個具體計數器,這些計數器值減少`1`。使用`CBF`判斷元素是否在集合中的時候:
- 某個元素通過`k`個雜湊函式對映到`k`個具體計數器,所有計數器的值都為`0`,那麼元素必定不在集合中
- 某個元素通過`k`個雜湊函式對映到`k`個具體計數器,至少有`1`個計數器的值大於`0`,那麼元素可能在集合中
## 小結
一句話簡單概括布隆過濾器的基本功能:**不存在則必不存在,存在則不一定存在。**
在使用布隆過濾器判斷一個元素是否屬於某個集合時,會有一定的誤判率。也就是有可能把不屬於某個集合的元素誤判為屬於這個集合,這種錯誤稱為`False Positive`,但不會把屬於某個集合的元素誤判為不屬於這個集合(相對於`False Positive`,"假陽性",如果屬於某個集合的元素誤判為不屬於這個集合的情況稱為`False Negative`,"假陰性")。`False Positive`,也就是錯誤率或者誤判率這個因素的引入,是布隆過濾器在設計上權衡空間效率的關鍵。
參考資料:
- [Bloom filter](https://en.wikipedia.org/wiki/Bloom_filter)
- `Guava`相關原始碼
- [Bloom Filters - the math](http://pages.cs.wisc.edu/~cao/papers/summary-cache/node8.html)
(本文完 c-1-w e-a-2021